






一、我们先分析网页
首先 我们要爬的网址是:PPT模板下载_PPT模板免费下载_幻灯片模板下载 -【优品PPT】
在浏览器地址栏输入这个网址访问进去,里面有很多PPT模板
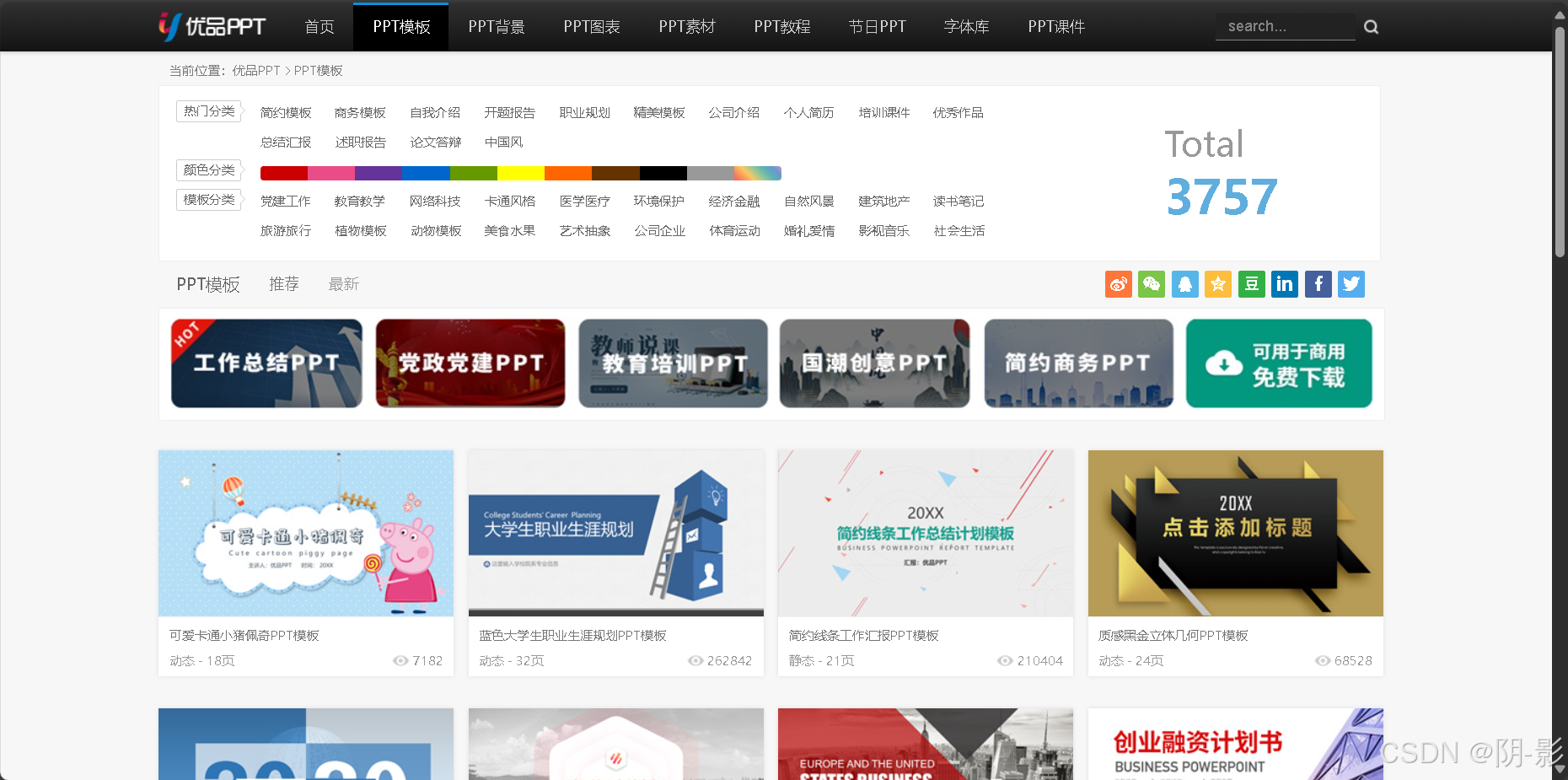
我们随机点击一个进去,再点击下载 ,如图
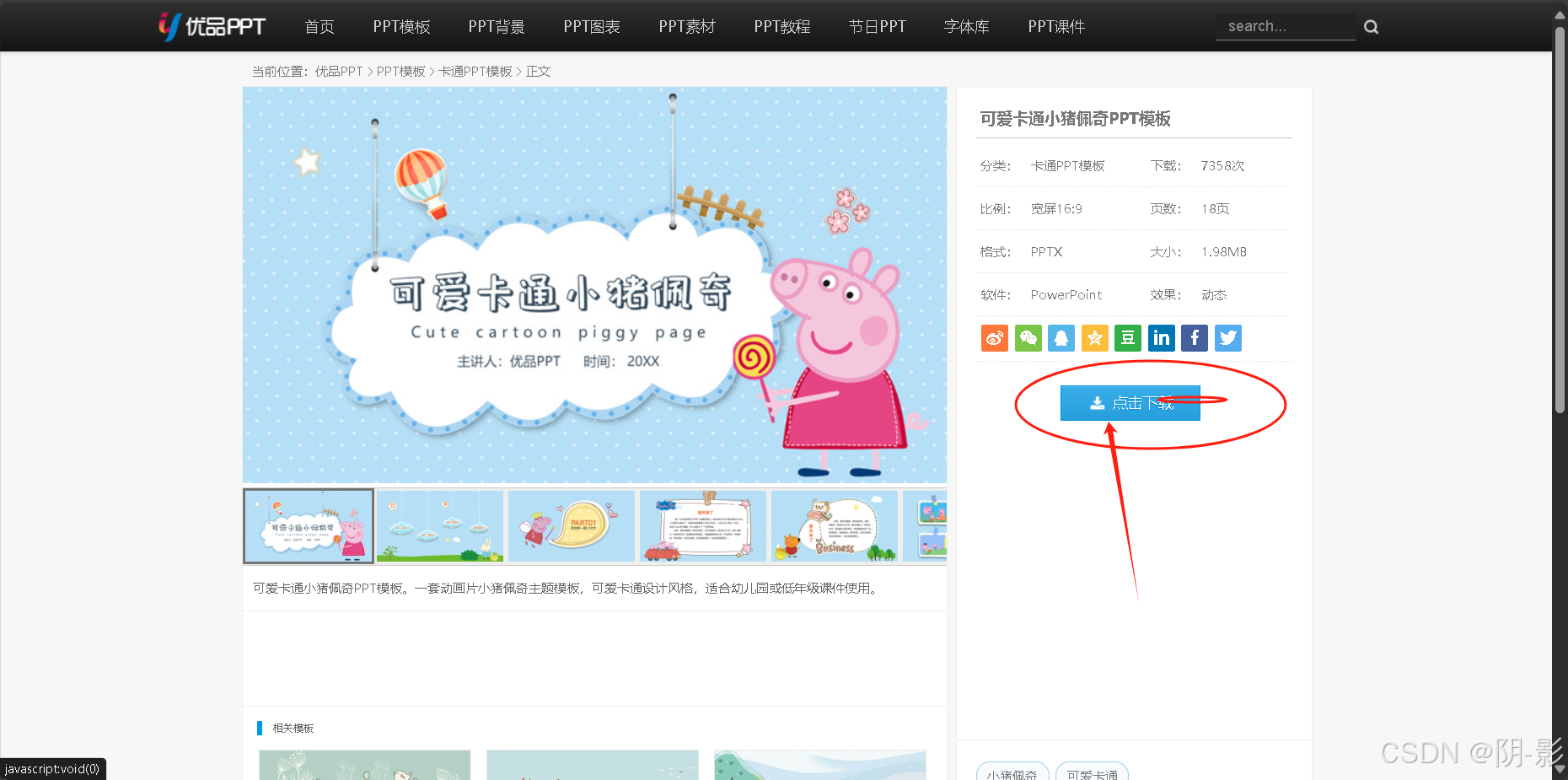
我们拿一下下载页面的网址可爱卡通小猪佩奇PPT模板 - 优品PPT
然后点击下载,会跳转一个网址
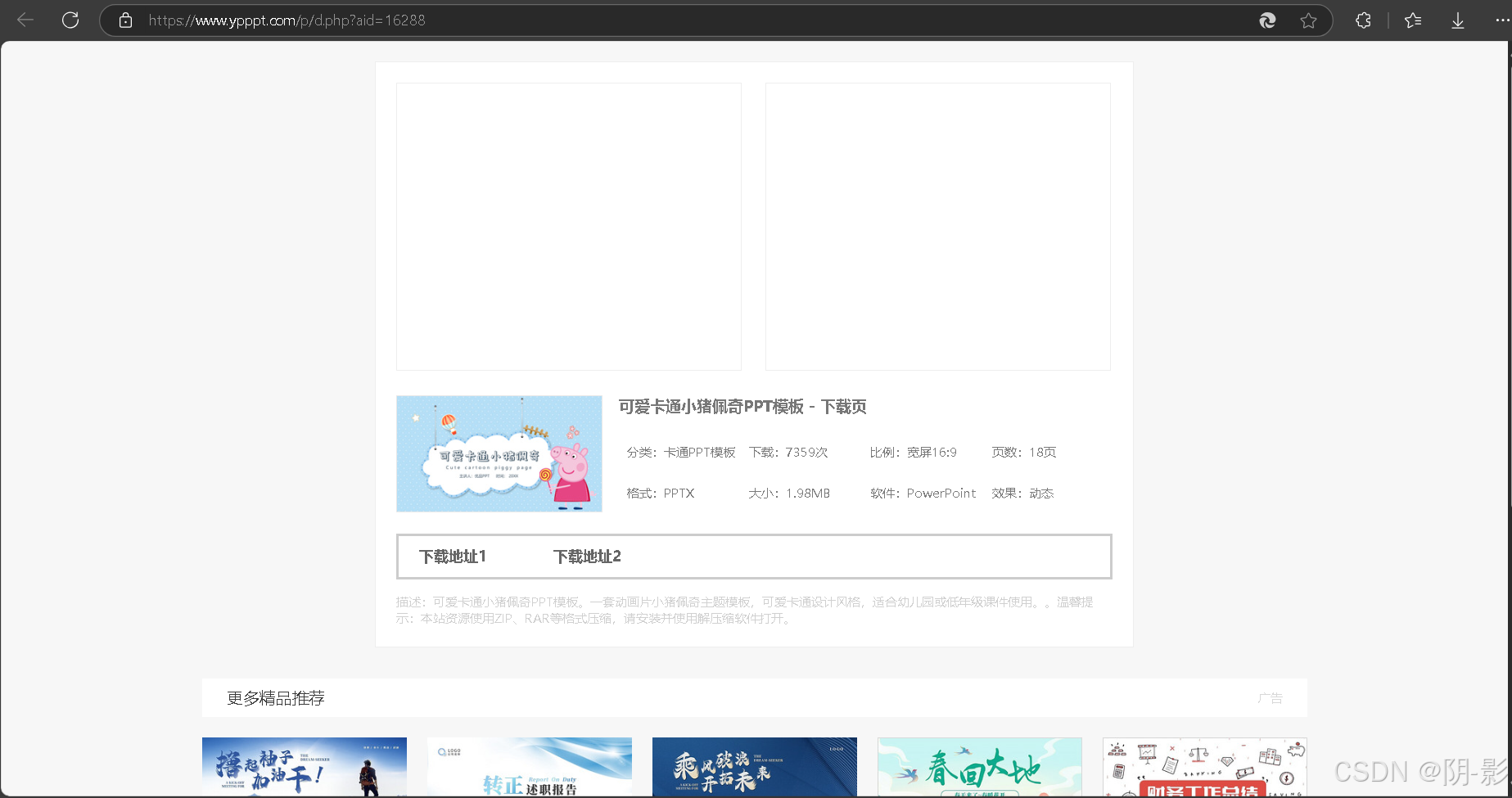
紧接着,我们点击下载地址1或下载地址2,会直接下载
二、代码实现
首先先导入我们的requests 模块 -----需安装
pip install requests紧接着写入代码
import requests #导入请求模块
url = 'https://www.ypppt.com/moban/'
res = requsets.get(url=url,headers=headers)
print(res.text)最基本的请求网址获取数据
然后就是我们的提取数据
采用正则表达式提取数据 -------导入正则模块 import re
data =re.findall('href="/article/.*?/(.*?).html"', res.text)
拿到我们的下载网址的id,并用for循环遍历(为什么用for循环),因为re提取出来的是一个列表数据。
用正则表达式提取
在把id拼接到我们的下载网址后面(注意是下载网址,不是首页的网址)
https://www.ypppt.com/article/2024/16288.html然后请求我们的这个网址的到https://down.ypppt.com/uploads/soft/240909/1-240Z91R306.pptx
接下来就是保存数据
下面就是完整代码
import requests #导入请求模块
import re #导入正则表达式模块
import time #导入时间模块
import os
folder_name = 'PPT素材模板'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
else:
print('该文件夹已存在')
#请求网址
# 伪装浏览器
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
page = 1
while True:
if page == 1:
url = 'https://www.ypppt.com/moban/'
else:
url = f'https://www.ypppt.com/moban/list-{page}.html'
#发送请求
res = requests.get(url=url, headers=headers)
if res.status_code==404:#打印请求状态码
break
res.encoding = 'utf-8' #换编码 ----- 换成万国码 utf-8
#'https://www.ypppt.com/p/d.php?aid=351' #下载页面网址
#找到所有的id
#'https://down.ypppt.com/uploads/soft/141215/1-141215104631.zip' #下载地址
#获取数据
# print(res.text)
#提取数据
data =re.findall('href="/article/.*?/(.*?).html"', res.text)
# print(data)
for aid in data:
moban_url = 'https://www.ypppt.com/p/d.php?aid=' + aid
res1 = requests.get(url=moban_url, headers=headers)
ppt_url = re.findall('<a href="(.*?)">下载地址1</a>',res1.text)[0]
file_names = re.findall('<title>(.*?) - 下载页</title>', res1.text)[0]
# print(file_names)
if 'pan.baidu'in ppt_url:
continue
else:
houzhui = ppt_url.split('.')[-1]
res2 = requests.get(url=ppt_url, headers=headers)
#保存数据
file_include = os.path.join(folder_name,f'{file_names}-{aid}.{houzhui}')
open(file_include, mode='wb').write(res2.content)
time.sleep(2)
page += 1
'''正则表达式用法 ----找到宿舍文字并打印'''
'''非贪婪模式'''
# text = '小路笑话西安出啊宿舍第三步选爱吃'
# result = re.findall('啊(.*?)第', text)[0]
# print(result)
'''贪婪模式'''
# text = '小路笑话西安出啊宿舍第三步选爱吃'
# result1 = re.findall('西安(.*)第', text)
# print(result1)

















 7879
7879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









