






python基础
1.0.0:字符串
1.0修改字符串大小写
name = "new bee "
name.title() # 名称首字母大写
name.upper() #名称全部大写
name.lower() #名称全部小写
1.1字符串中引用变量
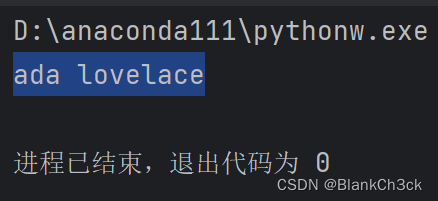
first_name = "ada"
last_name = "lovelace"
full_name = f"{first_name} {last_name}"
print(full_name)
结果如下:
1.2使用制表符或换行符来添加空白
print("Python")
print("\n")
print("\tPython")

1.3删除空白
lstrip和strip函数都可删除空白
example = (' python ')
print(example)
print("\n")
print(example.strip())
print(example.lstrip())

2.0.0列表
一个简单的列表:
2.1.0访问列表元素
列表是一个集合,想要访问元素,只需要输入元素索引就可以找到对应元素
注意:索引从0开始,并不是从1开始!
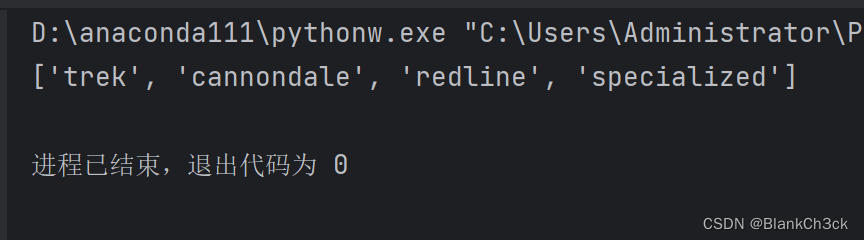
!bicycles = ['trek', 'cannondale', 'redline', 'specialized'] print(bicycles[0])
例如: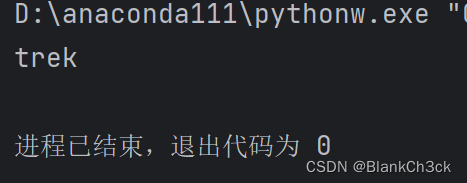
2.2.0更改列表中的元素
2.2.1修改列表元素
直接命令修改
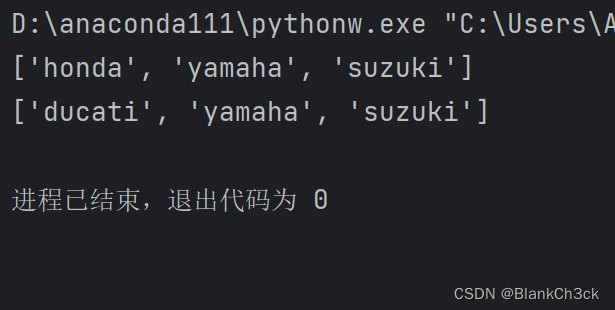
motorcycles = ['honda', 'yamaha', 'suzuki'] print(motorcycles) motorcycles[0] = 'ducati' print(motorcycles)
2.2.2在列表添加新元素
.append("添加的新元素") #直接将元素加到列表末尾
.insert("索引","修改后的元素") #直接改目标元素
2.2.3从列表删除元素
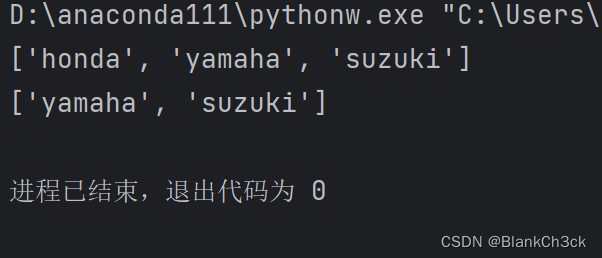
法一:del
motorcycles = ['honda', 'yamaha', 'suzuki'] print(motorcycles) del motorcycles[0] #可以更改索引删除目的元素 print(motorcycles)
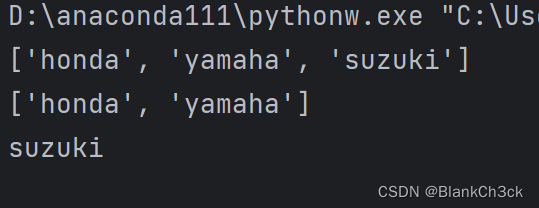
法二:pop()
#如果使用了pop()函数,元素被弹出就不在列表内了
motorcycles = ['honda', 'yamaha', 'suzuki'] print(motorcycles) popped_motorcycle = motorcycles.pop() #括号内可以填入目的元素索引 print(motorcycles) print(popped_motorcycle)
法三:remove #直接移除目的元素,不需要索引
motorcycles = ['honda', 'yamaha', 'suzuki', 'ducati']
print(motorcycles)
motorcycles.remove('ducati')
print(motorcycles)

2.3.0组织列表
2.3.2用sorted函数对列表临时排序 #不改变原来序列
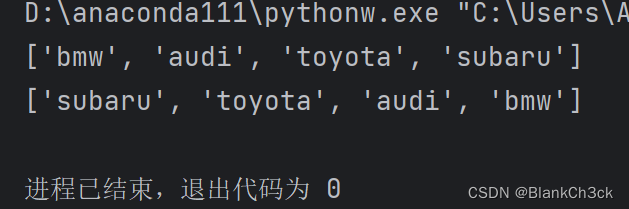
2.4.0 .reverse函数实现倒序 #永久改变序列,但是可以恢复
cars = ['bmw', 'audi', 'toyota', 'subaru'] print(cars) cars.reverse() print(cars)
2.4.1 len()函数确定列表长度
2.5.0 切片
players = ['charles', 'martina', 'michael', 'florence', 'eli'] print(players[1:3])
# [ ]中输入起始元素索引和结束元素索引就能提取之间的子集
# 如果从起始索引读到末尾,末尾可省略。
同样从起始读到结束值索引起始索引处也可以省略

3.0.0循环
# 可以结合C语言比较学习,两者相似,原理不变;
记录比较有意义的用循环的题目
A:简单的九九乘法表
for i in range(1, 10):
for j in range(1, i+1):
print("%d*%d=%d" % (i, j, i*j), end=" ")
pass
print()
pass
i += 1
pass
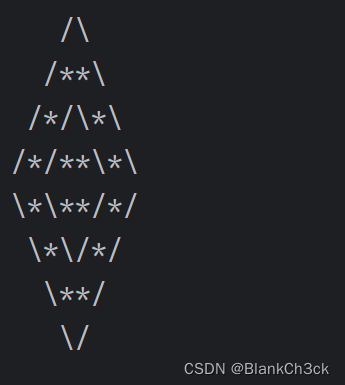
B:用循环画图
for i in range(1, 5):
for j in range(1, 9):
a = i + j
if a < 5 or j >= i+5:
print(" ", end='')
elif j < 5 and a % 2 == 0:
print("*", end='')
elif j < 5 and a % 2 != 0:
print("/", end='')
elif j >= 5 and a % 2 == 0:
print("\\", end='')
else:
print("*", end='')
print(" ")
for i in range(5, 9):
for j in range(1, 9):
a = i + j
if i-j > 4 or i+j > 13:
print(" ", end='')
elif j<5 and a % 2 == 0:
print("\\", end='')
elif j < 5 and a % 2 != 0:
print("*", end='')
elif j >= 5 and a % 2 == 0:
print("*", end='')
else:
print("/", end='')
print(" ")
4.0.0元组
#元组不可改变!
4.1.0 虽然不能修改元组的元素,但可以给存储元组的变量赋值。因此,如果要修改前述矩形的尺寸,可重新定义整个元组:
dimensions = (200, 50)
print("Original dimensions:")
for dimension in dimensions:
print(dimension)
dimensions = (400, 100)
print("\nModified dimensions:")
for dimension in dimensions:
print(dimension)

5.0.0 字典
一个简单的字典
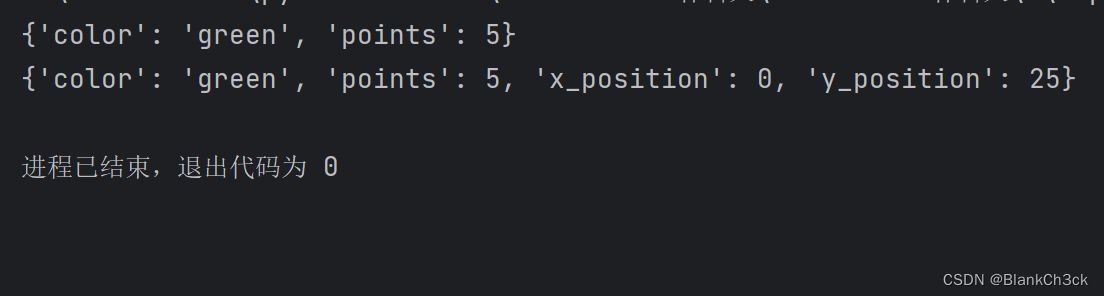
alien_0 = {'color': 'green', 'points': 5}
print(alien_0['color'])
print(alien_0['points'])

5.1.0添加键值对 #添加字典内容
alien_0 = {'color': 'green', 'points': 5}
print(alien_0)
alien_0['x_position'] = 0
alien_0['y_position'] = 25
print(alien_0)
5.1.1修改字典中的值直接修改
如:alien_0 = {'color': 'green'}
#创建空字典直接alien_0 = {}#字典名加空大括号
5.1.2删除键值对 del函数
如:del alien_0['points'] # del 字典名[ 键名 ]
Example:
模拟食堂点餐系统:
现有一些菜表,在客人选完菜之后输出应付的金额,选菜时输入序号即可
序号 菜名 价格/元
1 回锅肉 5
2 酸辣汤 3
3 红烧肉 7
4 糖醋排骨 7
5 麻婆豆腐 3
6 宫保鸡丁 4
7 水煮鱼 7
8 麻辣香锅 8
9 干煸豆角 3
10 清蒸鲈鱼 7
11 鱼香肉丝 3
12 蚂蚁上树 3
13 宫保虾球 5
14 米饭 1
def printmenu():
print("==========Menu========")
print("=Num====name=====price=")
for i in range(len(menu1)):
print(f" {i+1}\t\t{menu1[i]}\t\t\t{price1[i]}")
print("============================")
print("===Ordering instructions====")
print("1.Input at the time of ordering (drink1,pellet1),(drink2,pellet2),…… ,input 0 without adding pellet")
print("2.Use the form (drink1,pellet1,pellet2) when ordering multiple ingredients")
def order(meal):
global choose
choose = ""
menu = []
money = 0
for i in meal:
if i[1]:
menu_append = menu1[i[0]-1]+"+"+"+".join([menu2[i[j]] for j in range(1,len(i))])
else:
menu_append = menu1[i[0]-1]
menu.append(menu_append)
money += price1[i[0] - 1]+sum([price2[i[j]] for j in range(1,len(i))])
menu = ','.join(menu)
choose = input("Whether you need an extra meal(y/n):")
while choose == "y":
input_meal = input("Please enter your pellet in drink:")
meal1 = [tuple(map(int, i.strip('()').split(','))) for i in input_meal.split('),')]
menu_1,money_1 = order(meal1)
menu+=','+menu_1;money+=money_1
return menu,money
if __name__ =="__main__":
global menu1,price1,menu2,prince2
menu1 = ["回锅肉", "酸辣汤", "红烧肉", "糖醋排骨", "麻婆豆腐", "宫保鸡丁", "水煮鱼", "麻辣香锅", "干煸豆角",
"清蒸鲈鱼","鱼香肉丝", "蚂蚁上树", "宫保虾球", "米饭"]
price1 = [ 5, 3, 7, 7, 3, 4, 7, 8, 3, 7, 3, 3, 5, 1]
printmenu()
input_meal = input("Please enter your menu:")
meal = [tuple(map(int, i.strip('()').split(','))) for i in input_meal.split('),')]
menu,money = order(meal)
print(f"您点了{menu},总共支付{money}元")

机器学习
一,安装
matplotlib安装
使用pip安装:pip install matplotlib
使用 conda 安装:conda install -c conda-forge matplotlib
二,matplotlib
1.0绘图
#pyplot可视化
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
plt.show()

Question:为什么 x 轴范围为 0-3 而 y 轴范围为 从 1-4。由于 python 范围从 0 开始,默认的 x 向量具有 与 y 长度相同但从 0 开始;因此,x 数据是 。[0, 1, 2, 3]
也可以截取部分区间图像画出
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.ylabel('some numbers')
plt.show()

2.0#不同绘图风格的图像
常用color
| 颜色 | 说明 | 颜色 | 说明 |
|---|---|---|---|
| r | 红色 | g | 绿色 |
| b | 蓝色 | w | 白色 |
| c | 青色 | m | 洋红 |
| y | 黄色 | k | 黑色 |
| 英文名称版 | |||
 | |||
| RGB颜色版 | |||
标记风格
| 标记字符 | 说明 | 标记字符 | 说明 |
|---|---|---|---|
| '.' | 点标记 | ',' | 像素标记(极小点) |
| 'v' | 倒三角标记 | ’^‘ | 上三角标记 |
| '>' | 右三角标记 | '<' | 左三角标记 |
| '1' | 下花三角标记 | '2' | 上花三角标记 |
| '3' | 左花三角标记 | '4' | 右花三角标记 |
| 'o' | 实心圈标记 | 's' | 实心方形标记 |
| 'p' | 实心五角标记 | '*' | 星形标记 |
| 'h' | 竖六边形标记 | 'H' | 横六边形标记 |
| '+' | 十字标记 | 'x' | x标记 |
| 'D' | 菱形标记 | 'd' | 瘦菱形标记 |
线条样式
| 样式 | 说明 |
|---|---|
| ’-‘ | 实线 |
| ’--‘ | 虚线 |
| ’-.‘ | 点划线 |
| ':' | 点虚线 |
3.0注释
添加标题
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-4, 4, 10005)
y = 5 * (x + 4.2) * (x + 4.) * (x - 2.5)
plt.title('The handsomeboy‘s number of big data')
plt.plot(x, y, c = 'm')
plt.show()
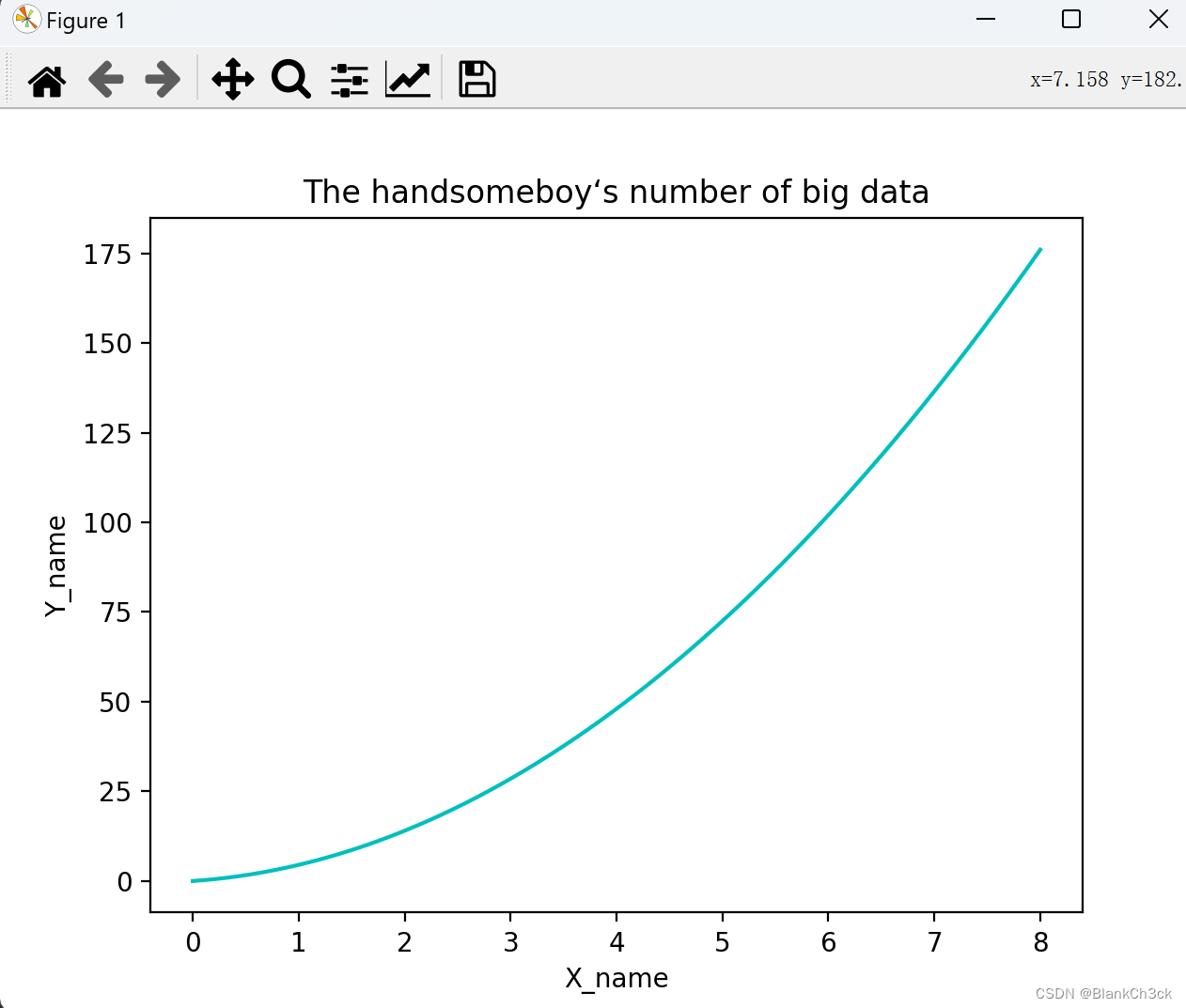
为坐标轴添加标签
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 8, 1000)
y = 2.0 * x + 0.5 * 5 * x ** 2
plt.title('The handsomeboy‘s number of big data')
plt.xlabel('X_name')
plt.ylabel('Y_name')
plt.plot(x, y, c='c')
plt.show()
4.0图像类型(图像类型有很多,只学了一部分,可以查看pie(x) — Matplotlib 3.8.2 documentation)
成对数据
成对图(x,y), 表格(var_0,⋯,var_n), 和功能性的f(x)=y数据。

统计分布
数据集中至少一个变量的分布图。其中一些 方法还计算分布。

a:折线图
import matplotlib.pyplot as plt import numpy as np x = [5, 10, 15, 20, 25] y = [3, 7, 4, 5, 3] plt.plot(x, y) plt.savefig(r"D:/Kongquanyuan6")#图片存储地址 plt.show()

b:
散点图
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('_mpl-gallery')
# 随机生成数据,用seed确保随机数不再改变
np.random.seed(3)
x = 4 + np.random.normal(0, 2, 24)
y = 4 + np.random.normal(0, 2, len(x))
# 大小和颜色:
sizes = np.random.uniform(15, 80, len(x))
colors = np.random.uniform(15, 80, len(x))
fig, ax = plt.subplots()
ax.scatter(x, y, s=sizes, c=colors, vmin=0, vmax=100)
ax.set(xlim=(0, 8), xticks=np.arange(1, 8),
ylim=(0, 8), yticks=np.arange(1, 8))
plt.show()

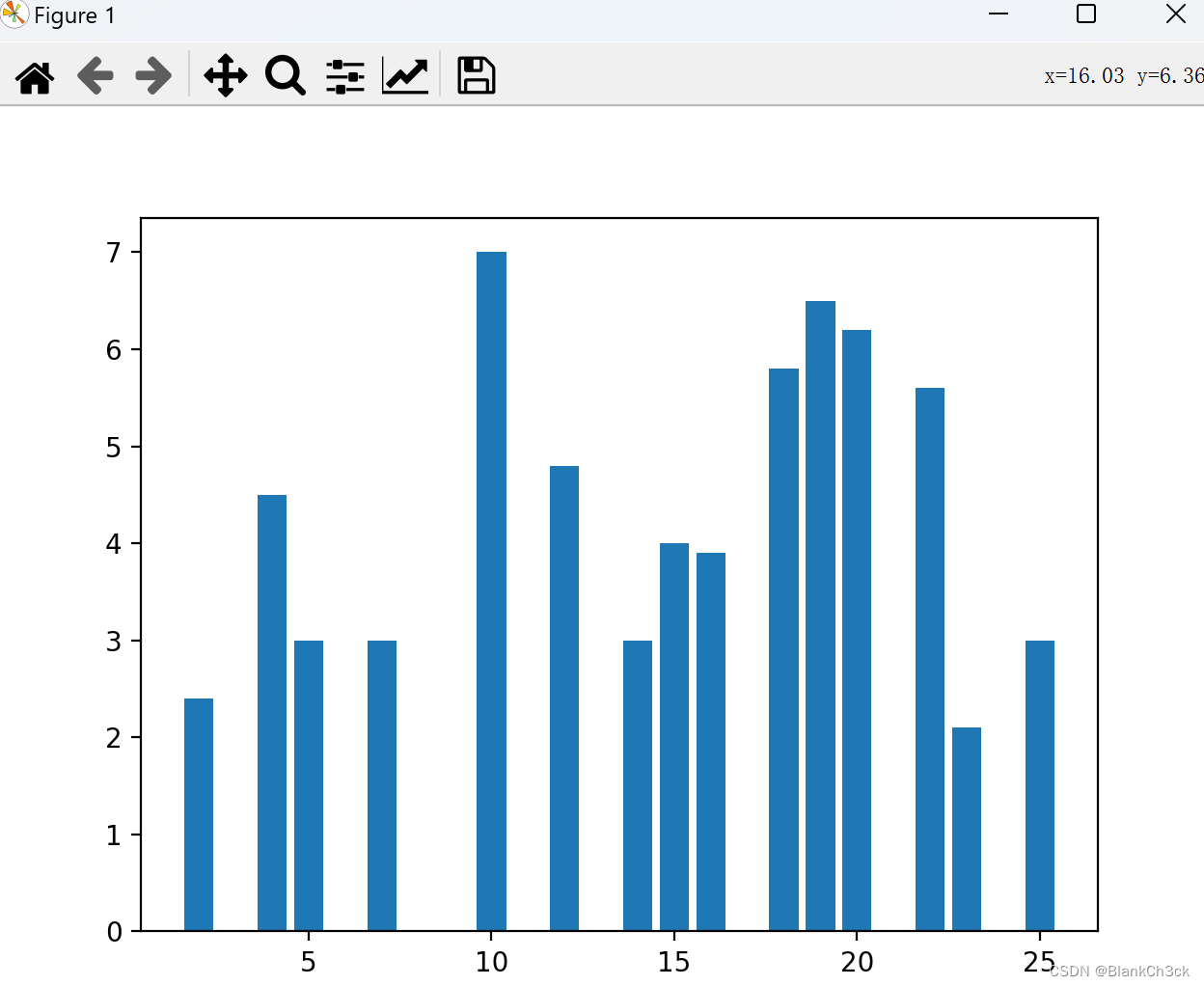
c:柱状图
x: 柱状图中的横坐标点
list height: 柱状图对应每个横坐标的高度值
width: 柱状图的宽度,默认值为0.8
label: 每个数据样本对应的label,后面调用legend()函数可以显示图例
alpha: 透明度 align:每个柱状图的对齐方法
color:选择柱状图的颜色
import matplotlib.pyplot as plt x = [5, 10, 15, 20, 25, 7, 4, 2, 4, 12, 23, 14, 19, 22, 19, 18, 20, 16] y = [3, 7, 4, 5, 3, 3, 2.3, 2.4, 4.5, 4.8, 2.1, 3, 4.5, 5.6, 6.5, 5.8, 6.2, 3.9] plt.bar(x,y) plt.savefig(r"D:/Kongquanyuan6") plt.show()
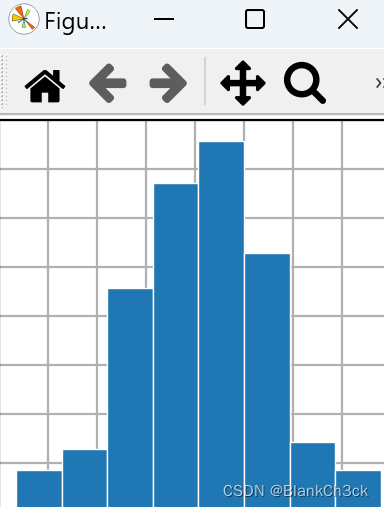
d:直方图
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('_mpl-gallery')
# make data
np.random.seed(1)
x = 4 + np.random.normal(0, 1.5, 200)
# plot:
fig, ax = plt.subplots()
ax.hist(x, bins=8, linewidth=0.5, edgecolor="white")
ax.set(xlim=(0, 8), xticks=np.arange(1, 8),
ylim=(0, 56), yticks=np.linspace(0, 56, 9))
plt.show()
e:饼图
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('_mpl-gallery-nogrid')
# make data
x = [1, 2, 3, 4]
colors = plt.get_cmap('Blues')(np.linspace(0.2, 0.7, len(x)))
# 创建数据:x 是一个包含四个元素的列表,colors 是一个根据 'Blues' 调色板生成的颜色数组,
# 颜色的范围从浅蓝到深蓝,颜色的数量与 x 中元素的数量相同
# plot
fig, ax = plt.subplots()
ax.pie(x, colors=colors, radius=3, center=(4, 4),
wedgeprops={"linewidth": 1, "edgecolor": "white"}, frame=True)
# 创建一个图形和一个坐标轴,然后使用 ax.pie 方法绘制饼图。
# 传入参数包括数据 x,颜色数组 colors,饼图的半径、中心坐标、楔形属性(边框宽度和颜色),以及是否显示图框
ax.set(xlim=(0, 8), xticks=np.arange(1, 8),
ylim=(0, 8), yticks=np.arange(1, 8))
plt.show()

5.0简单的数学图像
画一个sin(x)图像 import matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 2 * np.pi, 200) y = np.sin(x) fig, ax = plt.subplots() ax.plot(x, y) plt.show()
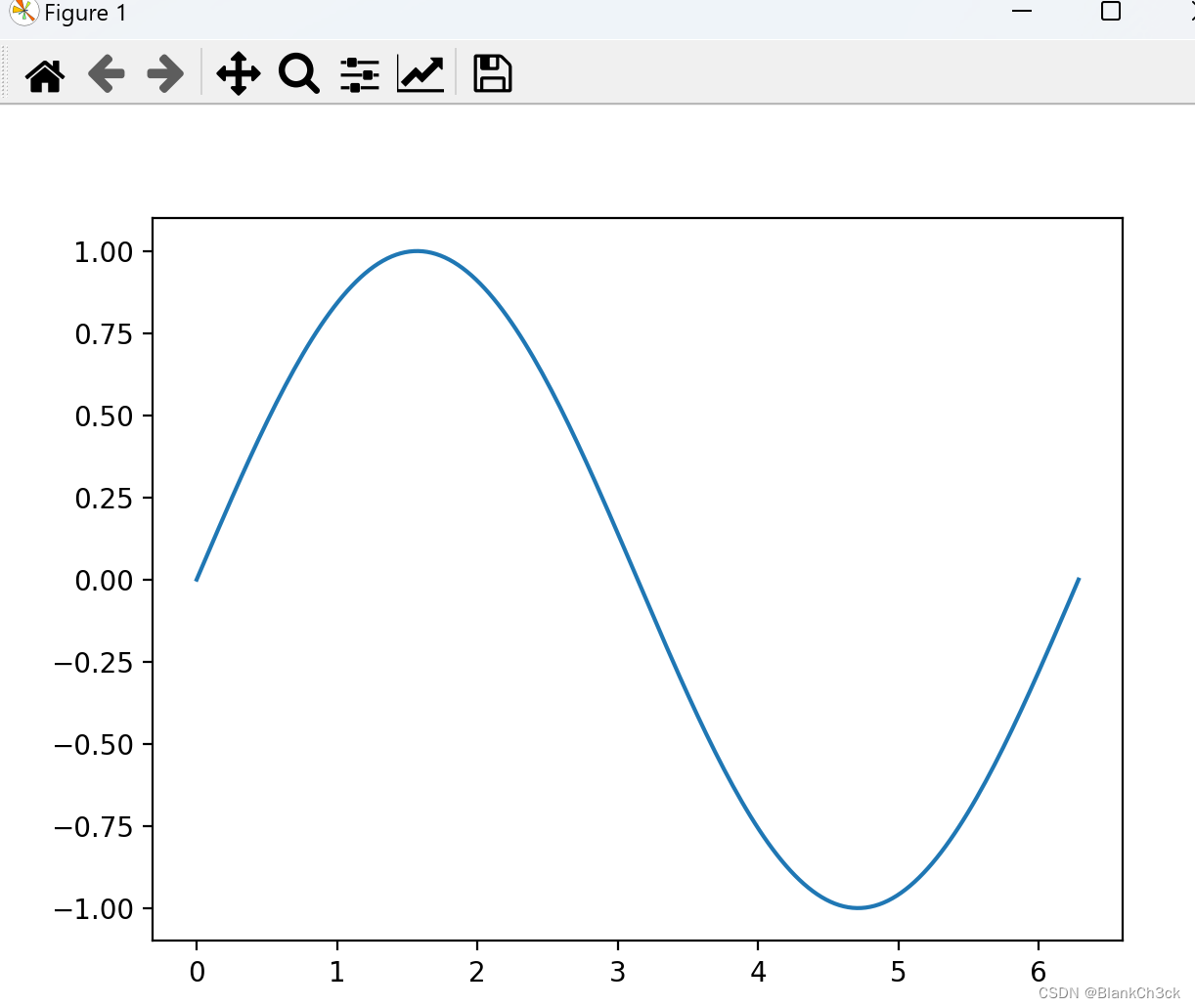
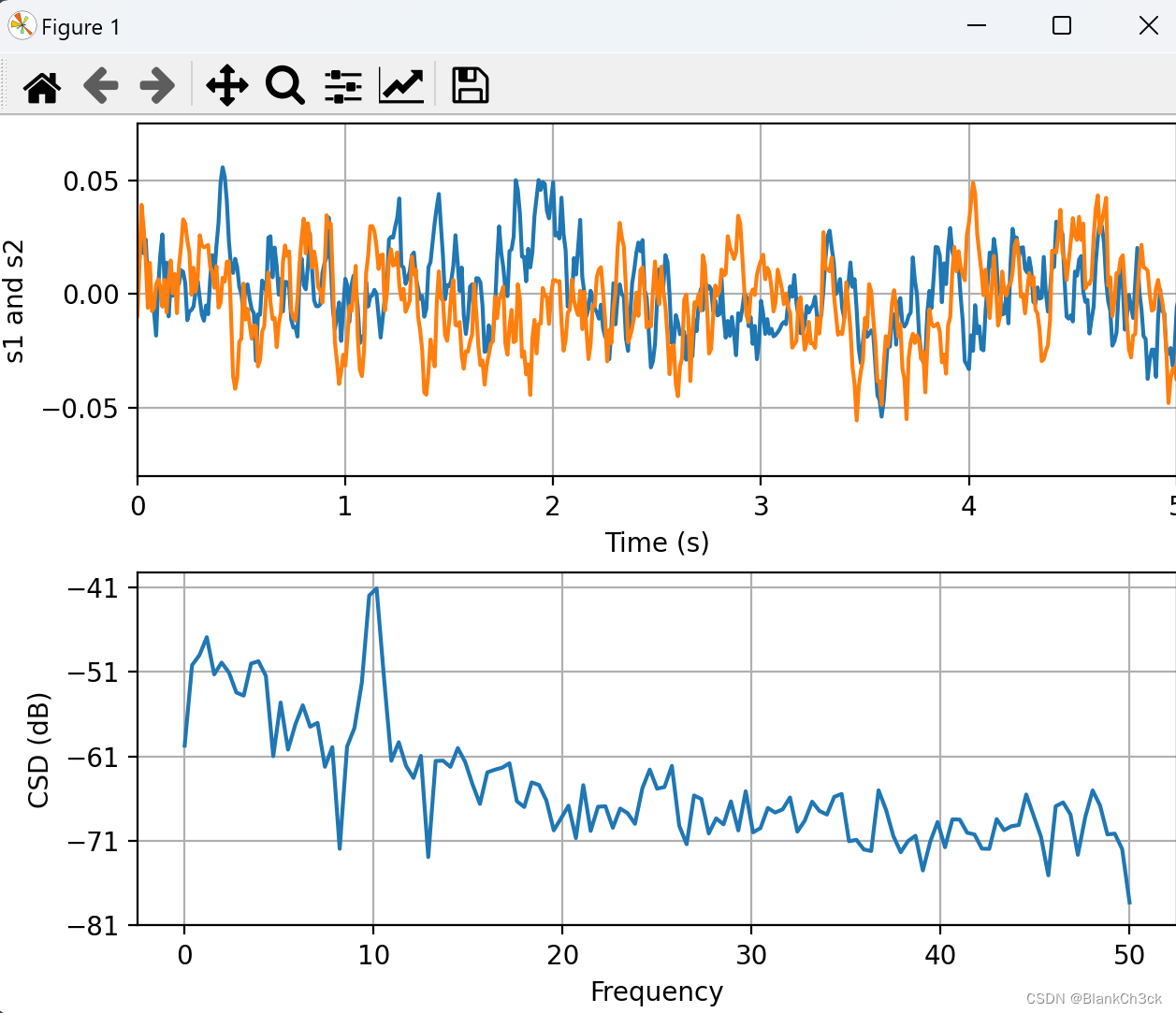
数学图像pro max
import matplotlib.pyplot as plt
import numpy as np
fig, (ax1, ax2) = plt.subplots(2, 1, layout='constrained')
dt = 0.01
t = np.arange(0, 30, dt)
# Fixing random state for reproducibility
np.random.seed(19680801)
nse1 = np.random.randn(len(t)) # white noise 1
nse2 = np.random.randn(len(t)) # white noise 2
r = np.exp(-t / 0.05)
cnse1 = np.convolve(nse1, r, mode='same') * dt # colored noise 1
cnse2 = np.convolve(nse2, r, mode='same') * dt # colored noise 2
# two signals with a coherent part and a random part
s1 = 0.01 * np.sin(2 * np.pi * 10 * t) + cnse1
s2 = 0.01 * np.sin(2 * np.pi * 10 * t) + cnse2
ax1.plot(t, s1, t, s2)
ax1.set_xlim(0, 5)
ax1.set_xlabel('Time (s)')
ax1.set_ylabel('s1 and s2')
ax1.grid(True)
cxy, f = ax2.csd(s1, s2, 256, 1. / dt)
ax2.set_ylabel('CSD (dB)')
plt.show()
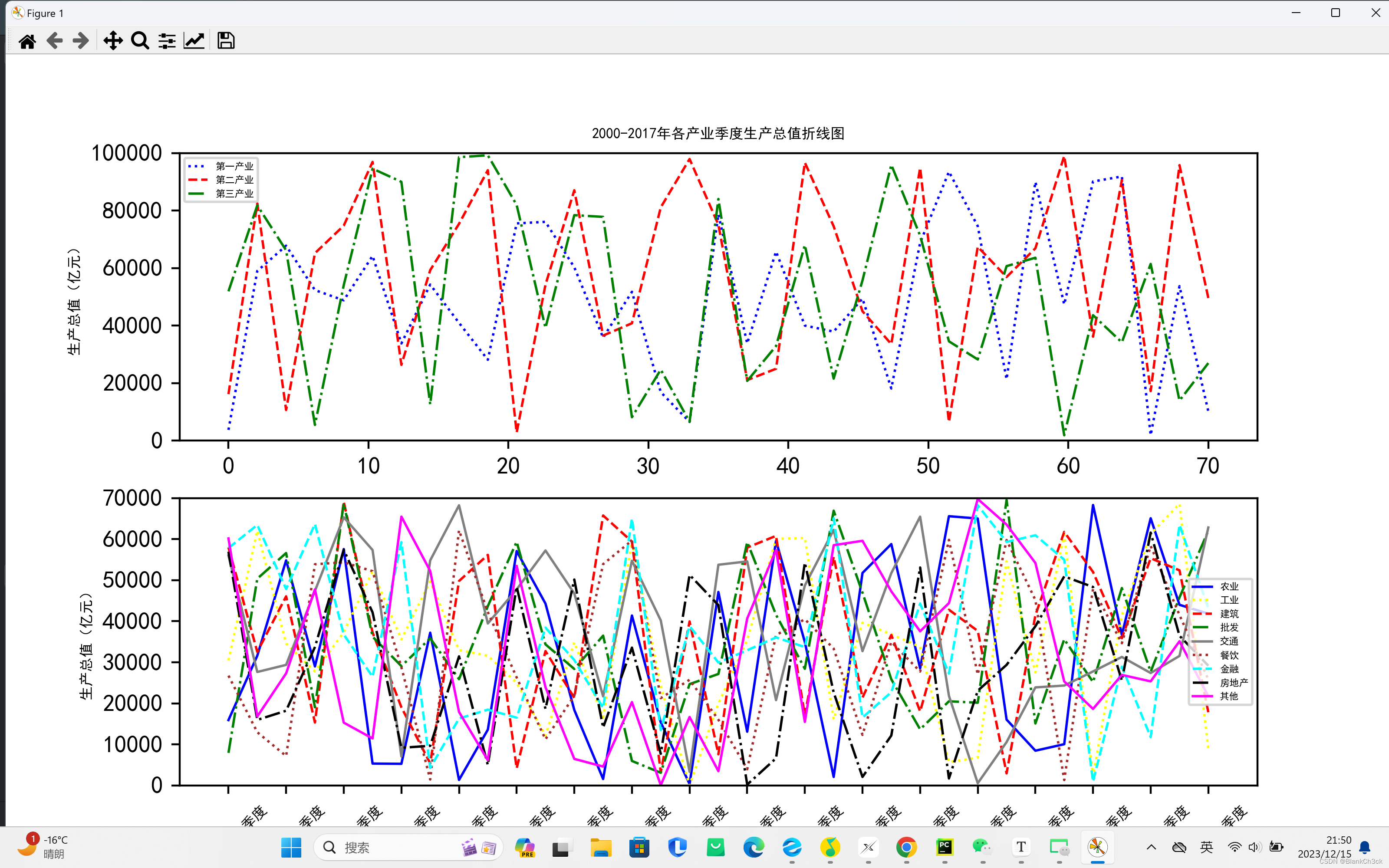
pro max ultra
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示问题
huaban = plt.figure(figsize=(10, 5), dpi=200)
p1 = huaban.add_subplot(211) #设置两个子图,排列方式为两行一列
plt.ylim(0, 100000) #设置y坐标的范围
x1 = np.linspace(0, 70, 35) #设置三组x,y
y1 = np.random.randint(0, 100000, 35) #使用np.random.randint(初始值,结束值,个数)输出随机数
x2 = np.linspace(0, 70, 35)
y2 = np.random.randint(0, 100000, 35)
x3 = np.linspace(0, 70, 35)
y3 = np.random.randint(0, 100000, 35)
plt.title('2000-2017年各产业季度生产总值折线图', fontsize=6)
plt.ylabel("生产总值(亿元)", fontsize=6)
L1, = p1.plot(x1, y1, color='blue', ls=':', lw=1)
L2, = p1.plot(x2, y2, color='red', ls='--', lw=1)
L3, = p1.plot(x3, y3, color='green', ls='-.', lw=1)
plt.legend(handles=[L1, L2, L3], labels=['第一产业', '第二产业', '第三产业'], loc='upper left', fontsize=4) #handles 表示所要处理的线,参数为列表
p2 = huaban.add_subplot(212) #子图2的编写
plt.ylim(0, 70000)
x4 = np.linspace(0, 17, 35) #设置9组x,y(y为随机数)
y4 = np.random.randint(0, 70000, 35) #使用np.random.randint(初始值,结束值,个数)输出随机数
x5 = np.linspace(0, 17, 35) #np.random.rand(个数)一般输出的随机数一般范围在-1.96~1.96之间
y5 = np.random.randint(0, 70000, 35)
x6 = np.linspace(0, 17, 35)
y6 = np.random.randint(0, 70000, 35)
x7 = np.linspace(0, 17, 35)
y7 = np.random.randint(0, 70000, 35)
x8 = np.linspace(0, 17, 35)
y8 = np.random.randint(0, 70000, 35)
x9 = np.linspace(0, 17, 35)
y9 = np.random.randint(0, 70000, 35)
x10 = np.linspace(0, 17, 35)
y10 = np.random.randint(0, 70000, 35)
x11 = np.linspace(0, 17, 35)
y11 = np.random.randint(0, 70000, 35)
x12 = np.linspace(0, 17, 35)
y12 = np.random.randint(0, 70000, 35)
plt.ylabel("生产总值(亿元)", fontsize=6)
_xtick_labels = ["200{}年第一季度".format(i) for i in range(10)] #设置x轴下标
_xtick_labels += ["201{}年第一季度".format(i) for i in range(8)]
plt.xticks(list(x4)[::2], _xtick_labels[::1], rotation=45, fontsize=6) #fontsize表示字体大小,rotation表示旋转角度
plt.yticks(np.linspace(0, 70000, 8))
D1, = p2.plot(x4, y4, color='blue', lw=1, label='农业') #定义9条线[D1, D2, D3, D4, D5, D6, D7, D8, D9]
D2, = p2.plot(x5, y5, color='yellow', ls=':', lw=1, label='工业')
D3, = p2.plot(x6, y6, color='red', ls='--', lw=1, label='建筑')
D4, = p2.plot(x7, y7, color='green', ls='-.', lw=1, label='批发')
D5, = p2.plot(x8, y8, color='grey', lw=1, label='交通')
D6, = p2.plot(x9, y9, color='brown', ls=':', lw=1, label='餐饮')
D7, = p2.plot(x10, y10, color='cyan', ls='--', lw=1, label='金融')
D8, = p2.plot(x11, y11, color='black', ls='-.', lw=1, label='房地产')
D9, = p2.plot(x12, y12, color='magenta', lw=1, label='其他')
plt.legend(handles=[D1, D2, D3, D4, D5, D6, D7, D8, D9]) #handles 表示所要处理的线,参数为列表
plt.legend(labels=['农业', '工业', '建筑', '批发', '交通', '餐饮', '金融', '房地产', '其他'],loc='center right', fontsize=4)
plt.savefig(r"D:Kongquanyuan6")
plt.show()
三,numpy
3.1.0
numpy安装:pip install numpy
3.1.1
要创建 NumPy 数组,可以使用函数np.array()
import numpy as np a = np.array([1, 2, 3]) print(a)
可以这样可视化您的数组:

3.1.2数组填充0
import numpy as np a = np.zeros(2) print(a) 同理
3.1.3填充了1的数组np.ones(2)
3.1.4 empty 创建一个空数组np.empty(2)
3.1.5包含一系列均匀间隔的数组。去做这个, 您将指定第一个数字,最后一个数字,步长。
import numpy as np a = np.arange(2, 9, 2) print(a)
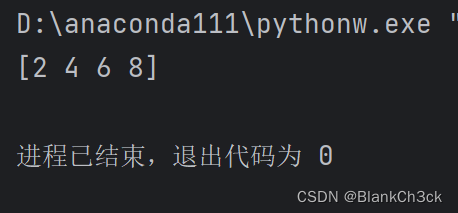
3.1.6 np.linspace() 创建一个数组 以指定间隔线性排列:
3.1.7 np.arange()创建等差数组,指定步长(数量自动计算) step:步长,默认为1
3.1.8 np.logspace()创建等比数组,生成以10的N次幂的数据 num:要生成的等比数组数量,
默认为50
3.1.9生成随机数组np.random
3.2.0 从现有数组中生成
data1 = np.array(data)
data2 = np.asarray(data)
#np.array和np.asarray的区别
import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a) a1 = np.array(a) a2 = np.asarray(a) a[0][0] = 100 print(a1) print(a2)

类似于深拷贝与浅拷贝,可以看到数组a1使用array进行复制,将a的原始数据拷贝过来,对于数组a中的元素改变,对数组a1的元素没有影响,数组a2使用asarray进行复制,对于数组a中的元素改变,数组a2的元素也跟着数组a中的元素改变而改变。
3.3.0正态分布
第一种:np.random.randn
np.random.randn(d0,d1,d2,……,dn)
功能:从标准正态分布中返回一个或多个样本值
第二种:np.random.normal
np.random.normal(loc = 0.0,scale = 1.0,size = None)
loc:float 此概率分布的均值(对应整个分布的中心) scale:float 此概率分布的标准差(对应于分布的宽度,scale值越大越矮胖,scale值越小越瘦高) size:int or tuple of ints 输出的shape,默认为None,只输出一个值
第三种:np.random.standard_normal
np.random.standard_normal(size = None)
返回指定形状的标准正态分布的数组
3.3.1 均匀分布
第一种:np.random.rand
np.random.rand(d0,d1,d2,……,dn)
返回[0.0,1.0)内的一组均匀分布的数
第二种:np.random.uniform
np.random.uniform(low = 0.0,high = 1.0,size = None)
从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high low:采样下界,float类型,默认值为0 high:采样上界,float类型,默认值为1 size:输出样本数目,为int或tuple类型,缺少时输出1个值。例如:size=(m,n,k)则输出mnk个样本 返回值:ndarray类型,其形状和参数与size中定义的一致
第三种:np.random.randint
np.random.randint(low, high = None,size = None,dtype = 'i')
从一个均匀分布中随机采样,生成一个整数或N维整数数组 取数范围:若high不为None时,取(low,high)之间的随机整数,否则取值[0,low)之间随机整数
3.3.2类型修改
ndarray.astype
ndarray.astype(type)
返回修改类型之后的数组
ndarray.tostring和ndarray.tobytes
ndarray.tostring([order]) ndarray.tobytes([order])
构造包含数组中原始数据字节的python字节
3.3.4 数组的去重
np.unique()
下面用一个例子来帮助理解
>>>data = np.array([[1,2,2],[4,5,6]]) >>>data1 = np.unique(data) >array([1, 2, 4, 5, 6])
3.4.0 ndarray运算
3.4.1 逻辑运算
3.4.2 np.logical_and
np.logical_and(condition1,condition2)
condition:条件 当两个条件同时满足时返回Ture
np.logical_or
np.logical_or(condition1,condition2)
当其中一个条件满足时返回Ture
3.4.3 np.all
np.all()
所有条件都满足要求返回True,有任一个不满足返回False
3.4.4 np.any
np.any()
任一个条件满足要求返回True
3.5.0 统计指标
| 方法 | 作用 |
|---|---|
| np.min(ndarray,axis) | 查询所有行或所有列的最小值 |
| np.max(ndarray,axis) | 查询所有行或所有列的最大值 |
| np.median(ndarray,axis) | 查询所有行或所有列的中位数 |
| np.mean(ndarray,axis) | 查询所有行或所有列的平均值 |
| np.std(ndarray,axis,dtype) | 查询所有行或所有列的标准差 |
| np.var(ndarray,axis,dtype) | 查询所有行或所有列的方差 |
| np.ardmax(ndarray) | 查询最大值的位置 |
| np.ardmin(ndarray) | 查询最小值的位置 |
4.0.0 Pandas
Pandas的安装pip install pandas
4.1.0
三种主要的数据结构
| 数据结构 | 描述 |
|---|---|
| Series | 一维数据结构 |
| DataFrame | 二维数据结构 |
| MultiIndex | 三维数据结构 |
| Panel | 三维数据结构(MultiIndex老版本) |
DataFrame
DataFrame 是一个表格型的数据结构,DataFrame 既有行索引,又有列索引。
index:行索引 column:列索引
DataFrame切片
对于 DataFrame 的切片操作,因为是表格型,因此可以分为行切片,列切片,行列切片。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=np.random.randint(10,100,size=(4,6)),
index=['小明','小红','小黄','小绿'],
columns=['语文','数学','英语','化学','物理','生物']
)
print(df)

使用loc:只能指定行列索引的名字(先行后列)
使用iloc:可以通过索引的下标去获取
使用ix组合索引:下标和名称组合做引
赋值
dataframe['a'] = b
dataframe.a = b
a代表某一列或者某一行的名称
b代表某个值
DataFrame排序
dataframe.sort_values(by = ,ascending =)
单个或多个键排序
by:指定排序参考的键
ascending:默认升序
ascending = False 降序
ascending = True 升序
Series排序
进行值排序 dataframe.sort_values(ascending = True)
进行索引排序 series.sort_index()
DataFrame运算
基本运算
元素相加,维度相等时找不到元素默认用fill_value
dataframe.add(dataframe2, fill_value = None, axis = 1)
元素相减,维度相等时找不到元素默认用fill_value
dataframe.sub(dataframe2, fill_value = None, axis = 1)
元素相除,维度相等时找不到元素默认用fill_value
dataframe.div(dataframe2, fill_value = None, axis = 1)
元素相乘,维度相等时找不到元素默认用fill_value
dataframe.mul(dataframe2, fill_value = None, axis = 1)
统计运算
dataframe.describe()
综合统计包括平均值,最大值,最小值等等
统计函数
| 函数 | 作用 |
|---|---|
| sum | 获取总和 |
| mean | 获取平均值 |
| median | 获取中位数 |
| min | 获取最小值 |
| max | 获取最大值 |
| mode | 获取众数 |
| abs | 获取绝对值 |
| prod | 获取累积 |
| std | 获取标准差 |
| var | 获取方差 |
| idxmax | 获取最大值索引 |
| idxmin | 获取最小值索引 |
累计统计函数
| 函数 | 作用 |
|---|---|
| cumsum | 计算1/2/3/……/n个数的和 |
| cummax | 计算1/2/3/……/n个数的最大值 |
| cummin | 计算1/2/3/……/n个数的最小值 |
| cumprod | 计算1/2/3/……/n个数的积 |
自定义运算
apply(func,axis=0)
func:自定义运算 axis=0默认是列,axis=1为行进行运算
文件读取与文件存储
| 类 | 数据类型 | 读取文件 | 存储文件 |
|---|---|---|---|
| text | CSV | read_csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_json |
| text | Local clipboard | read_clipboard | to_clipboard |
| binary | MS Excel | read_excel | to_excel |
| binary | HDF5 Format | read_hdf | to_hdf |
| binary | Feather Format | read_feather | to_feather |
| binary | Parquet Format | read_parquet | to_parquet |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | -- |
| binary | Python Pickle Format | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQL | Google Big Query | read_gbp | to_gbp |
CSV
read_csv
pd.read_csv(filepath_or_buffer,sep = ',',usecols = None)
filepath_or_buffer:文件路径 sep:分隔符,默认用','隔开 usecols:指定读取的列名,列表形式
to_csv
dataframe.to_csv(path_or_buffer=None,sep = ',',columns = None,header = True,index = True,mode = 'w',encoding = None)
path_or_buf:文件路径 sep:分隔符,默认用','隔开 columns:选择需要的列索引 header:是否写进列索引值 index:是否写进行索引值 mode:'w':重写,'a':追加
合并
pd.concat
pd.concat([data1, data2], axis = 1)
按照行或列进行合并,axis=0为扩展行,axis=1为扩展列















 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









