






测试期间涉及用到数据库的场景例如:
- 测试前造数据
- 测试中校验数据存储准确性
- 测试中验证边界条件/修改某字段提高测试效率
数据库
select version() 返回当前数据库版本号
show databases 查看所有数据库
use database 打开指定数据库
create database if not exists 库名/创建数据库
drop database if exists 库名/删除库
数据表
desc 表名 查看表结构
show tables from 库名 查看当前库的所有表
一、增
insert into 表名(列名1,列名2,...列名n) values(value1,value2,...valuen);
insert into 表名 set 列名1=value1,列名2=value2,...列名n=valuen;
二、删
delete from 表名 where 筛选条件;
truncate 表名;
drop table 表名;
- drop/truncate/delete区别
- delete、truncate删除表中数据;drop删除表中数据+表结构
- delete是DML语句,没有提交事物可以回滚;truncate、drop是DDL语句,立马生效,不能回滚
- 执行速度drop>truncate>delete
三、改
update 表名 set 列名1=value1,列名2=value2,...列名n=valuen where 筛选条件;
四、查
sql语句关键字执行逻辑
- from A jion B on
- where
- group by
- having
- select
- distinct
- order by
- limit
select
select 函数 distinct 字段 去重 ifnull(字段,指定值)
检测函数是否为null
是返回指定值;不是返回原本值
聚合函数
max()、min()、sum()、avg()、count()
日期函数
year/month/monthname/day/hour/minute/second()
返回年/月/以英文形式返回月/日/小时/分钟/秒now()返回当前系统日期+时间 curdate()返回当前系统日期+不包括时间 字符串函数 upper/lower()字符串大小写
length()获取字节个数
concat/连接字符串 concat(字段1,字段2)
分组函数 as/起别名 字段 as 别名
字段 别名
列/要求出现在group by的后面
from
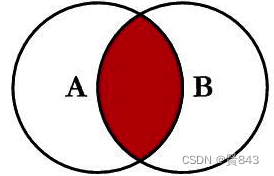
from A表 inner join内连接
B表 on 连接条件 select <select list> from
tableA A inner join TableB B on A.key=B.key
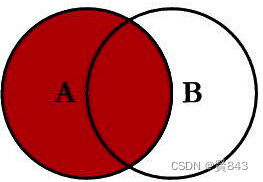
left join
左外连
接
select <select list> from
tableA A left join TableB B on A.key=B.key
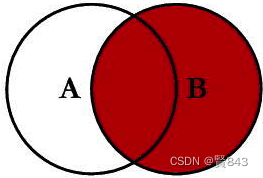
right join右外连接
select <select list> from
tableA A right join TableB B on A.key=B.key
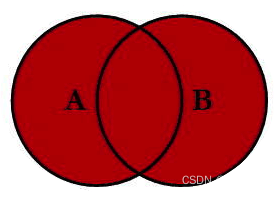
full outer join
全外连接
select <select list> from
tableA A full outer join TableB B on A.key=B.key
where
where
分组前筛选条件
>,<,>= ,<=,<>/!=
not,and,or
between and,not between and
like,not like
%通配符:>=0个字符
_通配符:单个字符
第二个字符为_,用到转义字符/ _\_%
is null
select <select list> from
tableA A left join TableB B on A.key=B.key where B.key is null
select <select list> from
tableA A right join TableB B on A.key=B.key
where A.key is null
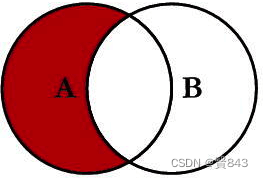
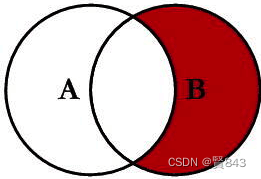
group by 分组列表
having分组后筛选
order by 排序列表
字段 asc(升序/不加默认)
字段 desc(降序)
limit 分页查询
limit i,n
i显示条目起始索引值,从0开始,i=0可省略
n显示条目个数
limit i offset n
i显示条目数
n==offset跳过的数量
limit (page-1)*size,size
page显示页数
size每页条目数
注意
where和having区别
1. where 在分组和聚合之前筛选数据,用于表数据过滤
2. having 在分组和聚合之后筛选数据,用于组数据过滤
mysql和redis
- redis 读写效率高,性能好,成本高,所以会用在对性能要求高的场合,如:抢购、秒杀、实时排行榜
- mysql 可以存储大量数据,持久化到硬盘,性价比高。在性能要求不那么高的场合均建议使用
- redis 持久化:由于redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失,于是需要开启redis持久化功能,将数据保存在磁盘上。redis 重启后可以从磁盘恢复数据。
本质区别
- mysql主redis辅:加快访问读取速度,提高性能
- mysql数据放在磁盘:mysql作为持久化存储的关系型数据库,相对薄弱的地方在于每次访问数据库时,都存在IO操作,如果频繁访问数据库:1. 会在反复连接数据库上花费大量时间,导致运行效率慢,2. 反复访问数据库也会导致数据库负载过高
- redis数据存在内存,读取数据极快,成本高,断电数据就清零,需要做持久化
使用场景
- mysql 支持复杂的联合查询,可以实现一些关联的查询和统计
- redis 对内存要求极高,在有限的条件下不能把所有的数据都放在redis中
- mysql 偏向于存数据,redis 偏向于快速读取数据















 36万+
36万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









