






在学习 Python 数据分析在工业互联网领域的应用过程中,我收获颇丰。以下是我的一些心得体会。
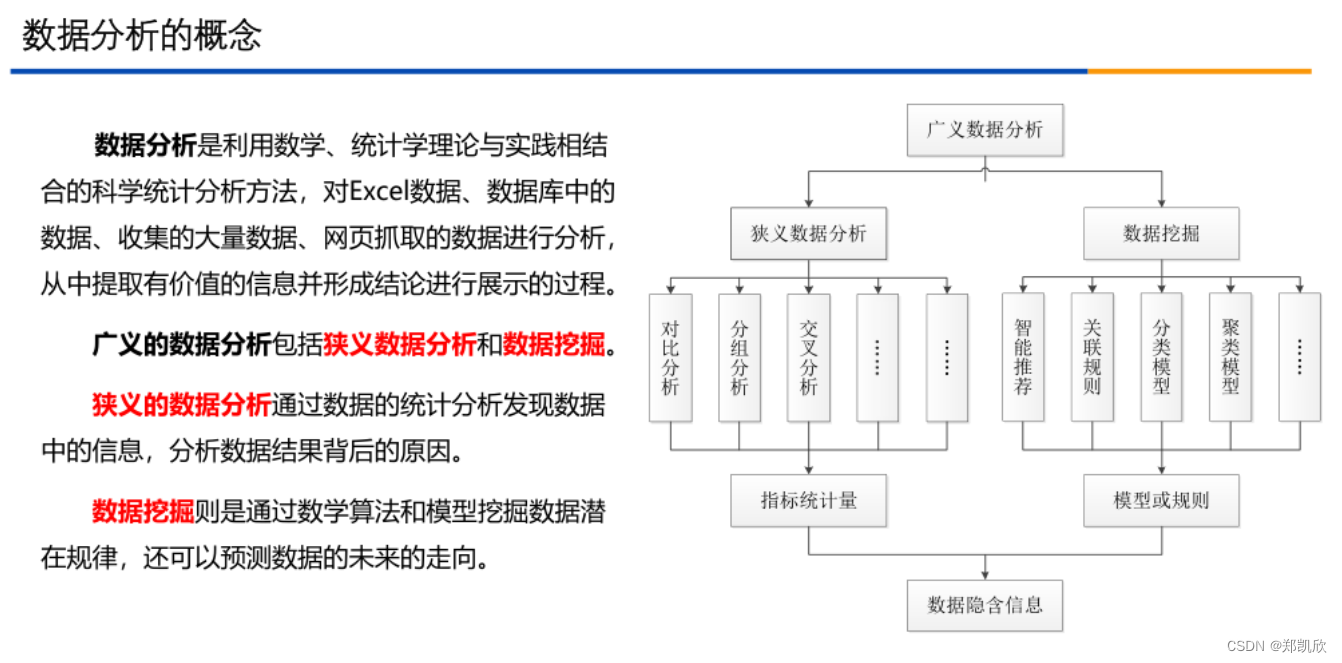
一、数据分析概况
Python 已经成为数据分析领域的强大工具,具有丰富的库和功能,使其能够处理、分析和可视化各种类型和规模的数据。
二、Python依赖的对象
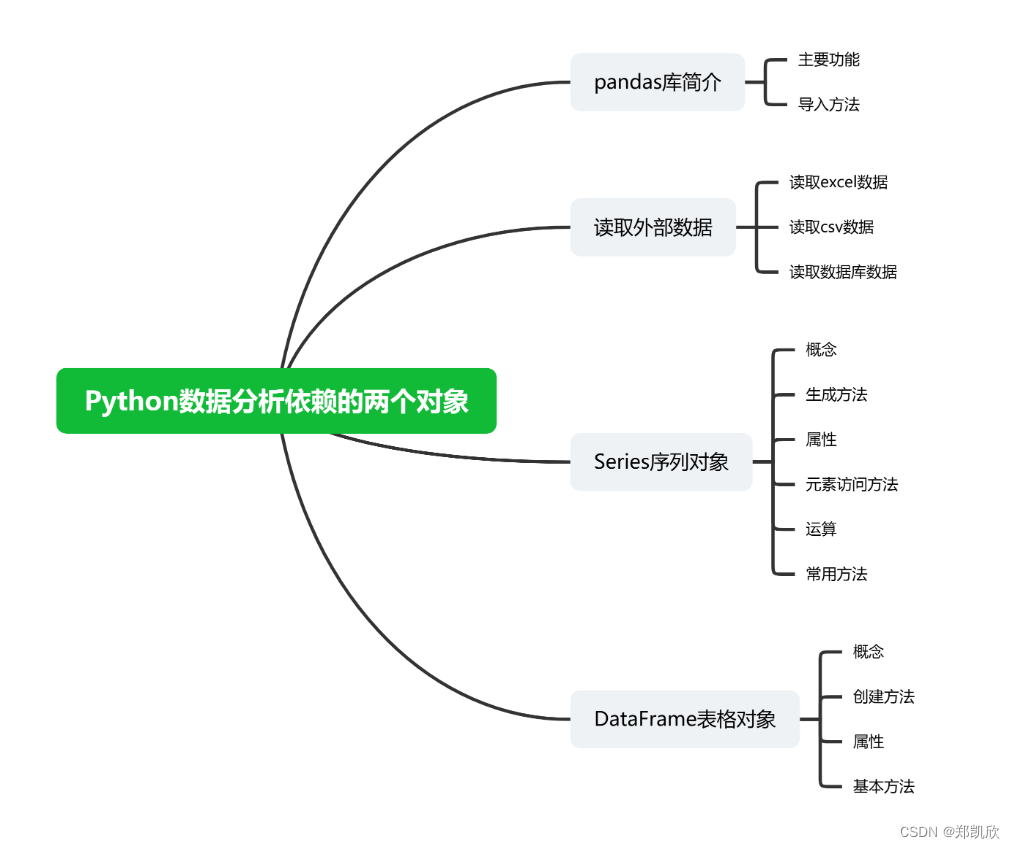
pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
常用的数据结构:
Series:一维的带标签数组。DataFrame:二维的表格结构,由行索引和列索引组成。
示例代码:
import pandas as pd
# 从 CSV 文件读取数据
data = pd.read_csv('data.csv')
# 查看数据的前几行
print(data.head())
# 选择特定的列
selected_data = data[['column1', 'column2']]
# 过滤满足条件的行
filtered_data = data[data['column3'] > 10]
pandas 在数据预处理、探索性数据分析和构建数据集等任务中被广泛使用,是 Python 数据科学和分析领域的重要工具
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
在上述代码中,整个脚本依赖于 pandas 库来创建和操作 DataFrame 对象
在 Python 的 pandas 库中,Series 是一种一维的标签化数组对象。
import pandas as pd
# 通过列表创建
s1 = pd.Series([1, 3, 5, 7, 9])
# 通过字典创建,键将成为索引
s2 = pd.Series({'a': 10, 'b': 20, 'c': 30})
可以通过索引来访问 Series 中的元素
在 Python 的 pandas 库中,DataFrame 是一种二维的表格型数据结构,类似于电子表格或关系型数据库中的表。

三、数据预处理

以下是一个使用 Python 的 pandas 库进行数据预处理的简单示例代码,包括处理缺失值、删除重复行和数据标准化:
import pandas as pd
from sklearn.preprocessing import StandardScaler
def data_preprocessing(data):
# 处理缺失值
data.fillna(data.mean(), inplace=True)
# 删除重复行
data.drop_duplicates(inplace=True)
# 数据标准化
scaler = StandardScaler()
data = pd.DataFrame(scaler.fit_transform(data), columns=data.columns)
return data
# 示例用法
data = pd.read_csv('your_data.csv')
preprocessed_data = data_preprocessing(data)
print(preprocessed_data)
在上述代码中:
- 首先,使用
fillna方法并用均值填充缺失值。 - 然后,使用
drop_duplicates方法删除重复的行。 - 最后,使用
StandardScaler进行数据标准化。
四、数据可视化
数据可视化是将数据以图形、图表等直观的形式展示出来,以便更有效地理解和分析数据。
常见的数据可视化工具和库
matplotlib:Python 中最基础、最广泛使用的绘图库,提供了丰富的绘图功能。seaborn:基于matplotlib构建,提供了更高级、更美观的绘图接口。plotly:支持交互性的绘图库,可以创建动态和可交互的图表。ggplot:模仿 R 语言中ggplot2的绘图风格。

Pyecharts团队提供了官网和社区。
其中官网有Pyecharts的使用文档,社区包含各种图形的项目案例代码和演示。
社区:DocumentDescription![]() https://gallery.pyecharts.org/#/README
https://gallery.pyecharts.org/#/README
常见的数据可视化图表类型
-
折线图:用于展示随时间或其他连续变量变化的数据趋势。
-
柱状图:比较不同类别之间的数据量或大小。
-
饼图:展示各部分占总体的比例关系。
-
箱线图:展示数据的分布情况,包括四分位数、异常值等。
-
散点图:用于观察两个变量之间的关系。
-
热力图:适合展示矩阵形式的数据,通过颜色深浅表示数值大小。
示例代码(使用 matplotlib)
import matplotlib.pyplot as plt
import numpy as np
# 生成示例数据
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x)
# 绘制折线图
plt.plot(x, y)
plt.xlabel('X 轴')
plt.ylabel('Y 轴')
plt.title('正弦曲线')
plt.show()
# 绘制柱状图
data = [10, 20, 30, 40, 50]
labels = ['A', 'B', 'C', 'D', 'E']
plt.bar(labels, data)
plt.xlabel('类别')
plt.ylabel('数量')
plt.title('不同类别的数量对比')
plt.show()
通过选择合适的图表类型和遵循良好的可视化原则,可以让数据更具可读性和洞察力,帮助我们更好地理解和分析数据。
五、持续学习与实践
工业互联网领域不断发展,新的技术和方法不断涌现。持续学习和实践是保持竞争力的关键。
参加相关的在线课程、阅读最新的研究文献,以及参与实际项目,都有助于提升自己在 Python 数据分析在工业互联网领域的能力。
总之,学习 Python 数据分析在工业互联网中的应用是一个充满挑战但也极具收获的过程。不断积累经验,将理论与实践相结合,才能更好地应对实际工作中的各种数据分析任务。
希望以上的心得能对正在学习这一领域的朋友们有所帮助,让我们共同在工业互联网数据分析的道路上不断前进!















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









