







本章将系统讲解Go语言基础数据类型的核心知识体系。编程基础的重要构成,我们将重点剖析以下内容:
- 数据类型详解:深入解析数值型(整型/浮点型)、布尔型、字符型等基础类型的特性与使用规范
- 底层原理图解:通过内存结构示意图,直观展示各类型在计算机中的存储方式及运算机制
- 可视化教学特色:采用"一图胜千言"的讲解方式,每个核心知识点均配有对应的原理示意图和代码示例
- 拓展认知维度:在讲解语法规范的同时,延伸解析数据类型与计算机体系结构的关联性
注:变量与常量作为数据载体,本章将简要概述其基本概念,重点聚焦于类型本身的特性解析。通过本单元的学习,读者不仅能掌握Go语言的数据类型使用规范,更能建立起从代码到内存的立体认知框架
(如果感觉作者写的还不错,不妨点一个免费的关注和赞捏,我把语雀的原文展示出来,让大家更方便的观看go语言的基本数据类型)
一.变量和常量
1.1 变量
变量顾名思义就是一个可以改变的值,常见的变量类型有:整型,浮点型,布尔类型。
Go语言中的每一个变量都有自己的类型,必须经过声明才可以被使用。
回顾一下常见的声明方式
var 变量名 变量类型
eg:
var name string
var age int
var ok boolvar (
name string
age int
ok bool
)package main
import "fmt"
//全局变量
var global = 100
func main() {
// 简短声明
n := 10
fmt.Println(n)
}
package main
import "fmt"
func foo() (int,int){
return 10,10
}
func main() {
a,_:= foo()
_,b := foo()
fmt.Println(a)
fmt.Println(b)
}注意:
- 对于简短声明,他是不可以在函数之外这样声明的
- ‘’_‘’多用于占位,表示忽略值
- 匿名变量不占用命名空间,并且不会被分配内存
1.2 常量
相对于变量,常量则是一成不变的值,只不过把var换成了const
常量的声明方式和变量基本一致,除了没有匿名常量之外。
在常量中涉及一个常量计数器(iota)看下它的使用吧
package main
import "fmt"
const (
a1 = iota
a2
a3
a4
)
func main() {
fmt.Println("a1=", a1)
fmt.Println("a2=", a2)
fmt.Println("a3=", a3)
fmt.Println("a4=", a4)
}对于iota就会涉及一系列的问题3.有关数据类型的题目
二.数值类型
数值类型涉及int,float32和float64等等
2.1 整型
整型主要分为两大类型,按照长度分为int8,int16,int32,int64,对应无符号位的uint8,uint16,uint32,uint64。
其中uint8就是我们熟知的 byte 类型,int16对应C语言的 short 类型,int64对应 long 类型,还有int32表示 rune 类型
看一下它的范围:
- 有符号整数类型:
-
int: 平台相关的有符号整数,大小与uint相同。int8: 8 位有符号整数,范围是-128到127。int16: 16 位有符号整数,范围是-32768到32767。int32: 32 位有符号整数,范围是-2147483648到2147483647。int64: 64 位有符号整数,范围是-9223372036854775808到9223372036854775807。
- 无符号整数类型:
-
uint8: 8 位无符号整数,范围是0到255。uint16: 16 位无符号整数,范围是0到65535。uint32: 32 位无符号整数,范围是0到4294967295。uint64: 64 位无符号整数,范围是0到18446744073709551615。
当一个 uint 变量的值超过它所能表示的最大值时,就会发生溢出。
- 它的大小取决于操作系统的位数:
- 在 32 位系统上,
uint通常为 32 位(4 字节)。 - 在 64 位系统上,
uint通常为 64 位(8 字节)。
- 范围:
- 32 位系统:
0到2^32 - 1(即0到4294967295)。 - 64 位系统:
0到2^64 - 1(即0到18446744073709551615)。
说一下溢出原理:
- 范围:
uint类型的范围取决于系统的位数。在 32 位系统上,uint的范围是0到2^32 - 1(即0到4294967295);在 64 位系统上,范围是0到2^64 - 1(即0到18446744073709551615)。 - 溢出: 当你尝试将一个
uint变量赋值为超出其最大值的数时,变量会回绕到 0。例如,如果你在 8 位的uint上加 1,结果会变成 0。
换句话说他最大大小只有255,但是你让他+1,就会超出他的范围,这个时候就被称为是uint的溢出
package main
import (
"fmt"
)
func main() {
var x uint8 = 255 // uint8 的最大值是 255
x++
fmt.Println(x) // 输出 0,因为发生了溢出
是取余输出。
}2.2 浮点型
go语言主要支持两种浮点型:float32和 float64
也可以通过常量定义。
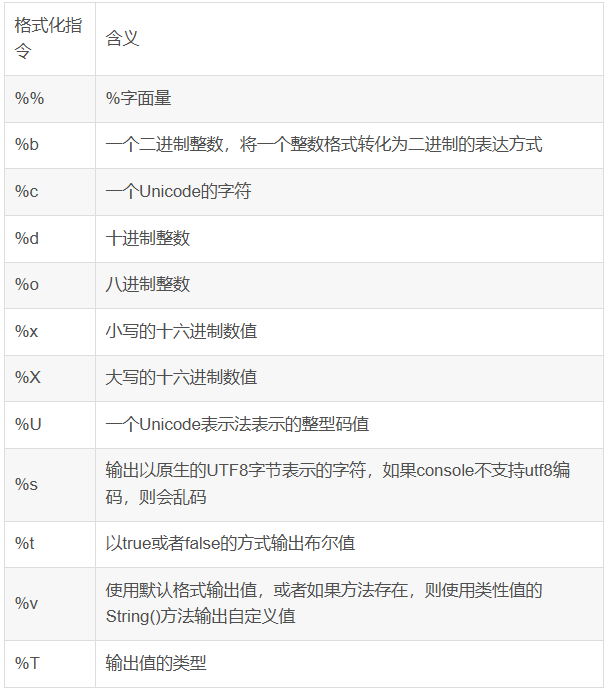
打印的是和可以结合格式化命令来打印,%f
package main
import "fmt"
func main() {
var a = 3.1415926
fmt.Printf("%f",a)
}看一下常见的格式:
2.3 复数
复数类型也有 complex64 和 complex128 两个类型
复数有实部和虚部,complex64的实部和虚部都为32位,另一个就是64位
package main
import "fmt"
func main() {
var a complex64
a = 1 + 2i
fmt.Println(a)
}注意:
- 这里的 i 前面必须有系数,哪怕是1也要加上
2.4 八进制和十六进制
Go语言里面无法直接定义二进制,但是可以定义八进制和十六进制
package main
import "fmt"
func main() {
var a = 101
fmt.Println(a)
fmt.Printf("%b\n", a) // 转为二进制
fmt.Printf("%o\n", a) // 转为八进制
fmt.Printf("%x\n", a) // 转为十六进制
// 八进制的定义
b := 077
fmt.Printf("%d\n", b)
// 十六进制的定义
c := 0x123
fmt.Printf("%d\n", c)
}三.布尔类型
Go语言中以bool声明布尔类型,布尔类型数据只有true和false两个值
- 布尔类型的默认值位false
- Go语言不允许整型转化为布尔类型
- 布尔类型无法参与值运算
四.字符串
4.1 字符串的概念
Go语言中的字符串是以原生的数据类型出现,和上述的类型都一样。
Go语言里面的字符串实现都是使用的UTF-8编码
- 注意:go语言里面的字符串只能用双引号包裹,单引号是包裹字符
有关字符串的概念,都是老生常谈了,说一下转义字符和常见操作
- 看一下转义字符

- 接着看一下常见的字符串操作
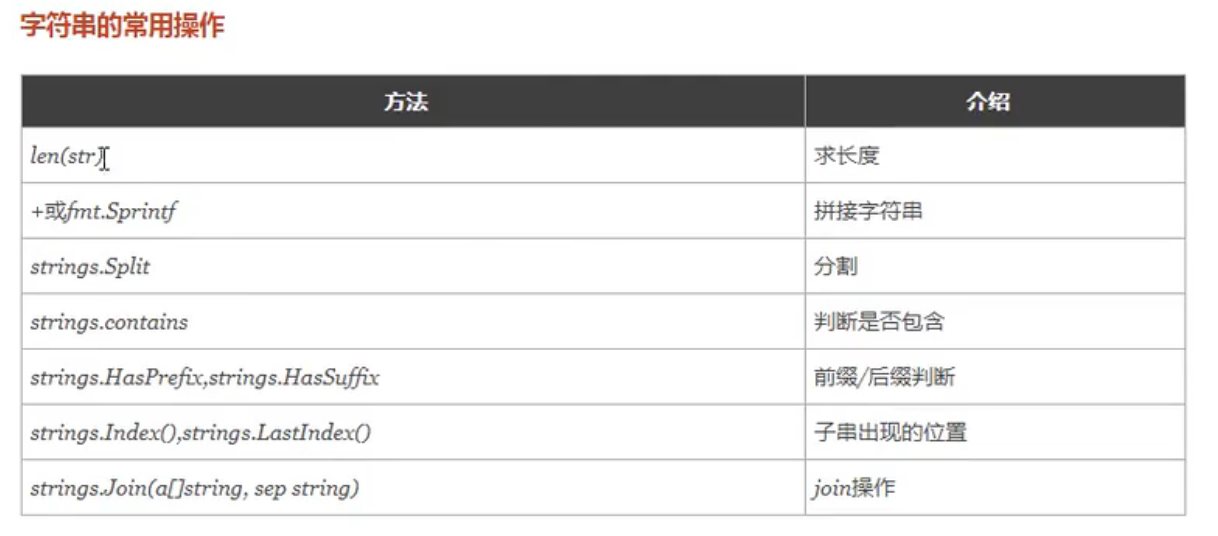
除此之外还有很多比如大小写化,反引号包裹的字符串是怎么样的,等等,这些用的时候查一下即可。
4.2 深入字符串
在文章的开头曾说过byte和rune这两个类型是什么,这就来了,他们两个都是字符。
既然两者都是字符,那他们有什么区别呢?
首先要知道组成每个字符串的元素叫做“字符”,字符使用单引号包裹起来
var a := '中'
var b := 'x'所以他们的区别到底是什么?
这主要涉及字符的编码,在最开始设置英文字母的时候是使用的ASCII,它是uint8类型,也就是byte类型,会发现它里面并没有中文,日文等等其他符合字符,也就是ASCII并没能收购所以的字符。
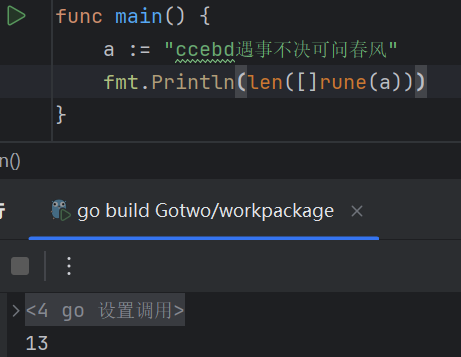
于是乎就出来了Unicode编码,rune类型就是用来表示这个编码,他的大小是三个字节,而不是1个,这里就会出现一个问题,当你用len去测量一个当有汉字的字符串,出来的结果和你想要得到的字符串长度他不一样。
如果你不知道rune占三个字节的话,就会很懵。
如果想要避免这个问题,你就需要把他转化为rune类型,再用len函数,就可以得到他的长度了
那字符串设置好了,它可以修改嘛?
实际上字符串是无法修改的,Go语言里面对字符串只支持读。
原因是字符串底层是由字节数组构成,且不支持直接修改其内容,这样做的目的是为了提高性能和安全性。
但是,我们可以通过转化为切片,从而实现对字符串的一个改变
字符串可以通过类型转换转换为字节切片:
s := "Hello, World!"
bytes := []byte(s)
字节切片也可以通过类型转换转换回字符串:
str2 := string(bytes)通过转化为字节切片,通过下标修改值之后,在转回string,就是实现了字符串的修改
转化的缺点
实际上在字符串和字节数组转化的过程,就是在string变成[]byte的过程,是开辟了一个新空间的,这样是十分浪费内存的。
package main
import "fmt"
func main() {
s := "hello"
b := []byte(s)
// 打印底层数组地址
fmt.Printf("字符串指针: %p\n", &s)
fmt.Printf("字节切片指针: %p\n", &b[0])
}可以通过这一段代码进行一个验证
一般的处理转化,并不会消耗特别大的内存。
看一下两者是如何转化的
- 从
string转换为[]byte:当你将string转换为[]byte时,Go 会 创建一个新的字节切片。由于字符串是不可变的,因此 Go 会将字符串内容的字节值复制到新的字节切片中。这里的每个字符都会被转换为一个字节(或多个字节,对于多字节字符),而不是直接引用原始字符串数据。 - 从
[]byte转换为string:当你将[]byte转换为string时,Go 会 创建一个新的字符串。字符串是不可变的,因此需要复制字节切片的内容到一个新的内存区域,并按 UTF-8 编码解释每个字节,确保它符合字符串的格式。
也就是在转化的过程里面,都需要我们申请一个新的空间才可以实现转化。
补充:字节切片的常见操作
- Go语言的
bytes包提供了许多操作字节切片的便利函数,如bytes.Contains()、bytes.Compare()、bytes.Equal()、bytes.Trim()、bytes.Split()等。 - 这些函数可以用于检查字节切片是否包含某个子切片、比较两个字节切片的大小、判断两个字节切片是否相等、去除字节切片两端的指定字符、将字节切片按指定分隔符分割等。
最后呢看一下字节切片的遍历结果:
可以使用for range 的方法来遍历字节切片
下面案例中,i获取是下标,而b获取的则是ASCII值
%d就是数值,使用%c就可以打印出对应的结果
package main
import "fmt"
func main() {
str := "hello world"
bytes := []byte(str)
for i, b := range bytes {
fmt.Printf("bytes[%d]=%d\n", i, b)
}
}4.3 string的底层结构
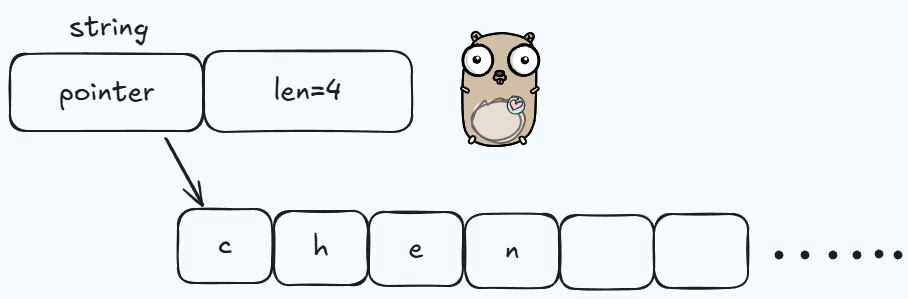
在Go运行时源码(runtime/string.go)中,字符串的实际内存结构为:
type stringStruct struct {
str unsafe.Pointer // 指向底层字节数组的指针
len int // 字符串字节长度
}str指向底层的字节数组,这一块指向的空间是连续的。
为什么存这个len呢?
还记得c语言字符串最后的/0吗,用来分隔两个不同的字符串,没错,这个len的作用也是如此,不仅做到分隔,还记录这个string的字节数。
与切片不同,切片则多了一个cap,因为切片要实现动态扩容机制
type slice struct {
array unsafe.Pointer // 底层数组指针
len int // 当前长度
cap int // 容量
}到这里要涉及一个内存共享的机制:
package main
import (
"unsafe"
)
func main() {
s1 := "abcdefg"
s2 := s1[:3] // 共享底层数组
println(*(*uintptr)(unsafe.Pointer(&s1)))
println(*(*uintptr)(unsafe.Pointer(&s2))) // 输出相同指针值
}
看到结果你会发现,他们俩共用了一个底层切片数组,这是一个浅拷贝,而不是深拷贝。
【【Golang】字符咋存?utf8咋编码?string啥结构?-哔哩哔哩】 【Golang】字符咋存?utf8咋编码?string啥结构?_哔哩哔哩_bilibili
可以看这个视频帮助理解


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









