






每日一个小问题:当你想要在一个序列中寻找一个大于等于k的数,一个大于k的数,你该怎么办呢?
答:这时就可以使用查找算法了,查找算法是可以寻找这个数是否存在,一个大于等于它的数的下标,第一个大于它的数的下标。
在此之前我们先来学习一下查找算法吧!
1.binary_search的介绍与头文件
顺序查找
这节课我们来学习查找算法,查找就是在给定数据中找到目标数据。
比如给一个数组,找到其中等于 x 的数,大于 x 的数,小于 x 的数,大于等于 x 并且小于等于 y 的数的数量、位置等,都是查找算法可以解决的问题。
最简单的查找算法就是直接用for循环扫描一遍数组,看每一个数,找到想要的数,或者统计想要的结果。
比如找有多少个数等于 x 就可以写成:

找到第一个等于 x 的位置就可以写成:

二分查找
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。
先从一个例子感受下二分这种思想的魅力:
乙在心中想了一个在 [1,1000] 范围内的整数,她考验甲能否在 10 次机会内猜出来。甲每次会猜一个数,并且能够得到乙的三个回复:太小了、太大了,猜中了。
那么采用二分的思想,甲第一个猜的数会是 500,他会根据乙的回复进行第二次猜数:
猜中了,游戏结束。
太大了,那么说明范围在
1∼499 以内,于是甲下次猜 250。
太小了,那么说明范围在
501∼1000,于是甲下次猜 750。

这样蒜头君每次猜不中的时候都会把范围 缩小一半,而 log
1000<10,因此 10 次以内一定能够猜出来。
二分查找最常见的一类问题是:在一个有序、无重复元素的数组中找出某个关键字。比如现在有一个包含 n 个元素的有序数组,想要在其中找到元素 x。
关键字出现时
下面我们用一个具体例子来说明二分查找算法过程。在这个例子中,我们要从 1,3,5,7,10,12,14中找出关键字 12。
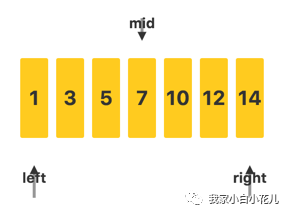
首先,用三个值来标记数组的待查找区间的左端点left、右端点right和中间位置mid。
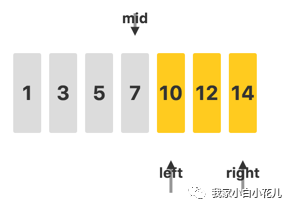
我们发现,中间位置mid指向的值 7<12,因此,要找的元素一定在mid的右边。于是我们将左端点left修改为mid + 1,继续后面的查找过程。

此时,更新mid,发现mid指向的值就是我们要找的 12,二分查找结束。
这里的mid一般取(l + r) / 2。
关键字没出现时
如果关键字并没有在数组中出现,整个查找的过程是怎样的呢?我们还是用上面给出的数据 1,3,5,7,10,12,14作为例子,要在其中查找关键字 11。
和之前一样,先确定三个标记的位置:
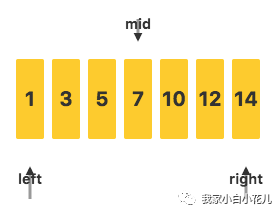
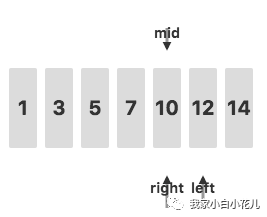
接下来,判断待查关键字 11 和mid指向的值的关系,发现 11>7,去右侧继续查询:

接下来,判断待查关键字 11 和mid指向的值的关系,发现 11<12,去左侧继续查询:
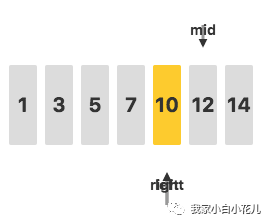
接下来,判断待查关键字 11 和mid指向的值的关系,发现 11>10,去右侧继续查询:
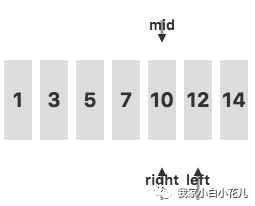
此时,由于left比right更大,说明没有找到关键字 11,查询结束。
在 C++ 中,我们可以很方便地使用 sort 对一个数组进行排序,而不需要写出很长的排序算法的程序。
那么,我们能不能用简单现成的函数来实现对一个数组的二分查找呢?答案是肯定的。
在 C++ 中,我们可以用binary_search对一个数组进行二分查找。不过,在使用binary_search之前,我们应该先引入#include <algorithm>头文件。

和sort的用法比较类似,binary_search一共有三个参数,其中前两个参数表示查找的区间,a和a + 7表示从a[0]到a[6]进行查找。
这点与sort类似,binary_search(a + l, a + r, x)是在a[l]到a[r - 1]中进行查找。
binary_search的最后一个参数表示要查找的元素值。在进行二分查找前,需要保证待查找的部分是从小到大排序的,一般情况下可以先将整个数组 从小到大排序 。数组中有重复元素不影响查找。
函数的返回值为bool类型,当返回true时,表示在数组中找到了这个值,否则表示没找到这个值。
注意,在vector中要用.begin()和.end(),写成binary_search(a.begin(), a.end(), x)或者binary_search(a.begin() + l, a.begin() + r, x)。
2.lower_bound和upper_bound
问:
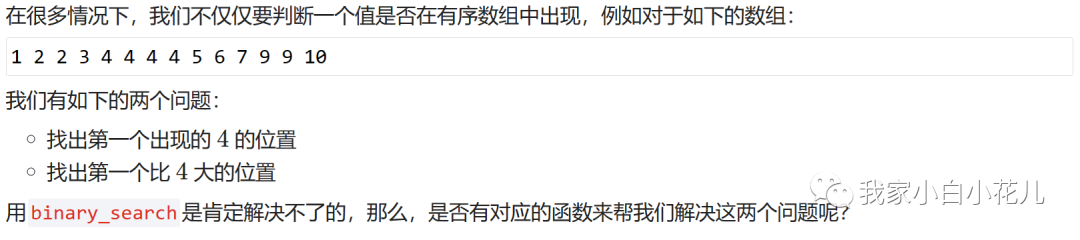
在 C++ 里,还有两个非常好用的函数:lower_bound和upper_bound,它们也在头文件algorithm里。其中,lower_bound返回第一个大于等于要查找的元素值的位置,upper_bound返回第一个大于要查找的元素值的位置。它的参数和binary_search类似,也是三个,首位置,尾位置和要查找的元素,不过返回值是找到的相应元素的位置。
lower_bound意思是“下界”,在这里是说这个数出现的位置最靠前也就是这个位置了,也就是第一个大于等于这个数的位置。
upper_bound意思是“上界”,在这里是说这个数出现的位置不能在这个位置及以后了,也就是第一个大于这个数的位置。
这两个函数也要求数组是从小到大排序的。

因为返回值是位置,所以想要得到数组下标需要减掉数组首位置,所以upper_bound(a, a + 14, 4) - a的值为 8,也就是会找到上面数组中的第一个 5;而lower_bound(a, a + 14, 4) - a的值为 4,也就是会找到上面数组中的第一个 4。
如果没有找到,返回的位置为查找区间的尾位置,比如这里就是a + 14这个位置。这种情况在实际使用的时候可能需要特判。
在vector中要相应使用.begin()和.end(),比如lower_bound(a.begin(), a.end(), x) - a.begin()。
我们观察:

那么 upper_bound(a.begin(), a.end(), 4) - lower_bound(a.begin(), a.end(), 4) 的结果为数组中 4 出现的次数。
如果将 4 换为 x,就可以计算出数组中 x 的出现次数。
3.每日小问题解
可以使用二分查找:

结果:















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









