






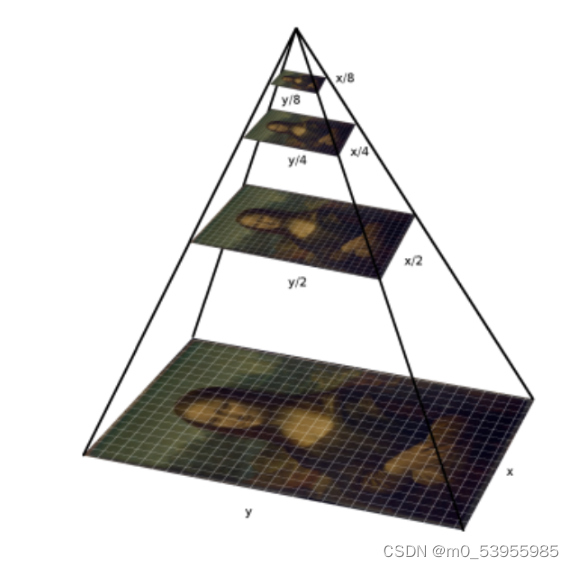
一、什么是多尺度?
所谓多尺度,实际上就是对信号的不同粒度的采样,通常在不同的尺度下我们可以观察到不同的特征,从而完成不同的任务
通常来说粒度更小/更密集的采样可以看到更多的细节,粒度更大/更稀疏的采样可以看到整体的趋势
这里的直观理解
你是一个人 你有一双眼睛 但只能看固定范围的东西 如果这张图片足够大 你只能看到图片的一个部分 也就是说 你只能关注到它的细节
对于一张小的图片 你可以看到他的全貌 但对于细节 你看的是不如大图片清晰的
思考一下
对于一张图片中的大物体 我可以给他缩小的更多 因为他更大 更容易看得到
小物体则需要更大的图像 才能看清小的图像
深层网络的感受野比较大,语义信息表征能力强,但是特征图的分辨率低,几何信息的表征能力弱(空间几何特征细节缺乏)
低层网络的感受野比较小,几何细节信息表征能力强,虽然分辨率高,但是语义信息表征能力弱
下采样倍数小(一般是浅层)的特征感受野小,适合处理小目标,小尺度特征图(深层)分辨率信息不足不适合小目标。在yolov3中对多尺度检测的理解是,1/32大小的特征图(深层)下采样倍数高,所以具有大的感受野,适合检测大目标的物体,1/8的特征图(较浅层)具有较小的感受野,所以适合检测小目标
空洞卷积
首先要介绍Atrous Convolution(空洞卷积)。和之前的non-local一样,都是为了增加感受野的方法。空洞卷积是是为了解决基于FCN思想的语义分割中,输出图像的size要求和输入图像的size一致而需要upsample的问题。
但由于FCN中使用pooling操作来增大感受野同时降低分辨率,导致upsample无法还原由于pooling导致的一些细节信息的损失的问题而提出的。为了减小这种损失,自然需要移除pooling层,因此空洞卷积应运而生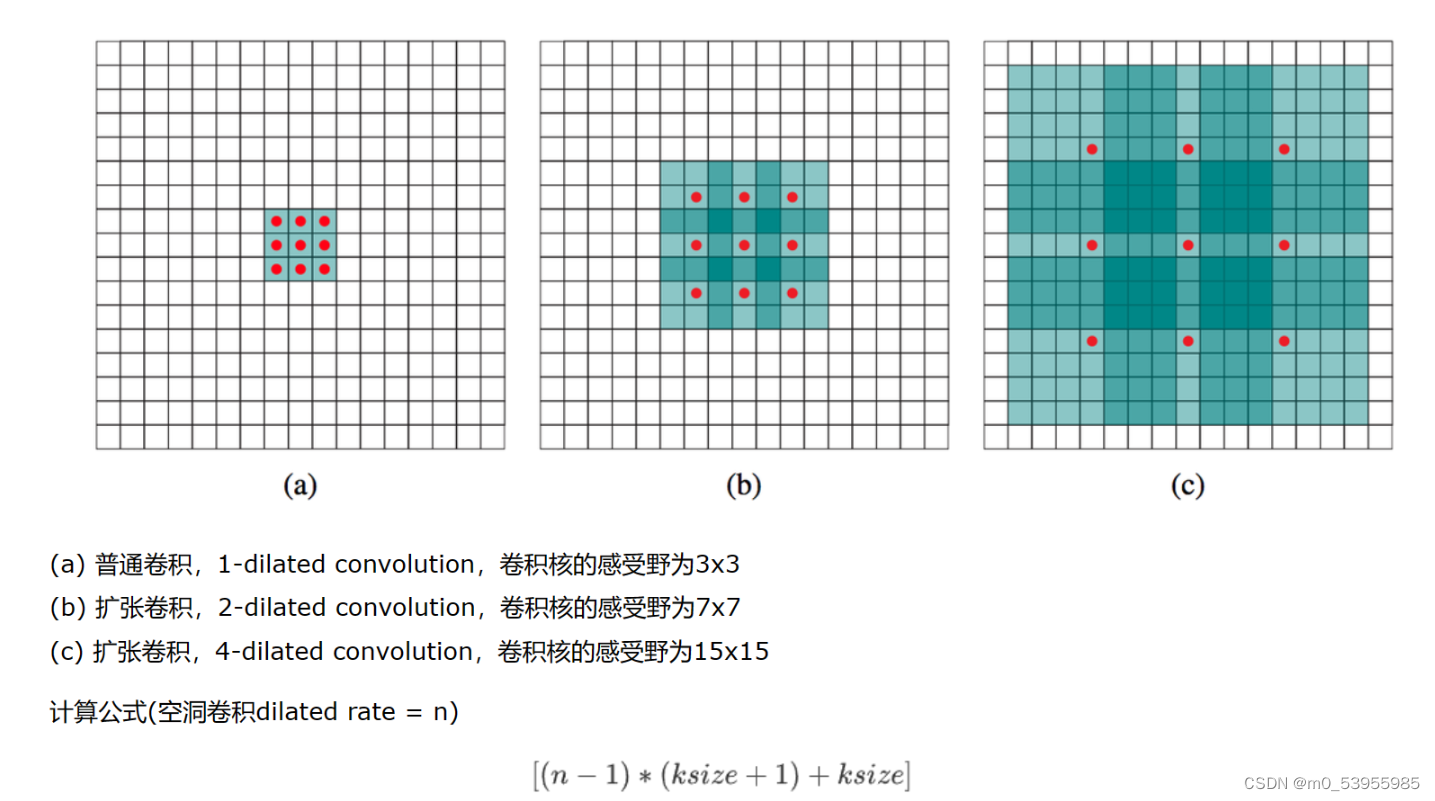
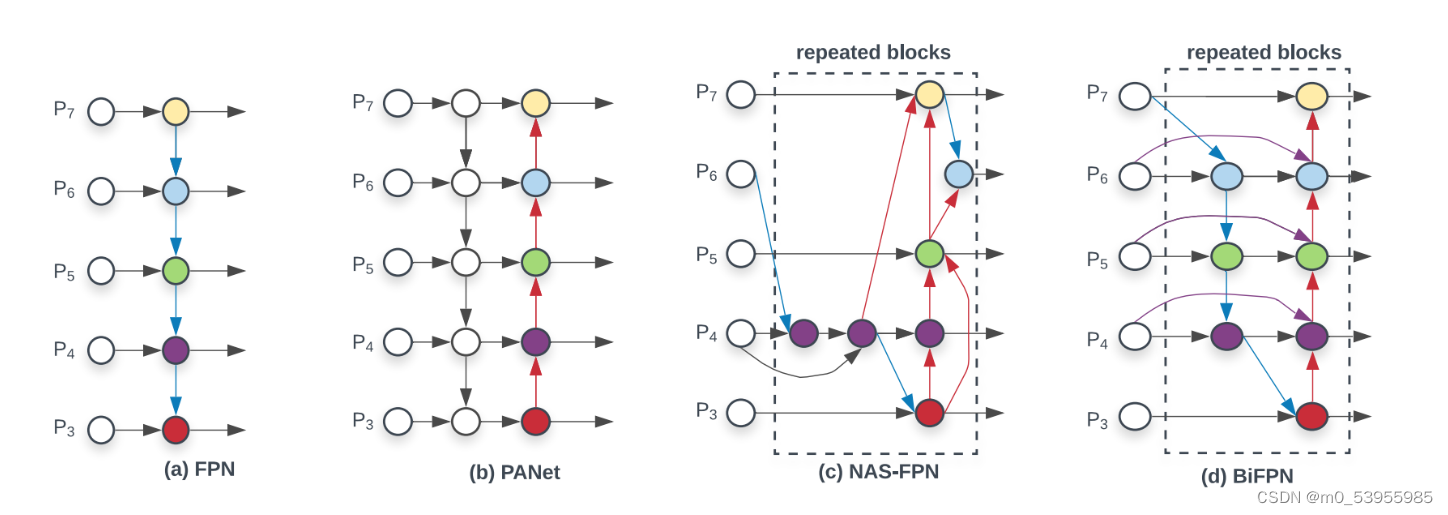
FPN——对SSD进行改进
Motivation:大多数方法为了检测速度而尽可能的去避免使用特征金字塔,而是只使用高层的特征来进行预测。高层的特征虽然包含了丰富的语义信息,但是由于低分辨率,很难准确地保存物体的位置信息。与之相反,低层的特征虽然语义信息较少,但是由于分辨率高,就可以准确地包含物体位置信息。所以如果可以将低层的特征和高层的特征融合起来,就能得到一个识别和定位都准确的目标检测系统。所以本文就旨在设计出这样的一个结构来使得检测准确且快速。
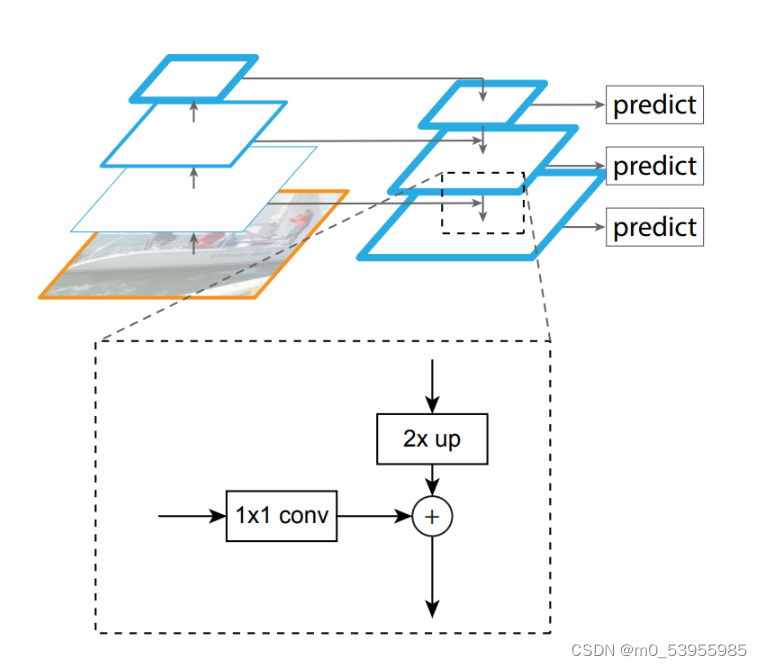
backbone可以分为浅层网络和深层网络,浅层网络负责提取目标边缘等底层特征,而深层网络可以构建高级的语义信息,通过使用FPN这种方式,让深层网络更高级语义的部分的信息能够融合到稍浅层的网络,指导浅层网络进行识别。
图中我们在第1层输出较大目标的实例分割结果,在第2层输出中型目标的实例检测结果,在第3层输出较小目标的实例分割结果。因为在大的feature map上进行操作,可以获得更多关于小目标的有用信息;检测也是一样,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标。
浅层特征中包含大量边缘形状等特征,这对实例分割这种像素级别的分类任务是起到至关重要的作用的
FPN已经证明了加入一条top-down的旁路连接,能给feature增加high-level的语义性有利于分类。
但是low-level的feature是很利于定位用的,虽然FPN中P5也间接得有了low-level的特征,但是信息流动路线太长了如红色虚线所示(其中有ResNet50/101很多卷积层),这样浅层信息丢失的情况比较严重
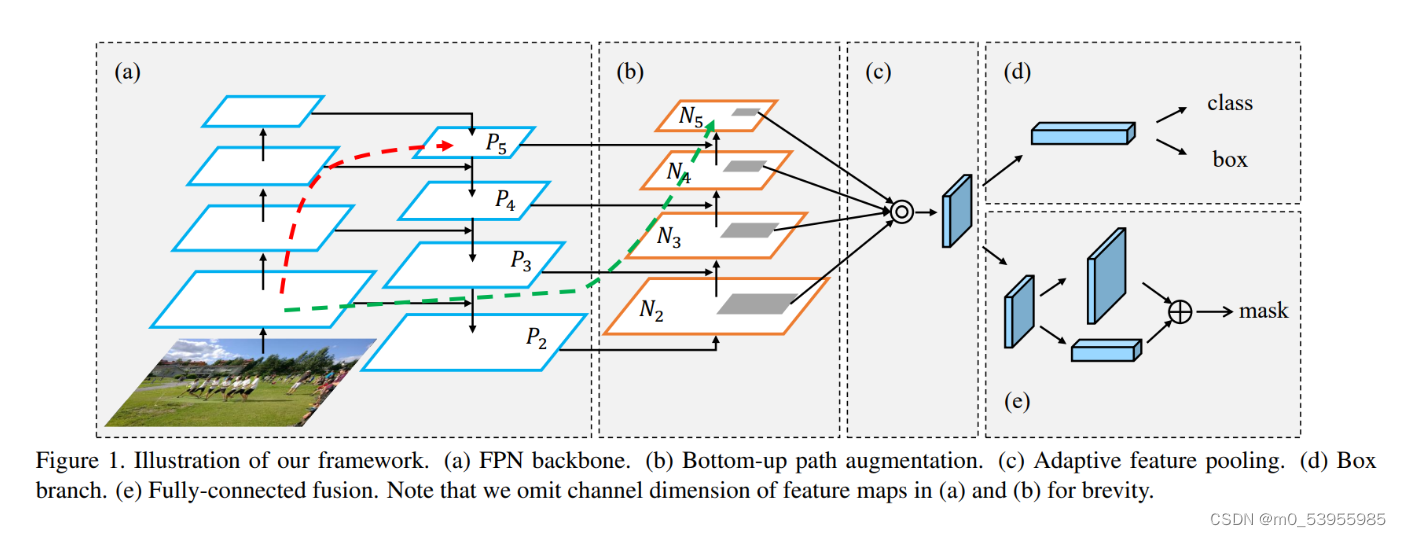
本文在FPN的P2-P5又加了low-level的特征,最底层的特征流动到N2-N5只需要经过很少的层如绿色需要所示(仅仅有几个降维的卷积)
PANet 因此在自上向下的FPN网络结构中额外增加了自底向上的路径聚合模块,将低层特征图的信息又传导到高层中特征图去,同时在自上向下的路径中减少了高层特征图到低层特征图的信息流通需要穿过的卷积层的数量。
BiFPN
PANet比FPN有更好的效果,但是计算量和参数量更大,为了提高效率提出BiFPN
删除那些只有一个输入边的节点。作者认为:如果一个节点只有一条输入边而没有特征融合,那么它对融合不同特征的特征网络的贡献就会更小
我们添加一个跳跃连接,在同一尺度的输入节点到输出节点之间加一个跳跃连接,因为它们在相同层,在不增加太多计算成本的同时,融合了更多的特征
与PANet 仅有一个自顶向下和一个自底向上的路径不同,我们将每个双向(自顶向下和自底向上)路径看作一个特征网络层(repeated blocks),并多次重复同一层,以实现更高层次的特征融合



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









