






函数逼近是人工智能领域的重要数学基础,它涉及如何用简单的函数来近似复杂函数或数据分布,广泛应用于模型构建、数据拟合和算法优化中。本文将从函数插值、曲线拟合、最佳逼近、核函数逼近和神经网络逼近等角度进行系统介绍,并结合 Python 实例,帮助大家深入理解和应用这些知识。资源绑定附上完整资源供读者参考学习!
7.1 函数插值
7.1.1 线性函数插值
线性插值是最基本的插值方法,通过两个已知点构造直线,估计中间点的函数值。它简单易行,但精度有限。
7.1.2 多项式插值
多项式插值通过构造一个多项式函数,使其经过所有已知数据点。常见的有拉格朗日插值和牛顿插值等方法。拉格朗日插值通过基函数线性组合构造插值多项式,而牛顿插值则利用差商逐步构造。
7.1.3 样条插值
样条插值使用分段多项式函数来逼近数据,具有高精度和光滑性。三次样条插值是最常用的方法,它在每个数据区间上拟合三次多项式,保证函数及其一阶、二阶导数的连续性。
7.1.4 径向基函数插值
径向基函数(RBF)插值利用径向基函数(如高斯函数、多项式函数等)作为基函数,通过线性组合来逼近数据。它适用于高维空间和散乱数据的插值。
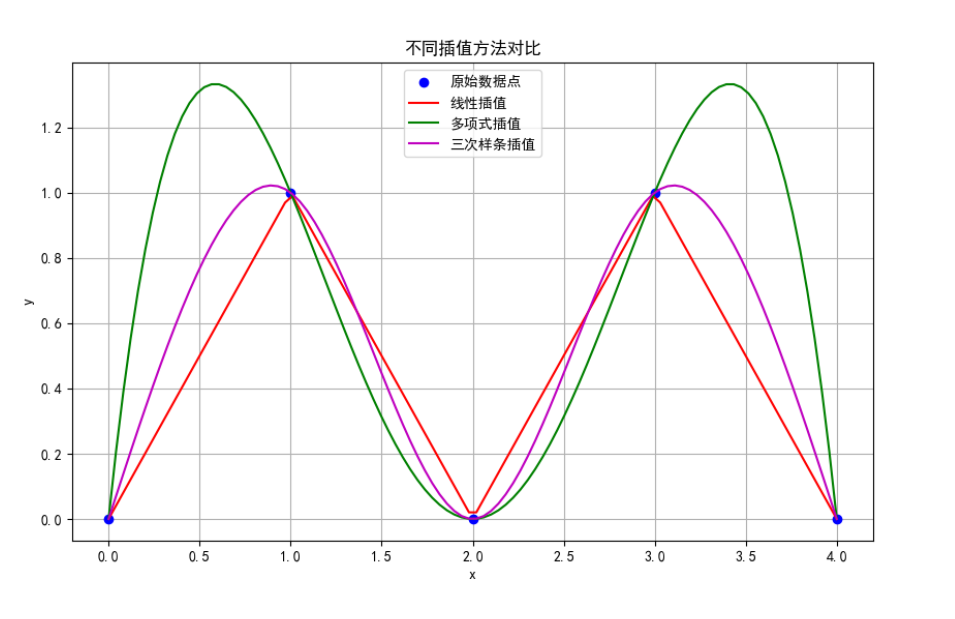
综合案例及应用:不同插值方法对比
案例描述 :对给定数据点,使用线性插值、多项式插值和样条插值进行插值,并比较结果。
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import lagrange, interp1d, CubicSpline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 给定数据点
x = np.array([0, 1, 2, 3, 4])
y = np.array([0, 1, 0, 1, 0])
# 线性插值
linear_interp = interp1d(x, y, kind='linear')
x_new = np.linspace(0, 4, 100)
y_linear = linear_interp(x_new)
# 多项式插值(拉格朗日)
poly = lagrange(x, y)
y_poly = poly(x_new)
# 样条插值(三次样条)
cs = CubicSpline(x, y, bc_type='natural')
y_cs = cs(x_new)
# 绘图比较
plt.figure(figsize=(10, 6))
plt.plot(x, y, 'bo', label='原始数据点')
plt.plot(x_new, y_linear, 'r-', label='线性插值')
plt.plot(x_new, y_poly, 'g-', label='多项式插值')
plt.plot(x_new, y_cs, 'm-', label='三次样条插值')
plt.xlabel('x')
plt.ylabel('y')
plt.title('不同插值方法对比')
plt.legend()
plt.grid(True)
plt.show()
7.2 曲线拟合
7.2.1 线性最小二乘法
线性最小二乘法用于寻找最佳直线拟合数据,使残差平方和最小。它是回归分析的基础。
7.2.2 非线性曲线拟合
非线性曲线拟合用于拟合非线性关系的数据。常用的方法包括梯度下降法和 Levenberg-Marquardt 算法。
7.2.3 贝塞尔曲线拟合
贝塞尔曲线是一种参数曲线,广泛用于计算机图形学和曲线设计。通过控制点定义曲线形状,具有良好的可控性和光滑性。
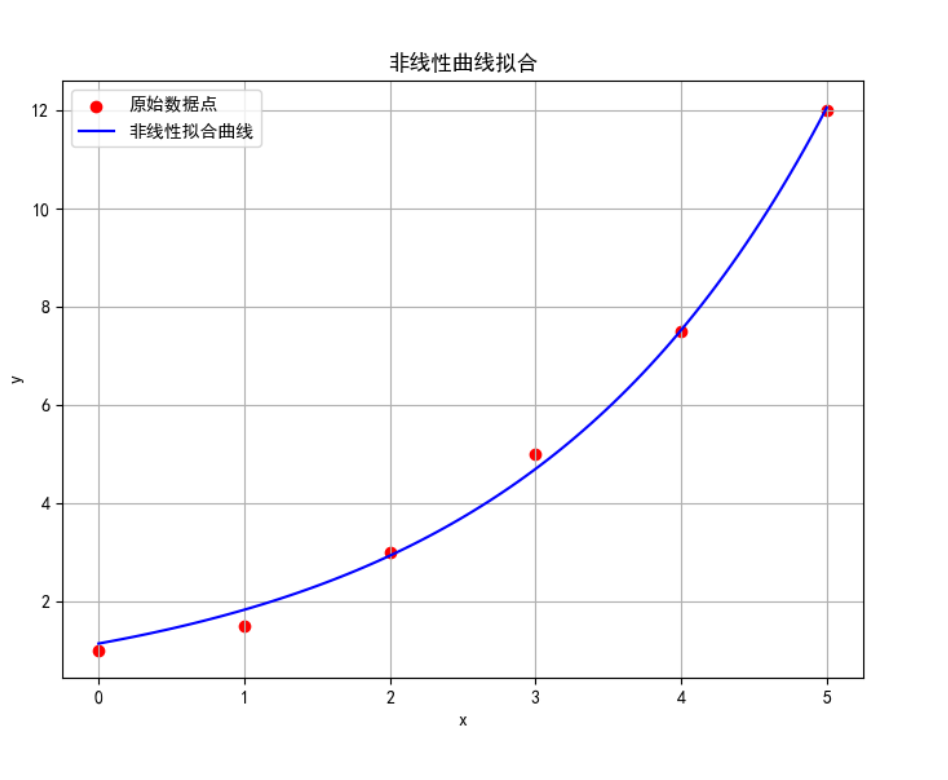
综合案例及应用:非线性曲线拟合
案例描述 :对给定数据点,使用非线性曲线拟合,拟合函数为 y = a * exp(b * x)。
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 给定数据点
x_data = np.array([0, 1, 2, 3, 4, 5])
y_data = np.array([1, 1.5, 3, 5, 7.5, 12])
# 定义非线性拟合函数
def func(x, a, b):
return a * np.exp(b * x)
# 初始参数猜测
initial_guess = [1, 0.1]
# 使用 curve_fit 进行非线性拟合
params, covariance = curve_fit(func, x_data, y_data, initial_guess)
# 提取拟合参数
a_fit, b_fit = params
# 计算拟合后的 y 值
x_fit = np.linspace(0, 5, 100)
y_fit = func(x_fit, a_fit, b_fit)
# 绘图比较
plt.figure(figsize=(8, 6))
plt.scatter(x_data, y_data, color='red', label='原始数据点')
plt.plot(x_fit, y_fit, 'b-', label='非线性拟合曲线')
plt.xlabel('x')
plt.ylabel('y')
plt.title('非线性曲线拟合')
plt.legend()
plt.grid(True)
plt.show()
# 输出拟合参数
print(f"拟合参数 a = {a_fit:.2f}, b = {b_fit:.2f}")
7.3 最佳逼近
7.3.1 函数空间范数与最佳逼近问题
在函数空间中,范数用于衡量函数的大小或长度。最佳逼近问题是在给定函数空间中,寻找与目标函数距离最小的函数。
7.3.2 最佳一致逼近
最佳一致逼近寻求在区间上与目标函数最大偏差最小的逼近函数。切比雪夫定理提供了最佳一致逼近多项式存在的条件。
7.3.3 最佳平方逼近
最佳平方逼近在平方可积函数空间中,寻找使误差平方积分最小的逼近函数。它通常通过正交函数系展开实现。
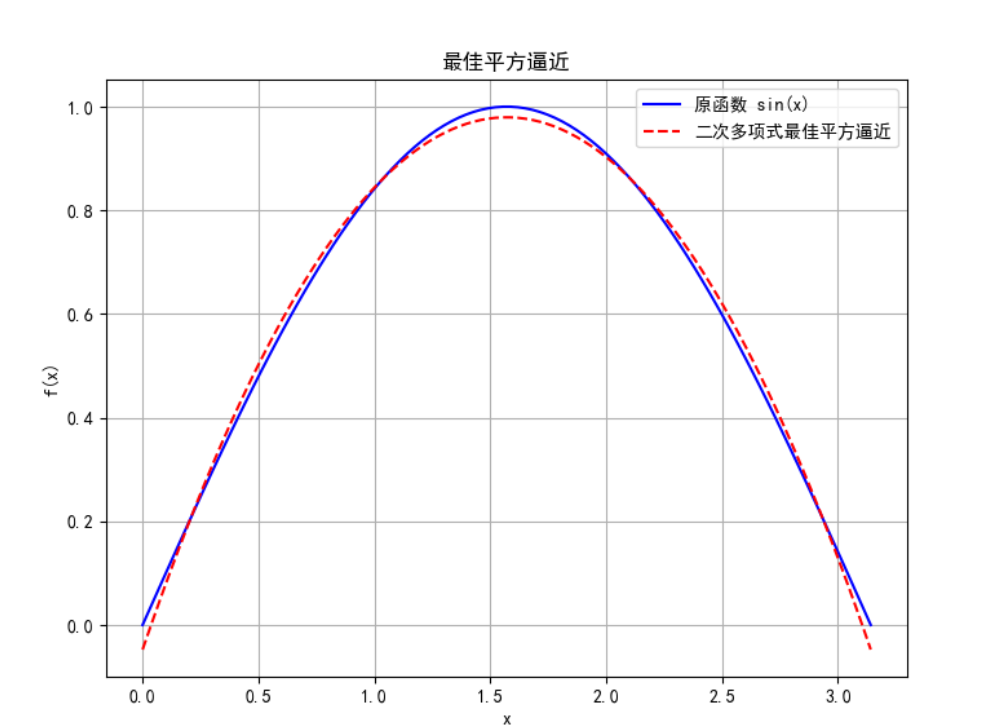
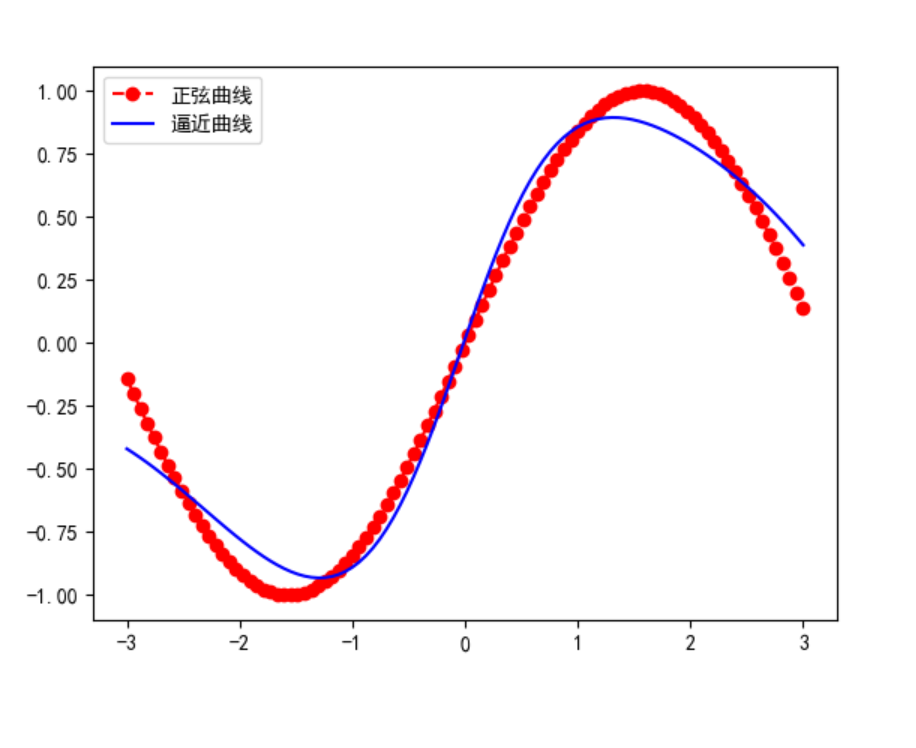
综合案例及应用:最佳平方逼近
案例描述 :对函数 f(x) = sin(x) 在区间 [0, π] 上进行最佳平方逼近,使用二次多项式。
import numpy as np
import matplotlib.pyplot as plt
from numpy.polynomial import Polynomial
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义函数
x = np.linspace(0, np.pi, 100)
f = np.sin(x)
# 使用二次多项式进行最佳平方逼近
poly = Polynomial.fit(x, f, 2)
# 计算逼近多项式的值
f_approx = poly(x)
# 绘图比较
plt.figure(figsize=(8, 6))
plt.plot(x, f, 'b-', label='原函数 sin(x)')
plt.plot(x, f_approx, 'r--', label='二次多项式最佳平方逼近')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('最佳平方逼近')
plt.legend()
plt.grid(True)
plt.show()
# 输出逼近多项式系数
print("逼近多项式系数:", poly.coef)
7.4 核函数逼近
7.4.1 核方法原理
核方法通过将数据映射到高维空间,利用核函数计算映射后的内积,从而在高维空间中进行线性操作,解决低维空间中的非线性问题。
7.4.2 常见核函数
常见的核函数包括线性核、多项式核、径向基函数核和 sigmoid 核等。不同核函数适用于不同类型的数据和问题。
7.4.3 支持向量机及其在函数逼近中的应用
支持向量机(SVM)是一种基于核方法的监督学习算法,用于分类和回归。在函数逼近中,SVM 通过核函数将数据映射到高维空间,寻找最佳超平面来逼近数据。
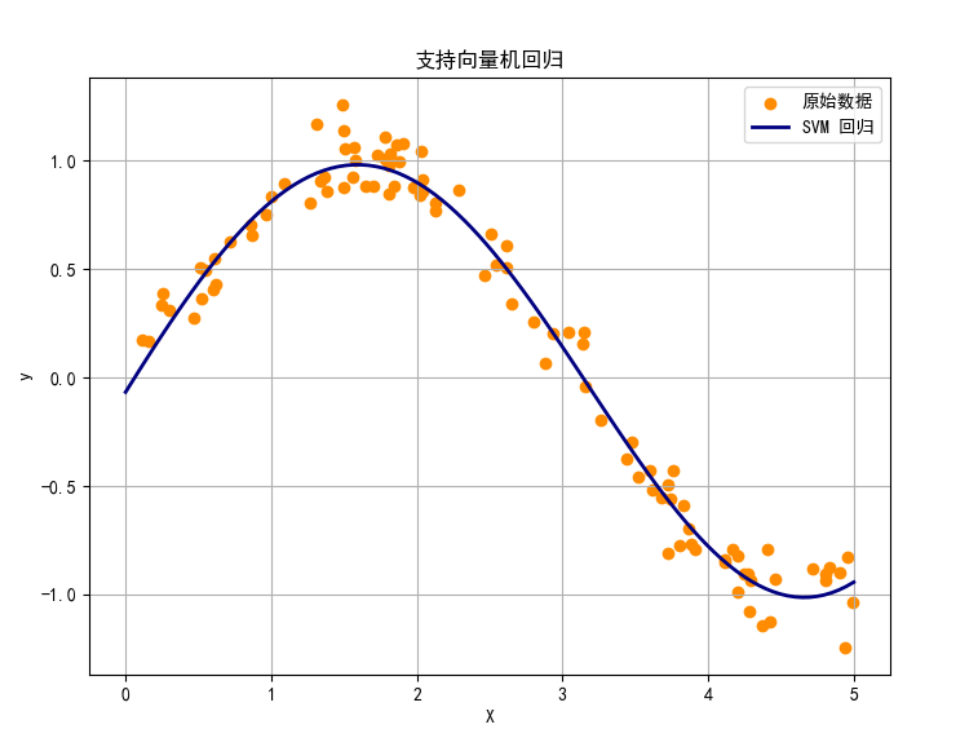
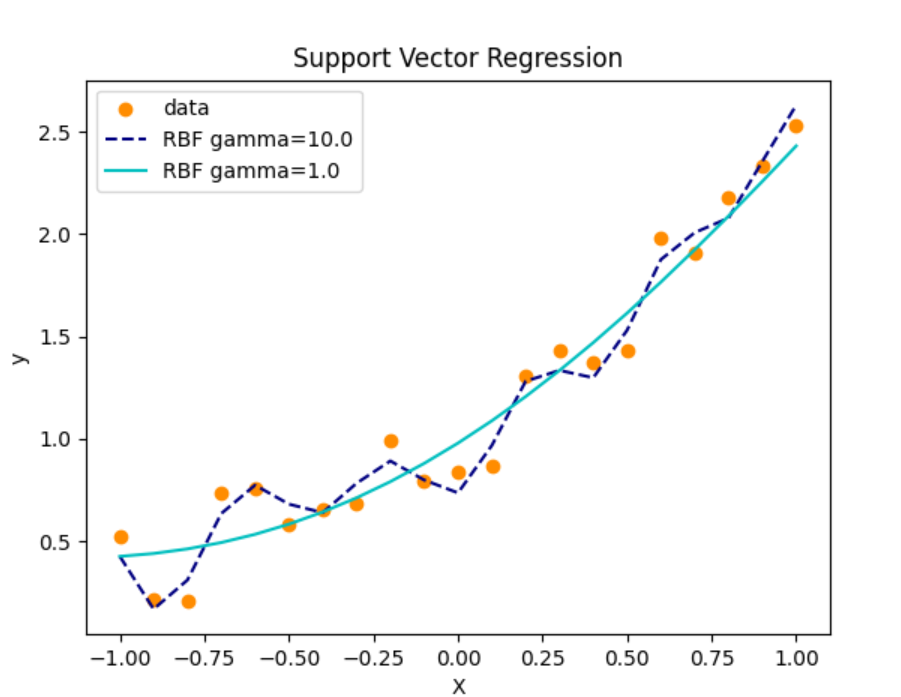
综合案例及应用:支持向量机回归
案例描述 :使用支持向量机回归对非线性数据进行函数逼近。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成非线性数据
X = np.sort(5 * np.random.rand(100, 1), axis=0)
y = np.sin(X).ravel() + 0.1 * np.random.randn(100)
# 标准化数据
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_scaled = scaler_X.fit_transform(X)
y_scaled = scaler_y.fit_transform(y.reshape(-1, 1)).ravel()
# 使用 SVR 进行回归
svr = SVR(kernel='rbf', C=100, gamma=0.1)
svr.fit(X_scaled, y_scaled)
# 预测
X_pred = np.linspace(0, 5, 100).reshape(-1, 1)
X_pred_scaled = scaler_X.transform(X_pred)
y_pred_scaled = svr.predict(X_pred_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1))
# 绘图比较
plt.figure(figsize=(8, 6))
plt.scatter(X, y, color='darkorange', label='原始数据')
plt.plot(X_pred, y_pred, color='navy', lw=2, label='SVM 回归')
plt.xlabel('X')
plt.ylabel('y')
plt.title('支持向量机回归')
plt.legend()
plt.grid(True)
plt.show()
7.5 神经网络逼近
7.5.1 神经网络函数逼近定理
神经网络函数逼近定理指出,具有单个隐藏层的神经网络可以逼近任何连续函数,只要隐藏层神经元数量足够多。这是神经网络在函数逼近中应用的理论基础。
7.5.2 BP 神经网络在函数逼近中的应用
BP 神经网络通过反向传播算法调整网络权重,以最小化预测误差。它在函数逼近中能够学习复杂的非线性关系。
7.5.3 RBF 神经网络在函数逼近中的应用
RBF 神经网络使用径向基函数作为隐藏层神经元的激活函数,对局部特征敏感,具有良好的逼近性能。
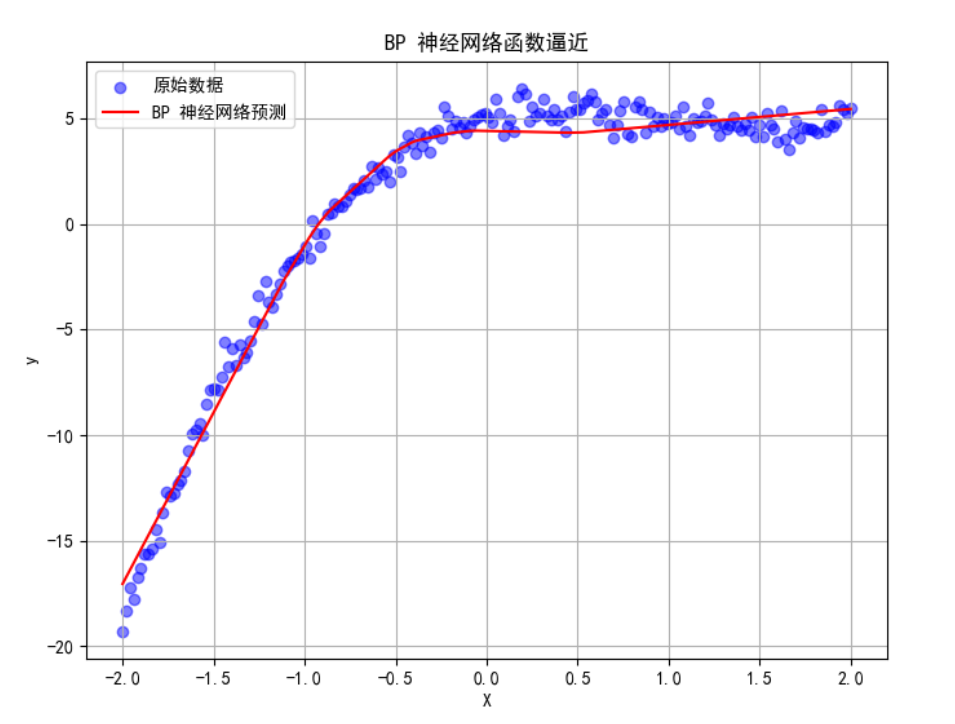
综合案例及应用:BP 神经网络函数逼近
案例描述 :使用 BP 神经网络对非线性函数进行逼近。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPRegressor
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成非线性数据
X = np.linspace(-2, 2, 200).reshape(-1, 1)
y = X**3 - 3*X**2 + 2*X + 5 + 0.5 * np.random.randn(200, 1)
# 创建 BP 神经网络回归模型
mlp = MLPRegressor(hidden_layer_sizes=(10, 10), activation='relu', solver='adam', max_iter=1000)
mlp.fit(X, y)
# 预测
X_pred = np.linspace(-2, 2, 200).reshape(-1, 1)
y_pred = mlp.predict(X_pred)
# 绘图比较
plt.figure(figsize=(8, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='原始数据')
plt.plot(X_pred, y_pred, color='red', label='BP 神经网络预测')
plt.xlabel('X')
plt.ylabel('y')
plt.title('BP 神经网络函数逼近')
plt.legend()
plt.grid(True)
plt.show()
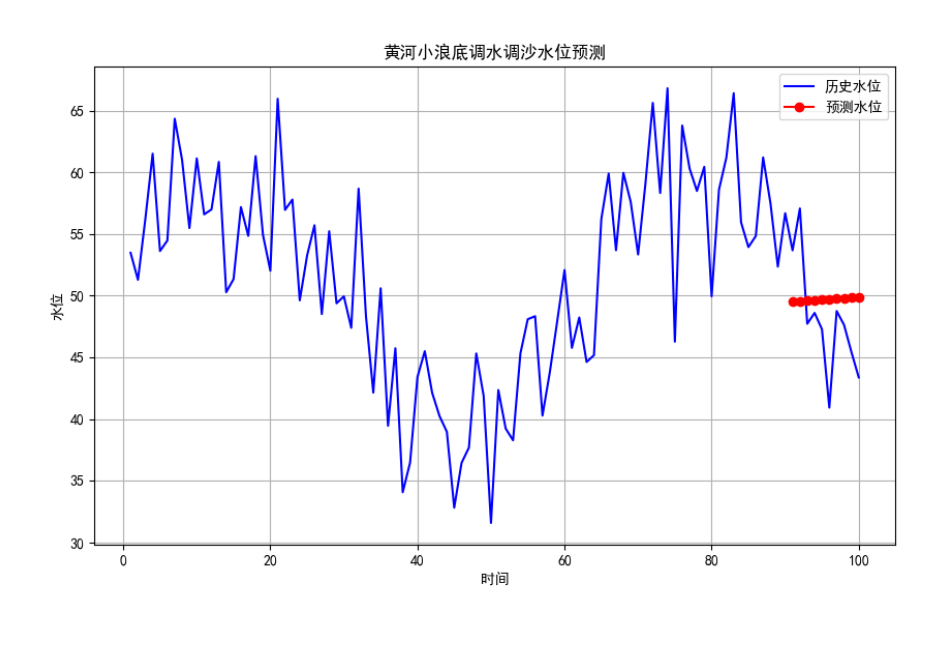
7.6 实验:黄河小浪底调水调沙问题
7.6.1 实验目的
通过函数逼近方法,模拟黄河小浪底调水调沙过程中的水位变化,提高对函数逼近技术在实际工程问题中应用的理解。
7.6.2 实验要求
利用给定的历史水位数据,构建函数逼近模型,预测未来一段时间内的水位变化,并评估模型精度。
7.6.3 实验原理
采用多项式插值、样条插值和神经网络逼近等方法,对水位时间序列数据进行建模和预测。
7.6.4 实验步骤
-
收集黄河小浪底调水调沙的历史水位数据。
-
对数据进行预处理,包括缺失值处理和归一化。
-
分别使用多项式插值、样条插值和 BP 神经网络构建预测模型。
-
用测试数据评估模型的预测精度。
-
比较不同模型的性能,选择最优模型进行未来水位预测。
7.6.5 实验结果
以 BP 神经网络为例 :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import MinMaxScaler
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载历史水位数据(这里假设数据已加载到 variables 中)
# 例如:dates 为时间序列,water_levels 为对应水位
# dates, water_levels = np.load('water_level_data.npy')
# 生成模拟数据(实际应用中请替换为真实数据)
np.random.seed(42)
dates = np.arange(1, 101).reshape(-1, 1)
water_levels = 50 + 10 * np.sin(dates / 10) + 5 * np.random.randn(100, 1)
# 数据归一化
scaler_date = MinMaxScaler()
scaler_water = MinMaxScaler()
dates_scaled = scaler_date.fit_transform(dates)
water_levels_scaled = scaler_water.fit_transform(water_levels)
# 构建时间序列特征(这里简化为直接使用日期作为特征)
X = dates_scaled[:-1] # 使用前一天的日期作为特征
y = water_levels_scaled[1:] # 预测当天的水位
# 创建并训练 BP 神经网络
mlp = MLPRegressor(hidden_layer_sizes=(10, 10), activation='relu', solver='adam', max_iter=1000)
mlp.fit(X, y.ravel())
# 预测
X_pred = dates_scaled[-10:] # 预测未来 10 天的水位
y_pred_scaled = mlp.predict(X_pred)
y_pred = scaler_water.inverse_transform(y_pred_scaled.reshape(-1, 1))
# 绘图展示预测结果
plt.figure(figsize=(10, 6))
plt.plot(dates, water_levels, 'b-', label='历史水位')
plt.plot(dates[-10:], y_pred, 'ro-', label='预测水位')
plt.xlabel('时间')
plt.ylabel('水位')
plt.title('黄河小浪底调水调沙水位预测')
plt.legend()
plt.grid(True)
plt.show()
7.7函数逼近知识点总结
| 概念 | 定义与说明 | 常见方法与应用场景 |
|---|---|---|
| 函数插值 | 构造函数使其经过给定数据点 | 线性插值、多项式插值、样条插值、径向基函数插值 |
| 曲线拟合 | 寻找最佳拟合曲线,使误差最小化 | 线性最小二乘法、非线性曲线拟合、贝塞尔曲线拟合 |
| 最佳逼近 | 在函数空间中寻找与目标函数距离最小的函数 | 最佳一致逼近、最佳平方逼近 |
| 核函数逼近 | 利用核函数将数据映射到高维空间进行线性逼近 | 支持向量机回归、常见核函数(线性核、多项式核、径向基函数核、sigmoid 核) |
| 神经网络逼近 | 使用神经网络学习数据分布,进行函数逼近 | BP 神经网络、RBF 神经网络 |
通过本文的系统学习,希望大家对函数逼近在人工智能中的应用有了更深入的理解。在实际操作中,多进行代码练习,可以更好地掌握这些数学工具,为人工智能的学习和实践打下坚实的基础。在面对实际问题时,能够灵活选择合适的函数逼近方法,解决复杂的数据建模和预测问题。资源绑定附上完整资源供读者参考学习!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









