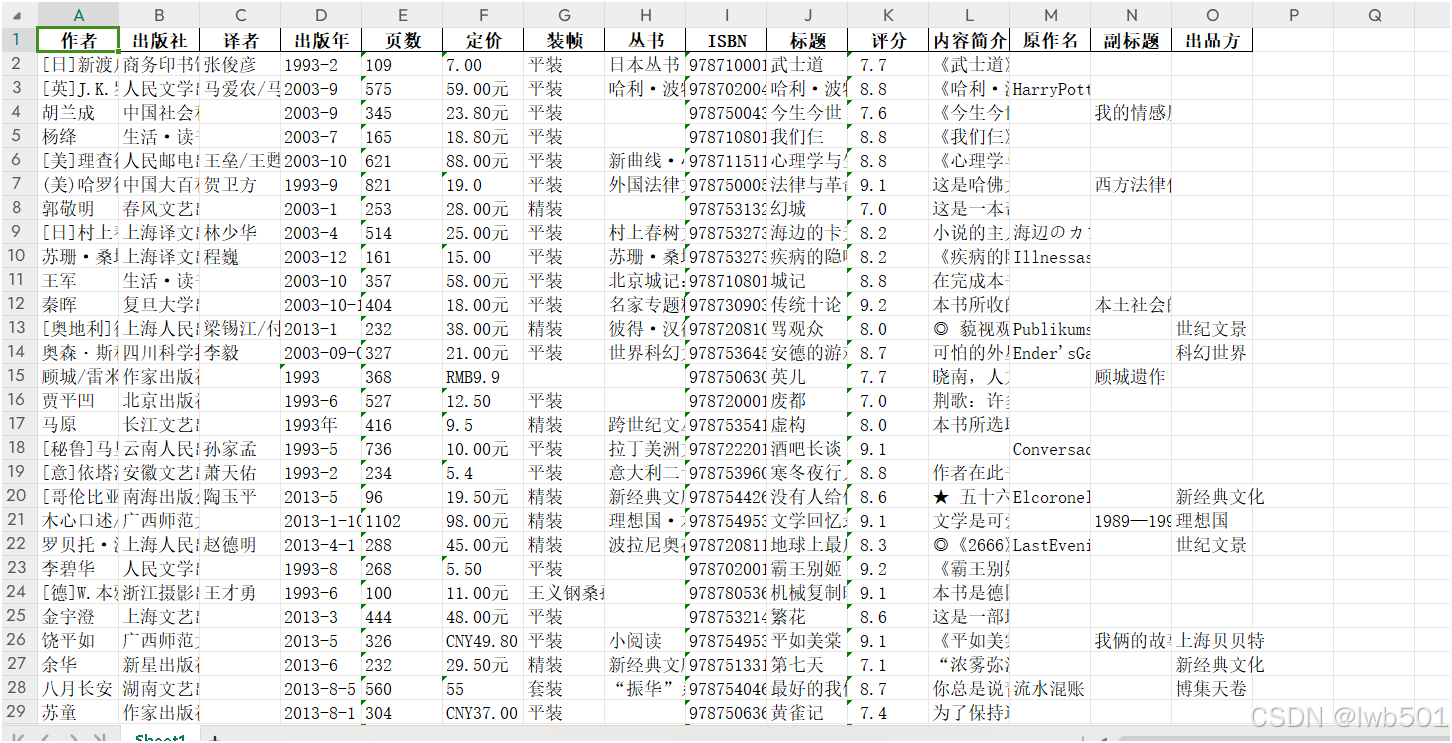
- 访问https://book.douban.com/annual/2023/?fullscreen=1&source=navigation,爬取《豆瓣2023年度书籍》的书籍信息。获取每本书籍的书名、作者、出版社、出版年、页数、定价、豆瓣评分、内容简介等数据
import json
import os
import time
import re
import requests
from bs4 import BeautifulSoup
from lxml import etree
def get_data(): # 首先从《豆瓣2023年度书籍》网站获取json
url = 'https://book.douban.com/j/neu/page/21/'
headers = {
"referer": "https://book.douban.com/annual/2023/?fullscreen=1&source=navigation",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"}
cookies = {
"bid": "WP9t8HIu3NU"
}
if os.path.exists('data.json'):
with open('data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
else:
print("正在从网络请求数据...")
response = requests.get(url, headers=headers, cookies=cookies)
if response.status_code == 200:
data = response.json()
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print("成功从网络获取数据,并已保存到data.json文件中。")
else:
print(f"请求失败,状态码:{response.status_code}")
return None
return data
def get_urls(d): # 从json中获取所有url
urls = []
if isinstance(d, dict):
for key, value in d.items():
if key == "url":
urls.append(value)
elif isinstance(value, (dict, list)):
urls.extend(get_urls(value))
elif isinstance(d, list):
for item in d:
urls.extend(get_urls(item))
return urls
def get_num(url): #从url里面取出索引为四的元素
parts = url.split('/')
return parts[4]
def handle_datas(): # 进一步筛选url,找出书单路由的url并且去重
urls = get_urls(get_data())
subject_urls = list(set(url for url in urls if '/subject' in url))
return subject_urls, len(subject_urls)
def datas(num): # 爬书单的详情界面获取数据 首先用bs4初步缩小范围 然后获取范围内所有文本进行数据清洗 最终构成json
url = f'https://book.douban.com/subject/{num}/'
book_html_filename = f"resource/book_{num}.html"
if os.path.exists(book_html_filename):
with open(book_html_filename, 'r', encoding='utf-8') as f:
book_html_content = f.read()
else:
print(f"正在从URL获取数据: {url}")
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'cookie': 'bid=dF6pXczRfGg; douban-fav-remind=1; _vwo_uuid_v2=D834B4F4A54428F1BD9E1C77F322DAC40|a3464cca644bed6420b25eb9a125f5a9; _pk_id.100001.3ac3=e0a81ac9dab0f55d.1731943283.; __utmz=30149280.1731943283.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmz=81379588.1731943283.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=YSfyimg4txndz76OeeogMNiKqJTdiQN7; viewed="36457094_36122667_36197606_36218576_36374149_36328704_35473516_35922841_36388449_36127030"; dbcl2="284971767:NyVVXTo2tvE"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.28497; ck=UI-X; frodotk_db="21154a871b91cefb633fdf9552b56cf1"; ap_v=0,6.0; _pk_ses.100001.3ac3=1; __utma=30149280.301400624.1731943283.1734752757.1734795787.8; __utmc=30149280; __utmt_douban=1; __utmb=30149280.1.10.1734795787; __utma=81379588.1438903848.1731943283.1734752757.1734795787.8; __utmc=81379588; __utmt=1; __utmb=81379588.1.10.1734795787',
'pragma': 'no-cache',
'priority': 'u=0, i',
'sec-ch-ua': '"Microsoft Edge";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
time.sleep(3)
response = requests.get(url, headers=headers)
if response.status_code == 200:
book_html_content = response.text
with open(book_html_filename, 'w', encoding='utf-8') as f:
f.write(book_html_content)
print(f"HTML内容已保存到 {book_html_filename}")
else:
print(f"获取数据失败,状态码:{response.status_code}")
# 这里应该返回一个有意义的值,而不是 None,以避免错误
return {}, ''
soup = BeautifulSoup(book_html_content, 'html.parser')
book_info_div = soup.find(id='info')
book_info_text = book_info_div.get_text()
book_info_text_str = str(book_info_text)
cleaned_book_info_text = re.sub(r' +', '', book_info_text_str) ##删去空格
book_info_list = [e for e in cleaned_book_info_text.split('\n') if e!= '']
book_info_list = [e.replace('\xa0', '') for e in book_info_list]
for i, book_info_item in enumerate(book_info_list):
if ':' in book_info_item:
book_info_list[i] = book_info_item.split(':')
for i, book_info_item in enumerate(book_info_list):
if isinstance(book_info_item, list):
if book_info_list[i][1] == '':
j = 1
temp = ''
while True:
if isinstance(book_info_list[i + j], str):
temp += book_info_list[i + j]
j += 1
continue
book_info_item[1] = temp
break
filtered_data = [item for item in book_info_list if isinstance(item, list)]
filtered_data = merge_lists(filtered_data)
book_info_dict = dict(filtered_data)
#爬取标题
title = soup.title.string
cleaned_title = re.sub(r'\s*\(.*\)', '', title)
#爬取评分
html_tree = etree.HTML(book_html_content)
element=html_tree.xpath('//*[@id="interest_sectl"]/div/div[2]/strong')
score=element[0].text;
content_list = []
# 爬取内容简介
content_summary = html_tree.xpath('//*[@id="link-report"]//div[@class="intro"]')
for intro_element in content_summary:
p_tags = intro_element.xpath('p')
for p_tag in p_tags:
# 检查 p_tag 的文本是否不为 None
if p_tag.text is not None:
# 对文本进行处理,例如去除特殊字符或截取长度
cleaned_text = p_tag.text.replace("\n", " ").replace("\r", " ").replace("\t", " ")
content_list.append(cleaned_text)
book_info_dict.update({
'标题': cleaned_title,
'评分': score,
'内容简介':''.join(content_list)
})
print(book_info_dict)
return book_info_dict, num
def merge_lists(input_list): #合并列表中的元素
result = []
for sublist in input_list:
if len(sublist) > 2:
for i in range(2, len(sublist)):
if len(result) == 0 or len(result[-1]) == 2:
result.append([sublist[0], sublist[i]])
else:
result[-1].append(sublist[i])
else:
result.append(sublist)
return result
def save_to_json_by_num(data, num):
# 检查传入的数据是否为空
if not data:
print("传入的数据为空!")
return
# 动态生成文件名
json_file = f"result/book_{num}.json"
# 如果文件已存在,清空文件内容
if os.path.exists(json_file):
try:
open(json_file, 'w', encoding='utf-8').close()
except Exception as e:
print(f"清空文件 {json_file} 时出现错误: {str(e)}")
return
# 将新的数据添加到文件中
try:
with open(json_file, 'w', encoding='utf-8') as file:
# 检查新数据是否可序列化
try:
json.dump([data], file, ensure_ascii=False, indent=4)
print(f"数据已成功保存到 {json_file}")
except TypeError:
print(f"传入的数据无法序列化,将不会保存。")
except Exception as e:
print(f"保存文件 {json_file} 时出现错误: {str(e)}")
def main():
urls, long = handle_datas()
for index in range(long):
data, num = datas(get_num(urls[index]))
save_to_json_by_num(data, num)
if __name__ == '__main__':
main()
# encoding=utf-8
import json
import os
import re
import time
import pandas as pd
def json_to_excel():
# 获取所有JSON文件的路径
json_files = [os.path.join('result', f) for f in os.listdir('result') if f.endswith('.json')]
# 用于存储所有书籍数据的列表
all_books_data = []
# 遍历每个JSON文件并读取数据
for json_file in json_files:
with open(json_file, 'r', encoding='utf-8') as file:
data = json.load(file)
for book in data:
all_books_data.append(book)
# 使用pandas将数据转换为DataFrame
df = pd.DataFrame(all_books_data)
# 将DataFrame保存为Excel文件
excel_file = 'books_data.xlsx'
df.to_excel(excel_file, index=False)
print(f"所有书籍数据已保存到 {excel_file} 文件!")
json_to_excel()

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









