






目录
一、数据库简介
1.1什么是数据库?
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
1.2关系型数据库的特点
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
1.3MySQL数据库
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL 是开源的,目前隶属于 Oracle 旗下产品。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 对 PHP 有很好的支持,PHP 是很适合用于 Web 程序开发。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。
二、select查询语句
2.1基本查询
语法如下:
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column_name [ASC | DESC]]
[LIMIT number];
参数说明:
column1,column2, ... 是你想要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。WHERE condition是一个可选的子句,用于指定过滤条件,只返回符合条件的行。ORDER BY column_name [ASC | DESC]是一个可选的子句,用于指定结果集的排序顺序,默认是升序(ASC)。LIMIT number是一个可选的子句,用于限制返回的行数。
2.1条件查询
我们知道从 MySQL 表中使用 SELECT 语句来读取数据。
如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句中。
WHERE 子句用于在 MySQL 中过滤查询结果,只返回满足特定条件的行。
语法如下:
SELECT column1, column2, ...
FROM table_name
WHERE condition;
参数说明:
column1,column2, ... 是你要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。WHERE condition是用于指定过滤条件的子句。
在where子句中还可以使用操作符,例如:
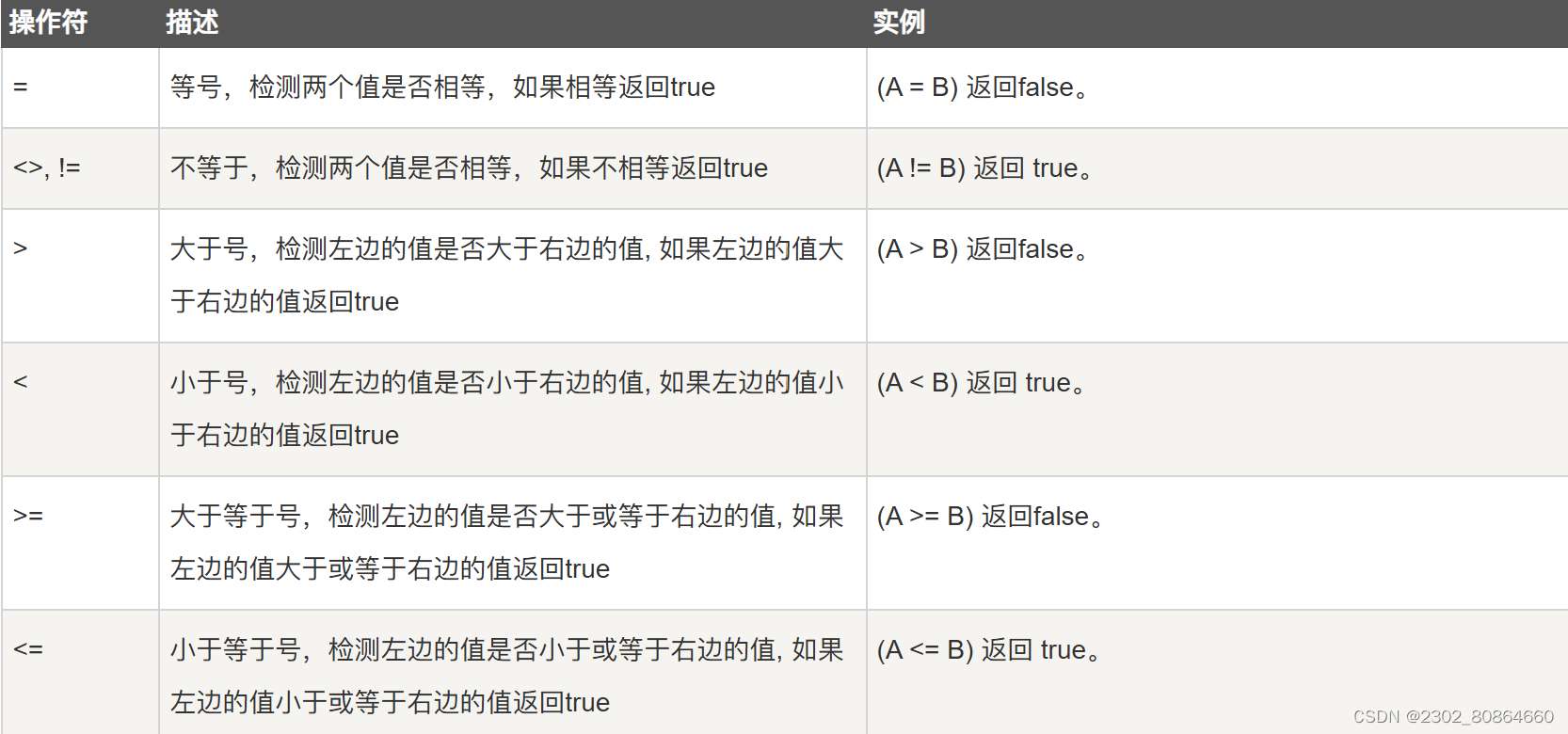
另外还有一些关键字也可用于条件查询
1. 模糊匹配条件(LIKE)
2. IN 条件
3. NOT 条件
4. BETWEEN 条件
5. IS NULL 条件
6. IS NOT NULL 条件
2.3高级查询
2.3.1DISTINCT关键字
实际应用中,出于对数据的分析需求,有时需要去除查询记录中重复的数据。可使用DISTINCT(去重复值子句)去除重复记录 (消除重复行,只保留一条)。
语法:DISTINCT 字段名1 [, 字段名2 ]…
2.3.2ORDER BY子句
在项目开发时,为了使查询的数据结果满足用户的要求,通常使用ORDER BY(排序子句)对查询出的数据进行上升或下降的排序。
语法:ORDER BY 字段名 [ASC|DESC]
说明:ASC 升序,DESC 降序,缺省值为升序
注意:
关于中文排序问题:
1、字段的字符集是utf8,默认不会按照中文拼音排序;2、字段的字符集是gbk, 将会按照中文拼音排序;
3、在不改变数据表结构的情况下,可以使用“CONVERT(字段名 USING gbk)”函数强制让指定的字段按中文排序,例如:select * from TBL_Bookinfo order by convert(Publisher using gbk);
关于空值NULL排序问题:
1、ASC方式,排序列为NULL的元组(记录、行)最先显示,2、DESC方式,排序列为NULL的元组(记录、行)最后显示;
2.3.3LIMIT关键字
关于记录数的限量问题:
对于一次性查询出的大量记录,不仅不便于阅读查看,还会浪费系统效率。MySQL中提供了一个关键字LIMIT(限量子句),可以限定记录的数量,也可以指定查询从哪一条记录开始(通常用于分页)。
语法:LIMIT [偏移量,] 记录数
说明:
1、记录数表示限定获取的最大记录数量。仅含此参数时,表示从第1条记录开始获取。
2、偏移量用于设置从哪条记录开始,默认第1条记录的偏移量值为0,第2条记录的偏移量值为1,依次类推。
3、LIMIT 后使用无符号的整数。
2.3.4常用聚合函数
| 函数 | 描述 |
| COUNT(字段名) | 返回参数字段的数量,参数可以使用*,即COUNT(*) |
| SUM(字段名) | 返回参数字段之和 |
| AVG(字段名) | 返回参数字段的平均值 |
| MAX(字段名) | 返回参数字段的最大值 |
| MIN(字段名) | 返回参数字段的最小值 |
说明:
1、COUNT()、SUM()、AVG()、MAX()、MIN() 函数中可以在字段名前添加DISTINCT,表示对不重复的记录进行相关操作;
2、COUNT(*),表示统计符合条件的所有记录(包含NULL);其他聚合函数都不能使用*,不统计字段中的空值(NULL)。
注意:select查询内容,group by、having、order by 子句是聚合函数允许出现的地方,在where 子句中不能使用聚合函数。
2.4 分组查询
2.4.1GROUP BY子句
在应用中,通常需要对数据按照某个或多个字段进行分组统计。
语法:GROUP BY 字段名
使用GROUP BY子句注意事项:
1.group by 分组字段最好选择非空字段,因为空值也将被当作一组。
2.SQL语法规定:使用group by 子句的select语句,非分组字段不能作为查询输出列,即查询输出列只能由分组字段和聚合函数列组成。
3.SQL语法规定:不使用group by 子句的select语句,查询输出列不允许同时出现字段与聚合函数。
GROUP BY子句带排序功能
语法:GROUP BY 字段名[ASC | DESC]
2.4.2HAVING子句
对查询的数据分组时,可以利用HAVING子句对分组筛选。
语法如下:
SELECT 查询列表 FROM 数据表名
[WHERE 条件表达式]
GROUP BY 字段名 [ASC | DESC][, …]
HAVING 条件表达式
HAVING子句与WHERE的区别
WHERE子句是在分组前对数据进行筛选,条件不可以使用聚合函数。
HAVING子句对分组统计后的结果进行筛选,条件使用聚合函数。















 6188
6188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









