






跑通baseline:
1,导入需要用到的库:
pandas
numpy
DicisionTreeClassifier
代码:
import pandas as pd
import numpy as pd
form sklearn.tree import DicisionTreeClassifier
2,读取训练集和测试集:
训练数据集:train.csv
测试数据集:test.csv
读取的代码:
train_data=pd.read_csv("train.csv")
test_data=pd.read_csv("test.csv")
3,将udmap进行onethot编码:
onethot将分类变量转化为二进制向量,每个整数代表一个类别,除了整数的索引之外其它都是0。处理的东西例如:颜色,性别,季节等
(1,10)代表0-9,不包括10。
代码:
def udmap_onethot(d):
v=np.zeros(9)
if d==unkown
return v
d=eval(d)
for i in range(10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
#np.zeros(9)表示创建一个全是0的数组,如果表中的数据是unknown,那数组中就是0。如果索引存在,就赋值给v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
dataframe由行(rows)和列(columns)组成,index为行索引,column为列索引。
print第一段,终端得到:
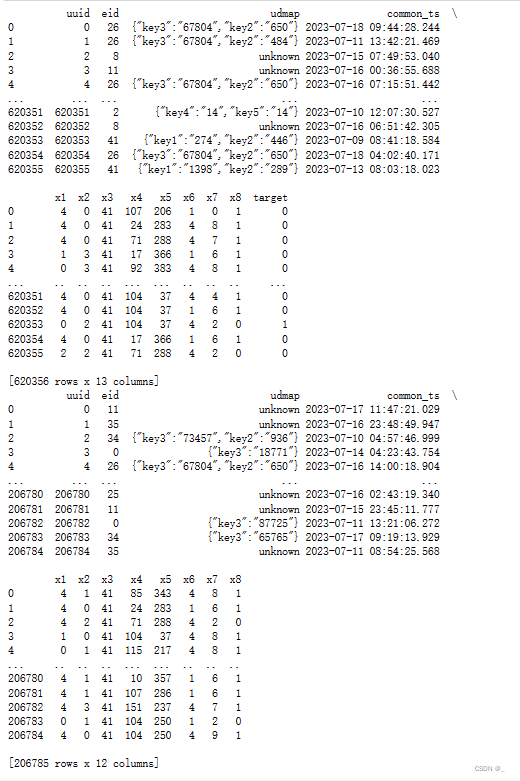
输出train_udmap_df,终端得到:
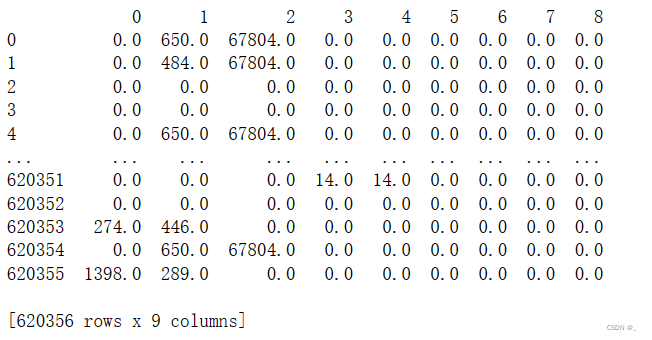
输出test_udmap_df,终端得到:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









