







这篇博客呢,作者打算复盘下工作室期中答辩的内容。第一个任务是:爬取安居客二手房数据 数据要求10万条数据以上,并写入csv文件。第二个任务是:对数据做最基础和简单的可视化展示。说实话,刚看到这俩任务的时候我还是有点窃喜的,毕竟感觉还是蛮简单的,but,实际上做起来我还是遇到了诸多困难,比如说IP池的搭建和使用,这个困扰我至今没有解决;再比如说多线程,即使这个现在能初步运用,但是代码的实现还是过于粗糙了。
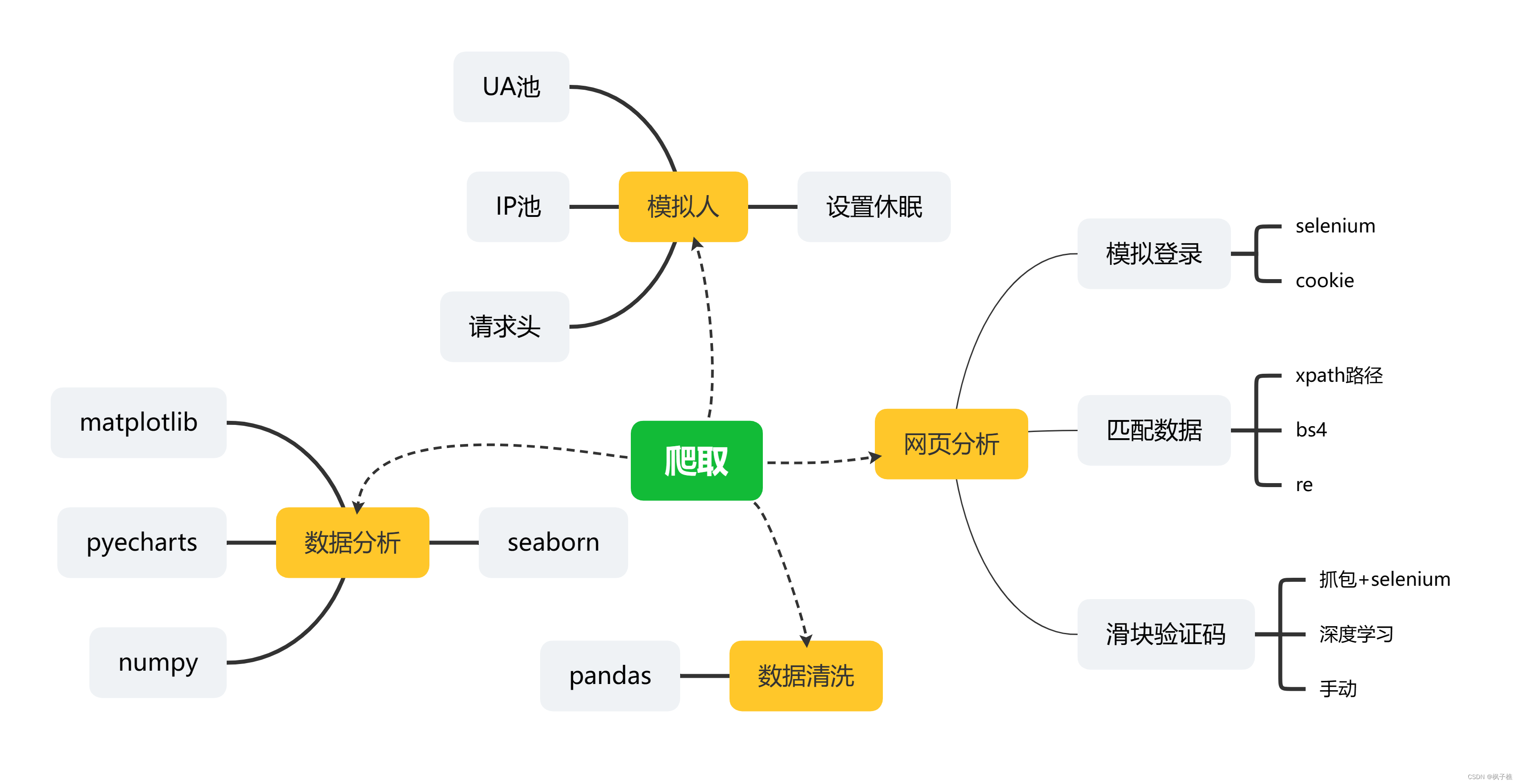
以下是复盘的思维导图:
一.任务要求
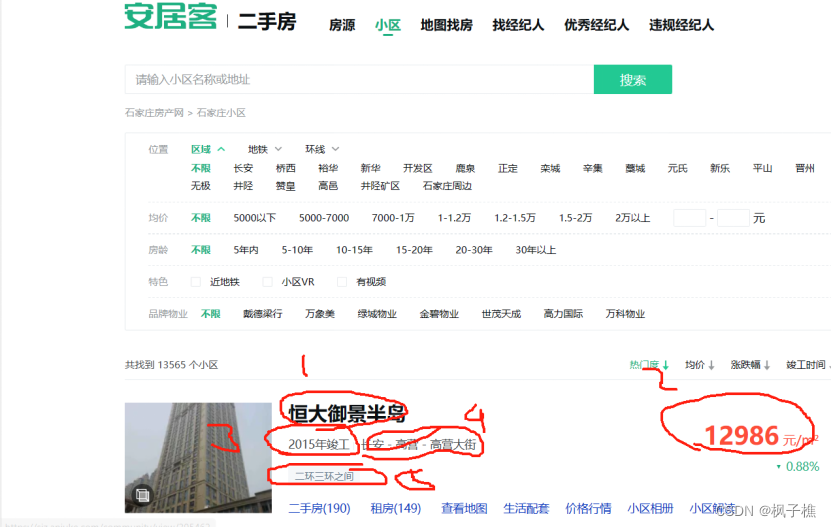
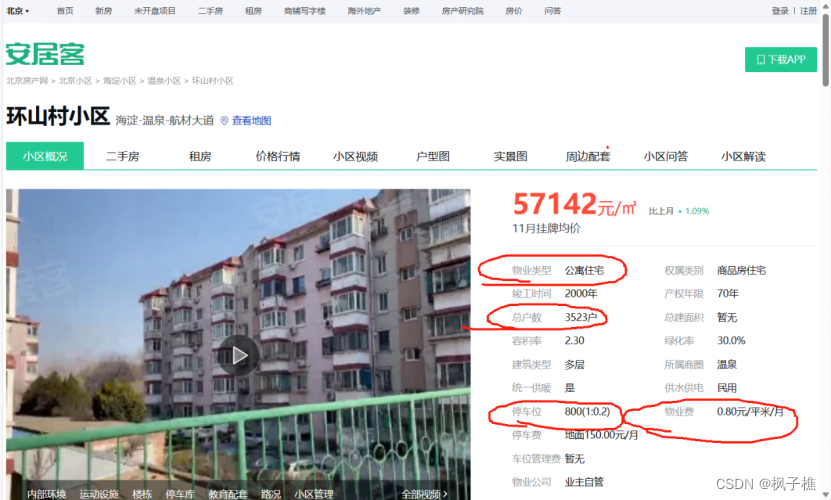
爬取以下画圈数据写入csv,进行初步数据分析
二.网页分析
1.网址分析
首先看一下网址的构成:
target_url = "https://sjz.anjuke.com/community/p1/"不难发现想换页可以将p1替换成p2,p3等等,想换城市就将sjz换成其他城市的名称。吐个槽,这个城市名称有的是拼音首字母,有的是全称,还得核对。
所以可以写成以下形式:
target_url = 'https://{}.anjuke.com/community/p{}/'.format(name, page)但是某小区的网址怎么获取呢,我们观察下源码
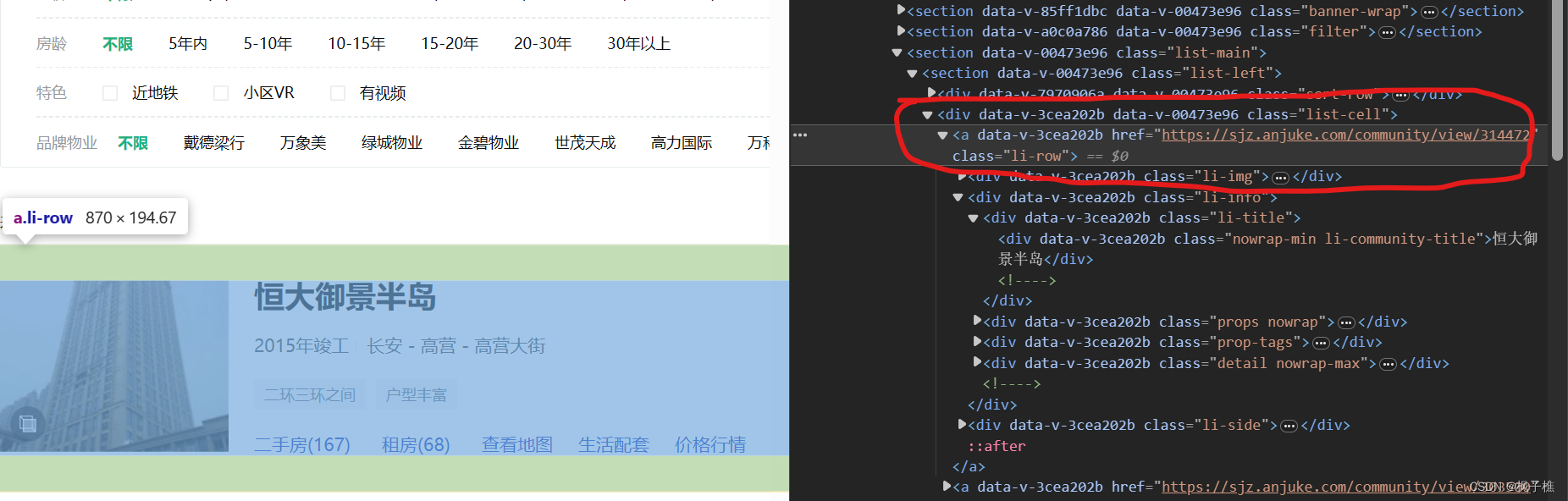
可以发现源码里携带着小区网址,那么我们可以先把网址爬下来后二爬。当然这也是造成爬取时间较长的一个关键原因。
2.匹配数据
1).xpath路径匹配
这个比较简单,就不多做介绍了。代码见后文。
2).bs4匹配
就是感觉这个库没有xpath路径匹配来得简单。下次有时间学学。
3.滑块验证以及模拟登录
这显然是一个极难的点,但是可以使用selenium解决,遗憾的是作者当时准备答辩的时候太仓忙了,加上需要爬的数据量有点大,加上自身的技术还不够,所以都是手动解决的。哇想起来都是泪啊,就一直守在电脑边等待报错。
至于登录的话作者暂时只能做到手动创建账号登录然后拿到cookie,当然这也是可以用selenium来自动获取的。
三.代码
from ua_pool import *
import requests
from lxml import etree
import time
import random
import csv
import threading
def write_csv(s): # 写入
with open('data', 'a+', newline='', encoding='utf-8_sig') as f:
writer = csv.DictWriter(f, fieldnames=['名字', '竣工时间', '地理位置', '特征', '房价', '物业类型', '总户数',
'停车位', '物业费'])
writer.writerows(s)
def standing_format(a): # 修正格式
for i in range(len(a)):
if '\n' in str(a[i]):
a[i] = str(a[i]).replace('\n', '')
if ' ' in str(a[i]):
a[i] = str(a[i]).replace(' ', '')
return a
def get_items(source): # 获取名字,竣工时间,地理位置,房价
tree = etree.HTML(source)
url_list = tree.xpath('//*[@id="__layout"]/div/section/section[3]/section/div[2]/a/@href')
house_list = tree.xpath('//*[@id="__layout"]/div/section/section[3]/section/div[2]/a/div[@class="li-info"]/div[@cla'
'ss="li-title"]/div[@class="nowrap-min li-community-title"]/text()') # 小区名
time_list = tree.xpath('//*[@id="__layout"]/div/section/section[3]/section/div[2]/a/div[@class="li-info"]/div[@cl'
'ass="props nowrap"]/span[1]/text()') # 竣工时间
location_list = tree.xpath('//*[@id="__layout"]/div/section/section[3]/section/div[2]/a/div[@class="li-info"]/div[@cl'
'ass="props nowrap"]/span/text()') # 地理位置
price_list = tree.xpath('//*[@id="__layout"]/div/section/section[3]/section/div[2]/a/div[3]/div/strong/text()') # 房价
content = [{'url_list': url_list}, {'house_list': house_list}, {'time_list': time_list},
{'location_list': location_list}, {'price_list': price_list}]
return content
def get_feature(source, a): # 获取特征
tree = etree.HTML(source)
feature_list = tree.xpath('//*[@id="__layout"]/div/section/section[3]/section/div[2]/a[{}]/div[2]/div[3]/'
'span/text()'.format(a))
return feature_list
def get(source): # 获取物业类型,总户数,停车位,物业费
tree = etree.HTML(source)
houseType = standing_format(
tree.xpath('//*[@id="__layout"]/div/div[2]/div[3]/div[2]/div[1]/div[2]/div/div[1]/div[2]/div[1]/text()'))
familyNumber = standing_format(
tree.xpath('//*[@id="__layout"]/div/div[2]/div[3]/div[2]/div[1]/div[2]/div/div[5]/div[2]/div[1]/text()'))
parkNumber = standing_format(
tree.xpath('//*[@id="__layout"]/div/div[2]/div[3]/div[2]/div[1]/div[2]/div/div[13]/div[2]/div[1]/text()'))
serviceFee = standing_format(
tree.xpath('//*[@id="__layout"]/div/div[2]/div[3]/div[2]/div[1]/div[2]/div/div[14]/div[2]/div[1]/text()'))
content = [{'houseType': houseType}, {'familyNumber': familyNumber}, {'parkNumber': parkNumber},
{'serviceFee': serviceFee}]
time.sleep(random.randint(0, 1))
return content
def get_source1(name, page):
target_url = 'https://{}.anjuke.com/community/p'.format(name) + str(page) + '/'
response = requests.get(url=target_url, headers=headers)
response.close()
res = response.text
return res
# name, page = 'shanghai', 1
# target_url = 'https://{}.anjuke.com/community/p{}/'.format(name, page)
# print(target_url)
def get_source2(target_url):
url_response = requests.get(url=target_url, headers=headers)
url_response.close()
url_res = url_response.text
return url_res
def main(*data):
p = data[0]
lock = threading.Lock()
for s in p:
lock.acquire()
start = time.time()
sou = get_source1(city, s)
content_list1 = get_items(sou)
content_list2 = []
content_list3 = []
li = []
for z in range(1, 26):
content_list2.append(get_feature(sou, z))
for url in content_list1[0]["url_list"]:
Sou = get_source2(url)
content_list3.append(get(Sou))
for y in range(25):
Content = {'名字': content_list1[1]['house_list'][y],
'竣工时间': content_list1[2]['time_list'][y],
# '竣工时间': '暂无',
'地理位置': content_list1[3]['location_list'][y],
'特征': content_list2[y],
# '特征': '暂无',
'房价': content_list1[4]['price_list'][y],
'物业类型': content_list3[y][0]['houseType'][0],
'总户数': content_list3[y][1]['familyNumber'][0],
'停车位': content_list3[y][2]['parkNumber'][0],
'物业费': content_list3[y][3]['serviceFee'][0]
}
li.append(Content)
write_csv(li)
end = time.time()
print("第{}页爬取完成,用时".format(s), end - start, "seconds")
lock.release()
if __name__ == '__main__':
city = ['nb', 'beijing', 'sjz', 'shanghai', 'hangzhou', 'suzhou', 'guangzhou', 'tianjin', 'dalian', 'sy', 'heb',
'ty', 'cc', 'weihai', 'weifang', 'huhehaote', 'baotou', 'qinhuangdao', 'yt', 'baoding', 'nanjing', 'wuxi',
'jinan', 'qd', 'ks', 'nanchang', 'fz', 'hf', 'xuzhou', 'zibo', 'nantong', 'cz', 'huzhou', 'shaoxing',
'yancheng', 'bengbu', 'wenzhou', 'jx', 'taicang', 'shenzhen', 'foshan', 'fs', 'cs', 'sanya', 'huizhou',
'dg', 'haikou', 'zh', 'zs', 'xm', 'nanning', 'quanzhou', 'liuzhou', 'chongqing', 'wuhan', 'zhengzhou', 'xa',
'km', 'gy', 'lanzhou', 'luoyang', 'nanyang', 'chenzhou', 'xianyang', 'mianyang', 'wulumuqi', 'tongling',
'dongyang', 'guilin', 'chuzhou', 'anqing', 'beihai', 'fuzhoushi', 'changde', 'cixi', 'deqingxian',
'lianyungang', 'jiujiang', 'dali', 'dezhou', 'huangshan', 'lishui', 'zhangjiakou', 'yichun', 'xuancheng',
'taiz', 'jinzhong', 'jiangyin']
for city in city:
headers = {
'User-Agent': str(my_ua_pool.get_useragent()),
'Cookie': ''}
page1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
page2 = [11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
page3 = [21, 22, 23, 24, 25, 26, 27, 28, 29, 30]
page4 = [31, 32, 33, 34, 35, 36, 37, 38, 39, 40]
page5 = [41, 42, 43, 44, 45, 46, 47, 48, 49, 50]
# page1 = [1, 2, 3, 4, 5]
# page2 = [6, 7, 8, 9, 10]
# page3 = [11, 12, 13, 14, 15]
# page4 = [16, 17, 18, 19, 20]
t1 = threading.Thread(target=main, args=(page1,))
t2 = threading.Thread(target=main, args=(page2,))
t3 = threading.Thread(target=main, args=(page3,))
t4 = threading.Thread(target=main, args=(page4,))
t5 = threading.Thread(target=main, args=(page5,))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
注释:这里UA池呢可以直接使用fake_useragent这个库就好了,作者当时为了实验一下调包才这么写的。哇这个线程池写的超级粗糙,后面可以在修改修改。以下是数据爬取完成的截图。
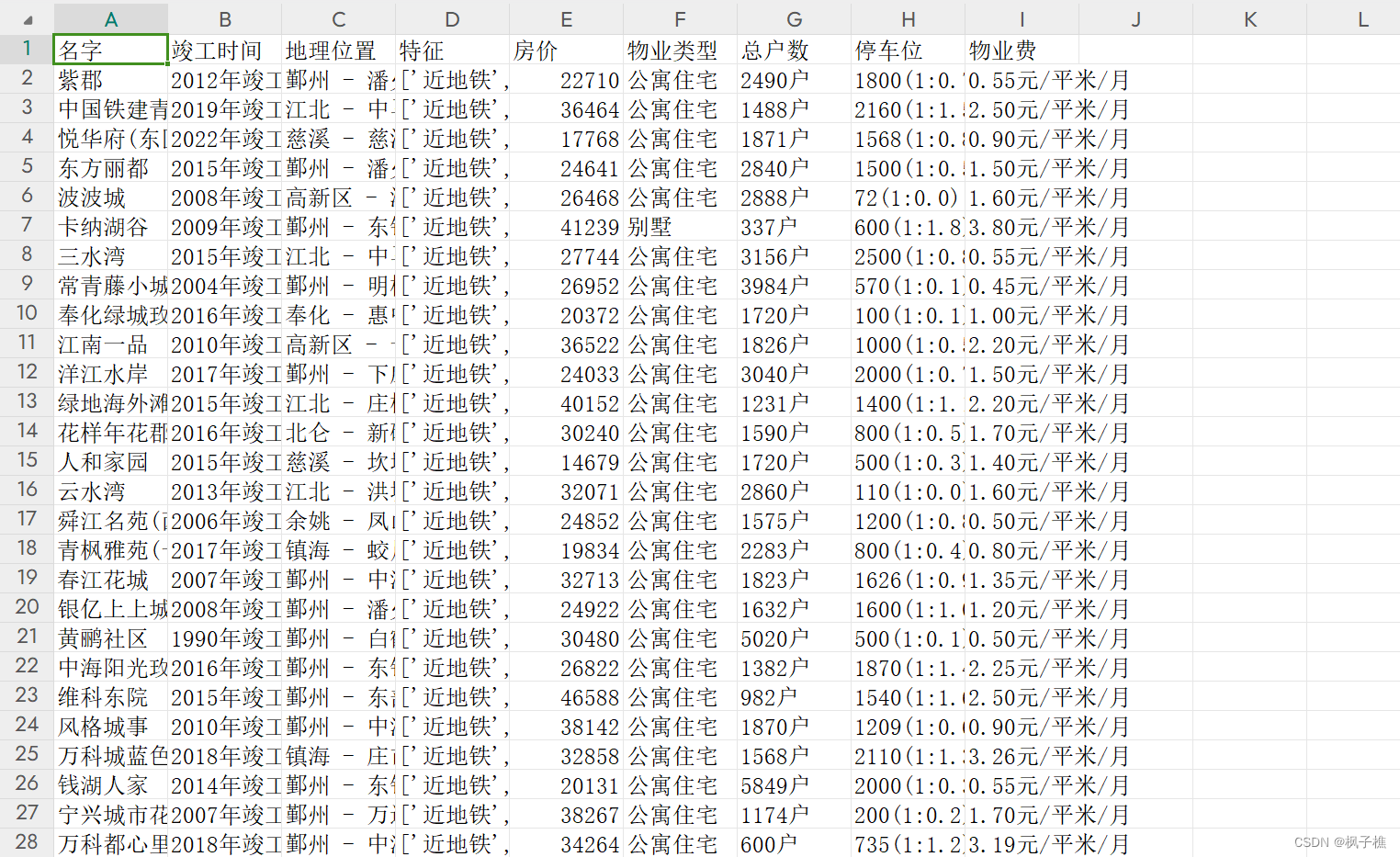 四.可视化
四.可视化
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Pie
data = pd.read_csv('data.csv', low_memory=False)
price = data.get('房价').head(1000)
df = pd.DataFrame(price)
df1 = df[df['房价'] <= 10000]
df2 = df[(df['房价'] > 10000) & (df['房价'] <= 20000)]
df3 = df[(df['房价'] > 20000) & (df['房价'] <= 30000)]
df4 = df[(df['房价'] > 30000) & (df['房价'] <= 40000)]
df5 = df[(df['房价'] > 40000) & (df['房价'] <= 50000)]
df6 = df[(df['房价'] > 50000) & (df['房价'] <= 60000)]
df7 = df[(df['房价'] > 60000) & (df['房价'] <= 70000)]
df8 = df[(df['房价'] > 80000) & (df['房价'] <= 90000)]
df9 = df[(df['房价'] > 90000) & (df['房价'] <= 100000)]
df10 = df[df['房价'] > 100000]
data1 = [("小于一万", len(df1)), ("1万~2万", len(df1)), ("2万~3万", len(df2)), ("3万~4万", len(df3)),
("4万~5万", len(df4)), ("5万~6万", len(df5)), ("6万~7万", len(df6)), ("7万~8万", len(df7)),
("8万~9万", len(df8)), ("9万~10万", len(df9)), ("大于10万", len(df10))]
pie = (Pie()
.add("", data1)
.set_global_opts(title_opts=opts.TitleOpts(title="宁波市1000个热门小区房价"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
# pie.render_notebook()
pie.render("宁波房价饼图.html")
这里使用的是pyecharts进行的一个基础可视化,再深入的话可以用机器学习去分析或者预测房价走势什么的。效果如下: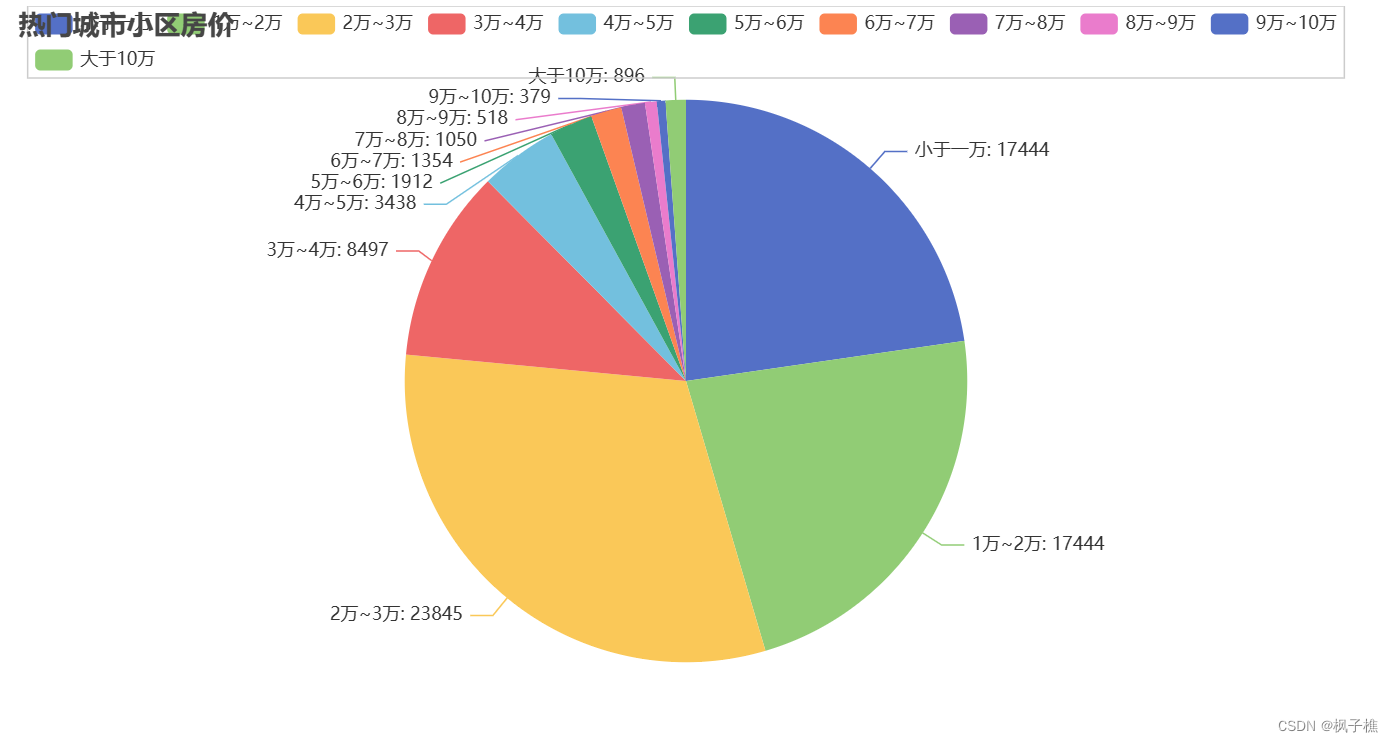
五.总结
怎么说呢,这篇复盘其实已经从上学期快期末的时候开始写,已经过去大几个月,一直拖着没写完,总的来说,做完这个答辩给了我启发以及知识面的拓展,受益良多。但是代码写的太过粗糙了,有待改进。做一下后面的大致计划好了,可以再去巩固线程的知识,然后去学一下异常地抛出,还有数据清洗啥的......
写一下作者寒假到大一下学期快结束这期间的感悟吧。作者寒假的时候本来是打算准备蓝桥杯的,包括开学一直到比赛的那段时间,但是由于自身的怠惰,三天打鱼两天晒网,最后想学的东西没学到,还白白浪费了报名费。在比赛之前,作者一直是有认知误区的,以为蓝桥杯很简单,但其实只是相较于acm那种赛事来说是比较简单的,这导致比赛后我被狠狠的打击了。算法呢,就是有点枯燥的,想要学出点成果呢,贵在坚持,坚持每天去刷题,去理解,慢慢也就有成效了。okey,可以从现在开始准备下一次比赛了,争取拿下!
















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









