






第10节课 元组、集合与字典
1 元组
元组是一个有序但不可变的序列(元素内容,以及序列长度不可变),使用圆括号()来创建元组。
那我们可以把元组理解为是一个不可变的列表。
既然是序列,那么序列的通用操作(索引、切片、len、in和not int)同样适用于元组。
tup = ()
tup = tuple()
tup = (1,2,3)
lst = [4,5,6]
# 将一个列表转换为元组
tup = tuple(lst)
# 将一个字符串转换为元组
tup = tuple("Hello")
# 如果元组只有一个元素的话
tup = (1) # <class 'int'>
# 加一个逗号
tup = (1,) # <class 'tuple'>
# 也可以不用括号来去创建元组
tup = 7,8,9
# 输入数据时 用逗号分隔
# 输入"1,2,3"
# tup = 1,2,3
# eval执行代码
# 输入"a,b,c"
# tup = a,b,c # NameError: name 'a' is not defined
# 输入"'a','b','c'""
# tup = 'a','b','c'
# tup = eval(input())
def show():
# 多个返回值 实际上 返回的是一个元组对象
return 9,10,11
tup = show()
# 元组的解包
# a,b,c = (9,10,11)# tup
# a = tup[0] b = tup[1] c = tup[2]
a,b,c = show()
print(a,b,c)
print(tup)
print(type(tup)) # <class 'tuple'>
tup = (1,2,3,4,5,6,7,8,9)
# ValueError: too many values to unpack (expected 3)
# a,b,c = tup
# * 多个元组数据被解包时 创建一个列表
a, *b, c = tup
print(a)
print(b)
print(c)
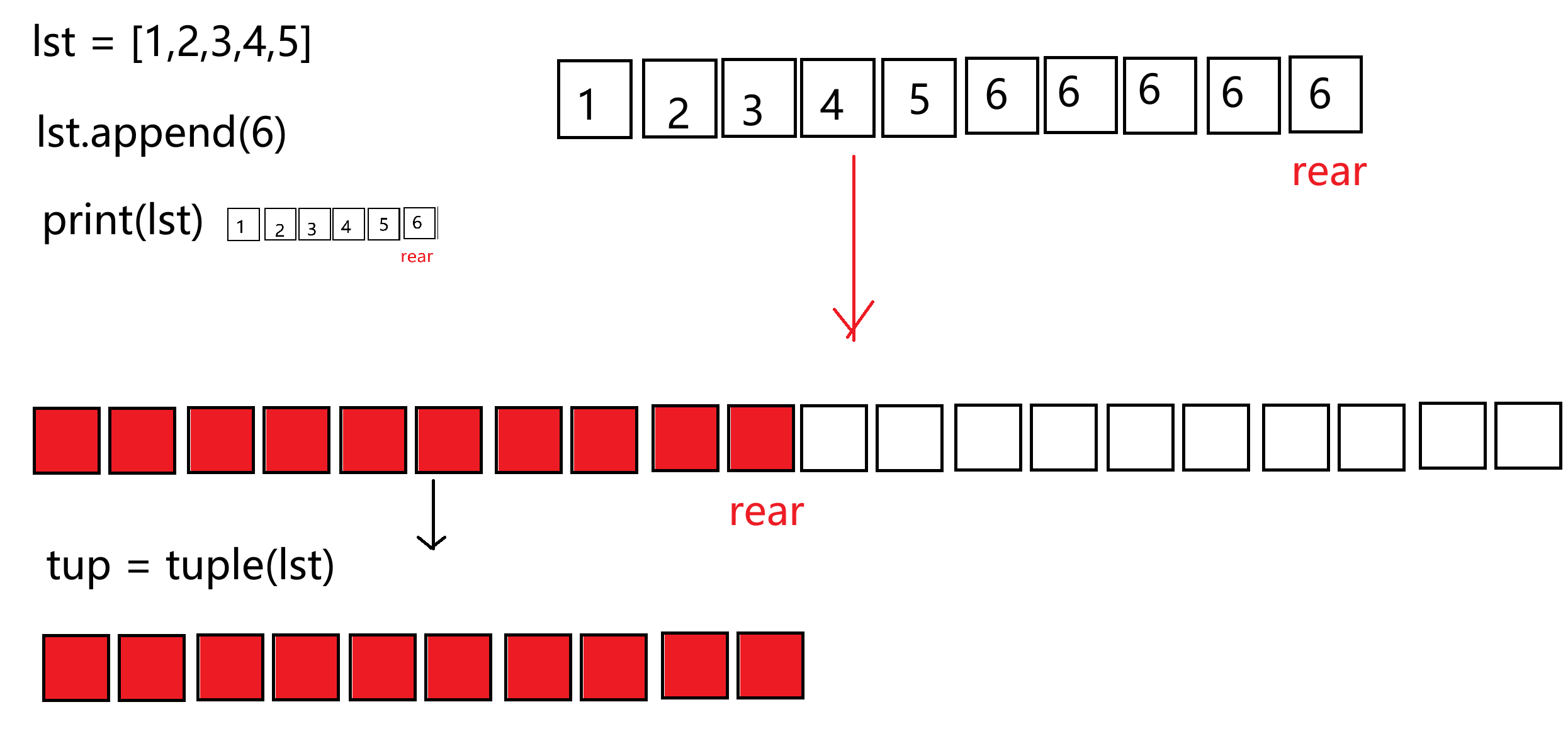
关于不可变的问题,元组中存储的实际上是数据对象在堆内存中的地址,这个存储的地址是不能改变的!同样元组的长度不能改变。但是,如果元组中存储了可变对象的话,那么可变对象内部的数据是可以修改的!
tup = (1,2,3,4)
print(tup[0])
# TypeError: 'tuple' object does not support item assignment
# tup[0] = 666
tup = (1, [2, 3], 4)
print(tup[1])
# TypeError: 'tuple' object does not support item assignment
# tup[1] = [6,7]
tup[1][0] = 8
print(tup) # (1, [8, 3], 4)
既然是不可变,那么元组就不会提供关于增、删和改的操作,顶多有个查
元组对象函数只有两个
- count():统计某一个元素出现的次数
- index():查找元素第一次出现的位置角标,如果没找到则报错
tup = (1,1,1,2,2,3,3,3,3,3)
print(tup.count(3))
print(tup.index(1))
# ValueError: tuple.index(x): x not in tuple
# print(tup.index(4))
# AttributeError: 'tuple' object has no attribute 'sort'
# tup.sort()
关于元组存在的一个必要性
- 因为元组是不可变的,所以今后我们在定义编程数据时,如果发现有些数据其内容是不能修改的,我可能可以考虑使用元组(坐标,时间,属性);可以作为字典的键(作为一种索引)。
- 时间效率更高,同样内容的列表和元组,后者的创建时间会更小;比如,在进行大批量数据处理和分析时。
import timeit
# 计算stmt代码在执行number次后,所用的时间是多少
time1 = timeit.timeit(stmt = "[1,2,3,4,5,6,7,8,9,10]", number = 1000000)
time2 = timeit.timeit(stmt = "(1,2,3,4,5,6,7,8,9,10)", number = 1000000)
print(time1) # 0.03029770008288324
print(time2) # 0.005637900088913739
- 内存更小,同样内容的列表和元组,后者所需的内存空间会更小;比如,在进行大批量数据处理和分析时。
import sys
lst = []
for i in range(1,10000):
lst.append(i)
tup = tuple(lst)
# 获取数据对象的内存大小
size1 = sys.getsizeof(lst)
size2 = sys.getsizeof(tup)
print(size1) # 85176 字节 byte
print(size2) # 80032 字节 byte
因为在列表中,除了存储元素之外,还会存储一些长度信息、表尾的信息、闲置位置的信息。
2 集合
集合是一个无序的、不包含重复元素的集合体,使用花括号{}来表示。注意 不是序列!!!
- 无序:集合中的元素没有固定顺序,每次打印集合时,可能元素顺序是不同的
- 不包含重复元素:元素在集合中时唯一存在的
主要应用场景:
- 关于集合数学运算的:交集、并集、差集、子集、超集
- 做重复元素去重操作
st = {} # 字典也是用{}表示的
st = set()
st = {3,1,2,6,5,8,7,9,4} # {1, 2, 3, 4, 5, 6, 7, 8, 9} 不代表排序了 特殊情况
st = {"C","A","E","F","B","D","D"}
lst = [1,2,3,3,4,4,2,1,3,5,2,5,8,3,4,6,8,9,3,4,2]
st = set(lst)
st = set("banana")
# TypeError: 'set' object is not subscriptable
# print(st[0])
print(st)
print(type(st))
关于集合常用操作
- add():向集合中添加一个元素
- remove():在集合中删除一个指定的元素,如果元素不存在则报错
- discard():在集合中删除一个指定的元素,如果元素不存在,不会报错
- update():添加多个元素进入到集合中,列表、元组、其他集合等可迭代的数据对象
- pop():随机删除一个元素
- clear():清空
st = set()
st.add(1)
st.add(3)
st.add(2)
print(st)
st.remove(2)
print(st)
# KeyError: 4
# st.remove(4)
st.update([1,2,3,4,5,6,7,8,9,9,9,1,2,3,4,4,4])
st = {"C","A","E","F","B","D"}
while len(st) != 0:
print(st.pop())
print(st)
关于集合的数学操作
set1 = {1,2,3}
set2 = {3,4,5}
# 并集
print(set1 | set2)
print(set1.union(set2))
print(set2.union(set1))
# 交集
print(set1 & set2)
print(set1.intersection(set2))
print(set2.intersection(set1))
# 差集 在set1中存在但不在set2中存在的元素
print(set1 - set2)
print(set2 - set1)
print(set1.difference(set2))
print(set2.difference(set1))
# 对称差集 获取两个集合中不共同的元素
# 并集 - 交集
print(set1 ^ set2)
print(set2 ^ set1)
print(set1.symmetric_difference(set2))
# 子集与超集的问题
set1 = {1, 2}
set2 = {1, 2, 3}
# set1是否是set2的子集
print(set1 < set2)
# set1是否是set2的真子集
print(set1 <= set2)
# 判断真子集
print(set1.issubset(set2))
print(set1.issuperset(set2))
print(set2.issuperset(set1))
set1 = {1,2,3}
set2 = {2,1,3}
print(set1 == set2) # 判断内容是否相等
延伸:为什么说集合是无序的,且pop是随机的【了解 理解】
在Python中,集合底层的数据结构为哈希表(广义表),说白了也是一个一维数组,只不过不是按照角标顺序进行存储的,而是根据哈希函数算得该元素的哈希值,来决定元素的存储位置。如果元素之间的哈希值一样的话,这个现象叫做哈希冲突,如果出现哈希冲突的话,先看元素是否相等,相等的话就不存储。如果元素不相等,且出现哈希冲突的话:
开放定址法:当发生哈希冲突时,通过一定的探测序列在哈希表中寻找下一个空的位置来存储数据。常见的探测方法有线性探测、二次探测和双重哈希等。【Python集合底层的实现思路】
线性探测:从发生冲突的位置开始,依次向后探测下一个位置,直到找到空位置为止。例如,哈希函数计算出的位置为 i,如果 i 位置已被占用,则依次探测 i+1、i+2、i+3 等位置。
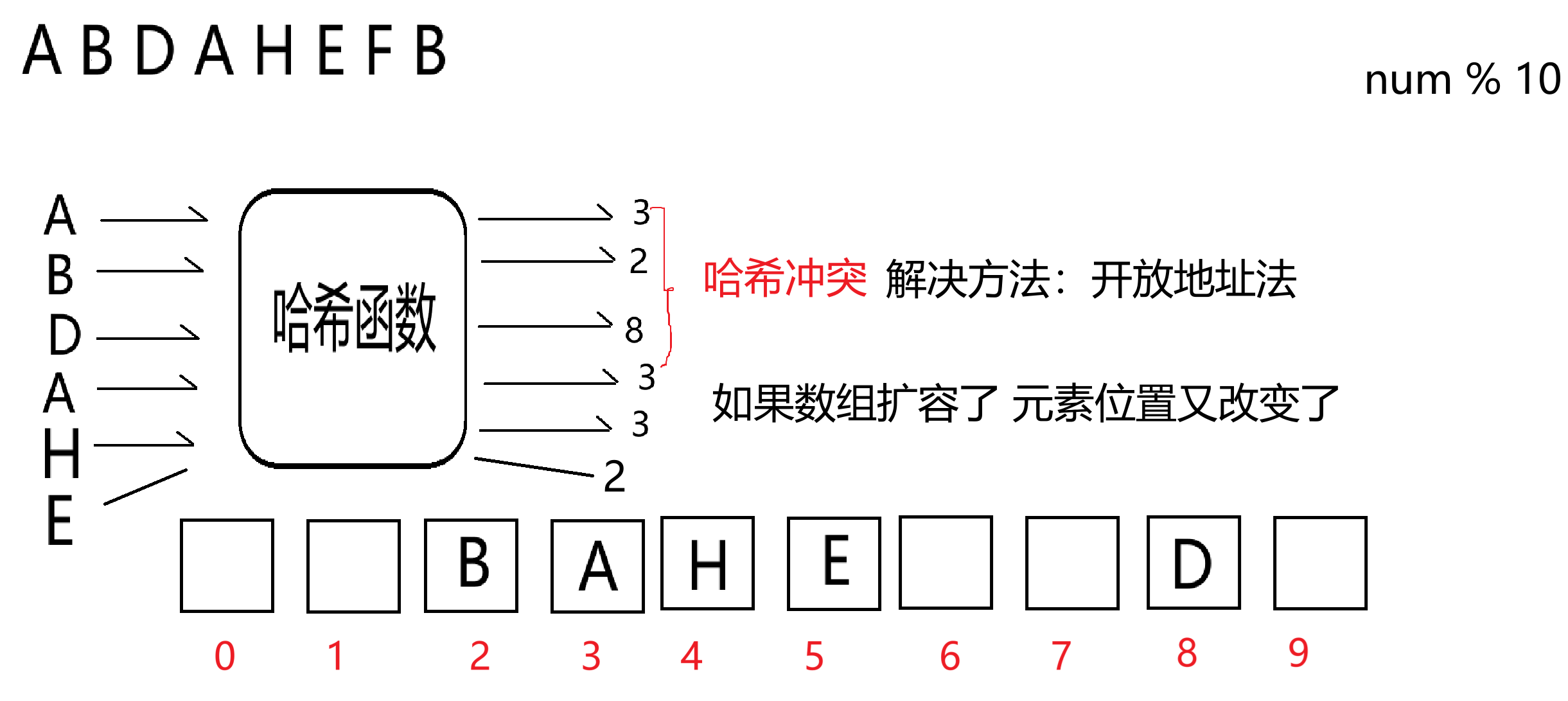
总而言之:哈希函数的策略、哈希冲突的解决方法、哈希表底层的扩容问题,都会导致元素的顺序不能直接确定,这就是集合为什么无序的原因。但是可以确定的是,实际上pop就是从左到右删除。
3 字典
字典是一个无序的键值对的集合,每个键值对之间用逗号,分隔,键和值之间用冒号:分隔,使用花括号{}来表示。所谓的字典,其实就是一个特殊的集合而已。键必须是唯一的,值是可以重复的。也就是说所有键组成一个集合,所有的值组成一个列表。
dic = {"姓名":"张三", "年龄":18, "性别":"男"}
dic = dict(name = "张三", age = 18, sex = "男")
# 可以汉字做标识符 但不推荐
数字 = 3
print(数字)
dic = dict(姓名 = "张三", 年龄 = 18, 性别 = "男")
lst = [("name", "张三"), ("age", 18), ("sex", "男")]
dic = dict(lst)
print(dic)
# 获取字典的内容
print(dic["name"])
# 不存在的键 则报错
# KeyError: 'girlfriend'
# print(dic["girlfriend"])
print(dic.get("name"))
# 可以看到 所谓的键 大胆的理解为 角标
dic = {0:1,1:2,2:3,3:4}
print(dic)
添加或修改字典:通过给不存在的键进行赋值可以添加新的键值对,如果该键已存在,则为修改
dic = {"name":"张三", "age":18}
dic["name"] = "李四" # 修改
dic["sex"] = "男" # 添加
print(dic)
删除元素:使用del语句进行删除,也可以使用pop(key)删除指定的键值对。popitem()随机删除一个键值对
dic = {"name":"张三", "age":18}
dic["name"] = "李四" # 修改
dic["sex"] = "男" # 添加
print(dic)
del dic["sex"] # 直接删除sex的键值对 没有任何返回的结果
print(dic)
value = dic.pop("name") # 删除name的键值对 返回name的值
print(value)
print(dic)
dic = {"name":"张三", "age":18, "sex":"男"}
# 随机删除一个键值对,返回值是一个元组,由于字典是无序的,所以删除可能是随机的
print(dic.popitem())
print(dic)
获取字典所有的键、值、键值对
# 键必须是唯一的 如果出现多个键 则以最后一个键的值为准
dic = {"name":"张三", "age":"张三", "sex":"张三", "sex":"女"}
# dict_keys(['name', 'age', 'sex'])
keys = set(dic.keys())
print(keys)
# dict_values(['张三', 18, '男'])
values = list(dic.values())
print(values)
items = list(dic.items())
print(items)
遍历字典的内容
dic = {"name":"张三", "age":"张三", "sex":"张三"}
for key in dic.keys():
print(key)
for value in dic.values():
print(value)
for key, value in dic.items():
print(key, value)
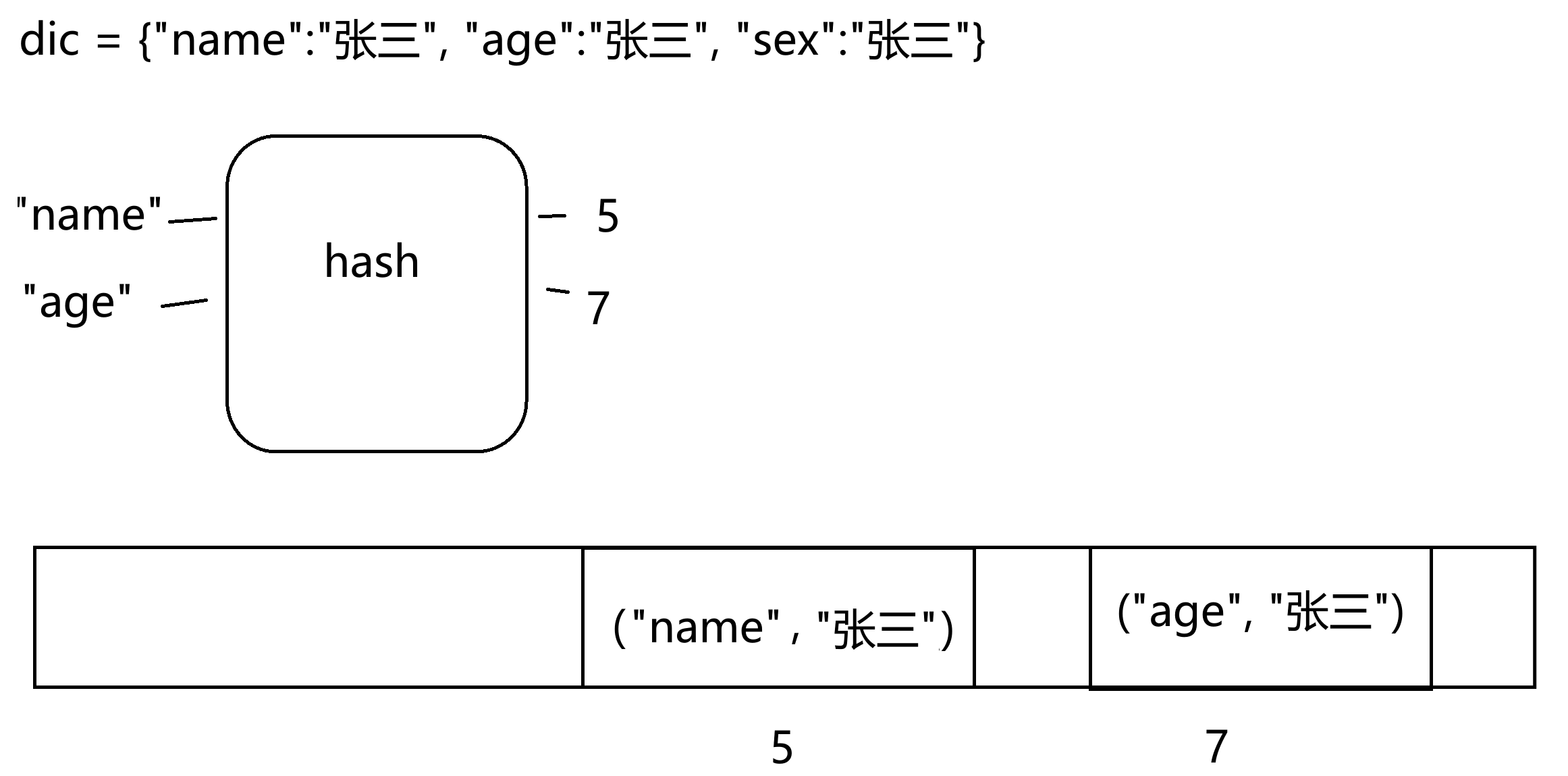
字典的键必须是可哈希的,即就是不可变数据类型(字符串、数字、元组)
字典的本质:底层是哈希表,以键进行哈希来计算存储位置,存储的是键值对的元组对象。
4 内置容器总结
列表
字符串
元组
集合
字典
练习01 密码强度检测
在设计密码强度检测系统时,需要检查密码是否包含不同类型的字符,如大写字母、小写字母、数字和特殊字符。
给定一个密码字符串 password,编写一个函数,使用集合来检查密码中是否同时包含大写字母、小写字母、数字和特殊字符(假设特殊字符为 !@#$%^&*)。如果包含所有类型的字符,返回 True,否则返回 False。
# 思路1
# 用字典给每一个类型做计数
# def check(password):
# pw_dic = {"upper":0, "lower":0, "number":0, "special":0}
# for letter in password:
# if letter.islower():
# pw_dic["lower"] += 1
# elif letter.isupper():
# pw_dic['upper'] += 1
# elif letter.isdigit():
# pw_dic['number'] += 1
# elif letter in "!@#$%^&*":
# pw_dic['special'] += 1
# else:
# return False
# for value in pw_dic.values():
# if value == 0:
# return False
# return True
# 思路2
def check(password):
password = set(password)
upper = set("ABCDEFGHIJKLMNOPQRSTUVWXYZ")
lower = set()
for i in range(26):
lower.add(chr(97 + i))
number = set('0123456789')
special = set('!@#$%^&*')
if len(password - (upper | lower | number | special)) > 0:
return False
return len(password & upper) > 0 and len(password & lower) > 0 and len(password & number) > 0 and len(password & special) > 0
password = input()
print(check(password))
练习02 统计关键字的个数
创建一个字符串变量,内容为某一篇Python源代码,用re.findall(r'\b[a-zA-Z]+\b', sources)解析出所有的英文单词,统计关键字的个数。
sources = """
BEGIN_YEAR = 2000
BEGIN_MONTH = 1
BEGIN_WEEK = 6
def get_month_str(month):
if month == 1:
return "一月"
elif month == 2:
return "二月"
elif month == 3:
return "三月"
elif month == 4:
return "四月"
elif month == 5:
return "五月"
elif month == 6:
return "六月"
elif month == 7:
return "七月"
elif month == 8:
return "八月"
elif month == 9:
return "九月"
elif month == 10:
return "十月"
elif month == 11:
return "十一月"
elif month == 12:
return "十二月"
def print_month_title(month):
print(" ", get_month_str(month))
print(" ---------------------------")
print(" 一 二 三 四 五 六 日")
print()
def is_leapyear(year):
return 400 % year == 0 or (year % 4 == 0 and year % 100 != 0)
def get_days_count(year, month):
if month in [1, 3, 5, 7, 8, 10, 12]:
return 31
elif month in [4, 6, 9, 11]:
return 30
elif is_leapyear(year):
return 29
else:
return 28
def get_days_begin(year, month):
total_days = 0
for i in range(BEGIN_YEAR, year):
if is_leapyear(i):
total_days += 366
else:
total_days += 365
for i in range(BEGIN_MONTH, month):
total_days += get_days_count(year, i)
return (total_days % 7 + BEGIN_WEEK) % 7
def print_month_body(year, month):
days_count = get_days_count(year, month)
days_begin = get_days_begin(year, month)
cur_count = 0
for i in range(days_begin):
print(" ", end="")
cur_count += 1
for i in range(1, days_count + 1):
print("%4d" % i, end="")
cur_count += 1
if cur_count % 7 == 0:
print()
print()
def print_month(year, month):
print_month_title(month)
print_month_body(year, month)
def print_calendar(year):
for month in range(1, 13):
print_month(year, month)
if __name__ == "__main__":
year = int(input("请输入年份(2000年起步):"))
print_calendar(year)
"""
import re
import keyword
kwords = keyword.kwlist
words = re.findall(r'\b[a-zA-Z]+\b', sources)
# print(words)
# print(kwords)
d = dict()
for word in words:
if word in kwords:
if word in d:
d[word] += 1
else:
d[word] = 1
print(d)
练习03 统计单词的个数
创建一个字符串变量,内容为某一篇英文文章,用re.findall(r'\b[a-zA-Z]+\b', sources)解析出所有的英文单词,统计每个英文单词出现的次数。
sources = """
# The Magic of Reading
Reading is a magical journey that transports us to different worlds, times, and perspectives. With a book in hand, we can explore ancient civilizations, visit far - off galaxies, or delve into the human psyche.
One of the greatest benefits of reading is its ability to expand our knowledge. Whether it's a history book, a science manual, or a work of fiction, each page offers new information, ideas, and vocabulary. It also enhances our imagination. When we read, we create vivid images in our minds, which enriches our creativity.
Moreover, reading is a great way to relax. In a world full of stress and distractions, getting lost in a good book allows us to unwind and recharge. It can reduce anxiety and improve our overall well - being.
In conclusion, reading is not just an activity; it's a lifelong companion that educates, inspires, and soothes us. So, pick up a book today and start your own magical adventure.
"""
import re
words = re.findall(r'\b[a-zA-Z]+\b', sources)
print(words)
d = dict()
for word in words:
lower_wd = word.lower()
if lower_wd in d:
d[lower_wd] += 1
else:
d[lower_wd] = 1
for key in d.keys():
print(key, " = ", d[key])
练习04 升序显示不重复的单词
创建一个字符串变量,内容为某一篇英文文章,用re.findall(r'\b[a-zA-Z]+\b', sources)解析出所有的英文单词,按升序显示所有不重复的单词。
sources = """
# The Magic of Reading
Reading is a magical journey that transports us to different worlds, times, and perspectives. With a book in hand, we can explore ancient civilizations, visit far - off galaxies, or delve into the human psyche.
One of the greatest benefits of reading is its ability to expand our knowledge. Whether it's a history book, a science manual, or a work of fiction, each page offers new information, ideas, and vocabulary. It also enhances our imagination. When we read, we create vivid images in our minds, which enriches our creativity.
Moreover, reading is a great way to relax. In a world full of stress and distractions, getting lost in a good book allows us to unwind and recharge. It can reduce anxiety and improve our overall well - being.
In conclusion, reading is not just an activity; it's a lifelong companion that educates, inspires, and soothes us. So, pick up a book today and start your own magical adventure.
"""
import re
words = re.findall(r'\b[a-zA-Z]+\b', sources)
words = [word.lower() for word in words]
lst = list(set(words))
lst.sort()
print(lst)
练习05 唯一摩尔斯密码词
题目描述
国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如:
- ‘a’ 对应
".-" - ‘b’ 对应
"-..." - ‘c’ 对应
"-.-."以此类推
为了方便,所有26个英文字母的摩尔斯密码表如下:
[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
给你一个字符串数组 words ,每个单词可以写成每个字母对应摩尔斯密码的组合。
例如,“cab” 可以写成 "-.-..--..." ,(即 "-.-." + ".-" + "-..." 字符串的结合)。我们将这样一个连接过程称作 单词翻译
对 words 中所有单词进行单词翻译,返回不同 单词翻译 的数量
输入输出描述
输入一组单词
输出不一样的翻译数量
示例
输入:
gin zen gig msg
输出:
2
解释:
各单词翻译如下:
“gin” -> “–…-.”
“zen” -> “–…-.”
“gig” -> “–…–.”
“msg” -> “–…–.”共有 2 种不同翻译, “–…-.” 和 “–…–.”.
morses = [".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
def sovle(words):
st = set()
for word in words:
pwd = ""
for letter in word:
pwd += morses[ord(letter) - 97]
st.add(pwd)
return len(st)
words = input().split(" ")
print(sovle(words))
练习06 前K个高频元素
题目描述
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
输入输出描述
输入数组长度n和k,接下来输入n个元素
输出前k个高频元素
示例
输入:
6 2
1 1 1 2 2 3
输出:
1 2
# 思路1 用字典计数 key=数字 value=次数,对values进行排序
"""
arr = [1,3,1,2,1,2,1,4,1,3,2,2,3,1,1,4,2]
k = 3
dic = dict()
for num in arr:
if num in dic:
dic[num] += 1
else:
dic[num] = 1
keys_lst = list(dic.keys())
values_lst = list(dic.values())
# 对值的列表进行降序排序 排序的过程中 同时交换keys_lst中的元素
for i in range(1, len(values_lst)):
j = i
while j > 0 and values_lst[j - 1] < values_lst[j]:
values_lst[j], values_lst[j - 1] = values_lst[j - 1], values_lst[j]
keys_lst[j], keys_lst[j - 1] = keys_lst[j - 1], keys_lst[j]
j -= 1
print(keys_lst[:k])
"""
# 思路2 最大堆/最小堆 -> 优先队列
"""
from queue import PriorityQueue
# 创建一个优先队列实例
#(最小堆->优先级数值越小 优先级越大)
# 想构建优先级数值越大 优先级越大的 将优先级取负数
pq = PriorityQueue()
# 向队列中添加元素,元素以 (优先级, 数据) 元组的形式存在
pq.put((-2, 'task2'))
pq.put((-1, 'task1'))
pq.put((-3, 'task3'))
# 从队列中取出元素
while not pq.empty():
# 获取元素
priority, task = pq.get()
print(f"Priority: {priority}, Task: {task}")
"""
from queue import PriorityQueue
arr = [1,3,1,2,1,2,1,4,1,3,2,2,3,1,1,4,2]
k = 3
dic = dict()
for num in arr:
if num in dic:
dic[num] += 1
else:
dic[num] = 1
pq = PriorityQueue()
for key in dic.keys():
pq.put((-dic[key], key))
for i in range(k):
priority, task = pq.get()
print(task)
"""
1 2 3 4 8 5 9 6 7 插入 选择
2 3 4 8 1 5 9 6 7 插入
4 5 6 7 1 2 3 4 6 7 8 9 2 3 4 5 归并
2 3 1 4 2 5 5 9 6 8 7 8 6 9 快排
7 4 2 8 1 3 8 8 9 冒泡
"""
练习07 根据字符出现频率排序
题目描述
给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。
返回 已排序的字符串 。如果有多个答案,返回其中任何一个。
输入输出描述
输入一个字符串
输出排序后的字符串
示例1
输入:
tree
输出:
eert
解释:
'e’出现两次,'r’和’t’都只出现一次。
因此’e’必须出现在’r’和’t’之前。此外,"eetr"也是一个有效的答案。
示例2
输入:
cccaaa
输出:
cccaaa
解释:
'c’和’a’都出现三次。此外,"aaaccc"也是有效的答案。
注意"cacaca"是不正确的,因为相同的字母必须放在一起。
s = "anasbdvbnavsdbvabsdnvad"
dic = dict()
for letter in s:
if letter in dic:
dic[letter] += 1
else:
dic[letter] = 1
from queue import PriorityQueue
pq = PriorityQueue()
for key in dic.keys():
pq.put((-dic[key], key))
res = []
while not pq.empty():
priority, element = pq.get()
res.append(element * dic[element])
print("".join(res))
"""
""
"aaaaa"
"aaaaabbbb"
....非常多的临时的字符串
"""
练习08 Z字形变换
题目描述
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 “PAYPALISHIRING” 行数为 3 时,排列如下:
P A H N
A P L S I I G
Y I R
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:“PAHNAPLSIIGYIR”。
输入输出描述
输入s和numRows
输出变换后的顺序
示例1
输入:
PAYPALISHIRING 3
输出:
PAHNAPLSIIGYIR
示例2
输入:
PAYPALISHIRING 4
输出:
PINALSIGYAHRPI
# 思路1 找规律变化->可操作/遍历数组
"""
s = "ABCDEFGHIJK"
rows = 4
direction = [0,1,2,3,2,1]
dic = dict()
for i in range(rows):
dic[i] = []
index = 0
for letter in s:
dic[direction[index % len(direction)]].append(letter)
index += 1
lst = []
for i in range(rows):
lst.extend(dic[i])
print("".join(lst))
"""
# 思路2 找规律变化 设置哨兵
s = "ABCDEFGHIJK"
rows = 4
dic = dict()
for i in range(rows):
dic[i] = []
index = 0
direction = True # 向下
for letter in s:
dic[index].append(letter)
if direction:
index += 1
if index == rows:
index -= 2
direction = not direction
else:
index -= 1
if index == -1:
index += 2
direction = not direction
lst = []
for i in range(rows):
lst.extend(dic[i])
print("".join(lst))
练习9 杨辉三角
题目描述
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
输入输出描述
输入行数numRows
输出对应杨慧三角
示例1
输入:
5
输出:
1 1 1 1 2 1 1 3 3 1 1 4 6 4 1
row = 5
# 所有的行
lines = []
for i in range(row):
line = [1] * (i + 1)
lines.append(line)
# 修改值
for j in range(1, i):
line[j] = lines[i - 1][j] + lines[i - 1][j - 1]
for line in lines:
for j in range(len(line)):
print(line[j], end=" ")
print()
"""
i
0 [1]
1 [1,1]
2 [1,2,1]
3 [1,3,3,1]
"""


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









