






一、树结点的定义和二叉树类定义
1.树结点的定义
typedef char DataType
struct TreeNode
{
struct TreeNode* lchild;
struct TreeNode* rchild;
DataType data;
TreeNode() :left(NULL), right(NULL),data(0){}
TreeNode(char a):left(NULL), right(NULL), data(a){}
};lchild:存储左孩子结点地址的指针;
rchild:存储右孩子结点地址的指针;
DataType为树节点中的数据类型;
typedef 关键字用于为已有的数据类型创建一个新的名称,define 也有类似作用
typedef char DataType
#define DataType char 最后两行代码是对新创建的结点进行初始化操作,将左右孩子指针置为NULL,同时给data赋值;
2.二叉树类的定义
#define MaxSize 13
class BTree
{
private:
TreeNode* creat01(TreeNode* root,char a[],int *n);
TreeNode* creat02(TreeNode* root, char a[], int nodeId);
void pre(TreeNode* root);
void in(TreeNode* root);
void post(TreeNode* root);
TreeNode* root;
public:
BTree();
~BTree();
void creatBTree01(char a[])
{
int n = 0;
root = creat01(root,a,&n);
}
void creatBtree02(char a[])
{
root = creat02(root, a, 1);
}
void preOrder()
{
pre(root);
}
void inOrder()
{
in(root);
}
void postOrder()
{
post(root);
}
//
void preVisit();
void inVisit();
void levelVisit();
};1.为什么pre要写在private域内,而preOrder要写在public域内?
a.pre 函数被声明为私有(private),这意味着它只能在类的内部被访问,而不能被类的外部代码直接调用。这样做通常是为了保护类的内部状态和实现细节,防止外部代码直接操作这些私有部分。
b.preOrder 函数被声明为公有(public),这意味着它可以被类的外部代码调用。这是为了提供一个接口,允许外部代码请求执行前序遍历操作,而不需要知道类的内部实现细节。
c.pre 函数是私有的,那么外部代码不能直接调用它来遍历树,而是必须通过 preOrder 函数来请求遍历。这样,如果将来类的内部实现需要改变(例如,改变遍历的顺序或算法),只需要修改 pre 函数的实现,而不需要修改任何外部代码。
总结来说,将 pre 函数声明为私有是为了保护类的内部实现,而将 preOrder 函数声明为公有是为了提供一个清晰的接口给外部代码使用。
2.为什么root要定义在private域中?
a.数据保护:私有成员变量不能被类的外部代码直接访问或修改。这有助于防止外部代码对类的内部状态进行不正确的操作,从而保护数据的一致性和完整性。
b.灵活性和可维护性:如果将来需要改变类的内部实现,私有成员变量的封装可以减少对外部代码的影响。例如,如果需要改变树的存储结构(从链表到数组或其他数据结构),只需要修改私有成员变量的定义和相关的访问函数,而不需要修改外部代码。
3.为什么有了pre,又要有preOrder?
a.root在private域中,而先序遍历函数中的参数要用到root,所以只能对外提供一个preOrder函数接口,在preOrder函数中调用pre函数
b.这种做法可以理解为封装:pre 函数是私有的,这意味着它只能在类的内部被调用。这有助于保护类的内部状态和实现细节,不需要知道类的内部实现细节。如果将来类的内部实现需要改变(例如,改变遍历的顺序或算法),只需要修改 pre 函数的实现,而不需要修改任何外部代码。
c.在实际使用中,外部代码应该只通过 preOrder 函数来请求遍历,而不需要直接调用 pre 函数。这样,如果类的内部实现需要改变,只需要修改 pre 函数的实现,而不需要修改任何外部代码。
二、递归
树的定义是递归的,因为树是由节点组成的,而每个节点又可以是另一个树的根节点。这种定义方式允许我们通过递归的方式来构建和操作树。
递归三部曲:
a.确定递归函数的返回值及参数
b.确定终止条件
c.确定单层递归的逻辑
三、二叉树的三种创建方式
1、手动创建
当二叉树是静态的且节点数量较少,手动创建可能更简单直接。
静态二叉树:当我们说一个二叉树是“静态的”(static),通常是指这个二叉树在创建后其结构不会发生变化。这意味着一旦二叉树被构建,它的节点和它们之间的关系(即父子关系和兄弟关系)将保持不变,直到二叉树被销毁。
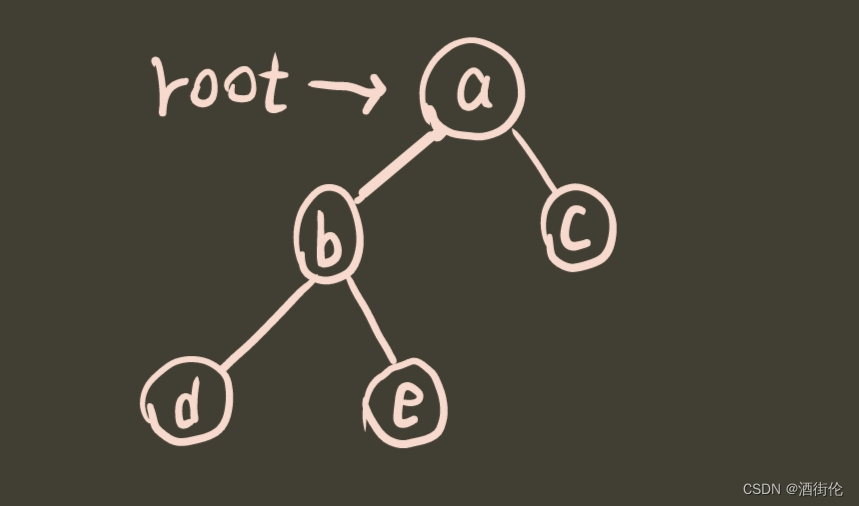
TreeNode* root = new TreeNode(a);
root->left = new TreeNode(b);
root->right = new TreeNode(c);
root->left->left = new TreeNode(d);
root->left->right = new TreeNode(e);创建结果如图:
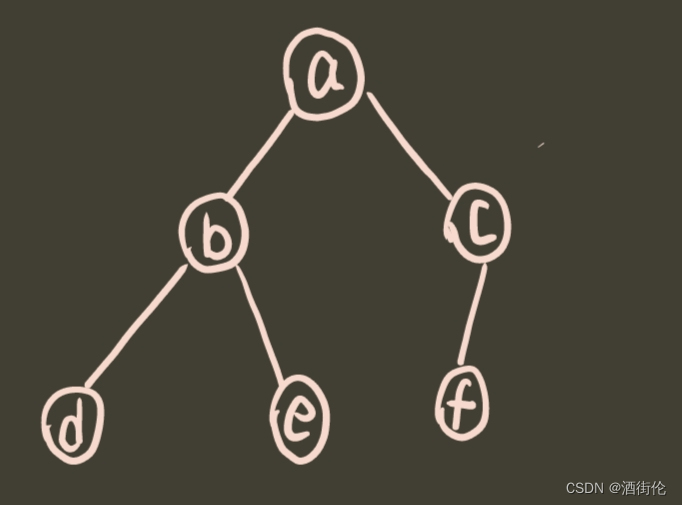
2.根据给定的数组来创建二叉树
给定二叉树:
给定数组的两种顺序:
a.按照树的先序遍历顺序(中序遍历或后序遍历):即 ('-'代表NULL)
char a[13]={'a','b','d','-','-','e','-','-','c','f','-','-','-'};f后面的'-'其实可以省略,因为初始化时已经置空,但是f之前的'-'不能省略
注意:如果按这种顺序,'-'不能省略。(如果省略,创建的结果会不同,但是如果同时有先序遍历和中序遍历数组或者同时有后序遍历和中序遍历数组,'-'可以省略,同时也通过算法可以构建出正确的二叉树)
代码:
TreeNode* BTree::creat(TreeNode* root,char a[],int* n)
{
if (*n >= MaxSize)
return NULL;
if (a[*n] == '-')
{
(*n)++;
return NULL;
}
root = new TreeNode(a[*n]);
(*n)++;
root->lchild = creat(root->lchild, a, n);
root->rchild = creat(root->rchild, a, n);
return root; //当当前的root的左右子树都遍历完后再返回
}算法:主要是递归的思路
1.确定函数返回值和参数: 返回值类型为TreeNode* ,最后返回整棵树的root;
2.判断终止条件:n指a数组当前遍历的位置的下标,当n>=MaxSize时(MaxSize指a数组的大小,可改变),即a数组遍历完,返回NULL;当a[[*n]]='-'时,表示当前树结点为NULL,返回NULL;
3.单层递归逻辑:开辟新结点并且给数据域和指针域赋值;
注意:此处的int* n不能写成int n
1.通过传递指针,你可以修改原始变量的值。在 creat 函数中,我们通过递增指针 n 来更新索引值,这样在函数返回后,原始数组 a 中的索引也会相应地更新。
2.如果我们将 int *n 改为 int n,那么 creat 函数将无法修改原始的 n 值,因为 n 将被视为一个局部变量,其值在函数返回后不会保留。这将导致 creat 函数无法正确地遍历数组 a,因为它无法更新索引。
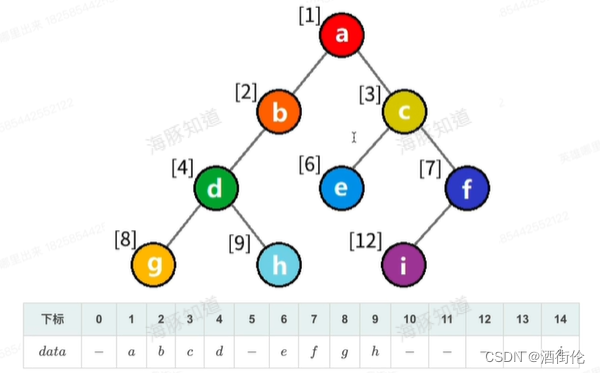
b.按照树的层次遍历顺序:
char a[7]={'-','a','b','c','d','e','f'};注意这种情况(如下图):第五号元素虽然为空,但是为了让第五号元素以后的元素能按照2*n和2*n+1来计算,第五号元素的左右孩子也要置空;
代码:
TreeNode* BTree::creat02(TreeNode* root, char a[], int nodeId)
{
if (nodeId >= MaxSize)
return NULL;
if (a[nodeId] == '-')
return NULL;
TreeNode* newnode = new TreeNode(a[nodeId]);
newnode->lchild = creat02(newnode->lchild, a, nodeId * 2);
newnode->rchild = creat02(newnode->rchild, a, nodeId * 2 + 1);
return newnode;
}算法:主要是递归的思路
1.确定函数返回值和参数: 返回值类型为TreeNode* ,最后返回整棵树的root;
2.判断终止条件:n指a数组当前遍历的位置的下标,当nodeId>=MaxSize时(MaxSize指a数组的大小,可改变),即a数组遍历完,返回NULL;当a[[nodeId]]='-'时,表示当前树结点为NULL,返回NULL;
3.单层递归逻辑:开辟新结点并且给数据域和指针域赋值;
注意:根结点为nodeId,则其左结点为nodeId*2,其右结点为nodeId*2+1;
其实还可以按照中序遍历或者后序遍历来创建二叉树,但是一般情况下并没有必要.
1.中序遍历:将数组中间的结点看做根节点,左边看成左子树,右边看成右子树,以此递归构建,比较麻烦;
2.后序遍历:按照先序遍历顺序倒过来看;
3.从键盘输入值来创建
从键盘依次输入(这里是按照先序遍历的顺序输入),输入顺序为:'a','b','d','-','-','e','-','-','c','f','-','-','-',即可得到2中的二叉树;(f后面的'-'其实可以省略,因为初始化时已经置空,但是f之前的'-'不能省略)
代码:
private:
TreeNode* root;
TreeNode* creat(TreeNode** root);
void pre(TreeNode* root);
void in(TreeNode* root);
public:
void creatTree()
{
cout << "请输入根节点的值" << endl;
root = creat(&root);
}TreeNode* Tree::creat(TreeNode** root)
{
char a;
cin >> a;
if (a == '-')
return NULL;
*root = new TreeNode(a);
cout << "请输入左孩子的值";
(*root)->lchild = creat(&((*root)->lchild));
cout << "请输入右孩子的值";
(*root)->rchild = creat(&((*root)->rchild));
return *root;
}细节:
a:注意整棵树根结点的创建时机,以及左右孩子结点的创建时机;
b:这里是用函数传参的方法来给每一个结点赋值,同上述的int *n一样,要传二级指针;
四、二叉树的遍历(前序、中序、后序和层次遍历)
二叉树的前中后序遍历若采用递归算法比较简单,代码也比较简洁;
1.二叉树的前中后序遍历(采用递归算法来实现)
代码:
class Tree
{
private:
TreeNode* root;
void pre(TreeNode* root);
void in(TreeNode* root);
void post(TreeNode* root);
public:
void preorder()
{
pre(root);
}
void inorder()
{
in(root);
}
void postorder()
{
post(root);
}
};void Tree::pre(TreeNode* root)
{
if (root)
{
cout << root->data;
pre(root->lchild);
pre(root->rchild);
}
}
void Tree::in(TreeNode* root)
{
if (root)
{
in(root->lchild);
cout << root->data;
in(root->rchild);
}
}
void Tree::post(TreeNode* root)
{
if(root)
{
post(root->lchild);
post(root->rchild);
cout<<root->data;
}
}2.二叉树的层次遍历(采用队列的结构来实现)
代码:
void BTree::levelVisit()
{
if (root == NULL)
return;
queue<TreeNode*> queue;
queue.push(root);
while (!queue.empty())
{
TreeNode* cur = queue.front();
queue.pop();
cout << cur->data;
if (cur->lchild)
queue.push(cur->lchild);
if (cur->rchild)
queue.push(cur->rchild);
}
}二叉树的前中后序遍历还可以采用非递归的方式来实现,运用栈的结构实现
3.二叉树的前中后序遍历(非递归实现)
代码:
void BTree::preVisit() //非递归前序遍历
{
if (root == NULL)
return;
TreeNode** stack = new TreeNode*[MaxSize];
int top = 0;
stack[top++] = root;
while (top != 0)
{
// 弹出栈顶元素
TreeNode* current = stack[--top];
// 访问当前节点
cout << current->data;
// 先右后左,保证左子树先遍历
if (current->rchild) {
stack[top++] = current->rchild;
}
if (current->lchild) {
stack[top++] = current->lchild;
}
}
}
void BTree::inVisit() //非递归中序遍历
{
TreeNode** stack = new TreeNode * [MaxSize];
int top = 0;
TreeNode* cur = root;
while (cur || top)
{
if (cur)
{
stack[top++] = cur;
cur = cur->lchild;
}
else
{
cur = stack[--top];
cout << cur->data;
cur = cur->rchild;
}
}
}
void postVisit(BTree&tree) //非递归后序遍历
{
int n = MaxSize;
char arr[MaxSize];
int p = 0;
if (tree.root == NULL)
return;
TreeNode** stack = new TreeNode * [MaxSize];
int top = 0;
stack[top++] = tree.root;
while (top != 0)
{
// 弹出栈顶元素
TreeNode* current = stack[--top];
arr[p++] = current->data;
if (current->lchild) {
stack[top++] = current->lchild;
}
if (current->rchild) {
stack[top++] = current->rchild;
}
}
for (n = p-1; n>=0; n--)
{
cout << arr[n];
}
}














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









