







📚 博主的专栏
本文承接着上文继续讲解剩余的知识:协议解析与C++编写Http实现客户端服务器端的发送请求与响应
下篇文章:传输层协议-TCP
目录
1.Get方法不仅可以获取资源,同时也可以向服务器发送数据,同样Post方法也可以向服务器端推送数据。
2.POST可以通过http request的正文来进行参数传递
3.url传递参数,参数的体量一定不大,正文可以很大,因此这就是使用GET和POST的区别
注意:C++对于字符串的处理很麻烦,需要结合其他语言进行处理
C++是用来设计构建请求,构建应答的工作,因为C++比较高效。
摘要:本文系统解析HTTP协议核心机制,聚焦3XX重定向状态码(301/302)的应用场景与代码实现,对比GET/POST方法的参数传递差异及安全性问题。通过C++实战演示如何构建HTTP服务器,处理URL解析、动态资源响应及表单数据交互,结合Postman工具验证请求流程。文章详解Cookie在会话管理中的作用,探讨如何通过报头维持用户状态,并延伸C++与脚本语言(Python/PHP)协作的业务处理模式。内容涵盖协议原理、服务端开发及调试技巧,为网络编程提供从理论到落地的完整指南。
重定向状态码3XX
请求状态码:3XX
状态码 含义 是否为临时重定向 应用样例 301 MovedPermanently 否(永久重定向) 网站换域名后, 自动跳转到新域名;搜索引擎更新网站链接时使用 302 Found 或 See Other 是(临时重定向) 用户登录成功后,重定向到用户首页 307 TemporaryRedirect 是(临时重定向) 临时重定向资源到新的位置(较少使用 308 PermanentRedirect 否(永久重定向) 永久重定向资源到新的位置(较少使用)
当浏览器向服务器发送了请求,服务器给浏览器推了一个响应(不携带任何正文)在应答报头里包含一个Location:www.xxx.com,浏览器会识别到服务器响应回来的状态码(301\302),因此浏览器回转而向目标服务器www.xxx.com发起请求,由目标服务器来响应。
关于重定向的验证, 以 301 为代表 ,永久重定向是给搜索引擎看的!!!因为域名是被爬取到搜索引擎里面的,因此在访问新域名的时候,搜索引擎发现域名更改(发生永久重定向),就会用新域名替代旧域名做书签更新,将相关带域名的全部更新,往后别人再搜索的时候访问到的就是新域名。在用户看来实际上没什么区别。
HTTP 状态码 301(永久重定向) 和 302(临时重定向) 都依赖 Location 选项。 以下是关于两者依赖 Location 选项的详细说明:
HTTP 状态码 301(永久重定向):
• 当服务器返回 HTTP 301 状态码时, 表示请求的资源已经被永久移动到新的置。
• 在这种情况下, 服务器会在响应中添加一个 Location 头部, 用于指定资源的新位置。 这个 Location 头部包含了新的 URL 地址, 浏览器会自动重定向到该地址。
• 例如, 在 HTTP 响应中, 可能会看到类似于以下的头部信息:
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\n代码编写:
首先将某个跳转链接的按钮设置为目标redir(可能是一个服务)
然后再更改我们的Http.hpp中的代码(在上篇文章 有完整代码)
std::string HandlerHttpRequest(std::string &reqstr) { #ifdef TEST std::cout << "---------------------------------------" << std::endl; std::cout << reqstr; std::string responsestr = "HTTP/1.1 200 OK\r\n"; responsestr += "Content-Type: text/html\r\n"; responsestr += "\r\n"; responsestr += "<html><h1>hxy is a pigpig</h1></html>"; return responsestr; #else std::cout << "---------------------------------------------------"<<std::endl; std::cout << reqstr; std::cout << "---------------------------------------------------"<<std::endl; // 将请求构建成一个结构化请求 HttpRequest req; //响应: HttpResponse resp; // 反序列化 req.Deserialize(reqstr); if(req.Path() == "wwwroot/redir") { //要说清楚以什么协议去访问 std::string redir_path = "https://www.qq.com"; resp.AddCode(302, _code_desc[302]); resp.AddHeader("Location", redir_path); } else { // 最基本的上层处理 std::string content = GetFileContent(req.Path()); if(content.empty()) { //文件打开失败,返回一个404的页面就 std::string content = GetFileContent("wwwroot/404.html"); resp.AddCode(404, _code_desc[404]); resp.AddHeader("Content-Length", std::to_string(content.size())); resp.AddHeader("Content-Type", _mini_type[".html"]); resp.AddBodyText(content); } else { //状态码设置为200 resp.AddCode(200, _code_desc[200]); //告诉别人请求报头的长度 resp.AddHeader("Content-Length", std::to_string(content.size())); resp.AddHeader("Content-Type", _mini_type[req.Suffix()]); resp.AddBodyText(content); } } return resp.Serialize(); #endif }运行结果:
再在网页上点击我们的测试重定向的链接:
从而重定向到我们指定的页面
HTTP方法
接下来我们详细讲解HTTP的方法:
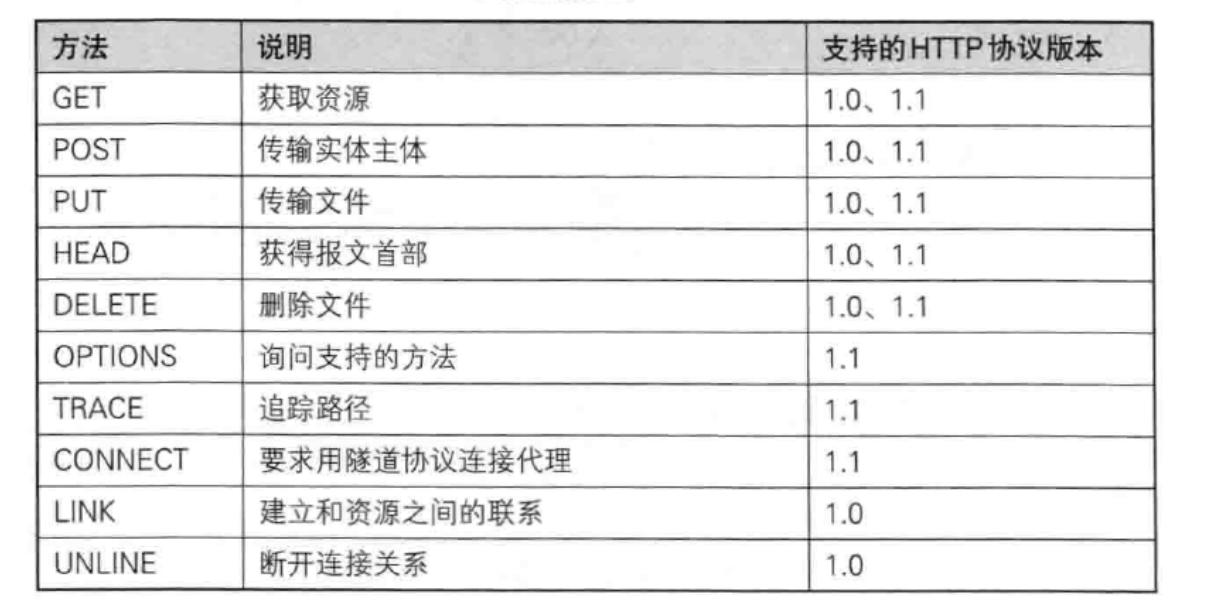
其中最常用的就是 GET 方法和 POST 方法
通过代码来看:
在HttpRequest类当中添加获取方法的公有函数:
std::string Method() { LOG(DEBUG, "Client request method %s\n", _method.c_str()); return _method; }在HttpServer类当中的处理HTTP请求的函数当中再添加一句打印方法:
运行结果: 我们可以看到所有的请求方法都是Get
HTTP 常见方法重点讲解GET\POST
1. GET 方法(重点)常用70%
用途: 用于请求 URL 指定的资源。
示例: GET /index.html HTTP/1.1
特性: 指定资源经服务器端解析后返回响应内容。
2. POST 方法(重点)常用30%
用途: 用于传输实体的主体, 通常用于提交表单数据。
示例: POST /submit.cgi HTTP/1.1
特性: 可以发送大量的数据给服务器, 并且数据包含在请求体中。
在这里需要再介绍一个软件:
Postman软件
Fiddler使用来本地主机之间进行抓包的,Postman是用来构建Http请求的
当我们点击Send之后:
基本上和Fiddler相似的展现一些,但是没有Fiddler做的优雅,全面
1.Get方法不仅可以获取资源,同时也可以向服务器发送数据,同样Post方法也可以向服务器端推送数据。
再次Send:就可以向服务器传递参数。
使用Post方法,向对应的这个URL发送特定的请求:
再次Send:
这个时候的参数,并没有像我们的预期,放在URL后面,而是放在了正文部分,参数以正文方式发给了服务器端。
2.POST可以通过http request的正文来进行参数传递
以代码形式演示真实情况下GET和POST是如何做的:
需要结合前端的form表单完成GET or POST 请求
演示:
我们需要准备好一个Login.html页面:我这里就直接贴一个表单的代码图
这是我的登录页面,当我们在输入好用户名和密码点击提交后:
当我们查看服务器获得的请求内容时:这里就会记录到我们所填写的内容,并且用的POST方法,正文字段通过我们前端代码的命名,来赋值:
而当我们将表单的提交方法改为GET:
此时在链接中就会直接显示出我们所填写的内容
3.url传递参数,参数的体量一定不大,正文可以很大,因此这就是使用GET和POST的区别
4.POST方法,比GET方法传参更私密,但是都不安全
因此可以对HTTP的参数部分进行加密,也就是HTTPS
而所提交的参数最终会交给表单中所写到的action里面的内容:
我们需要注意的是,如果使用的是post为提交方式也就意味着我们所传的参数存在正文内容里面,使用的是GET也就是说参数包括路径一起都存在url中。因此在前方处理请求反序列化的时候,我们还需要改进:如果传过来的是/login?username=XXX&userpasswd=XXXX,实际上的url只有login,参数是后面的一块。
const static std::string arg_sep = "?";(strcasecmp--->忽略大小写的来比较两个字符串的大小)
修改HttpRequest类当中的解析行的函数:
void ParseReqLine() { // 将字符串转化成 字符串流 std::stringstream ss(_req_line); // 类似于cin >> ss >> _method >> _url >> _version; // 依次按空格为分隔符依次输入多个单词 _path += _url; // (strcasecmp--->忽略大小写的来比较两个字符串的大小) // 根据是否包含问号,来决定是否处理 if(strcasecmp(_method.c_str(), "GET") == 0) { auto pos = _url.find("arg_sep"); if(pos != std::string::npos) { //包含问号,我们就将?后部分截取到正文部分 _body_text = _url.substr(pos + arg_sep.size()); //将pos后的字符串全部删除 _url.erase(pos); } } //判断打开的是否是根目录,也就是需要打开默认页 if(_path[_path.size() - 1] == '/') { _path += homepage; } //提取后缀: auto pos = _path.find(suffixsep); if(pos != std::string::npos) { _suffix = _path.substr(pos); } else { _suffix = ".default"; } }再提供获取_body_text的接口:
std::string GetRequestBody() { LOG(DEBUG, "Client request method is %s, args is %s, request path: %s\n" , _method.c_str(), _body_text.c_str(), _path.c_str()); return _body_text; }如图: 我们获取到了body_text,此时我们使用的是Get方法
现在我们换成post看看现象:
action?
我们先再优化代码:
Http.hpp
首先我们需要做一个任务,将任务处理结果返回,这个action就是来处理这件事了:
定义一个返回值是HttpResponse类型,参数是HttpRequest的函数类型
using func_t = std::function<HttpResponse (HttpRequest &)>;创建一个服务列表成员自定义类型变量:参数就是服务的目录以及任务
// 创建一个服务列表 std::unordered_map<std::string, func_t> _service_list;创建一个接口,用于插入想要执行的方法:
void InsertService(const std::string &servicename, func_t f) { //不存在就插入,存在就更新: _service_list[servicename] = f; } //判断服务是否存在 bool IsServiceExists(const std::string &servicename) { auto iter = _service_list.find(servicename); //说明服务不存在 if(iter == _service_list.end()) return false; else return true; }再在ServiceMain.cc调用服务器的文件:
//会话层,只有一个tcp服务器-->进行基本的tcp管理 #include "TcpServer.hpp" //能够读到http字符串 #include "Http.hpp" HttpResponse Login(HttpRequest &req) { } // ./tcpserver 8888 int main(int argc, char *argv[]) { if (argc != 2) { std::cerr << "Usage: " << argv[0] << " local-port" << std::endl; exit(0); } uint16_t port = std::stoi(argv[1]); HttpServer hserver; //让服务器支持登录功能: 服务名,方法函数 hserver.InsertService("/login", Login); // hserver.InsertService("./register", Login); // hserver.InsertService("./search", Login); // //构建TCP服务器 std::unique_ptr<TcpServer> tsvr = std::make_unique<TcpServer>( std::bind(&HttpServer::HandlerHttpRequest, &hserver, std::placeholders::_1), port); tsvr->Loop(); return 0; }路径还需要拼接,因为我们的页面资源等都是放在wwwroot下的:
修改服务列表:
void InsertService(const std::string &servicename, func_t f) { std::string s = prefixpath + servicename; //不存在就插入,存在就更新: _service_list[s] = f; }然后经历这样的一个历程:
我们将参数提交给服务器内部指定的服务,在服务器内部做处理。(最后实际上是tcpserver去做的处理)
HttpResponse Login(HttpRequest &req) { HttpResponse resp; std::cout << "外部已经拿到参数了:" << std::endl; //这里将打印我们获取到的Requestbody以及请求方法、和path req.GetRequestBody(); std::cout << "#####################################" << std::endl; resp.AddCode(200, "OK"); resp.AddBodyText("<html><h1>result done!!</h1></html>"); return resp; }最后运行结果:我们得到了这个页面,说明传参被处理成功
因此,action这里的参数到底是什么呢?
这里的form表单在提参数的时候,这个参数一般在C++里面是提交给指定的例如这里的/login,让他直接直接把这个参数注册到HttpServer里对应的服务当中,服务拿到了这个参数,在后续就能进行数据库的访问了。
注意:C++对于字符串的处理很麻烦,需要结合其他语言进行处理
username=helloworld&userpasswd=123456
但是在未来,C++就不再去处理业务(处理数据了,通过一些方法:
1. pipe
2. dup2
3. fork();
把我们的参数交给
4. exec* -> python, PHP, 甚至是Java!
再由这些语言处理完这些参数后,在通过向标准输出打印,因为我们已经做过重定向了,然后HttpServer就获取到他们处理好的结果,最后再给别人构建response返回
因此为什么说php、python、java是web语言,就是因为别人已经给他们把所有的工作都做好了,他们需要拿到参数去写登录注册,访问数据库的操作。
C++是用来设计构建请求,构建应答的工作,因为C++比较高效。
现在我们可以理解一下百度的搜索功能:
hi_百度搜索![]() https://www.baidu.com/s?wd=hi&rsv_spt=1&rsv_iqid=0xd0e74be300084d92&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=5&rsv_sug1=1&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&prefixsug=hi&rsp=6&inputT=2206&rsv_sug4=8905s实际上就是类似于我们的login一样是HTTP服务的入口就是他算法的入口。
https://www.baidu.com/s?wd=hi&rsv_spt=1&rsv_iqid=0xd0e74be300084d92&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=5&rsv_sug1=1&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&prefixsug=hi&rsp=6&inputT=2206&rsv_sug4=8905s实际上就是类似于我们的login一样是HTTP服务的入口就是他算法的入口。

cookie报头:
用于在客户端存储少量信息,通常用于实现会话(session)的功能
我们会遇到这些情况
1.必须登录,不登录,只能试看5min.
2.必须是会员,否则只能看vip视频里的5min
那么服务器是怎么知道我们是谁的呢?去区分我是否登录,是否是vip。
会话管理:
因此我们必须要有一种策略去标识用户状态,对用户的登录状态进行保持,方便随时验证用户身份。
http不是无状态的吗,但是在实际情况下为什么能够实现状态保持呢,就是因为提供了cookie功能,来维持状态,是http的报头属性(通常在响应报文添加),可以像客户端浏览器写入信息,从此往后,当浏览器发送请求的时候,他都自动将曾经写入的cookie信息携带上,方便服务器端随时进行身份验证。就像是我们登陆了一次csdn之后,之后打开csdn就基本不用再登录了。成为了合法用户。就例如上班进入公司,入职时第一次带上工牌,往后进入公司有工牌就能被保安识别到,安全放行。这里的工牌就是cookie值,浏览器就是打工人,cookie向浏览器写值,就是把工牌交给浏览器,浏览器每次请求时都携带上工牌。
比如登录B站时,这些就是存在b站中的cookie值。
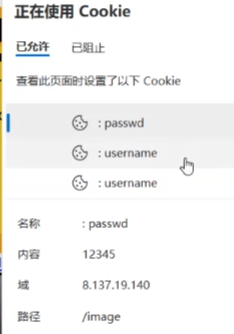
关于cookie和session,将会写一篇专门的文章来讲解,有兴趣的朋友可以在我们计算机网络专栏看看。
结语:
随着这篇博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









