






一、redis的性能管理
1、内存指标info memory
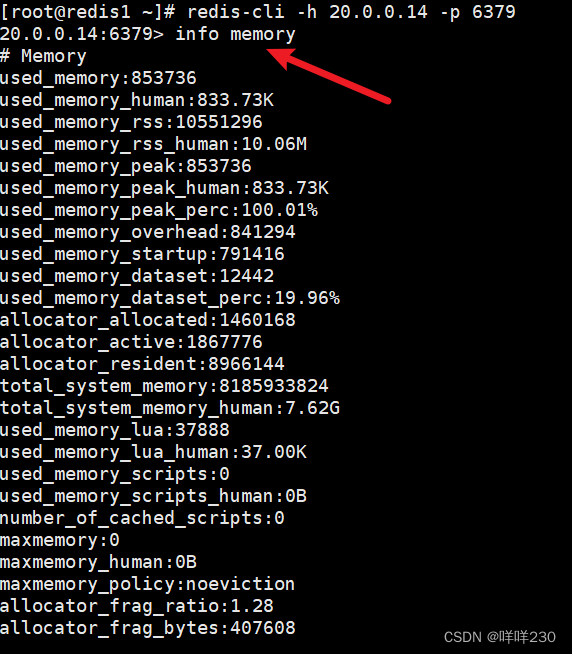
| 内存指标(重要) | |
| used_memory:853736 | 数据占用的内存 |
| used_memory_rss:10551296 | redis向操作系统申请的内存 |
| used_memory_peak:853736 | redis使用内存的峰值 |
| 注:单位:字节 | |
系统巡检:硬件巡检、数据库、中间件(nginx、redis)、docker、k8s
2、内存碎片率
(1)定义:系统已分配给redis,但reids未能有效利用的内存
(2)计算格式:内存碎片率=used_memory_rss/used_memory
(3)监控指标redis-cli info memory|grep ratio(生产环境常用)
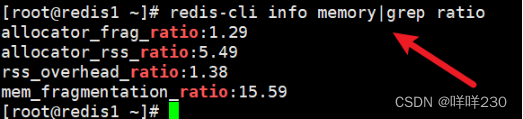
| 监控指标 | 定义 | |
| allocator_frag_ratio:1.29 | 分配器碎片的比例 (越小越好,值越高,内存浪费越多) | redis主进程调度时产生的内存 |
| allocator_rss_ratio:5.49 | 分配器占用物理内存的比例 | 主进程调度时占用的物理内存 |
| rss_overhead_ratio:1.38 | redis占用物理空间额外的开销比例(比例越低越好,redis实际占用的物理内存和向系统申请的内存越接近,额外的开销越低) | RSS是redis向系统申请的内存空间 |
| mem_fragmentation_ratio:15.59 | 内存碎片率 (越低越好,内存使用率越高) | |
3、清理内存的两种方式
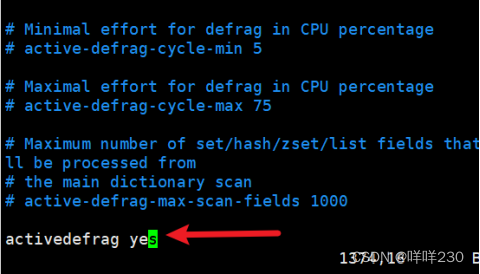
(1)自动清理碎片vim /etc/redis/6379.conf
末尾添加activedefrag yes自动清理碎片的配置
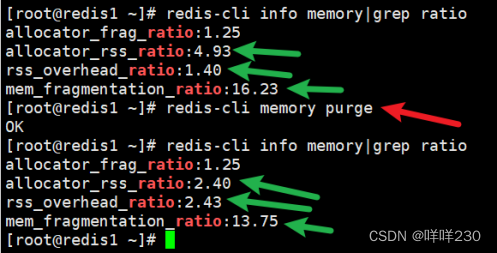
(2)手动清理碎片redis-cli memory purge
4、设置redis的最大内存阀值
(在工作中一定要设置redis的占用内存阈值。若不设置阈值,会塞满内存,直到炸)
(1)先设置最大内存阀值vim /etc/redis/6379.conf
添加maxmemory 1gb
一旦达到阀值,会自动清理碎片,开启key的回收机制
(2)再开启key的回收机制
| key的回收机制 | |
| maxmemory-policy volatile-lru (常用) | 使用redis内置的lru算法,在已设置过期时间的键值对中淘汰数据中,移除最近最少使用的键值对 |
| maxmemory-policy volatile-ttl (常用) | 使用redis内置的ttl算法,在已设置过期时间的键值对中挑选一个即将过期的键值对 |
| maxmemory-policy volatile-random (少用) | 在已设置过期时间的键值对中,挑选数据,随机淘汰键值对 |
| 注:以上算法只针对已设置过期时间的键值对,永不过期的不在此范围内 | |
| allkeys-lru | 使用redis内置的lru算法,对所有的键值对进行淘汰,移除最少使用的键值对 |
| allkeys-random (更少用) | 在所有键值对中任意选择数据进行淘汰 |
| 注:以上算法针对所有的键值对,无论是否设置过期时间 | |
| maxmemory-policy noeviction (最常用) | 禁止键值对回收(不删除任何键值对,直到redis把内存塞满,写满报错为止) |
【面试题】redis占用内存的效率问题如何解决?(经验)
①日常巡检中,监控redis的占用情况
②设置redis占用系统内存的阀值,避免占用系统全部内存
③手动/自动清理内存碎片
④配置合适的key回收机制
5、redis雪崩(缓存雪崩)(少见)
(1)定义
大量的应用请求无法在redis缓存中处理,请求会全部发送到后台数据库,数据库并发能力本身就差,一旦高并发,数据库很快会崩溃
(2)产生雪崩的原因
①redis集群大面积故障
②在redis缓存中,大量数据同时过期,大量的请求无法得到处理
③redis实例宕机
(3)解决雪崩的方式
①事前预防:采用高可用架构(主从复制、哨兵模式、redis集群),防止整个缓存故障
②事中处理(开发):在国内通用方式——HySTRIX(熔断、降级、限流),降低雪崩发生后的损失,确保数据库不死,可以慢,但不能没有响应
③事后解决:以redis备份的方式恢复数据(运维)或快速缓存预热(开发)
6、redis的缓存击穿(重点)
(1)产生原因
①热点数据缓存过期或被删除,当多个请求并发访问热点数据时,请求转发到数据库,导致数据库性能快速下降。经常被请求的缓存数据最好设置为永不过期
②键值对还在,但值被替换,原有的请求找不到之后,同样会请求后台数据库,导致数据库性能快速下降
(2)解决方式
①热点数据设置成永不过期
②恢复原有的值
7、redis的缓存穿透(恶意攻击)(很少见)
(1)定义
缓存中没有数据,数据库也没有相应的数据,但有用户一直在发起这个都没有的请求,而且请求的数据格式很大。这种情况一般是黑客利用漏洞攻击,压垮应用数据库
(2)解决方式:专门的安全人员处理
二、redis的集群架构
1、高可用方案
(1)主从复制
(2)哨兵模式
(3)redis集群
2、主从复制
(1)主从复制是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础上实现高可用
(2)主从复制实现数据的多机备份和读写分离(主服务器——写,从服务器——读)
缺点:故障无法自动恢复,需人工干预,无法实现写操作的负载均衡
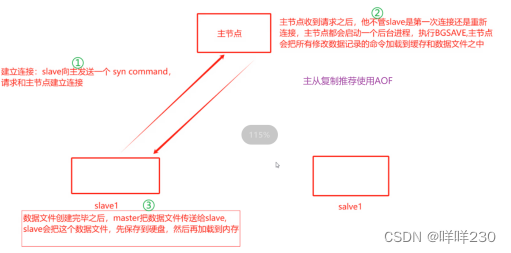
3、主从复制的工作原理
由主节点master和从节点slave组成,数据复制是单向的,只能从主节点到从节点
4、哨兵模式
在主从复制的基础上实现主节点故障的自动切换
(1)哨兵模式定义
哨兵是一个分布式系统,用于在主从结构之间,对每台redis服务进行监控。主节点出现故障时,从节点通过投票的方式选择一个新的master
哨兵模式也需要至少三个节点
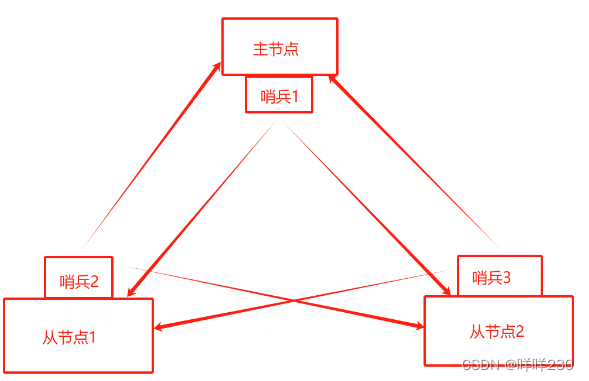
(2)哨兵模式的结构
①哨兵节点:监控主、从节点,不存储数据
②数据节点:主节点和从节点,都是数据节点
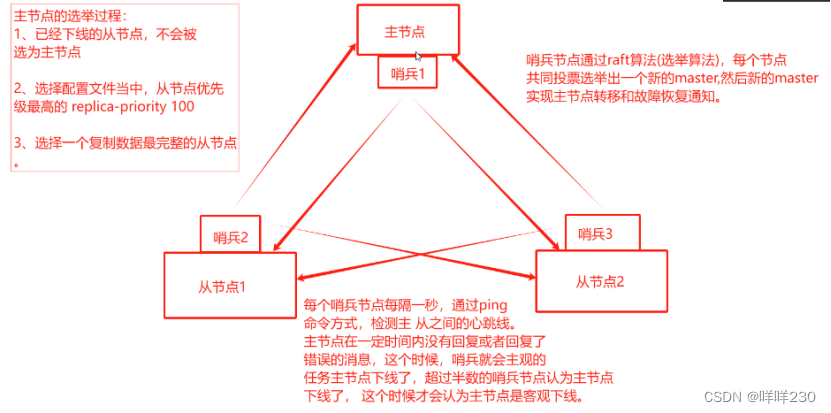
(哨兵1监控从1,从2节点;哨兵2监控主节点,从2 节点;哨兵3监控主节点,从1节点)
(2)哨兵模式工作原理
每个哨兵节点每隔一秒,通过ping命令方式,检测主、从之间的心跳线,主节点在一定时间内没有回复或回复了错误消息,这个时候哨兵会主观认为主节点下线了;超过半数的哨兵节点认为主节点下线了,这个时候才会认为主节点是客观下线
故障恢复可能会有延迟,因为有一个选举过程
(4)如何选举新的主节点
哨兵节点通过raft算法(选举算法),每个节点共同投票选举出一个新的master,然后新的master实现主节点的转移和故障恢复通知
(5)主节点的选举过程
①已下线的从节点不会被选为主节点
②选择配置文件中从节点优先级最高的replica-priority 100
③自动选择一个复制数据最完整的从节点
 三、主从复制+哨兵模式实验
三、主从复制+哨兵模式实验
基于主从复制做哨兵模式实验
实验目的:解决redis单节点故障问题
实验条件:
| IP地址 | 作用 | 组件 |
| 20.0.0.14 | 主服务器 | redis服务 |
| 20.0.0.24 | 从服务器1 | redis服务 |
| 20.0.0.34 | 从服务器2 | redis服务 |
实验步骤:
1、主从复制实验
(1)配置主服务器
(2)配置从服务器
从1

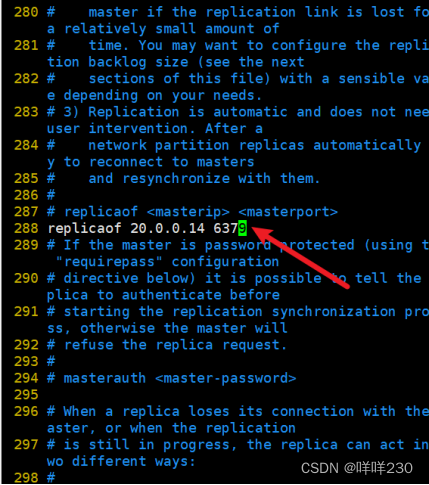
从2
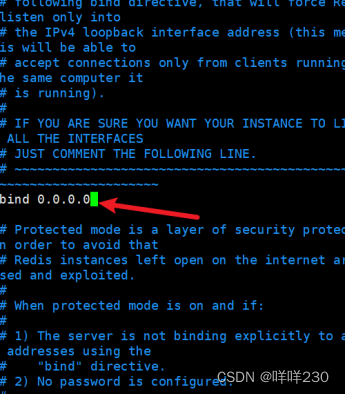
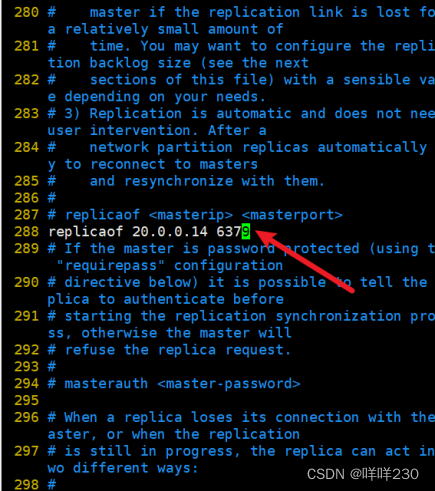
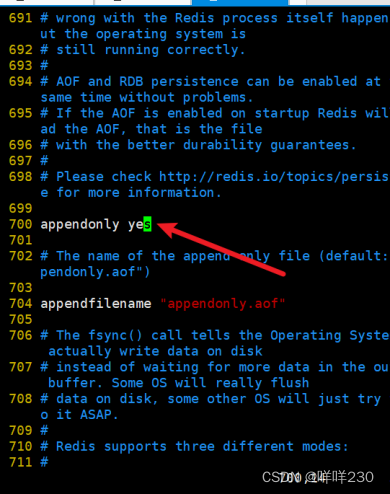
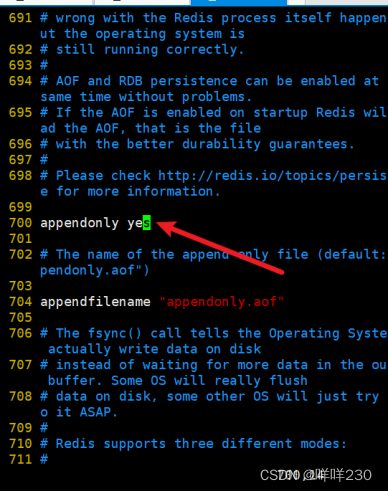
replicaof 20.0.0.14 6379表示只读(20.0.0.14是主服务器的IP地址)
主从复制完成
(3)测试
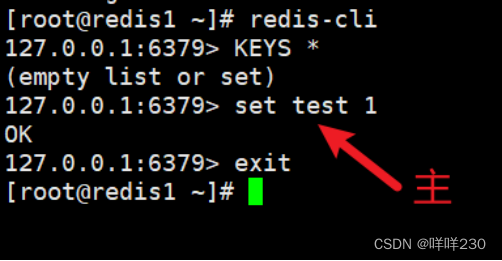
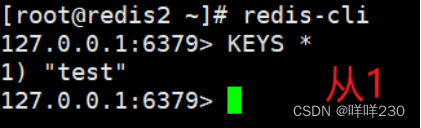
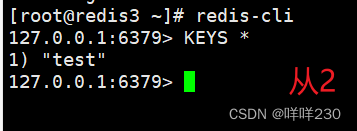
2、哨兵模式实验

(1)配置主服务器
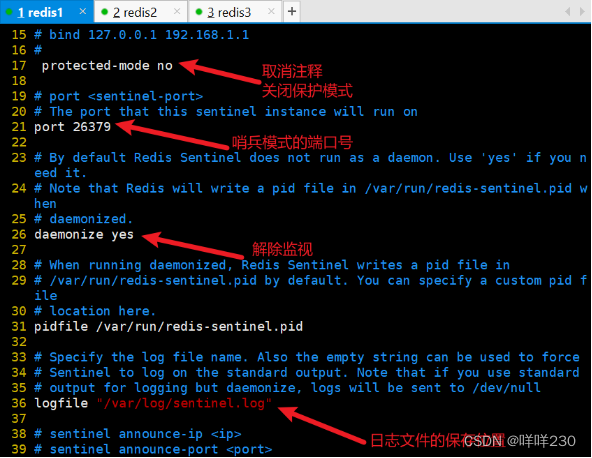
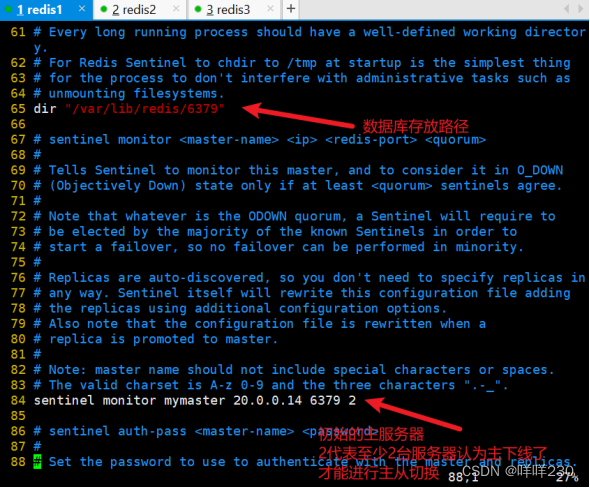
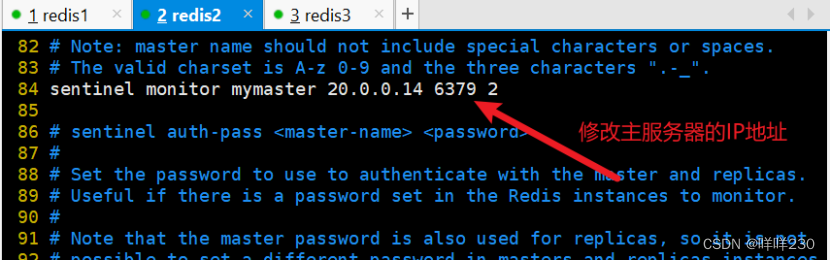
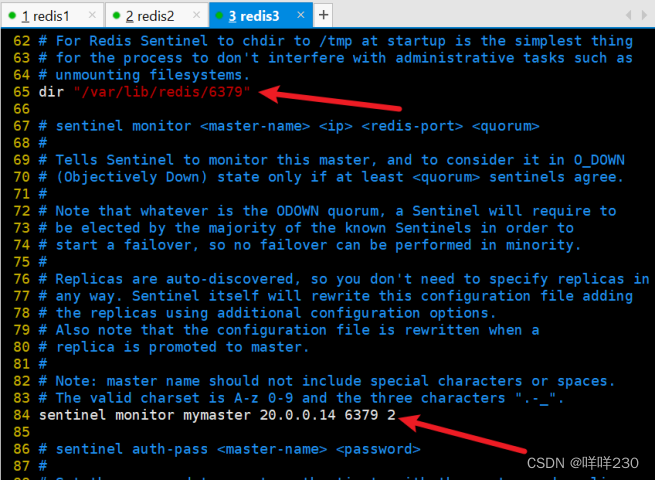
这个2:一般设置成集群的一半

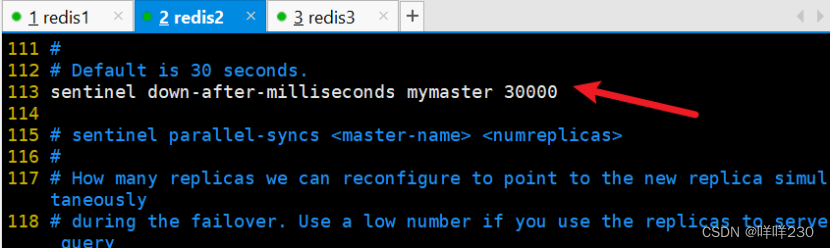
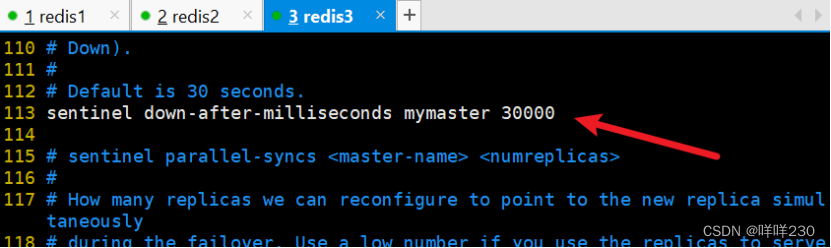
最小切换时间30秒
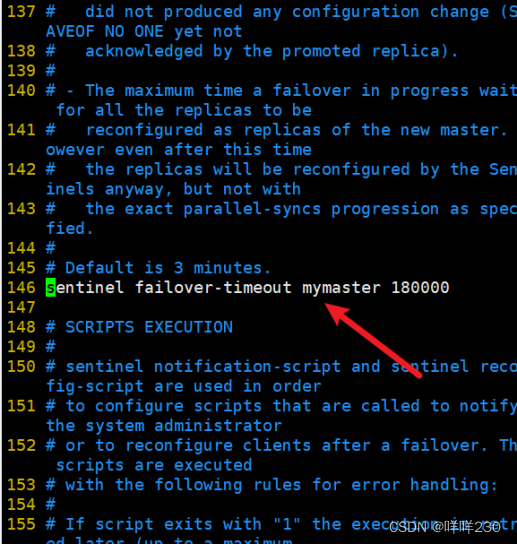
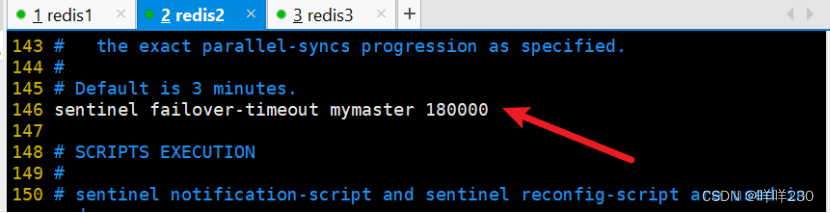
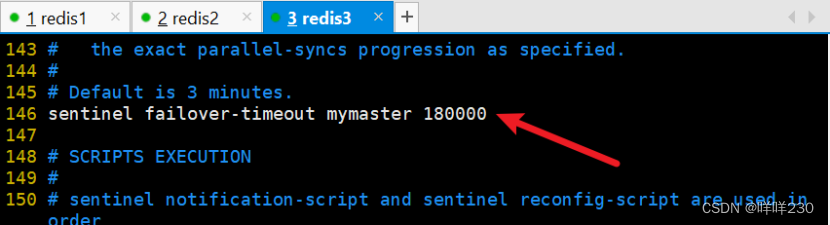
最大切换时间180秒
(2)配置从服务器
从1
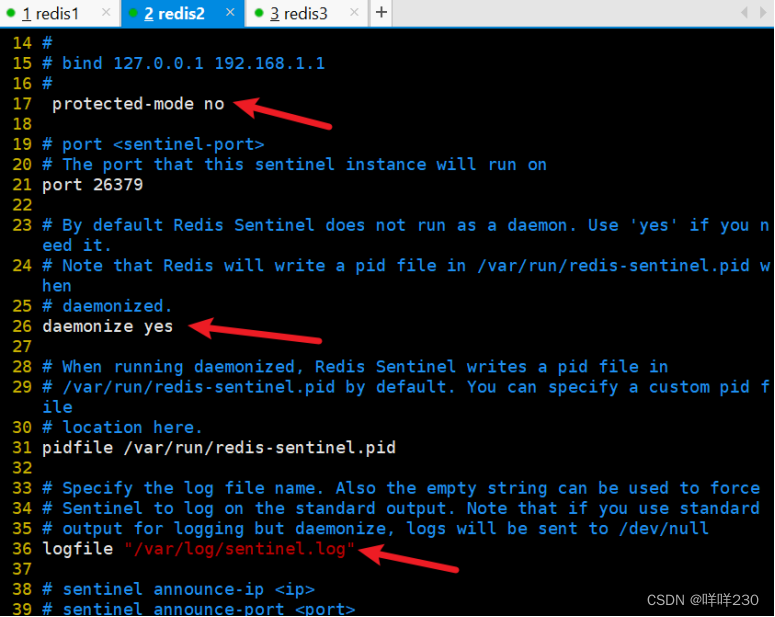
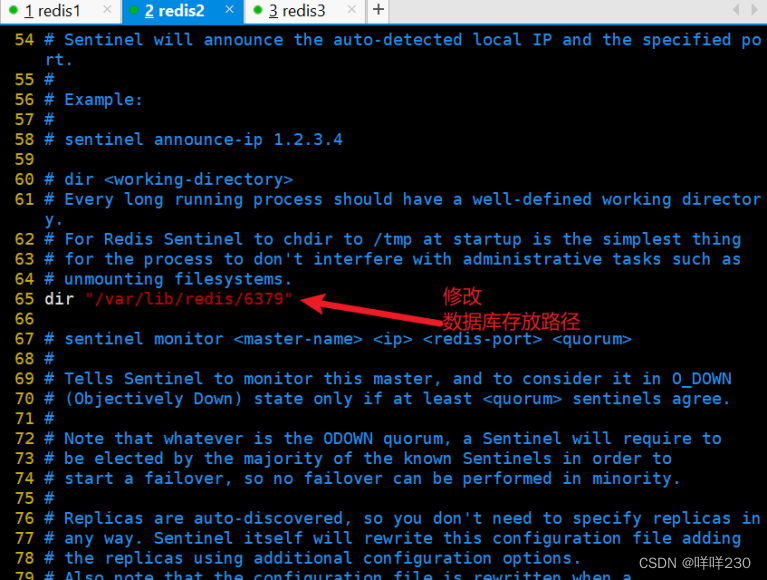
从2(与从1同样的配置)
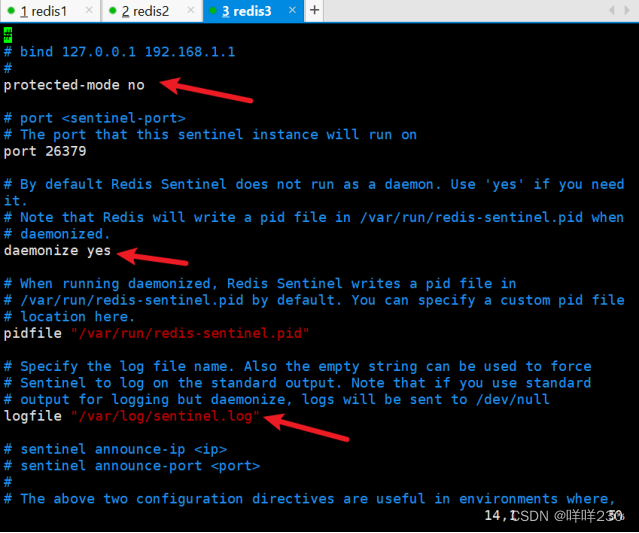
(3)启动主从服务器(先启动主再启动从)
redis-sentinel sentinel.conf &



监控哨兵集群的信息redis-cli -p 26379 info Sentinel
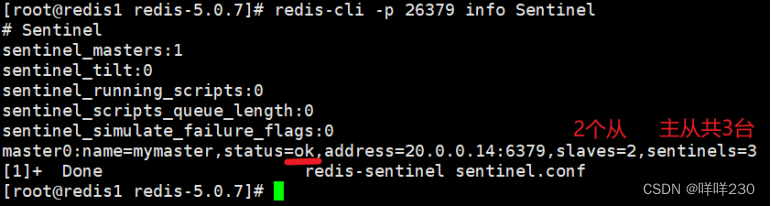
哨兵模式搭建完毕
查看从节点信息tail -f /var/log/sentinel.log


(4)故障切换
模拟故障

看日志是否主从切换,有延迟
tail -f /var/log/sentinel.log
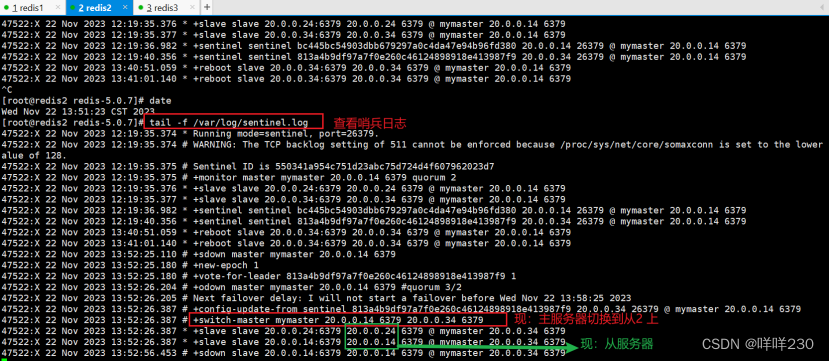
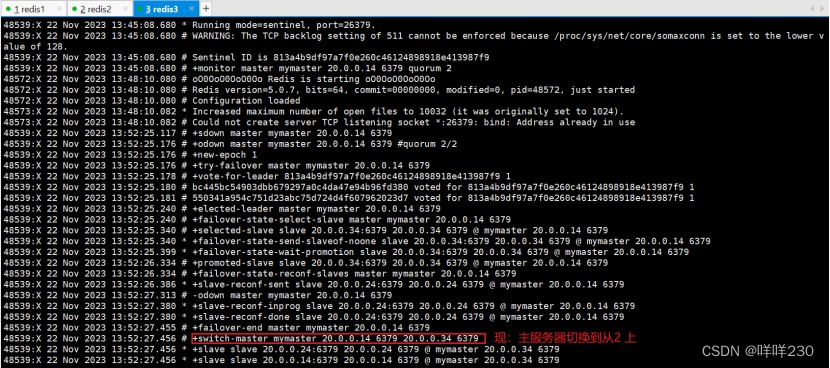
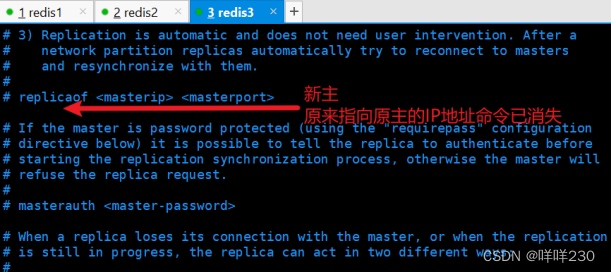
目前,新主的IP地址是20.0.0.34
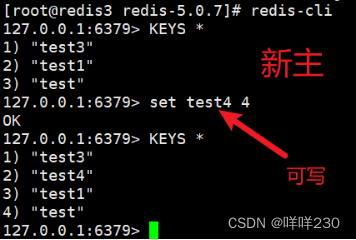
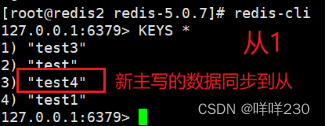
(5)测试
①测试新主能不能写
能
恢复原主

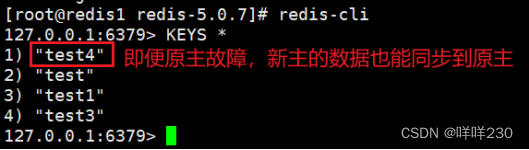
②测试原主能否继续写
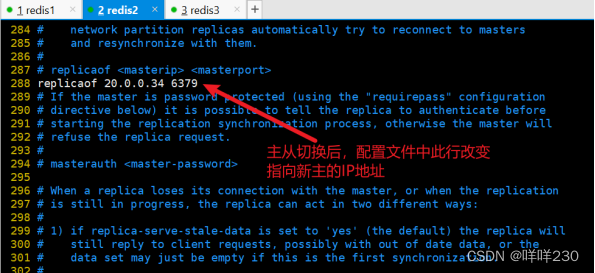
不能

原因:配置文件/etc/redis/6379.conf发生变化
原主(现从2)

从1
原从2(新主)














 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









