






首先
我们来思考一个问题——如何将概率论、编程和AI联系起来呢?或者说三者之间有什么关系?
我们可以通过chatGPT直观感受到它们三者的关系。首先我们要明确,当我们对chatGPT下达指令后,不管是画一只小猪或者写一段代码,chatGPT给我们的答案并不是直接从网络上截来在缝缝补补拼成的,而是一个个像素或是一个个字母自己码出来的,完完全全是自己“想”出的。那又是如何“想”出这些答案的呢?它首先会在互联网上进行大量的数据学习,摸索出字与字之间的关联。然后进行思考,比如说你问它“黑龙江省的省会是哪里?”它的思考过程大概如下:
-
与“黑龙江省的省会是”关联度最大的字是哈;
-
与“黑龙江省的省会是哈”有关联度的字包括“尔”(89%),“哈”(20%),“好”(10%)等等,那么取正确概率最大的字——“尔”;
-
与“黑龙江省的省会是哈尔”有关联度的字包括“滨”(90%),哈”(20%),“好”(10%)等等,那么取正确概率最大的字——“滨”;
-
...
最后,它给我们一条回答“黑龙江省的省会是哈尔滨。”
图1.与chatGPT一起“摸鱼”的日常(手动滑稽)
由此可见,chatGPT是通过计算下个字与之前部分的关联度与准确率,来输出每一条答案,也就是通过算“概率”实现了智能,而如何在大量数据中,算得我们想得知的概率,就需要通过编程与各种算法实现。这便解释了我们提出的提一个问题。
实现途径大致分为两条——“神经网络”与“机器学习”
IDEA 1 神经网络
这个灵感来自于生物的神经系统,尤其是大脑神经元的链接与交互。1943年,Warren McCulloch和Walter Pitts发表了一篇名为《神经活动中的逻辑计算》的论文,首次提出了用数学模型来描述神经元的概念。这个模型被称为“麦卡洛克—皮茨神经元”,为后来的神经网络研究奠定了基础。而后的感知机(Perceptron)模型、反向传播(Backpropagation)算法为深度学习领域奠定了基础。
大多神经网络实现原理是通过构建由多个层次组成的网络结构来处理数据,这些层次包括输入层、隐藏层和输出层等。每层的基本单位是神经元,每个神经元接收来自前一层神经元的输入,通过权重加权累加起来(通常还会加上一个偏置项)。累加的结果通过激活函数处理,以此决定神经元的输出。最后通过损失函数评估网络输出与实际期望输出之间的差距。
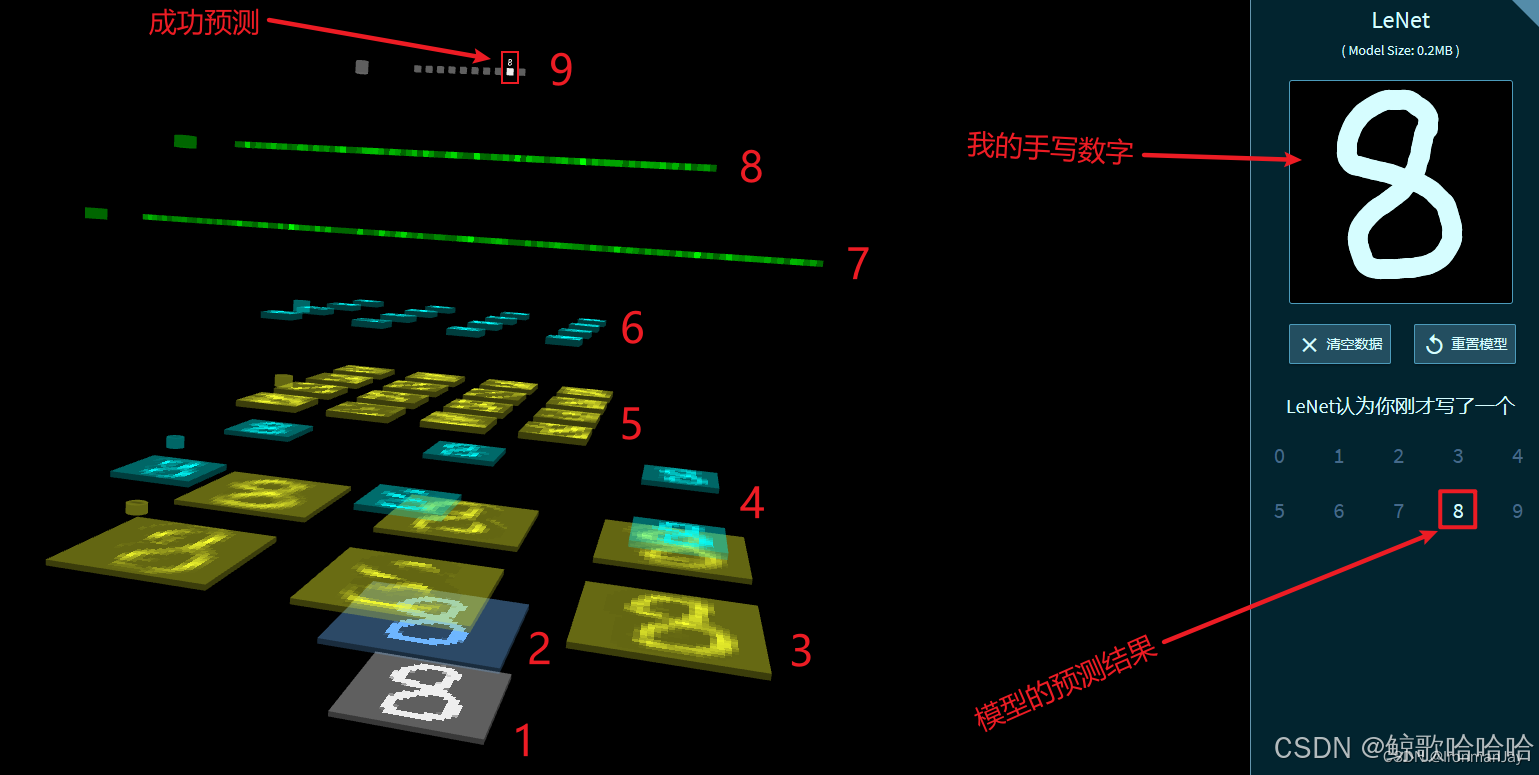
图2.利用卷积神经网络实现手写数字识别
IDEA 2 机器学习
1956年达特茅斯会议标志着人工智能作为一个独立研究领域的诞生。第一次AI冬天结束后,研究者将统计理论应用到机器学习上,发展出支持向量机(SVM)、随机森林等新的算法。2006年,Hinton等人提出的深度信念网络,引发了深度学习的热潮。此后,深度学习在图像识别、语音识别、自然语言处理等领域取得了重大突破。
机器学习算法依赖数据。数据集一般分为训练集、验证集和测试集。主要原理是在数据集中进行特征提取,建立模型,并通过适合的学习算法调整模型参数,达到最优解。
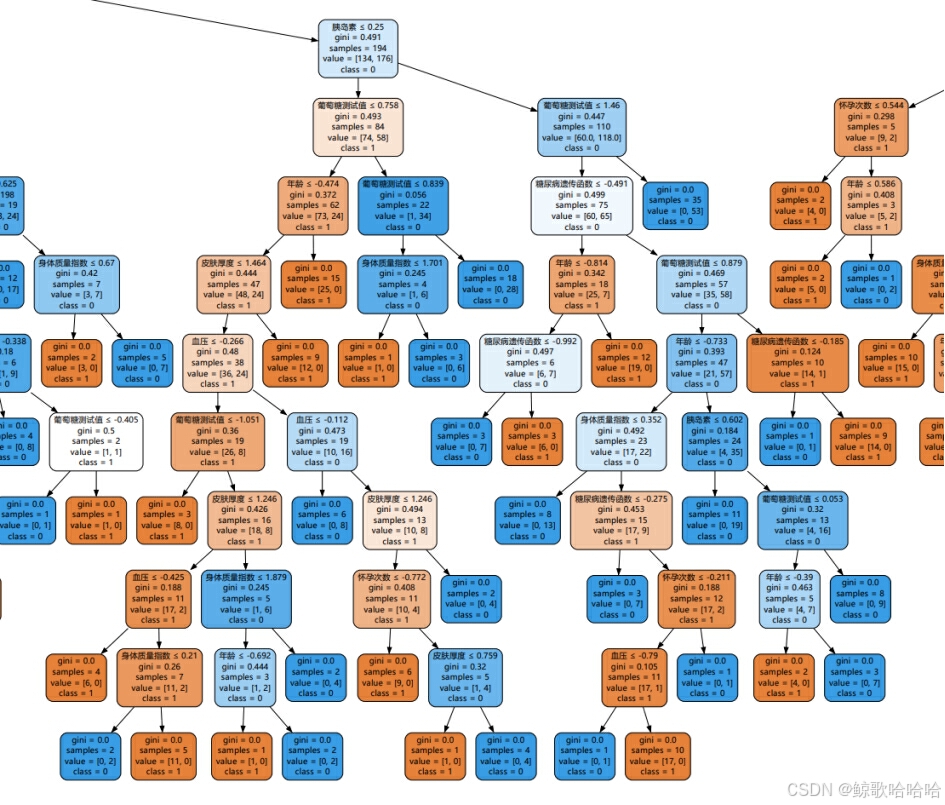
图3.利用随机森林算法实现糖尿病预测(此图为局部的随机森林决策树)
最后
以此图作为绪论的总结,提醒我们要重视基础。
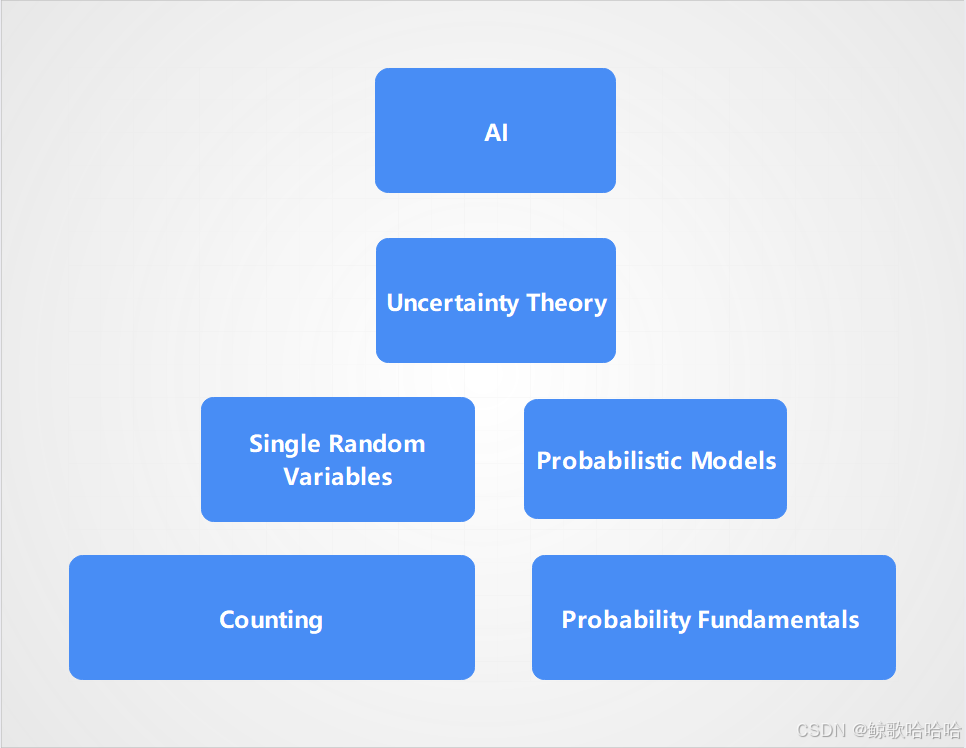
图4.基础金字塔(复刻了老师PPT上的图片)
引用声明
图2来源CSDN 《卷积神经网络(CNN)详细介绍及其原理详解》 一文
原文作者及链接如下卡片所示IronmanJay https://blog.csdn.net/IronmanJay
https://blog.csdn.net/IronmanJay


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









