






APL jdk7 时间:
//创建两个时间对象 // Date d1=new Date(Math.abs(r.nextInt())); // Date d2=new Date(Math.abs(r.nextInt()));
比较时间用getTtime函数
long time1=d1.getTime();
爬虫:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
/* 有如下文本,请按照要求爬取数据。 Java自从95年问世以来,
经历了很多版本,目前企业中用的最多的是Java8和Java11, 因为这两
个是长期支持版本,下一个长期支持版本是Java17,相信在未
来不久Java17也会逐渐登上历史舞台 要求:找出里面所有的JavaXX */
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"
+ "因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//1.获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//2.获取文本匹配器的对象
// 拿着m去读取str,找符合p规则的子串
Matcher m = p.matcher(str);
//3.利用循环获取
while (m.find()){
String s = m.group();
System.out.println(s);
}
}
private static void method1(String str)
{ //Pattern:表示正则表达式
// Matcher: 文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。
// 在大串中去找符合匹配规则的子串。
// 获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//获取文本匹配器的对象
// m:文本匹配器的对象
// str:大串
// p:规则
// m要在str中找符合p规则的小串
Matcher m = p.matcher(str);
//拿着文本匹配器从头开始读取,寻找是否有满足规则的子串
// 如果没有,方法返回false
// 如果有,返回true。在底层记录子串的起始索引和结束索引+1
// 0,4
boolean b = m.find();
//方法底层会根据find方法记录的索引进行字符串的截取
// substring(起始索引,结束索引);包头不包尾
// (0,4)但是不包含4索引
// 会把截取的小串进行返回。
String s1 = m.group();
System.out.println(s1);
//第二次在调用find的时候,会继续读取后面的内容
// 读取到第二个满足要求的子串,方法会继续返回true
// 并把第二个子串的起始索引和结束索引+1,进行记录
b = m.find();
// 第二次调用group方法的时候,会根据find方法记录的索引再次截取子串
String s2 = m.group();
System.out.println(s2);
}
}
正则表达式:
1.校验字符串是否满足规则
2.在一段文本中查找满足要求的内容
//验证一个QQ是否正确 //规则:6~20,0不能在开头 String qq="1234567890"; System.out.println(qq.matches("[1-9]\\d{5,19}"));//[1-9]是第一个数字是1-9,\\d是整数的意思 // {5,19}的意思是后面的5或者到十九位 心得: 拿着一个正确的数据,从左到右依次去写。 13112345678 分成三部分: 第一部分:1 表示手机号码只能以1开头 第二部分:[3-9]表示手机号码第二位只能是3-9之间的 第三部分:\\d{9}表示任意数字可以出现9次,也只能出现9次

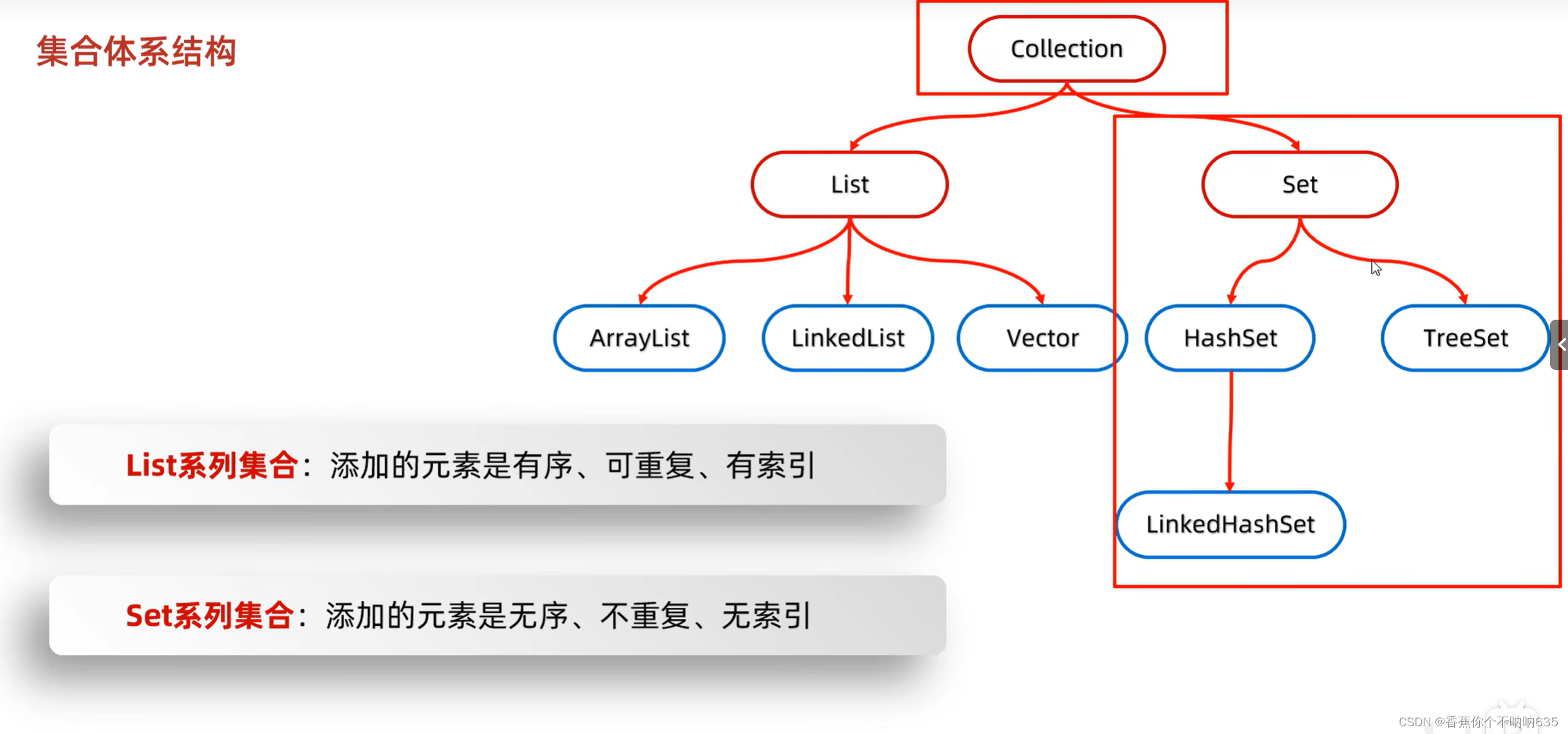
Collection是单列集合,map是双列集合
Collection是一个接口,我们不能直接创建他的对象。
所以,现在我们学习他的方法时,只能创建他实现类的对象。
例如实现类:ArrayList
list有索引,但是方法用的是collection 接口里的,而collection是 list set vector 的共性接口,所以此时不能通过索引删除,只能通过元素的对象进行删除。
eg:
xxx.remove(“aaa”);
匿名内部类只是针对某一个接口的实例化对象,也就是不写接口的实现类,直接采用内部类的方式实现其中方法。这种情况下的实例化方法是不能被其他实现类对象复用的
迭代器遍历:
第一步,利用集合调用方法获取迭代器的对象
Integer<String> it=list.interator();
第二步,用迭代器的对象调用hasNext()方法判断当前位置是否有元素
boolean flag =it.hasNext();
第三步,用迭代器的对象调用next()方法获取元素并移动迭代器
String str =it.next();
注意:迭代器遍历完毕,指针不回复位,如果再遍历,只能再创建一个对象
增强for遍历:
Set<Map.Entry<String, String>> entries = map.entrySet();
//用增强for
for (Map.Entry<String, String> entry : entries) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value); }
Lambda遍历:
//用Lambda表达式
entries.forEach((o)->System.out.println(o.getKey()+"="+o.getValue()));
lambda表达式:
先:从new删到方法名,再形参和方法组之间加个->,然后还可以省略,删掉数据类型,两个参数则小括号不能省略,最后方法体如果只有一行则删掉花括号还有分号变为一行
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key+"="+value);
}
});
删后:
map.forEach((key,value)-> System.out.println(key+"="+value));
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
//初识lambda表达式
Integer[] arr1={3,8,5,7,9,1,4,2};
Integer[] arr2={3,8,5,7,9,1,4,2};
Arrays.sort(arr1, (Integer o1, Integer o2) ->{
return o1 - o2;
}
);
System.out.println(Arrays.toString(arr1));
Arrays.sort(arr2, (o1, o2) ->o1 - o2);
System.out.println(Arrays.toString(arr2));
method(new Swim() {
@Override
public void swimming() {
System.out.println("正在游泳~~~");
}
});
method(
() ->{
System.out.println("正在游泳~~~");
}
);
}
public static void method(Swim s){
s.swimming();
}
}
//一个接口
interface Swim{
public abstract void swimming();
}
//ctrl alt +v 自动生成左边
//ctrl +p可以看看括号里面是什么类型的
map的三种遍历方式:
1.键找值
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Main {
public static void main(String[] args) {
//创建map对象
Map<String,String> map=new HashMap<>();
//添加元素
map.put("111","一一一");
map.put("222","二二二");
map.put("333","三三三");
Set<String> keys = map.keySet();
for (String key : keys) {
// System.out.println(key);
String v=map.get(key);
System.out.println(key+"="+v);
}
}
}
2.键值对
map.entrySet()是获得键值对对象的意思
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Main {
public static void main(String[] args) {
//键值
Map<String,String> map=new HashMap<>();
map.put("111","一一一");
map.put("222","二二二");
map.put("333","三三三");
Set<Map.Entry<String, String>> entries = map.entrySet();
//是获得键值对对象的意思,将其放入Set集合中
for (Map.Entry<String, String> entry : entries) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);
}
}
}
3.结合lambda遍历map
map.forEach((key,value)-> System.out.println(key+"="+value));
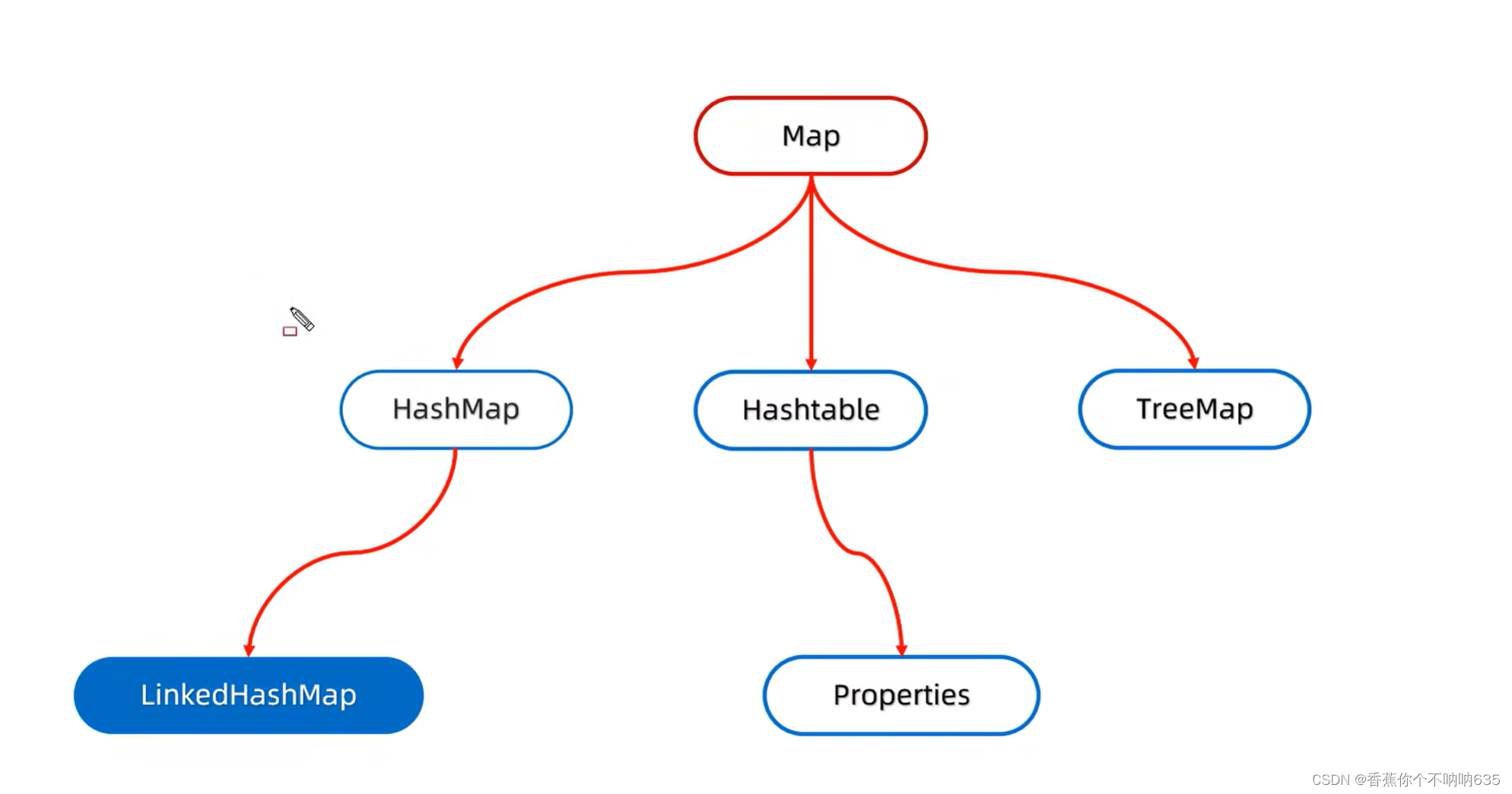
HashMap:保证键值唯一(可以用来统计出现的次数)
LinkedHashMap:由键决定:有序(这里的有序指的是保证存储和取出的元素顺序一致)、不重复(加两个还是一个)、无索引。原理:底层数据结构依旧是哈希表,只是每个键值对元素有额外的多了一个双链表的机制记录存储的顺序
TreeMap:与TreeSet底层原理一样,都是红黑树结构。由键决定特性:不重复,无索引,可排序(对键进行排序,如果是默认的,他给你排好了,无序自己排一遍
因为:Integer Double 默认情况下都是按照升序排序的,String是按照字母)
TreeMap若要按指定排序,则在创建时
TreeMap<Integer,String> tm=new TreeMap<>();这个(里面,new Comparator加快捷键............然后进行一下改造就行了)
eg:
TreeMap<Integer,String> tm=new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//o1当前要添加的元素
//o2表示已在红黑树存在的元素
return o2-o1;
}
});














 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









