






目录
leetcode125:验证回文串
题目:
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。
示例:
示例 1:
输入: s = "A man, a plan, a canal: Panama" 输出:true 解释:"amanaplanacanalpanama" 是回文串。
示例 2:
输入:s = "race a car" 输出:false 解释:"raceacar" 不是回文串。
示例 3:
输入:s = " " 输出:true 解释:在移除非字母数字字符之后,s 是一个空字符串 "" 。 由于空字符串正着反着读都一样,所以是回文串。
提示:
1 <= s.length <= 2 * 105s仅由可打印的 ASCII 字符组成
解题思路:
这个问题要求检查一个给定的字符串是否是回文。
1.忽略非字母数字字符,然后将所有大写字母转换为小写字母。这样,只需比较处理过的字符串的两端字符是否相同。
2.使用双指针法,一个指针从字符串的开始向后移动,另一个从结尾向前移动,跳过非字母数字字符,并在必要时转换大写字母为小写。如果在任何时候两个指针所指的字符不匹配,就可以判断这不是一个回文字符串。
具体方法:
定义一个辅助函数x来检查一个字符是否是字母或数字。然后,在x函数中,我使用两个指针left和right分别指向字符串的起始和结束位置。在循环中,不断移动这两个指针,跳过非字母数字字符,并使用tolower函数将大写字母转换为小写字母。如果在任何时候left和right所指的字符不相同,函数返回false。如果循环完成没有找到不匹配的字符,说明这是一个回文字符串,函数返回true。
代码实现:
bool x(char c) {
return (c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z') || (c >= '0' && c <= '9');
}
bool isPalindrome(char *s) {
int left = 0, right = strlen(s) - 1;
while (left < right) {
while (left < right && !x(s[left])) {
left++;
}
while (left < right && !x(s[right])) {
right--;
}
if (tolower(s[left]) != tolower(s[right])) {
return false;
}
left++;
right--;
}
return true;
}leetcode73:矩阵置零
题目:
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
示例:
示例 1:
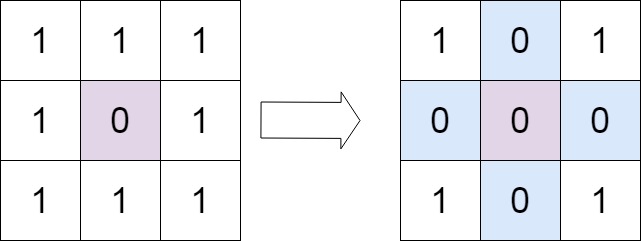
输入:matrix = [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]
示例 2:
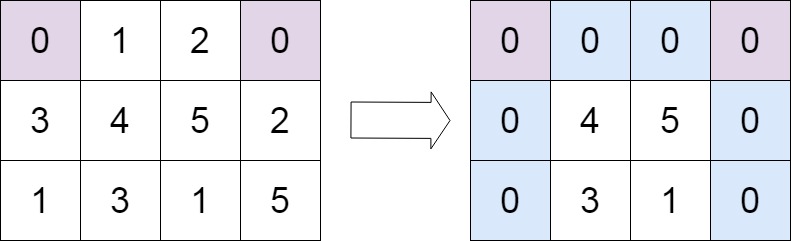
输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]] 输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
提示:
m == matrix.lengthn == matrix[0].length1 <= m, n <= 200-231 <= matrix[i][j] <= 231 - 1
解题思路:
用两个标记数组分别记录每一行和每一列是否有零出现。
定义了m,n分别表示矩阵的行数和列数,定义了数组row和col标记哪些行和列应该被设置为0
首先遍历该数组一次,如果某个元素为 0,那么就将该元素所在的行和列所对应标记数组的位置置为 true。最后我们再次遍历该数组,用标记数组更新原数组即可
代码实现:
void setZeroes(int** matrix, int matrixSize, int* matrixColSize) {
int m=matrixSize;
int n=matrixColSize[0];
int row[m],col[n];
memset(row,0,sizeof(row));
memset(col,0,sizeof(col));
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(matrix[i][j]==0){
row[i]=true;
col[j]=true;
}
}
}
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(row[i]!=0||col[j]!=0){
matrix[i][j]=0;
}
}
}
}leetcode21:合并两个有序链表
题目:
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
示例 1:
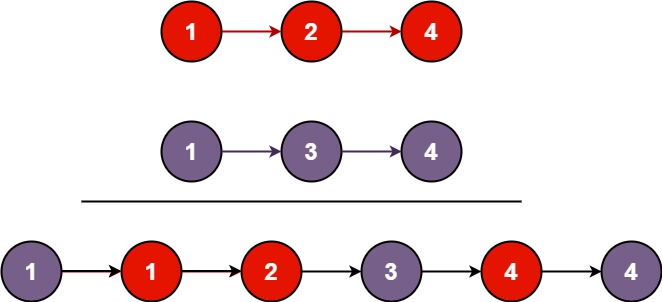
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = [] 输出:[]
示例 3:
输入:l1 = [], l2 = [0] 输出:[0]
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
解题思路:
首先,如果一个链表为空,则返回另一个链表
定义一个结构体变量m作为合并链表。这里关键的一点在于递归的思想,可以从两个链表的第一个值进行比较,如果第一个链表的第一个值小于第二个链表的第一个值,则更新m的值为第一个链表,并将m->next用递归的形式更新,即将第一个链表的下一个值来跟第二个链表比较;同理,如果大于,则将条件更换即可,通过不断更新并排序链表内的值,最终可以得到一个升序链表
代码实现:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if (list1 == NULL) {
return list2;
}
if (list2 == NULL) {
return list1;
}
struct ListNode* m;
if (list1->val <= list2->val) {
m = list1;
m->next = mergeTwoLists(list1->next, list2);
} else {
m = list2;
m->next = mergeTwoLists(list1, list2->next);
}
return m;
}leetcode147:对链表进行插入排序
题目:
给定单个链表的头 head ,使用 插入排序 对链表进行排序,并返回 排序后链表的头 。
插入排序 算法的步骤:
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
- 重复直到所有输入数据插入完为止。
示例:
示例 1:
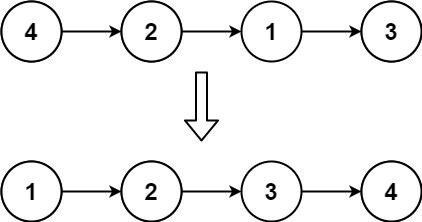
输入: head = [4,2,1,3] 输出: [1,2,3,4]
示例 2:

输入: head = [-1,5,3,4,0] 输出: [-1,0,3,4,5]
提示:
- 列表中的节点数在
[1, 5000]范围内 -5000 <= Node.val <= 5000
解题思路:
此题用冒泡、选择、插入排序均可做,以下解题思路为插入排序
插入排序的基本思想是,维护一个有序序列,初始时有序序列只有一个元素,每次将一个新的元素插入到有序序列中,将有序序列的长度增加 1,直到全部元素都加入到有序序列中。
对于单向链表而言,只有指向后一个节点的指针,因此需要从链表的头节点开始往后遍历链表中的节点,寻找插入位置。
对链表进行插入排序的具体过程如下。
1.首先判断给定的链表是否为空,若为空,则不需要进行排序,直接返回。
2.创建头节点 dummy,令 dummy->next = head,便于在 head 节点之前插入节点。
3.维护 last 为链表的已排序部分的最后一个节点,初始时 last = head。
4.维护 cur 为待插入的元素,初始时 cur = head->next。
5.比较 last 和 cur 的节点值。
若 last->val <= cur->val,说明 cur 应该位于 last 之后,将 last后移一位,cur 变成新的 last。
否则,从链表的头节点开始往后遍历链表中的节点,寻找插入 cur 的位置。令 pre 为插入 cur 的位置的前一个节点,进行如下操作,完成对 cur 的插入:
last->next = cur->next
cur->next = pre->next
pre->next = cur
令 cur= last->next,此时 cur 为下一个待插入的元素。
6.重复第 5 步和第 6 步,直到 cur 变成空,排序结束。
7.返回 dummy->next,为排序后的链表的头节点。
代码实现:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *insertionSortList(struct ListNode *head) {
if (head == NULL) {
return head;
}
struct ListNode *dummy = malloc(sizeof(struct ListNode));
dummy->val = 0;
dummy->next = head;
struct ListNode *last = head;
struct ListNode *cur = head->next;
while (cur != NULL) {
if (last->val <= cur->val) {
last = last->next;
} else {
struct ListNode *pre = dummy;
while (pre->next->val <= cur->val) {
pre = pre->next;
}
last->next = cur->next;
cur->next = pre->next;
pre->next = cur;
}
cur = last->next;
}
return dummy->next;
}leetcode309:买卖股票的最佳时机含冷冻期
题目:
给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例:
示例 1:
输入: prices = [1,2,3,0,2] 输出: 3 解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
示例 2:
输入: prices = [1] 输出: 0
提示:
1 <= prices.length <= 50000 <= prices[i] <= 1000
解题思路:
1.确定dp数组以及下标的含义
dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。
具体可以区分出如下四个状态:
- 状态一:持有股票状态(今天买入股票,或者是之前就买入了股票然后没有操作,一直持有)
- 不持有股票状态,这里就有两种卖出股票状态
- 状态二:保持卖出股票的状态(两天前就卖出了股票,度过一天冷冻期。或者是前一天就是卖出股票状态,一直没操作)
- 状态三:今天卖出股票
- 状态四:今天为冷冻期状态,但冷冻期状态不可持续,只有一天
2.确定递推公式
达到买入股票状态(状态一)即:dp[i][0],有两个具体操作:
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
达到今天就卖出股票状态(状态三),即:dp[i][2] ,只有一个操作:
昨天一定是持有股票状态(状态一),今天卖出
即:dp[i][2] = dp[i - 1][0] + prices[i];
达到冷冻期状态(状态四),即:dp[i][3],只有一个操作:
昨天卖出了股票(状态三)
dp[i][3] = dp[i - 1][2];
3.dp数组如何初始化
这里主要讨论一下第0天如何初始化。
如果是持有股票状态(状态一)那么:dp[0][0] = -prices[0],一定是当天买入股票。
保持卖出股票状态(状态二),这里其实从 「状态二」的定义来说 ,很难明确应该初始多少,这种情况我们就看递推公式需要我们给他初始成什么数值。如果i为1,第1天买入股票,那么递归公式中需要计算 dp[i - 1][1] - prices[i] ,即 dp[0][1] - prices[1],那么大家感受一下 dp[0][1] (即第0天的状态二)应该初始成多少,只能初始为0。想一想如果初始为其他数值,是我们第1天买入股票后 手里还剩的现金数量是不是就不对了。今天卖出了股票(状态三),同上分析,dp[0][2]初始化为0,dp[0][3]也初始为0。
- 操作一:前一天就是持有股票状态(状态一),dp[i][0] = dp[i - 1][0]
- 操作二:今天买入了,有两种情况
- 前一天是冷冻期(状态四),dp[i - 1][3] - prices[i]
- 前一天是保持卖出股票的状态(状态二),dp[i - 1][1] - prices[i]
-
那么dp[i][0] = max(dp[i - 1][0], dp[i - 1][3] - prices[i], dp[i - 1][1] - prices[i]);
达到保持卖出股票状态(状态二)即:dp[i][1],有两个具体操作:
- 操作一:前一天就是状态二
- 操作二:前一天是冷冻期(状态四)
4.确定遍历顺序
从递归公式上可以看出,dp[i] 依赖于 dp[i-1],所以是从前向后遍历。
5.举例推导dp数组
代码实现:
#define max(a, b) ((a) > (b) ? (a) : (b))
/**
* 状态一:持有股票状态(今天买入股票,
* 或者是之前就买入了股票然后没有操作,一直持有)
* 不持有股票状态,这里就有两种卖出股票状态
* 状态二:保持卖出股票的状态(两天前就卖出了股票,度过一天冷冻期。
* 或者是前一天就是卖出股票状态,一直没操作)
* 状态三:今天卖出股票
* 状态四:今天为冷冻期状态,但冷冻期状态不可持续,只有一天!
*/
int maxProfit(int* prices, int pricesSize) {
if(pricesSize == 0){
return 0;
}
int dp[pricesSize][4];
memset(dp, 0, sizeof (int ) * pricesSize * 4);
dp[0][0] = -prices[0];
for (int i = 1; i < pricesSize; ++i) {
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][1] - prices[i], dp[i - 1][3] - prices[i]));
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
dp[i][2] = dp[i - 1][0] + prices[i];
dp[i][3] = dp[i - 1][2];
}
return max(dp[pricesSize - 1][1], max(dp[pricesSize - 1][2], dp[pricesSize - 1][3]));
}leetcode187:重复的DNA序列
题目:
DNA序列 由一系列核苷酸组成,缩写为 'A', 'C', 'G' 和 'T'.。
- 例如,
"ACGAATTCCG"是一个 DNA序列 。
在研究 DNA 时,识别 DNA 中的重复序列非常有用。
给定一个表示 DNA序列 的字符串 s ,返回所有在 DNA 分子中出现不止一次的 长度为 10 的序列(子字符串)。你可以按 任意顺序 返回答案。
示例:
示例 1:
输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" 输出:["AAAAACCCCC","CCCCCAAAAA"]
示例 2:
输入:s = "AAAAAAAAAAAAA" 输出:["AAAAAAAAAA"]
提示:
0 <= s.length <= 105s[i]=='A'、'C'、'G'or'T'
解题思路:
hash + 滑动窗口
关键点:
1: 使用hashMap来记录子串出现的次数
2:通过滑动窗口的方式来找子串
3:最后统计hashMap的次数等于最大次数的子串
代码实现:
#define MAXSIZE 769/* 选取一个质数即可 */
typedef struct Node
{
char string[101];
int index;
struct Node *next; //保存链表表头
} List;
typedef struct
{
List *hashHead[MAXSIZE];//定义哈希数组的大小
} MyHashMap;
List * isInHash(List *list,char * stringKey)
{
List *nodeIt = list;
//通过链表下遍历
while (nodeIt != NULL)
{
if (strcmp(stringKey, nodeIt->string)== 0 )
{
return nodeIt;
}
nodeIt = nodeIt->next;
}
return NULL;
}
MyHashMap* myHashMapCreate()
{
int i;
MyHashMap* newHash= (MyHashMap* )malloc(sizeof(MyHashMap));
/* 对链表的头结点赋初值 */
for (i = 0; i < MAXSIZE; i++)
{
newHash->hashHead[i] = NULL;
}
return newHash;
}
int myHashID(char * str)
{
long h = 0;
for(int i = 0; i < strlen(str); i++)
{
h = (h * 26 % MAXSIZE + str[i] - 'A') % MAXSIZE;
// 字符串的hashcode, 权为26是因为小写字母,不限制时为128,这样能够让结点尽可能分布均匀,减少地址冲突
// 取模是为了防止int型溢出
}
return h % MAXSIZE;
}
void myHashMapPut(MyHashMap* obj, char* stringKey,int index)
{
//一定不再这里面
List * it= isInHash(obj->hashHead[myHashID(stringKey)],stringKey);
if(it != NULL)
{
//在表里面更新键值
it->index = index;
}
else
{
//不在表里面
List *newNode = (List*)malloc(sizeof(List));
strcpy(newNode->string , stringKey);
newNode->next = NULL;
newNode->index = index;
if(obj->hashHead[myHashID(stringKey)] != NULL)
{
//当前头链表不为空,则需要将后续的链表接上
//需要主要这里表头也代表一个数据的值
newNode->next = obj->hashHead[myHashID(stringKey)];
}
//修改头链表
obj->hashHead[myHashID(stringKey)] = newNode;
}
}
int myHashMapGet(MyHashMap* obj, char* stringKey)
{
List * it= isInHash(obj->hashHead[myHashID(stringKey)],stringKey);
if( it!= NULL)
{
return it->index;
}
return -1;
}
void myHashMapFree(MyHashMap* obj)
{
int i;
List *freeIt;
List *curIt;
for (i = 0; i < MAXSIZE; i++)
{
if(obj->hashHead[i] != NULL)
{
freeIt = NULL;
curIt = obj->hashHead[i];
while(curIt != NULL)
{
freeIt = curIt;
curIt= curIt->next;
free(freeIt);
}
obj->hashHead[i]= NULL;
}
}
free(obj);
}
char ** findRepeatedDnaSequences(char * s, int* returnSize)
{
char* stringKey = (char * )malloc(sizeof(char ) * 11);
int len = strlen(s);
if(len < 10)
{
*returnSize = 0;
return NULL;
}
MyHashMap * hsahMap = myHashMapCreate();
int maxCount = 0;
for(int i = 10; i <= len; i++)
{
memcpy(stringKey, &s[i-10], 10);
stringKey[10] = '\0';
int count = myHashMapGet(hsahMap, stringKey);
if(count == -1)
{
count = 1;
}
else
{
count++;
}
myHashMapPut(hsahMap,stringKey,count);
maxCount = fmax(maxCount, count);
}
if(maxCount < 2)
{
*returnSize = 0;
return NULL;
}
*returnSize = 0;
char ** returnMatStr = (char ** )malloc(sizeof(char *) * len);
int i;
List *freeIt;
List *curIt;
for (i = 0; i < MAXSIZE; i++)
{
if(hsahMap->hashHead[i] != NULL)
{
freeIt = NULL;
curIt = hsahMap->hashHead[i];
while(curIt != NULL)
{
freeIt = curIt;
curIt= curIt->next;
if(freeIt->index == maxCount)
{
returnMatStr[*returnSize] = (char * )malloc(sizeof(char ) * 11);
strcpy(returnMatStr[*returnSize], freeIt->string);
*returnSize = *returnSize + 1;
}
free(freeIt);
}
hsahMap->hashHead[i]= NULL;
}
}
free(hsahMap);
return returnMatStr;
}leetcode2517:礼盒的最大甜蜜度
题目:
给你一个正整数数组 price ,其中 price[i] 表示第 i 类糖果的价格,另给你一个正整数 k 。
商店组合 k 类 不同 糖果打包成礼盒出售。礼盒的 甜蜜度 是礼盒中任意两种糖果 价格 绝对差的最小值。
返回礼盒的 最大 甜蜜度。
示例:
示例 1:
输入:price = [13,5,1,8,21,2], k = 3 输出:8 解释:选出价格分别为 [13,5,21] 的三类糖果。 礼盒的甜蜜度为 min(|13 - 5|, |13 - 21|, |5 - 21|) = min(8, 8, 16) = 8 。 可以证明能够取得的最大甜蜜度就是 8 。
示例 2:
输入:price = [1,3,1], k = 2 输出:2 解释:选出价格分别为 [1,3] 的两类糖果。 礼盒的甜蜜度为 min(|1 - 3|) = min(2) = 2 。 可以证明能够取得的最大甜蜜度就是 2 。
示例 3:
输入:price = [7,7,7,7], k = 2 输出:0 解释:从现有的糖果中任选两类糖果,甜蜜度都会是 0 。
提示:
2 <= k <= price.length <= 1051 <= price[i] <= 109
解题思路:
礼盒的甜蜜度是 k种不同的糖果中,任意两种糖果价格差的绝对值的最小值。计算礼盒的甜蜜度时,可以先将 k 种糖果按照价格排序,然后计算相邻的价格差的绝对值,然后取出最小值。
要求甜蜜度的最大值,可以采用二分查找的方法。先假设一个甜蜜度 mid,然后尝试在排好序的 price 中找出 k种糖果,并且任意两种相邻的价格差绝对值都大于 mid。如果可以找到这样的 k 种糖果,则说明可能存在更大的甜蜜度,需要修改二分查找的下边界;如果找不到这样的 k 种糖果,则说明最大的甜蜜度只可能更小,需要修改二分查找的上边界。
在假设一个甜蜜度 mid后,在排好序的 price 中找 k种糖果时,需要用到贪心的算法。即从小到大遍历 price的元素,如果当前糖果的价格比上一个选中的糖果的价格的差大于 mid,则选中当前糖果,否则继续考察下一个糖果。
二分查找起始时,下边界为 0,上边界为 price的最大值与最小值之差。二分查找结束时,即可得到最大甜蜜度。
代码实现:
bool check(const int* price, int priceSize,int k, int tastiness) {
int prev = INT_MIN >> 1;
int cnt = 0;
for (int i = 0; i < priceSize; i++) {
int p = price[i];
if (p - prev >= tastiness) {
cnt++;
prev = p;
}
}
return cnt >= k;
}
static inline int cmp(const void *pa, const void *pb) {
return *(int *)pa - *(int *)pb;
}
int maximumTastiness(int* price, int priceSize, int k) {
qsort(price, priceSize, sizeof(int), cmp);
int left = 0, right = price[priceSize - 1] - price[0];
while (left < right) {
int mid = (left + right + 1) >> 1;
if (check(price, priceSize, k, mid)) {
left = mid;
} else {
right = mid - 1;
}
}
return left;
}leetcode238:除自身以外数组的乘积
题目
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法,且在 O(n) 时间复杂度内完成此题。
示例
示例 1:
输入: nums =[1,2,3,4]输出:[24,12,8,6]
示例 2:
输入: nums = [-1,1,0,-3,3] 输出: [0,0,9,0,0]
提示:
2 <= nums.length <= 105-30 <= nums[i] <= 30- 保证 数组
nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内
解题思路
初始化:创建一个结果数组 ra,并将所有元素初始化为 1。
前缀乘积:从左到右遍历数组,使用变量 pre 累积左侧元素的乘积。
后缀乘积:从右到左遍历数组,使用变量 suf 累积右侧元素的乘积。
组合结果:结合前缀和后缀乘积,存储在结果数组 ra 中。
返回结果:设置返回数组的大小,并返回结果数组 ra
代码实现
// 数组中除自身以外元素的乘积
int* productExceptSelf(int* nums, int numsSize, int* returnSize) {
static int ra[100000]; // 结果数组
for (int i = 0; i < numsSize; i++) {
ra[i] = 1; // 初始化结果数组为1
}
int pre = 1, suf = 1; // 前缀和后缀乘积初始化为1
for (int i = 1; i < numsSize; i++) {
pre *= nums[i - 1]; // 计算前缀乘积
suf *= nums[numsSize - i]; // 计算后缀乘积
ra[i] *= pre; // 更新结果数组
ra[numsSize - i - 1] *= suf; // 更新结果数组
}
*returnSize = numsSize; // 设置返回数组大小
return ra; // 返回结果数组
}leetcode394:字符串解码
题目
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例
示例 1:
输入:s = "3[a]2[bc]" 输出:"aaabcbc"
示例 2:
输入:s = "3[a2[c]]" 输出:"accaccacc"
示例 3:
输入:s = "2[abc]3[cd]ef" 输出:"abcabccdcdcdef"
示例 4:
输入:s = "abc3[cd]xyz" 输出:"abccdcdcdxyz"
提示:
1 <= s.length <= 30s由小写英文字母、数字和方括号'[]'组成s保证是一个 有效 的输入。s中所有整数的取值范围为[1, 300]
解题思路
创建两个栈,一个保存原串里的数字,另一个保存“ [ ”的位置,遇到数字,数字入栈;遇到左括号,则索引位置入栈(输出串的尾指针);遇到“ ] ”时,
从索引栈里弹出栈顶元素——就是最近的与之闭合的左括号,这部分内容是要被复制的,再弹出数字栈的栈顶元素,是几就把这部分内容复制几遍。
代码实现
#define N 2000
typedef struct {
int data[30];;
int top;
} Stack;
void push(Stack *s, int e) { s->data[(s->top)++] = e; }
int pop(Stack *s) { return s->data[--(s->top)]; }
//多位数字串转换成int
int strToInt(char *s)
{
char val[] = {'\0', '\0', '\0', '\0'};
int result = 0;
for(int i = 0; isdigit(s[i]); ++i)
val[i] = s[i];
for(int i = strlen(val) - 1, temp = 1; i >= 0; --i, temp *= 10)
result += ((val[i] - '0') * temp);
return result;
}
char* decodeString(char *s)
{
Stack magnification; magnification.top = 0;
Stack position; position.top = 0;
char *result = (char*)malloc(sizeof(char) * N);
char *rear = result;
for(int i = 0; s[i] != '\0'; ) {
if(isdigit(s[i])) {
push(&magnification, strToInt(&s[i]));
while(isdigit(s[i]))
++i;
}
else if(s[i] == '[') {
push(&position, rear - result);
++i;
}
else if(s[i] == ']') {
char *p = result + pop(&position);
int count = (rear - p) * (pop(&magnification) - 1);
for(; count > 0; --count)
*(rear++) = *(p++);
++i;
}
else
*(rear++) = s[i++];
}
*rear = '\0';
return result;
}leetcode23:合并K个升序链表
题目
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6
示例 2:
输入:lists = [] 输出:[]
示例 3:
输入:lists = [[]] 输出:[]
提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if(list1 == NULL){
return list2;
}
if(list2 == NULL){
return list1;
}
struct ListNode* ans;
if(list1->val <= list2->val){
ans = list1;
ans->next = mergeTwoLists(list1->next,list2);
}
else{
ans = list2;
ans->next = mergeTwoLists(list1,list2->next);
}
return ans;
}
struct ListNode* mergeKLists(struct ListNode** lists, int listsSize) {
if(!listsSize) return NULL;
struct ListNode* head = NULL;
for(int i = 0; i < listsSize; i++){
head = mergeTwoLists(head,lists[i]);
}
return head;
}leetcode232:用栈实现队列
题目
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false
说明:
- 你 只能 使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例
示例 1:
输入: ["MyQueue", "push", "push", "peek", "pop", "empty"] [[], [1], [2], [], [], []] 输出: [null, null, null, 1, 1, false] 解释: MyQueue myQueue = new MyQueue(); myQueue.push(1); // queue is: [1] myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue) myQueue.peek(); // return 1 myQueue.pop(); // return 1, queue is [2] myQueue.empty(); // return false
提示:
1 <= x <= 9- 最多调用
100次push、pop、peek和empty - 假设所有操作都是有效的 (例如,一个空的队列不会调用
pop或者peek操作)
解题思路
双栈
思路
将一个栈当作输入栈,用于压入 push传入的数据;另一个栈当作输出栈,用于 pop 和 peek 操作。
每次 pop 或 peek 时,若输出栈为空则将输入栈的全部数据依次弹出并压入输出栈,这样输出栈从栈顶往栈底的顺序就是队列从队首往队尾的顺序。
代码实现
typedef struct {
int intop,outtop;
int in[100],out[100];
} MyQueue;
MyQueue* myQueueCreate() {
MyQueue* queue=(MyQueue*)malloc(sizeof(MyQueue));
queue->intop=0;
queue->outtop=0;
return queue;
}
void myQueuePush(MyQueue* obj, int x) {
obj->in[(obj->intop)++]=x;
}
int myQueuePop(MyQueue* obj) {
int intop=obj->intop;
int outtop=obj->outtop;
while(outtop==0){
while(intop>0){
obj->out[outtop++]=obj->in[--intop];
}
}
int top=obj->out[--outtop];
while(outtop>0){
obj->in[intop++]=obj->out[--outtop];
}
obj->intop=intop;
obj->outtop=outtop;
return top;
}
int myQueuePeek(MyQueue* obj) {
return obj->in[0];
}
bool myQueueEmpty(MyQueue* obj) {
return obj->intop==0&&obj->outtop==0;
}
void myQueueFree(MyQueue* obj) {
obj->intop=0;
obj->outtop=0;
}
/**
* Your MyQueue struct will be instantiated and called as such:
* MyQueue* obj = myQueueCreate();
* myQueuePush(obj, x);
* int param_2 = myQueuePop(obj);
* int param_3 = myQueuePeek(obj);
* bool param_4 = myQueueEmpty(obj);
* myQueueFree(obj);
*/leetcode61:旋转链表
题目
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置
示例
示例 1:
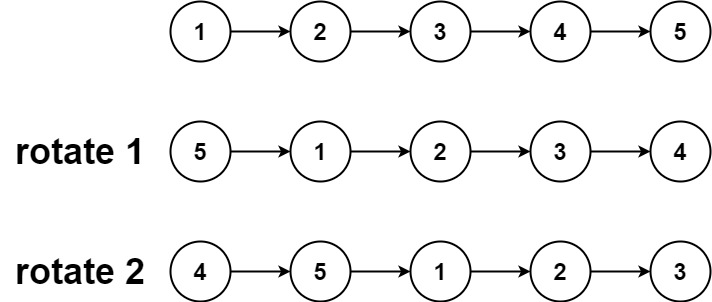
输入:head = [1,2,3,4,5], k = 2 输出:[4,5,1,2,3]
示例 2:

输入:head = [0,1,2], k = 4 输出:[2,0,1]
提示:
- 链表中节点的数目在范围
[0, 500]内 -100 <= Node.val <= 1000 <= k <= 2 * 109
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* rotateRight(struct ListNode* head, int k){
if(k==0 || head==NULL || head->next==NULL) return head;
struct ListNode* p,*q;
int a=0;
int count=0;
q=p=head;
while(p->next){
p=p->next;
count++;
}
count=count+1;
p->next=head;
while(a<count-k%count){
q=q->next;
p=p->next;
a++;
}
p->next=NULL;
return q;
}leetcode392:判断子序列
题目
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
示例
示例 1:
输入:s = "abc", t = "ahbgdc" 输出:true
示例 2:
输入:s = "axc", t = "ahbgdc" 输出:false
解题思路
双指针
思路及算法
本题询问的是,s 是否是 t 的子序列,因此只要能找到任意一种 s 在 t中出现的方式,即可认为 s 是 t的子序列。
而当我们从前往后匹配,可以发现每次贪心地匹配靠前的字符是最优决策。
假定当前需要匹配字符 c,而字符 c 在 t中的位置 x1 和 x2出现(x1<x2),那么贪心取 x1是最优解,因为 x2后面能取到的字符,x1也都能取到,并且通过 x1与 x2之间的可选字符,更有希望能匹配成功。
这样,我们初始化两个指针 i和 j,分别指向 s 和 t 的初始位置。每次贪心地匹配,匹配成功则 i 和 j 同时右移,匹配 s 的下一个位置,匹配失败则 j 右移,i不变,尝试用 t 的下一个字符匹配 s。
最终如果 i 移动到 s 的末尾,就说明 s 是 t 的子序列。
代码实现
bool isSubsequence(char* s, char* t) {
int n = strlen(s), m = strlen(t);
int i = 0, j = 0;
while (i < n && j < m) {
if (s[i] == t[j]) {
i++;
}
j++;
}
return i == n;
}














 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









