






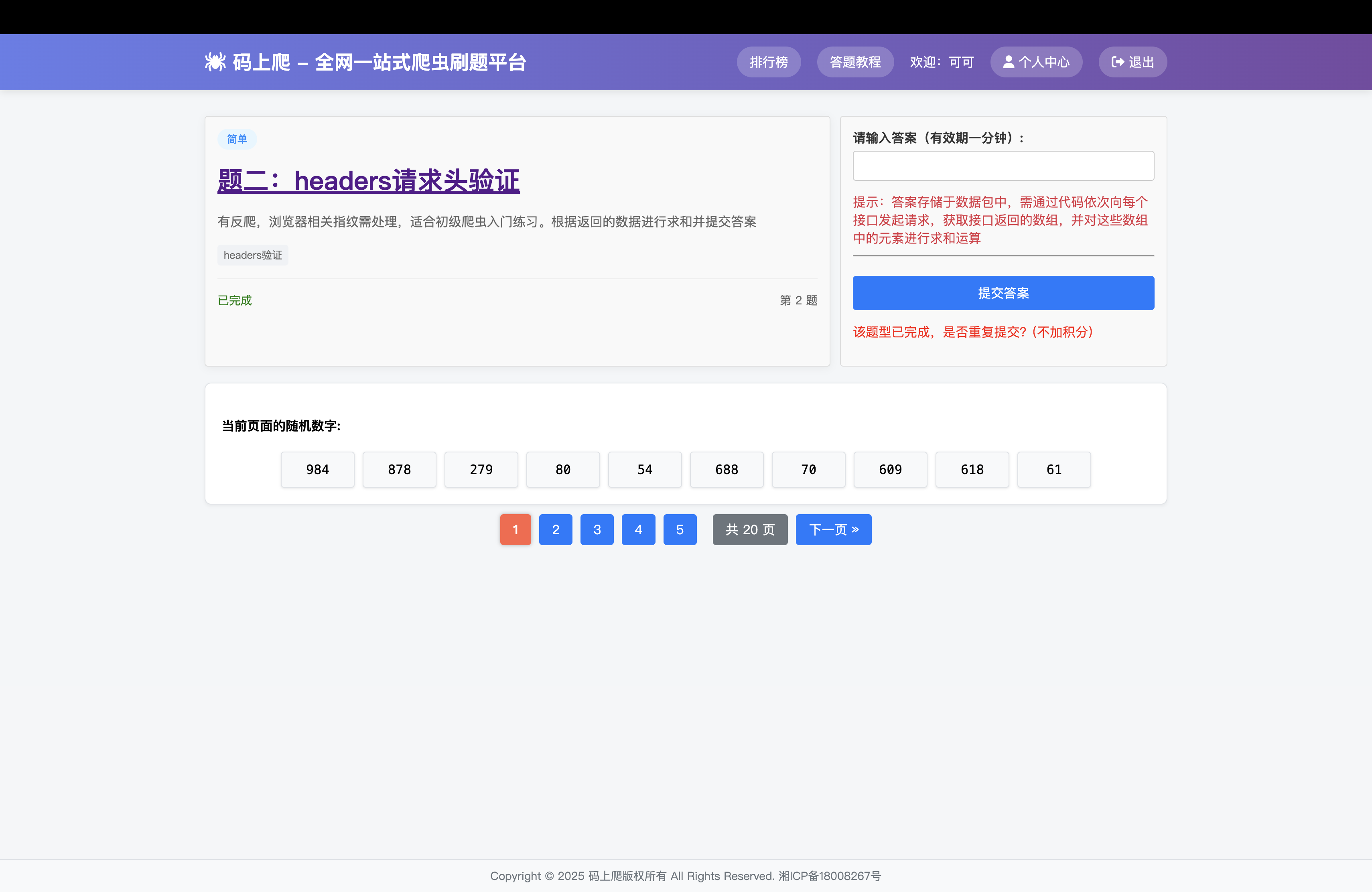
题二:headers请求头验证
有反爬,浏览器相关指纹需处理,适合初级爬虫入门练习。根据返回的数据进行求和并提交答案
这一题还是跟第一题一样,直接放到爬虫网站里面去
网址:Convert curl commands to code
然后可以直接生成,获取到正确的答案
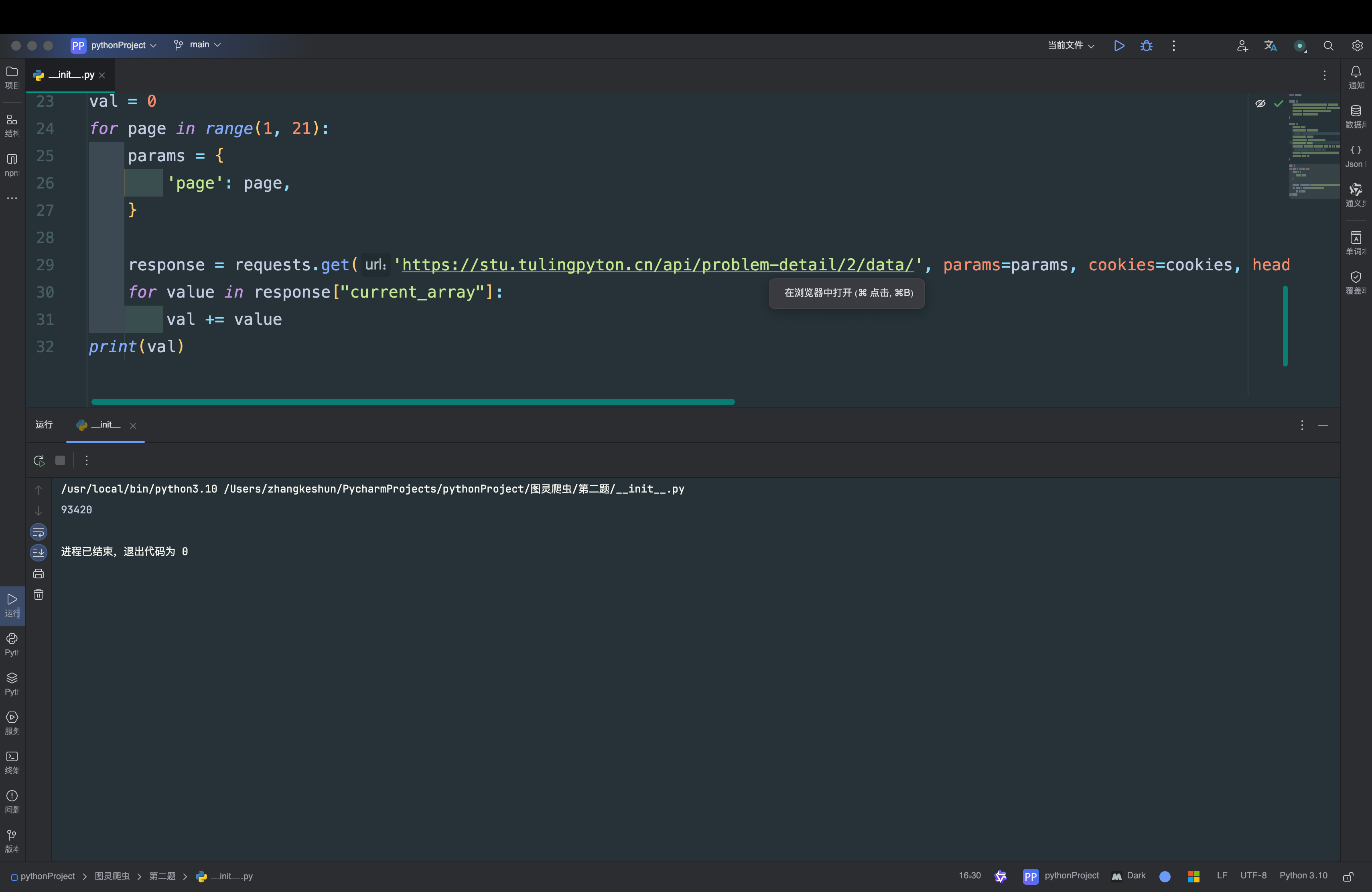
这里的header验证其实就是header里面的一些值的使用
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.3.1 Safari/605.1.15',
'Referer': 'https://stu.tulingpyton.cn/problem-detail/2/',
一般这几个值都需要写上去,不熟悉的话可以去学一下基础的爬虫

















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









