







大家都知道我们在前面说过我们写排序的六大方法。当然我们前面只写过的冒泡排序,那么就不用写了。那么接下来我们就将剩下的归并排序与选择排序给大家解释一下。首先归并排序其实是利用我们的递归。将数组分化,从而比较排列。然而选择培训呢就是在数组里面选择最大的或者最小的。走一遍,然后把它放在开头或者末尾,然后再走第二遍。找次大的或次小的。如此反复,就能将整个数组排列有序。那么我们简单说一下后我们就来讲解一下。
归并排序思路
对于归并排序来说,我们前面说过归并还是相当于一个递归过程。我们这样一个无序的数组。每递归一次我就除以二,每递归一次我就除以二直到数组成为一个元素的时候就返回来。再返回来的时候,我们就比较大小,将小的放在一个数组里面,然后再回去,然后再比较再放,一直到返回到最原始的数据,那么这个就是归并排序的大概内容。我们来看一张图片大家应该会更容易理解一些: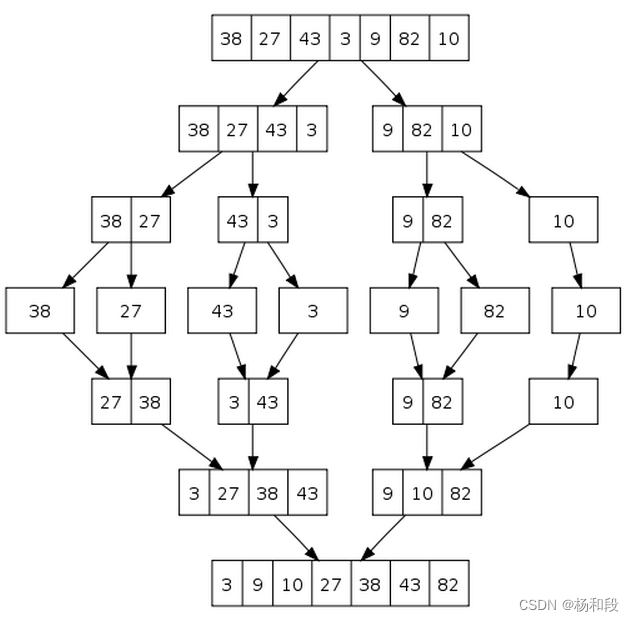
看这个图,我们大家从上往下看。我们可以看到上面的手镯是一个无序数组,然后我们将它划分为二。一个数字中的内容是38 27 43和12。另外一个数组是9,82,10。然后这些数组再依次划分的划分一直到每一个数组都只剩一个元素的时候就开始合并。但是大家也可以看到,每一个数组并不是随机合并的,是先比较大,小的在前面,大的在后面。然后将他们在汇集成一个数组,那么这样就结束了。
归并排序的实现
接下来我们来实现归并排序,首先我们需要知道归并排序里面的初始数据有哪些?我们肯定要有数组,并且有头和尾。然后我们就用子函数来实现,因为如果不用子函数的话会比较麻烦。递归的话用主函数递归是比较不好的。然后我们前面说过归并排序是将他们划分为二。那么我们肯定要求得他们的中间数,那么是不是就是头和尾相加除以二了。但是我不知道我们是要先算到每一个数组中只剩一个元素的时候才开始合并。那么我们是不是接下来就要继续递归,然后划分数组。在开始中我没有说过归并排序也是涉及到一点二叉树的内容的。但最主要的还是利用他的思想,因为我们知道二叉树如果读的话都是先左后右。那么我们递归也是,我这里先将左区间一直划分到最小之后,并且比较放置后我们再回去继续划分右区间合并。但是大家知道我们需要把数组存放的话,肯定需要另外一个数组。那么我们就是要创建一个另外的空的数组。但是我们都知道了,如果我们在子函数里面创建的话,每一次第一回都会创建一个。那这样的话肯定是不好的吧。所以我们最好在传递参数的时候就创建一个数组,把它传递到子函数里面。的话,我们就不需要在子函数里每一次递归都创建一个新的数组了。
创建新数组:创建新数字的话就是比较简单,我们只需要像开始一样malloc就可以了。但是我们前面也说过,你创建了的话肯定还需要释放,所以我们在传递后就要释放了。
int* tmp = (int*)malloc(sizeof(int)*n);子函数分化区间: 开始在归并排序说过我们需要将这个数组一直分化指导为一个元素的时候再合并。因为我们就需要先创建一个一个代表他们中间的下标的数。然后递归递归。我们肯定不能一直递归呀,但我们需要结束条件,那么递归的结束条件就是当做左区间的下标数大于右区间的下标数,那么就结束了。
if (l >= r)
return;
int mind = (l + r) / 2;
di(a, tmp, l,mind - 1);//递归分化到最小的那个元素去
di(a, tmp, mind, r);人为的确立区间:为什么我们需要确立一个区间嘞。因为我们前面讲过这是将两两比较,所以肯定需要两个数组来比较,然后放进另外一个数组里面。那我们区间都分为了左区间和右区间,所以我们需要把区间确定下来,然后接下来就是循环比较。
int be = l; int end = mind - 1;//把区间确定下来
int be1 = mind; int end1 = r;
int i = l;//表示合并的时候的数组位置循环比较放元素: 当我们递归好了之后,就剩下来就是合并了。我没有说过我们是左区间和右区间比较。但是我们循环肯定有一个度呀,左区间不能超出啊,右区间肯定也不能超出啊,那么这就是我们循环的判断条件了。但大家需要注意,我们因为是两个条件,如果有一个不满足就要退出来,那么肯定是与。如果用货的话,一个不满足,另一个满足还能继续,那么我们就出错了。但是我也知道我们可能有一些数组走的快,有一些数组走的嘛,当一个数组结束之后,另外一个数组可能还有数。梦的是在最基础的循环结束之后还要判断一下是否还有数组没有走到末尾。
while (be<=end&&be1<=end1)//当其中一个结束,那么就退出
{
if (a[be] < a[be1])
{
tmp[i++] = a[be++];
}
else
{
tmp[i++] = a[be1++];
}
}
while (be < be1)//当一个结束了,另外一个没有结束那么剩下的一个还要合并,不想判断直接写
{
tmp[i++] = a[be++];
}
while (be1 < be)
{
tmp[i++] = a[be1++];
}数组交换 :大家想一想,我们现在的数据存放在哪里的呀。是不是在tmp里面啊。但是我们原本要放在哪个数组里面啊。是不是a啊。那我们是不是一个在最后的时候把tmp里面的数组交换回来啊。那么我们是不是就要用以前的指令
memcpy(a + l, tmp + l, (r - l + 1)*sizeof(int));
总结
总体来说归并排序就是将数组分化分化分化到只有一个元素的时候,我们是在合并比较合并循环。当然我们需要创建一个新的数组来存储,所以这就是归并排序的大概思路了。其实总体来说,大家只需要知道上面我们的那张图片的话就有一个大概思路了,然后可以以此发挥,从而把整个思路推出来。
void di(int *a, int *tmp, int l, int r)
{
if (l >= r)
return;
int mind = (l + r) / 2;
di(a, tmp, l,mind );//递归分化到最小的那个元素去
di(a, tmp, mind+1, r);
int be = l; int end = mind;//把区间确定下来
int be1 = mind+1; int end1 = r;
int i = l;//表示合并的时候的数组位置
while (be<=end&&be1<=end1)//当其中一个结束,那么就退出
{
if (a[be] < a[be1])
{
tmp[i++] = a[be++];
}
else
{
tmp[i++] = a[be1++];
}
}
while (be < be1)//当一个结束了,另外一个没有结束那么剩下的一个还要合并,不想判断直接写
{
tmp[i++] = a[be++];
}
while (be1 < be)
{
tmp[i++] = a[be1++];
}
memcpy(a + l, tmp + l, (r - l + 1)*sizeof(int));
}
void xixi2(int *a, int n)
{
int* tmp = (int*)malloc(sizeof(int)*n);//提前创建数组,这样的话我们就可以不要在每一次递归的时候,或者在合并的时候创建数组了
if (tmp == NULL)
{
perrpr("malloc ");
exit(1);
}
di(a, tmp, 0,n-1);
free(tmp);
tmp = NULL;
}选择排序思路
相较于前面的几个排序的话。选择排序就相对简单很多了。他大概的思路就是我先走一遍。找到里面最小的,然后进行交换与头点交换,交换了之后我再走,但是我就不计算头节点了我再找次的,然后一直走,这样的话就按这顺序就排序了。但是如果只找小的话,其实效率也不是很高,我们可以在顺便把大的也找出来,这样的话,大家想一想是不是更快一些了?下面的图片只有小。
大家看了上面的图片的话,可能对更好理解我上面说的,走一遍找最小的,然后再走找次小,一直到走完整个数组。
选择排序的实现
因为选择排序的思路都比较简单,那么实现的话肯定也不是很难,所以嘞我们接下来就来写写。我们先来想一想,选择排序要用到什么,因为我们是找最大和最小的,那么我们肯定要创建两个来记录吧。但是在此之前。我们想想记录之前肯定要循环啊。不然的话不就是单趟排序了嘛。但是我们传递过来的数据中并没有把元素的头节点下标和尾节点下标发过来。但是好歹发了数元素个数,那么我们也可以简单的找到头节点和尾节点下标。数组都是从零开始的吧?然后我们为今年的下标都是元素个数减一,这样大家都是比较能理解的吧。
确立循环次数:我们上面说过,我们找到了头结点的下标和尾节点的下标,我们只需要当头节点下标小于等于尾节点的下标,那么就可以再次循环。
int l = 0;
int r = sz - 1;
while (l <= sz)
{循环内容:前面我们说过,我们创建两个数来记录最大的下标和最小的下标,那么我们需要在循环前面创建一个。大家需要注意一下,我们这个设置的b1等于l他们都不是等于1。只是我在这里设置的时候,它长得比较像1而已。如果我们设置一的话,我们都已经排过了,后面还排那岂不是就是有问题了。
int be = 1;
int end = 1;
for (int i = l; i <= sz; i++)
{循环比较:那我们很简单be来记录最小的,end是记录最大的。我然后当他们都找到了最大和最小的时候,那么就开始交换。最小的很简单,只需要他和头节点交换就可以了。但是很有可能就是be还等于原本的没变,就是原本处所处的地方就是最小的。那么我们是不是需要再判断一下?如果是这样的话,我们需要交换一下。然后当都交换了之后,我们再加加减减,这样我们就一直循环,直到最后这样选择排序就结束了。
if (a[be] > a[i])
{
be = i;
}
if (a[end] < a[i])
{
end = i;
}
Swap(&a[l], &a[be]);
if (be = 1)
{
end = be;
}
Swap(&a[r], &a[end]);
l++;
r--;
}总结
选择排序其实还是比较简单的,就只需要多走几遍。数最大或者最小,然后交换,然后再循环。次大或次小,然后一直交换,交换到最后,那么就交换完了。只需要大家如果稍微要注意一下,就是如果你是找最大和最小的同时进行的话,需要判断一下最小的地方,是不是?最开始的地方就是最小的需要判断一下。然后好了,上面就是今天想与大家分享的规定排序和选择排序的所有内容了。
void xuan1(int *a, int sz)
{
int l = 0;
int r = sz - 1;
while (l <= sz)
{
int be = 1;
int end = 1;
for (int i = l; i <= sz; i++)
{
if (a[be] > a[i])
{
be = i;
}
if (a[end] < a[i])
{
end = i;
}
Swap(&a[l], &a[be]);
if (be = 1)
{
end = be;
}
Swap(&a[r], &a[end]);
l++;
r--;
}
}
}














 3181
3181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









