






 本文详细介绍了Hive,一个使用类SQL语言处理大数据的Hadoop生态系统组件。它包括服务端组件如Metastore和客户端接口如CLI和JDBC/ODBC,以及ThriftServer和WEBGUI。通过实例展示了如何创建和操作Hive数据库及执行各种查询操作。
本文详细介绍了Hive,一个使用类SQL语言处理大数据的Hadoop生态系统组件。它包括服务端组件如Metastore和客户端接口如CLI和JDBC/ODBC,以及ThriftServer和WEBGUI。通过实例展示了如何创建和操作Hive数据库及执行各种查询操作。
Hive是一个基于Hadoop的数据仓库系统,它允许用户使用类SQL语言查询存储在Hadoop分布式文件系统中的大型数据集。Hive旨在为数据分析师和数据科学家提供一个简单的工具,以便他们可以使用熟悉的SQL语言来处理和分析大数据集。
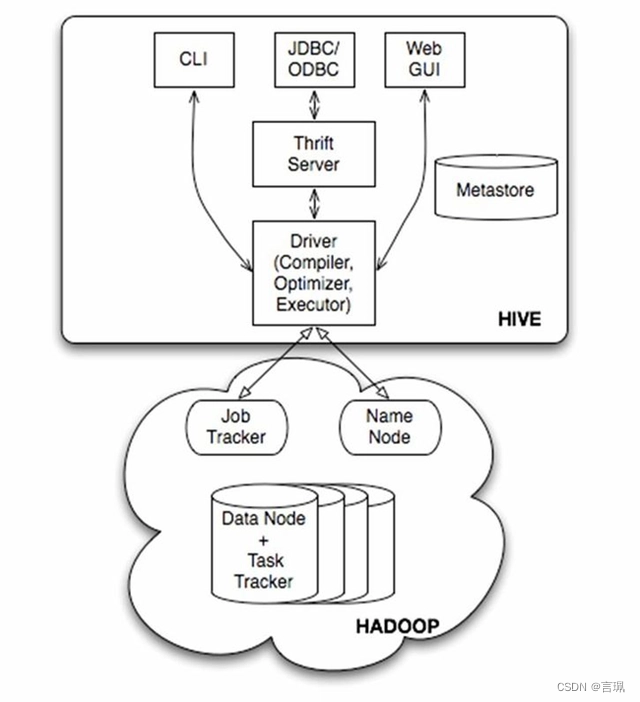
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(ComplierOptimizer和Executor),这些组件我可以分为两大类:服务端组件和客户端组件。 CLI(Command Line Interface):Hive的命令行接口,允许用户通过命令行窗口执行Hive查询和操JDBC/ODBC:Hive提供了Java数据库连接(JDBC)和开放数据库连接(ODBC)接口,使得用户可以通过各种编程语言和工具连接并操作Hive数据库。Thrift Server:Hive Thrift Server是一个支持多客户端并发连接的服务,允许远程客户端通过Thrift协议与Hive进行交互。WEB GUI:Hive提供了一个Web界面,用户可以通过浏览器访问并执行Hive查询和操作。Metastore:Hive元数据存储,用于存储表结构、分区信息、表位置等元数据信息,以便Hive可以对数据进行查询和操作。Driv(Compiler、Optimizer和Executor):Hive查询处理过程中的三个重要组件。Compiler负责将HiveQL查询编译成逻辑执行计划,Optimizer优化执行计划以提高查询性能,Executor执行优化后的查询计划并返回结果。
数据库....
最基础的
-- 创建一个名为 'students' 的表,包含三列:id, name, grade
CREATE TABLE students (id INT, name STRING, grade FLOAT);
-- 向 'students' 表中插入数据
INSERT INTO TABLE students VALUES (1, 'Alice', 90.5), (2, 'Bob', 85.5);
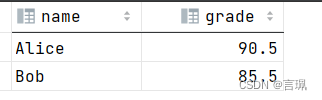
-- 查询 'students' 表中所有学生的名字和成绩
SELECT name, grade FROM students;
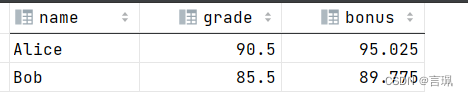
-- 计算每个学生的成绩加上5%的bonus
SELECT name, grade, (grade * 1.05) AS bonus FROM students;
-- 统计所有学生的平均分
SELECT AVG(grade) FROM students;















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









