






 本文介绍了如何使用Python的requests和BeautifulSoup库爬取实习僧网站上的工作岗位、公司名称等信息,包括如何处理反爬策略和添加新的爬取字段,如城市和职位描述。作者还演示了翻页循环的实现和网址格式调整。
本文介绍了如何使用Python的requests和BeautifulSoup库爬取实习僧网站上的工作岗位、公司名称等信息,包括如何处理反爬策略和添加新的爬取字段,如城市和职位描述。作者还演示了翻页循环的实现和网址格式调整。
本文基于大佬的原创基础上,增加了爬取字段,供大家交流应用
首先是引入requests与BeautifulSoup,构建headers那些基本的
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}本次爬取字段选择的是工作岗位、公司名称,学历,岗位关键词以及工资。因为实习僧数字部分有反爬所以麻烦了点。
def detail_url(url):
html = requests.get(url,headers=headers).text
soup = BeautifulSoup(html, 'lxml')
title = soup.title.text
job = title.split("招聘")[0]
company_name = soup.select('.com_intro .com-name')[0].text.strip()
adress = soup.select('.job_position')[0].text.strip()
academic = soup.select('.job_academic')[0].text.strip()
good_list = soup.select('.job_good_list')[0].text.strip()
salary = soup.select(".job_money.cutom_font")[0].text.encode("utf-8")
salary = salary.replace(b'\xee\x8b\x92',b"0")
salary = salary.replace(b'\xee\x9e\x88',b"1")
salary = salary.replace(b'\xef\x81\xa1',b"2")
salary = salary.replace(b'\xee\x85\xbc',b"3")
salary = salary.replace(b'\xef\x84\xa2',b"4")
salary = salary.replace(b'\xee\x87\x99',b"5")
salary = salary.replace(b'\xee\x9b\x91',b"6")
salary = salary.replace(b'\xee\x94\x9d',b"7")
salary = salary.replace(b'\xee\xb1\x8a',b"8")
salary = salary.replace(b'\xef\x86\xbf',b"9")
salary = salary.decode()
print(":{} :{} :{} :{} :{} :{} ".format(job,salary,company_name,adress,academic,good_list))三个小问题新手小伙伴可能会有困难:
一.有小伙伴不知道添加新的爬取字段,这里我演示一下(比如我想提取实习僧具体岗位的城市)
1.进入具体实习岗位界面,右击选择“检查”
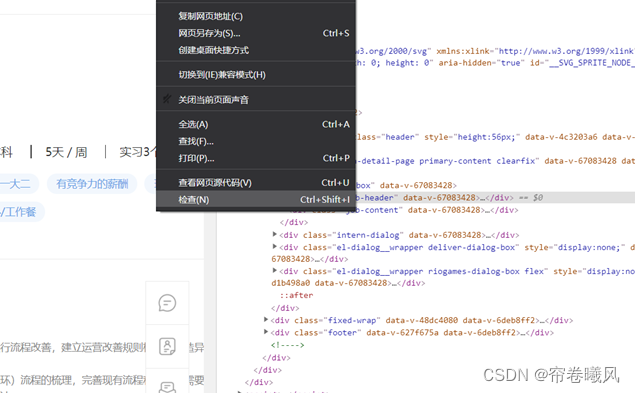
Element下的网页源码,可以看到我们鼠标移动到 job-box它是整个页面被选中的;而鼠标移动到 job_header,job_content时候,选择范围有相应的改变。这个时候我们就是要找到想要的数据所在的“具体位置”。通过观察可以看出,我们所要采集的城市包含在job-header里面,那么想要把它单独拿出来就要往job-header下进一步寻找。
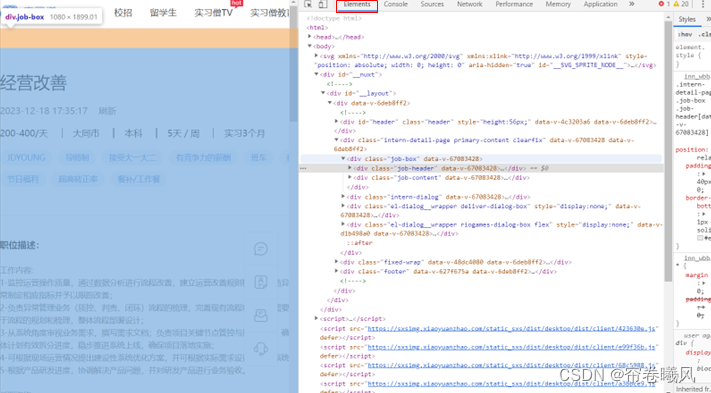
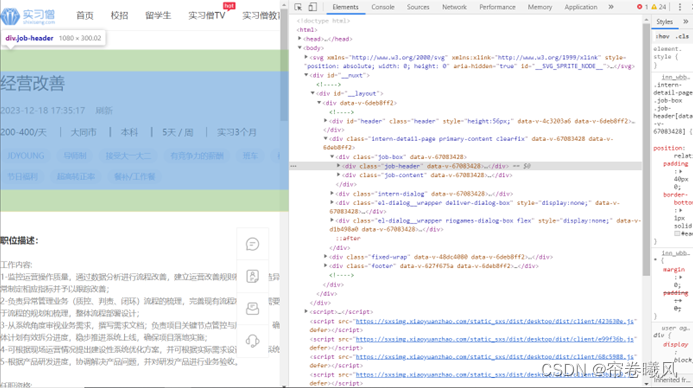
接着我们很快就找到了“城市”,把其中的“job_position”拿出来作为爬虫查找的依据
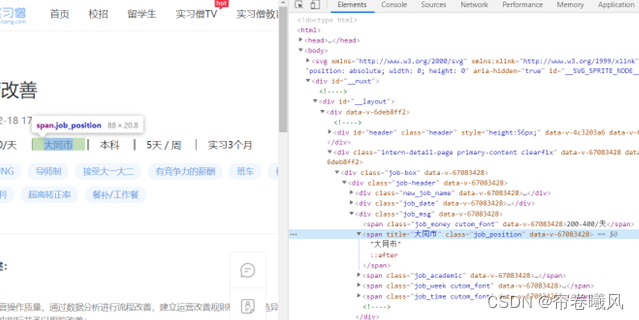
同理,如果我想获得具体的岗位的“职位描述”,仅需要到 job_content 底下找到 job_part 就行
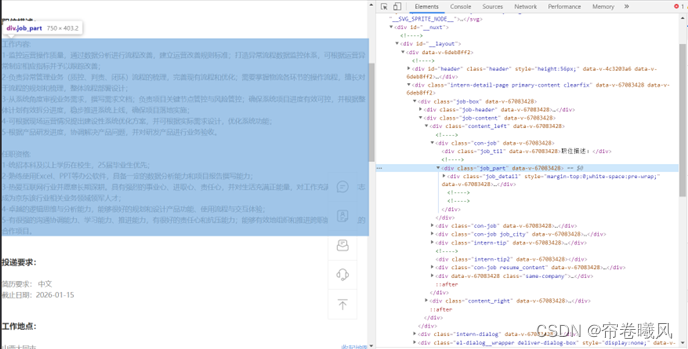
代码部分是类似这样的格式:
adress = soup.select('.job_position')[0].text.strip()
job_part=soup.select('.job_part')[0].text.strip()二.翻页循环在哪里?如何定义采集页数?
修改 for i in range()那栏里的数据;注意range(start,stop[,step])分别是起始、终止和步长,例如 for i in range(1,3)指的是将把1,2赋值给i,是不包括3的;假如我想采集3页,就应该改为for i in range(1,4)
三.网址替换、翻页循环的网址问题
1.网址替换在request.get()那里
2.通过观察我们发现实习僧网站具体岗位的不同页数的网址有细微区别,在page那里
比如这是第二页:
https://www.shixiseng.com/interns?page=2&type……
这是第三页、第四页
https://www.shixiseng.com/interns?page=3&type……
https://www.shixiseng.com/interns?page=4&type……
因此我们要稍微处理一下,把page那里改为page={ i }
def job_url():
for i in range(1,4):
req = requests.get(f'https://www.shixiseng.com/interns?page={i}&type=intern&keyword=数据仓库&area=&months=&days=°ree=本科&official=&enterprise=&salary=-0&publishTime=&sortType=&city=全国&internExtend=',
headers = headers)最后是完整代码
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
def detail_url(url):
html = requests.get(url,headers=headers).text
soup = BeautifulSoup(html, 'lxml')
title = soup.title.text
job = title.split("招聘")[0]
company_name = soup.select('.com_intro .com-name')[0].text.strip()
adress = soup.select('.job_position')[0].text.strip()
academic = soup.select('.job_academic')[0].text.strip()
good_list = soup.select('.job_good_list')[0].text.strip()
salary = soup.select(".job_money.cutom_font")[0].text.encode("utf-8")
salary = salary.replace(b'\xee\x8b\x92',b"0")
salary = salary.replace(b'\xee\x9e\x88',b"1")
salary = salary.replace(b'\xef\x81\xa1',b"2")
salary = salary.replace(b'\xee\x85\xbc',b"3")
salary = salary.replace(b'\xef\x84\xa2',b"4")
salary = salary.replace(b'\xee\x87\x99',b"5")
salary = salary.replace(b'\xee\x9b\x91',b"6")
salary = salary.replace(b'\xee\x94\x9d',b"7")
salary = salary.replace(b'\xee\xb1\x8a',b"8")
salary = salary.replace(b'\xef\x86\xbf',b"9")
salary = salary.decode()
print(":{} :{} :{} :{} :{} :{} ".format(job,salary,company_name,adress,academic,good_list))
def job_url():
for i in range(1,4):
req = requests.get(f'https://www.shixiseng.com/interns?page={i}&type=intern&keyword=数据仓库&area=&months=&days=°ree=本科&official=&enterprise=&salary=-0&publishTime=&sortType=&city=全国&internExtend=',
headers = headers)
html = req.text
soup = BeautifulSoup(html,'lxml')
offers = soup.select('.intern-wrap.intern-item')
for offer in offers:
url = offer.select(" .f-l.intern-detail__job a")[0]['href']
detail_url(url)
job_url()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









