






1.AC自动机
1.1 搜索关键字 一个模式串只算一次
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10010, S = 55, M = 1000010;
int n;
int tr[N * S][26], cnt[N * S], idx;
char str[M];
int q[N * S], ne[N * S];
void insert()
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int t = str[i] - 'a';
if (!tr[p][t]) tr[p][t] = ++ idx;
p = tr[p][t];
}
cnt[p] ++ ;
}
void build()
{
int hh = 0, tt = -1;
for (int i = 0; i < 26; i ++ )
if (tr[0][i])
q[ ++ tt] = tr[0][i];
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = 0; i < 26; i ++ )
{
int p = tr[t][i];
if (!p) tr[t][i] = tr[ne[t]][i];
else
{
ne[p] = tr[ne[t]][i];
q[ ++ tt] = p;
}
}
}
}
int main()
{
int T;
scanf("%d", &T);
while (T -- )
{
memset(tr, 0, sizeof tr);
memset(cnt, 0, sizeof cnt);
memset(ne, 0, sizeof ne);
idx = 0;
scanf("%d", &n);
for (int i = 0; i < n; i ++ )
{
scanf("%s", str);
insert();
}
build();
scanf("%s", str);
int res = 0;
for (int i = 0, j = 0; str[i]; i ++ )
{
int t = str[i] - 'a';
j = tr[j][t];
int p = j;
while (p)
{
res += cnt[p];
cnt[p] = 0;
p = ne[p];
}
}
printf("%d\n", res);
}
return 0;
}
1.2 单词 每个模式串在自己和其他中出现多少次
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1000010;
int n;
int tr[N][26], f[N], idx;
int q[N], ne[N];
char str[N];
int id[210];
void insert(int x)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int t = str[i] - 'a';
if (!tr[p][t]) tr[p][t] = ++ idx;
p = tr[p][t];
f[p] ++ ;
}
id[x] = p;
}
void build()
{
int hh = 0, tt = -1;
for (int i = 0; i < 26; i ++ )
if (tr[0][i])
q[ ++ tt] = tr[0][i];
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = 0; i < 26; i ++ )
{
int &p = tr[t][i];
if (!p) p = tr[ne[t]][i];
else
{
ne[p] = tr[ne[t]][i];
q[ ++ tt] = p;
}
}
}
}
int main()
{
scanf("%d", &n);
for (int i = 0; i < n; i ++ )
{
scanf("%s", str);
insert(i);
}
build();
for (int i = idx - 1; i >= 0; i -- ) f[ne[q[i]]] += f[q[i]];
for (int i = 0; i < n; i ++ ) printf("%d\n", f[id[i]]);
return 0;
}
2.AC自动机+dp
2.1最佳文章
最佳文章
小明最近在研究一门新的语言,叫做
Q
Q
Q 语言。
Q Q Q 语言单词和文章都可以用且仅用只含有小写英文字母的字符串表示,任何由这些字母组成的字符串也都是一篇合法的 Q Q Q 语言文章。
在 Q Q Q 语言的所有单词中,小明选出了他认为最重要的 n n n 个。
使用这些单词,小明可以评价一篇 Q Q Q 语言文章的“重要度”。
文章“重要度”的定义为:在该文章中,所有重要的 Q Q Q 语言单词出现次数的总和。其中多次出现的单词,不论是否发生包含、重叠等情况,每次出现均计算在内。
例如,假设
n
=
2
n = 2
n=2,小明选出的单词是 gvagv 和 agva。
在文章 gvagvagvagv 中,gvagv 出现了
3
3
3 次,agva 出现了
2
2
2 次,因此这篇文章的重要度为
3
+
2
=
5
3+2=5
3+2=5。
现在,小明想知道,一篇由 m m m 个字母组成的 Q Q Q 语言文章,重要度最高能达到多少。
输入格式
输入的第一行包含两个整数 n , m n, m n,m,表示小明选出的单词个数和最终文章包含的字母个数。
接下来 n n n 行,每行包含一个仅由英文小写字母构成的字符串,表示小明选出的这 n n n 个单词。
输出格式
输出一行一个整数,表示由 m m m 个字母组成的 Q Q Q 语言文章中,重要度最高的文章的重要度。
数据范围
在评测时将使用
10
10
10 个评测用例对你的程序进行评测。
设
s
s
s 为构成
n
n
n 个重要单词字母的总个数,例如在样例中,
s
=
4
+
7
+
6
=
17
s=4+7+6=17
s=4+7+6=17;
a
a
a 为构成
n
n
n 个重要单词字母的种类数,例如在样例中,共有
3
3
3 种字母 a,g,v,因此
a
=
3
a=3
a=3。
评测用例
1
1
1 和
2
2
2 满足
2
≤
n
≤
3
2 ≤ n ≤ 3
2≤n≤3,
1500
≤
m
≤
2000
1500 ≤ m ≤ 2000
1500≤m≤2000,
s
=
40
s = 40
s=40;
评测用例
3
3
3 和
4
4
4 满足
m
=
20
m = 20
m=20,
2
≤
a
≤
3
2 ≤ a ≤ 3
2≤a≤3;
评测用例
5
、
6
5、6
5、6 和
7
7
7 满足
2000
≤
m
≤
100000
2000 ≤ m ≤ 100000
2000≤m≤100000;
评测用例
8
8
8 满足
n
=
2
n = 2
n=2;
所有的评测用例满足
1
≤
s
≤
100
1 ≤ s ≤ 100
1≤s≤100,
1
≤
m
≤
1
0
15
1 ≤ m ≤ 10^{15}
1≤m≤1015,每个单词至少包含
1
1
1 个字母,保证单词中仅出现英文小写字母,输入中不含多余字符,不会出现重复的单词。
输入样例:
3 15
agva
agvagva
gvagva
输出样例:
11
样例解释
15
15
15 个字母组成的重要度最高的文章为 gvagvagvagvagva。
在这篇文章中,agva 出现
4
4
4 次,agvagva 出现
3
3
3 次,gvagva 出现
4
4
4 次,共计
4
+
3
+
4
=
11
4+3+4=11
4+3+4=11 次。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 110;
const LL INF = 1e18;
int n;
LL m;
int tr[N][26], cnt[N], ne[N], idx;
int q[N];
LL ans[N][N], w[N][N];
void insert(char* str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!tr[p][u]) tr[p][u] = ++ idx;
p = tr[p][u];
}
cnt[p] ++ ;
}
void build()
{
int hh = 0, tt = -1;
for (int i = 0; i < 26; i ++ )
if (tr[0][i])
q[ ++ tt] = tr[0][i];
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = 0; i < 26; i ++ )
{
int p = tr[t][i];
if (!p) tr[t][i] = tr[ne[t]][i];
else
{
ne[p] = tr[ne[t]][i];
cnt[p] += cnt[ne[p]];
q[ ++ tt] = p;
}
}
}
}
void mul(LL c[][N], LL a[][N], LL b[][N])
{
static LL tmp[N][N];
memset(tmp, -0x3f, sizeof tmp);
for (int i = 0; i <= idx; i ++ )
for (int j = 0; j <= idx; j ++ )
for (int k = 0; k <= idx; k ++ )
tmp[i][j] = max(tmp[i][j], a[i][k] + b[k][j]);
memcpy(c, tmp, sizeof tmp);
}
int main()
{
cin >> n >> m;
char str[N];
while (n -- )
{
cin >> str;
insert(str);
}
build();
memset(w, -0x3f, sizeof w);
for (int i = 0; i <= idx; i ++ )
for (int j = 0; j < 26; j ++ )
{
int k = tr[i][j];
w[i][k] = max(w[i][k], (LL)cnt[k]);
}
for (int i = 1; i <= idx; i ++ ) ans[0][i] = -INF;
while (m)
{
if (m & 1) mul(ans, ans, w);
mul(w, w, w);
m >>= 1;
}
LL res = 0;
for (int i = 0; i <= idx; i ++ ) res = max(res, ans[0][i]);
cout << res << endl;
return 0;
}
修复DNA
状态机模型
生物学家终于发明了修复DNA的技术,能够将包含各种遗传疾病的DNA片段进行修复。
为了简单起见,DNA看作是一个由’A’, ‘G’ , ‘C’ , ‘T’构成的字符串。
修复技术就是通过改变字符串中的一些字符,从而消除字符串中包含的致病片段。
例如,我们可以通过改变两个字符,将DNA片段”AAGCAG”变为”AGGCAC”,从而使得DNA片段中不再包含致病片段”AAG”,”AGC”,”CAG”,以达到修复该DNA片段的目的。
需注意,被修复的DNA片段中,仍然只能包含字符’A’, ‘G’ , ‘C’ , ‘T’。
请你帮助生物学家修复给定的DNA片段,并且修复过程中改变的字符数量要尽可能的少。
输入格式
输入包含多组测试数据。
每组数据第一行包含整数N,表示致病DNA片段的数量。
接下来N行,每行包含一个长度不超过20的非空字符串,字符串中仅包含字符’A’, ‘G’ , ‘C’ , ‘T’,用以表示致病DNA片段。
再一行,包含一个长度不超过1000的非空字符串,字符串中仅包含字符’A’, ‘G’ , ‘C’ , ‘T’,用以表示待修复DNA片段。
最后一组测试数据后面跟一行,包含一个0,表示输入结束。
输出格式
每组数据输出一个结果,每个结果占一行。
输入形如”Case x: y”,其中x为测试数据编号(从1开始),y为修复过程中所需改变的字符数量的最小值,如果无法修复给定DNA片段,则y为”-1”。
数据范围
1 ≤ N ≤ 50 1 \le N \le 50 1≤N≤50
输入样例:
2
AAA
AAG
AAAG
2
A
TG
TGAATG
4
A
G
C
T
AGT
0
最标准的,更新f[i+1][p]
#include<iostream>
using namespace std;
#include<cstring>
const int N=60;
//一个字符就是一层
//一位就是一层
int tr[N*20+10][4];
int ne[(N*20+10)*4];
int f[(N*20+10)*4];
bool dan[N*20+10];
int idx=0;
int get(char c){
if(c=='A')return 0;
if(c=='G')return 1;
if(c=='C')return 2;
if(c=='T')return 3;
}
void insert(string str){
int p=0;
for(int i=0;str[i];i++){
int u=get(str[i]);
if(!tr[p][u])tr[p][u]=++idx;
p=tr[p][u];
}
dan[p]=1;
}
void bui(){
int q[(N*20+10)*4];
int hh=0;int tt=-1;
for(int i=0;i<4;i++){
if(tr[0][i])q[++tt]=tr[0][i];
}
while(hh<=tt){
int t=q[hh++];
for(int i=0;i<4;i++){
int p=tr[t][i];
if(!p) tr[t][i]=tr[ne[t]][i];
else {
ne[p]=tr[ne[t]][i];
q[++tt]=p;
}
}
}
}
int main(){
int n;
int T=0;
while(cin>>n){
if(n==0)break;
memset(tr,0,sizeof(tr));idx=0;
memset(dan,0,sizeof(dan));
memset(ne,0,sizeof(ne));
while(n--){
string s;cin>>s;
insert(s);
}
bui();
char str[1010];
scanf("%s",str+1);
int m=1;while(str[m])m++;m--;
memset(f,INF,sizeof(f));
f[0][0]=0;
for(int i=0;i<m;i++){
for(int j=0;j<=idx;j++){
for(int k=0;k<4;k++){
int t=s[i+1]!=k;
int p=tr[j][k];
if(dan[p])continue;
f[i+1][k]=min(f[i][j]+t,f[i+1][k]);
}
}
}
int ans=INF;
for(int j=0;j<=idx;j++)ans=min(ans,f[m][j]);
printf("Case %d: %d\n",T,ans);
}
}
输出样例:
Case 1: 1
Case 2: 4
Case 3: -1
最近在补全提高课所有题目的题解,宣传一下汇总的地方提高课题解补全计划
题目描述
本题 有限字符集 为 { A , G , C , T } \{A,G,C,T\} {A,G,C,T}
题目给定 n n n 个 模式串 T i ( 1 ≤ i ≤ n ) T_i (1 \le i \le n) Ti(1≤i≤n) 和 一个 主串 S S S
每次可以修改 主串 中的一个字符 S [ i ] S[i] S[i]
要求进行最少次 修改操作,使得 主串 S S S 中不存在 模式串 T i ( 1 ≤ i ≤ n ) T_i (1 \le i \le n) Ti(1≤i≤n) 的子串
求出该 操作次数 ,如果不行,输出 − 1 -1 −1
分析
阅读本题解的前置知识: 自动机,AC自动机, 线性DP
基本思路和上一题 AcWing 1052. 设计密码【线性DP+KMP自动机模型】 一致
我就照搬一下上一题题解中的分析思路了
采用 线性扫描 的方法,进行 动态规划
考虑一个 单主串 与 多模式串 的 匹配算法,考虑使用 AC自动机 进行分析
考虑 阶段i 需要记录的状态也和上一题类似,是 自动机 的 状态j
自动机模型分析
依然举样例来分析,因为不同模式串构成的字典树不同,没法一概而论
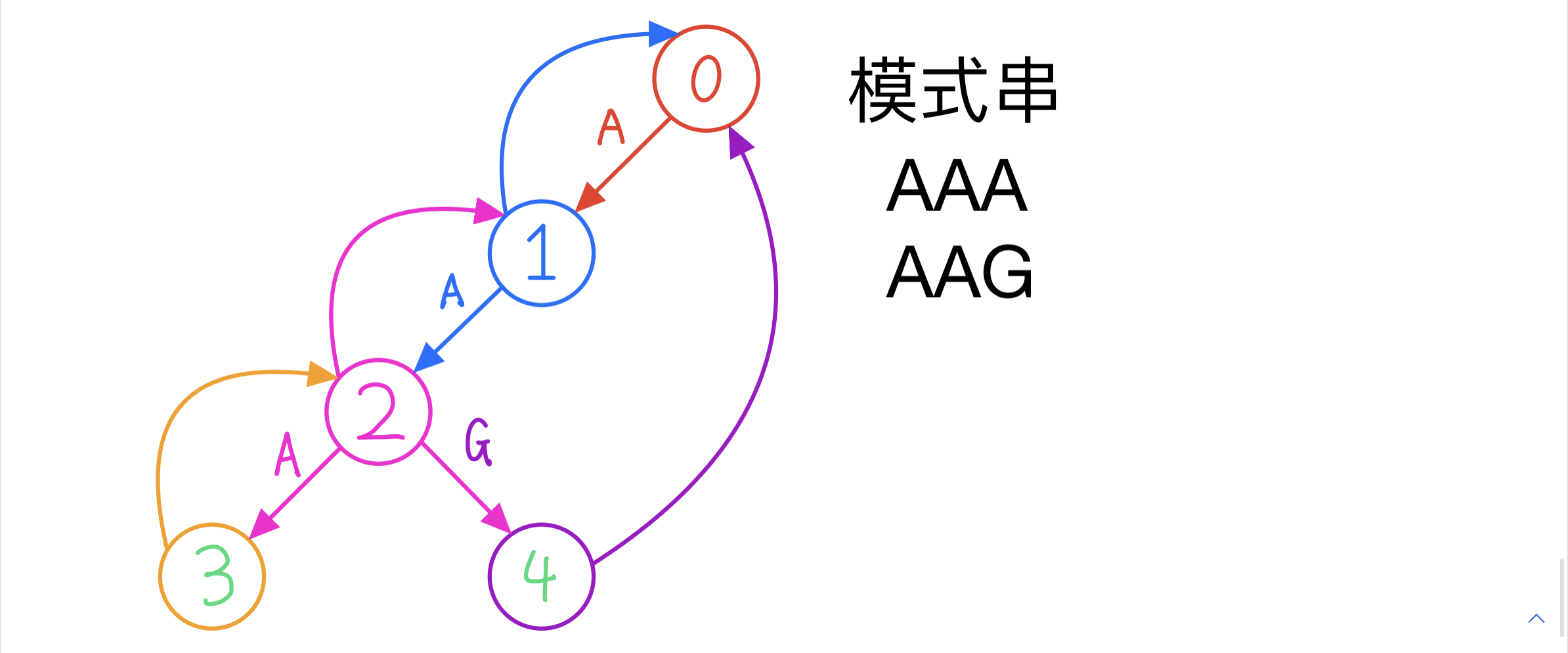
以 状态 j = 2 j=2 j=2为例
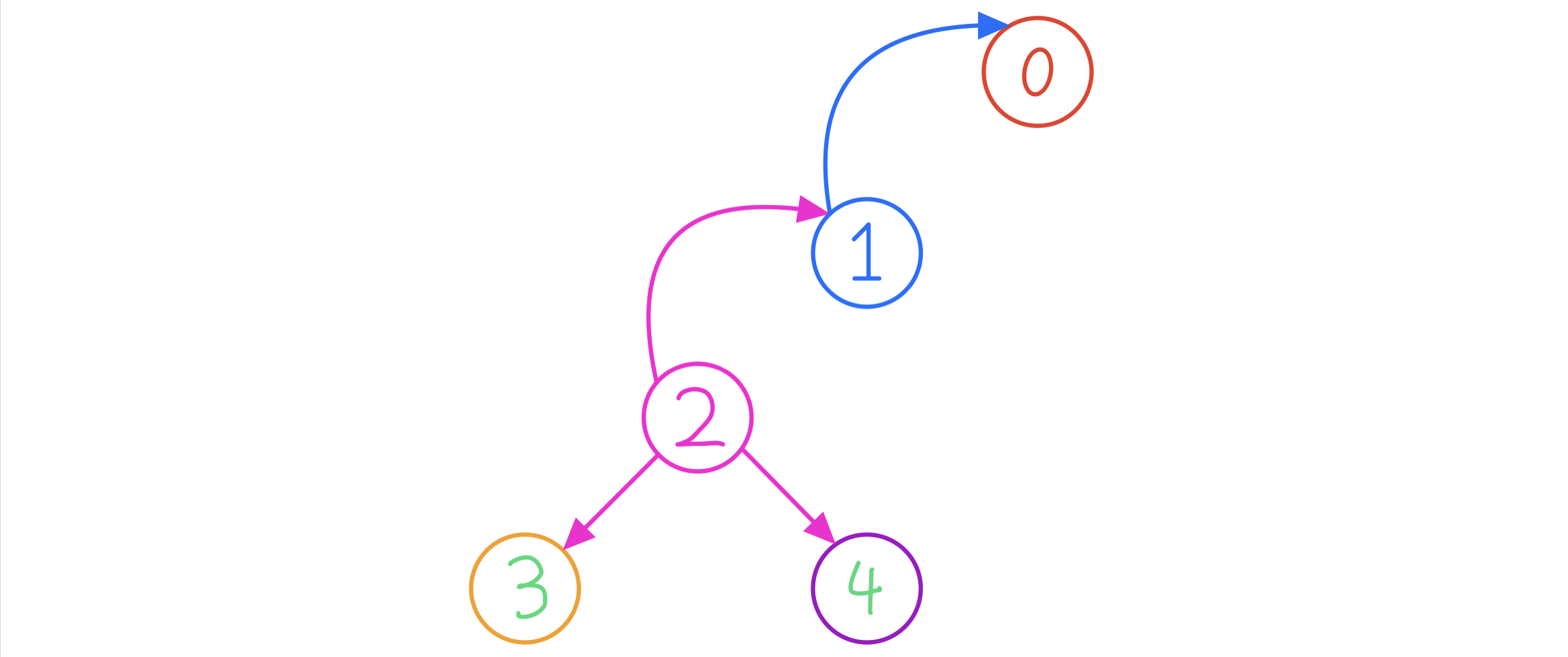
根据 AC自动机 的状态转移:
t r a n s j , c = { j + 1 , i f s i = c h t r a n s f a i l j , c h e l s e trans_{j,c} = \begin{cases} j + 1, &if s_i=ch \\\ trans_{fail_j,ch} &else \end{cases} transj,c={j+1, transfailj,chifsi=chelse
对应于本样例就是:
- ch是b,则最大长度增加一,对应到 f i + 1 , j + 1 f_{i+1,j+1} fi+1,j+1
- ch不是b,则根据自动机跳到状态 t r a n s f a i l j , c h trans_{fail_j,ch} transfailj,ch,对应到 f i + 1 , t r a n s f a i l j , c h f_{i+1,trans_{fail_j,ch}} fi+1,transfailj,ch
闫氏DP分析法
状态表示—集合 f i , j f_{i,j} fi,j: 考虑主串中前 i i i 个字符,且当前自动机状态是 j j j 的方案
状态表示—属性 f i , j f_{i,j} fi,j: 方案的操作数最小 M i n Min Min
状态计算 f i , j f_{i,j} fi,j:
f i + 1 , t r a n s j , c = min ( f i , t r a n s j , c , f i , j ) ( 其中 0 ≤ c ≤ 3 ) f_{i+1, trans_{j,c}} = \min(f_{i, trans_{j,c}}, f_{i,j}) \quad(其中0\le c \le 3) fi+1,transj,c=min(fi,transj,c,fi,j)(其中0≤c≤3)
【注】:本题是求最小值,因此要把非初始状态初始化为正无穷
初始状态: f 0 , 0 f_{0,0} f0,0
目标状态: f n , j j 枚举的是所有自动机的状态 f_{n,j} \quad j枚举的是所有自动机的状态 fn,jj枚举的是所有自动机的状态
Code 朴素写法
时间复杂度: O ( 4 L e n S ∑ L e n T i ) O(4Len_S \sum Len_{T_i}) O(4LenS∑LenTi)
#include <iostream>
#include <cstring>
using namespace std;
const int N = 55, M = 1010, K = 25;
const int INF = 0x3f3f3f3f;
int n;
char s[M];
int tr[N * K][4], cnt[N * K], idx;
int fail[N * K], q[N * K];
int f[M][N * K];
int get(char c)
{
if (c == 'A') return 0;
if (c == 'G') return 1;
if (c == 'C') return 2;
return 3;
}
void insert(char s[])
{
int p = 0;
for (int i = 0; s[i]; ++ i)
{
int u = get(s[i]);
if (!tr[p][u]) tr[p][u] = ++ idx;
p = tr[p][u];
}
cnt[p] = 1;
}
void build()
{
int tt = -1, hh = 0;
for (int i = 0; i < 4; ++ i)
if (tr[0][i])
q[ ++ tt] = tr[0][i];
while (hh <= tt)
{
int u = q[hh ++ ];
for (int i = 0; i < 4; ++ i)
{
if (tr[u][i])
fail[tr[u][i]] = tr[fail[u]][i],
q[ ++ tt] = tr[u][i];
else
tr[u][i] = tr[fail[u]][i];
}
}
}
void solve()
{
//initializing
memset(fail, 0, sizeof fail);
memset(cnt, 0, sizeof cnt);
memset(f, 0x3f, sizeof f);
memset(tr, 0, sizeof tr);
f[0][0] = 0;
idx = 0;
//input and build the AC Automaton
for (int i = 1; i <= n; ++ i) cin >> s, insert(s);
cin >> s + 1; build();
int n = strlen(s + 1);
//dp
for (int i = 0; i < n; ++ i)
{
for (int j = 0; j <= idx; ++ j)
{
//枚举下一个字符
for (int k = 0; k < 4; ++ k)
{
int cost = get(s[i + 1]) != k; //修复下一个字符的费用
//递归找到下一层的状态
int p = tr[j][k];
bool flag = true;
int temp = p;
while (temp)
{
if (cnt[temp])
{
flag = false;
break;
}
temp = fail[temp];
}
//找到了,就更新
if (flag) f[i + 1][p] = min(f[i + 1][p], f[i][j] + cost);
}
}
}
int res = INF;
for (int j = 0; j <= idx; ++ j) res = min(res, f[n][j]);
if (res == INF) res = -1;
cout << res << endl;
}
int main()
{
int T = 1;
while (cin >> n, n)
{
cout << "Case " << T ++ << ": ";
solve();
}
return 0;
}
Code(y总的优化思路)
OI爷的想法就是牛!
考虑一个长的匹配串,如果他的某一个前缀子串的最大相等前后缀(就是 f a i l [ j ] fail[j] fail[j]) 出现了另一个模式串匹配成功的状态,则我们认为该状态就是 匹配成功状态
这样我们就不用每次枚举第 i + 1 i+1 i+1 个字符后,再额外进行 f a i l fail fail 跳转枚举了
只需在建 AC自动机 时,构建 f a i l fail fail 指针的跳转时,顺便记录 跳转到的状态 是否也会匹配上即可
由于 BFS 保证枚举状态 j j j 时,所有 长度小于当前状态 的模式串以及 f a i l fail fail 指针跳转都构建好了
因此,可以保证建立 f a i l fail fail 指针时,他 跳转的状态 以及他 跳转的跳转的状态 是否是 匹配成功的状态 已经被更新出了
于是,通过该思路,就可以进行 y总的代码优化了
#include <iostream>
#include <cstring>
using namespace std;
const int N = 55, M = 1010, K = 25;
const int INF = 0x3f3f3f3f;
int n;
char s[M];
int tr[N * K][4], cnt[N * K], idx;
int fail[N * K], q[N * K];
int f[M][N * K];
int get(char c)
{
if (c == 'A') return 0;
if (c == 'G') return 1;
if (c == 'C') return 2;
return 3;
}
void insert(char s[])
{
int p = 0;
for (int i = 0; s[i]; ++ i)
{
int u = get(s[i]);
if (!tr[p][u]) tr[p][u] = ++ idx;
p = tr[p][u];
}
cnt[p] = 1;
}
void build()
{
int tt = -1, hh = 0;
for (int i = 0; i < 4; ++ i)
if (tr[0][i])
q[ ++ tt] = tr[0][i];
while (hh <= tt)
{
int u = q[hh ++ ];
for (int i = 0; i < 4; ++ i)
{
if (tr[u][i])
fail[tr[u][i]] = tr[fail[u]][i],
cnt[tr[u][i]] |= cnt[fail[tr[u][i]]],//看他跳转的状态是否是匹配成功状态
q[ ++ tt] = tr[u][i];
else
tr[u][i] = tr[fail[u]][i];
}
}
}
void solve()
{
//initializing
memset(fail, 0, sizeof fail);
memset(cnt, 0, sizeof cnt);
memset(f, 0x3f, sizeof f);
memset(tr, 0, sizeof tr);
f[0][0] = 0;
idx = 0;
//input and build the AC Automaton
for (int i = 1; i <= n; ++ i) cin >> s, insert(s);
cin >> s + 1; build();
int n = strlen(s + 1);
//dp
for (int i = 0; i < n; ++ i)
{
for (int j = 0; j <= idx; ++ j)
{
//枚举下一个字符
for (int k = 0; k < 4; ++ k)
{
int cost = get(s[i + 1]) != k; //修复下一个字符的费用
int p = tr[j][k]; //下一个字符的自动机状态
if (!cnt[p]) f[i + 1][p] = min(f[i + 1][p], f[i][j] + cost);
}
}
}
int res = INF;
for (int j = 0; j <= idx; ++ j) res = min(res, f[n][j]);
if (res == INF) res = -1;
cout << res << endl;
}
int main()
{
int T = 1;
while (cin >> n, n)
{
cout << "Case " << T ++ << ": ";
solve();
}
return 0;
}
密信与计数
20次
背景
小明和小鱼研究出了一套加密通信的规则。
小鱼给小明发送信息(仅由小写字母组成的字符串)的流程如下:
- 小鱼使用手中的密码本,将明文信息生成密文,该密文也仅由小写字母组成且与明文等长;
- 小鱼将密文发送给小明;
- 小明使用手中的密码本(内容与小鱼的密码本很可能不同),将密文解密为明文,该明文与小鱼的原信息一定是相同的。
解密密码本
虽然你不知道小鱼是如何加密的,但是你拿到了小明用来解密的密码本。
小明的密码本共有 n n n 页(从 1 1 1 到 n n n 编号)。
每页有 26 26 26 行,对应着字母 a a a 到 z z z。
每行写有一个小写字母 o u t out out 和一个整数 n e x t next next( 1 ≤ n e x t ≤ n 1 \le next \le n 1≤next≤n)。
对于每一页,其上面的 26 26 26 个 o u t out out 是两两不同的。
小明在解密信息时,先将密码本翻到第 1 1 1 页,然后对于密文的每一个字符依次进行以下操作:
在当前页找到该字符对应的行,在纸上写下该行的 o u t out out 字符,并将密码本翻到第 n e x t next next 页。
扫描完密文的每个字符后,纸上写下的字符就依次形成了明文。
下面是一个密码本的例子:
Page 1 Page 2
'a' (out='x',next=1) (out='w',next=2)
'b' (out='y',next=2) (out='z',next=1)
'c' (out='z',next=2) (out='y',next=2)
'd' ...... ......
... ...... ......
'z' ...... ......
在这个例子下,如果小明收到的密文为 a b a c abac abac,则相应的解密过程如下:
初始时,将密码本翻到第 1 1 1 页;
- 遇到密文字符 a a a,查到 o u t out out 为 x x x, n e x t next next 为 1 1 1,则向纸上写字符 x x x,密码本仍在第 1 1 1 页;
- 遇到密文字符 b b b,查到 o u t out out 为 y y y, n e x t next next 为 2 2 2,则向纸上写字符 y y y,将密码本翻到第 2 2 2 页;
- 遇到密文字符 a a a,查到 o u t out out 为 w w w, n e x t next next 为 2 2 2,则向纸上写字符 w w w,密码本仍在第 2 2 2 页;
- 遇到密文字符 c c c,查到 o u t out out 为 y y y, n e x t next next 为 2 2 2,则向纸上写字符 y y y,密码本仍在第 2 2 2 页。
所以,解密得到的明文为 x y w y xywy xywy。
词典
你还拿到了一个词典,小鱼和小明的通信内容明文都是由这个词典中的字符串拼接而成的。
词典中不会有空串,不会有两个完全相同的单词,也不会存在某个单词是另一个单词的前缀。
例如,词典有 4 4 4 个单词:
dog
is
good
happy
那么 d o g i s h a p p y dogishappy dogishappy、 h a p p y d o g i s g o o d d o g happydogisgooddog happydogisgooddog 都是可能出现的通信内容,但是 d o g o o d dogood dogood、 h i s a p p y hisappy hisappy 是不合法的明文。
此外,小鱼在编写明文时,会特别注意使它对应的密文“看起来像密文”。
“看起来像密文”是指,对应的密文当中不应当包含词典中的任何词作为子串。
例如明文 d o g g o o d doggood doggood 本身符合词典的要求,但假设它对应的密文是 x i s x x y z xisxxyz xisxxyz,由于其中包含了 i s is is 为子串,则小鱼也不会编写 d o g g o o d doggood doggood 这一明文。
本题的任务
给定小明的解密密码本和词典,我们定义 k k k-合法密文是指:
- 长度为 k k k,仅包含小写字母的字符串;
- 不包含词典中的任何一个串为子串;
- 其对应的明文可以通过词典中的字符串拼接而成。
除了密码本和词典以外,我们还输入正整数 m m m。
你需要对于 k = 1 , 2 , 3 , … , m k=1,2,3,…,m k=1,2,3,…,m 输出 k k k-合法密文的数量。
由于答案可能很大,每个数只需要对 998244353 998244353 998244353 取模后输出即可。
输入格式
第一行输入两个正整数 n , m n,m n,m。
接下来输入小明的解密密码本。密码本包含 26 26 26 行,每行有 n n n 个元素。其中第 i i i 行第 j j j 列的元素输入密码本第 j j j 页第 i i i 行的内容。每个元素先输入 o u t out out,后输入 n e x t next next。例如输入 y 2 y2 y2 表示 o u t out out 为 y y y, n e x t next next 为 2 2 2。注意字母和数字之间没有空格。
接下来输入词典,词典的每个单词占据一行。
输出格式
输出 m m m 行,每行一个整数,依次表示 k = 1 , k = 2 , … , k = m k=1,k=2,…,k=m k=1,k=2,…,k=m 时, k k k-合法密文的数量,对 998244353 998244353 998244353 取模的结果。
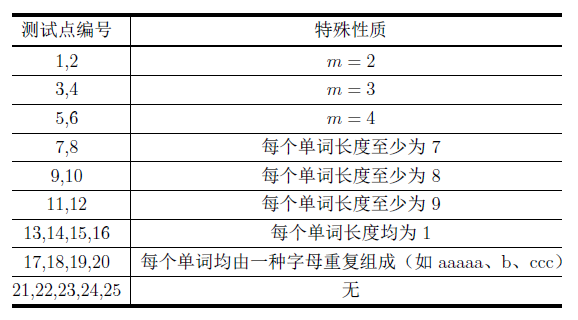
数据范围
对于所有的测试点, 1 ≤ n ≤ 50 , 1 ≤ m ≤ 1000 1 \le n \le 50, 1 \le m \le 1000 1≤n≤50,1≤m≤1000,词典不为空且所有单词的长度之和不超过 50 50 50。
对于编号为偶数的测试点, n = 1 n=1 n=1。
其他的特殊性质如下表所述:
输入样例1:
2 4
x2 w2
y2 z1
z1 y2
a2 x1
b2 a2
c1 b1
d2 c2
e2 d1
f1 e2
g2 f1
h2 g2
i1 h1
j2 i2
k2 j1
l1 k2
m2 l1
n2 m2
o1 n1
p2 o2
q2 p1
r1 q2
s2 r2
t2 s1
u1 t2
v2 u1
w2 v2
a
de
hh
输出样例1:
1
2
3
5
样例1解释

输入样例2:
1 30
n1
b1
k1
w1
l1
q1
r1
y1
h1
o1
f1
d1
u1
i1
g1
p1
c1
m1
v1
x1
j1
t1
z1
e1
s1
a1
yyyyy
a
sss
ffff
uuuu
n
rrrrr
zzzz
dd
l
w
x
jjj
i
tttt
kkk
ee
ggg
qq
输出样例2:
4
15
62
254
1037
4238
17318
70762
289147
1181515
4827896
19727703
80611180
329392745
347717570
508636782
512101020
990699955
897183687
992683554
367164478
441771655
282208579
707622895
680435638
349679885
49272719
821317456
174000209
371253693
#include <iostream>
#include <cstring>
#include <algorithm>
#include <vector>
using namespace std;
const int N = 55, M = 1010, MOD = 998244353;
int n, m;
int tr[N][26], cnt[N], idx;
int q[N], ne[N];
struct Node
{
int row, next;
}g[26][N];
int f[M][N][N];
vector<string> strs;
void insert(string& str)
{
int p = 0;
for (char c: str)
{
int u = c - 'a';
if (!tr[p][u]) tr[p][u] = ++ idx;
p = tr[p][u];
}
cnt[p] ++ ;
}
void build()
{
int hh = 0, tt = -1;
for (int i = 0; i < 26; i ++ )
if (tr[0][i])
q[ ++ tt] = tr[0][i];
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = 0; i < 26; i ++ )
{
int p = tr[t][i];
if (!p) tr[t][i] = tr[ne[t]][i];
else
{
ne[p] = tr[ne[t]][i];
cnt[p] += cnt[ne[p]];
q[ ++ tt] = p;
}
}
}
}
int main()
{
cin >> n >> m;
for (int i = 0; i < 26; i ++ )
for (int j = 1; j <= n; j ++ )
{
string str;
cin >> str;
g[str[0] - 'a'][j] = {i, stoi(str.substr(1))};
}
string str;
while (cin >> str)
{
insert(str);
strs.push_back(str);
}
build();
f[0][0][1] = 1;
for (int i = 0; i <= m; i ++ )
{
int sum = 0;
for (int j = 0; j <= idx; j ++ )
for (int k = 1; k <= n; k ++ )
{
if (!f[i][j][k]) continue;
sum = (sum + f[i][j][k]) % MOD;
for (auto& s: strs)
{
if (i + s.size() > m) continue;
bool flag = true;
int x = j, y = k;
for (auto c: s)
{
int u = c - 'a';
auto& t = g[u][y];
x = tr[x][t.row];
if (cnt[x])
{
flag = false;
break;
}
y = t.next;
}
if (flag)
{
auto& v = f[i + s.size()][x][y];
v = (v + f[i][j][k]) % MOD;
}
}
}
if (i) printf("%d\n", sum);
}
return 0;
}















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









