






目录
LambdaUpdateWrapper和UpdateWrapper
前两天在练习一个项目的时候,发现项目里面使用的是MybatisPlus,但是我一直用的是Mybatis,所以去学了一下MybatisPlus,因此出一个教程来供初学者快速上手MybatisPlus(后续就称他为MP)
MyBatisPlus简介
首先是MP的官网,下面这两个都是MP的官网
MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
他的特性介绍

依赖引入
如果是基于SpringBoot2开发的项目的话就引入下面这个依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.12</version>
</dependency>如果是基于SpringBoot3开发的项目的话就使用下面这个依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.12</version>
</dependency>注意:一定要根据自己的SpringBoot项目的版本来选择对应的依赖,如果依赖引错了的话是会报错的!!!
前置准备
数据库信息配置
我们还要引入数据库的连接器依赖
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
还有lombok依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>当我们在使用MP前,要先去把数据库相关的详细设置在我们的项目文件里面
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver #对应驱动器的包
url: jdbc:mysql://localhost:3306/MyDatabase? #自己的数据库
username: #用户名
password: #密码MP驼峰命名法
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
# 驼峰命名这个配置是让我们能够开启驼峰命名,在数据库中我们有些字段比如create_time字段,我们在Java对象中的属性是不能携带下划线的,开启驼峰命名的时候在数据插入或者查询等情况的时候能自动映射对应的字段就比如数据库中的create_time字段能映射到对象属性中的createTime上。
数据库表和实体类
数据库表
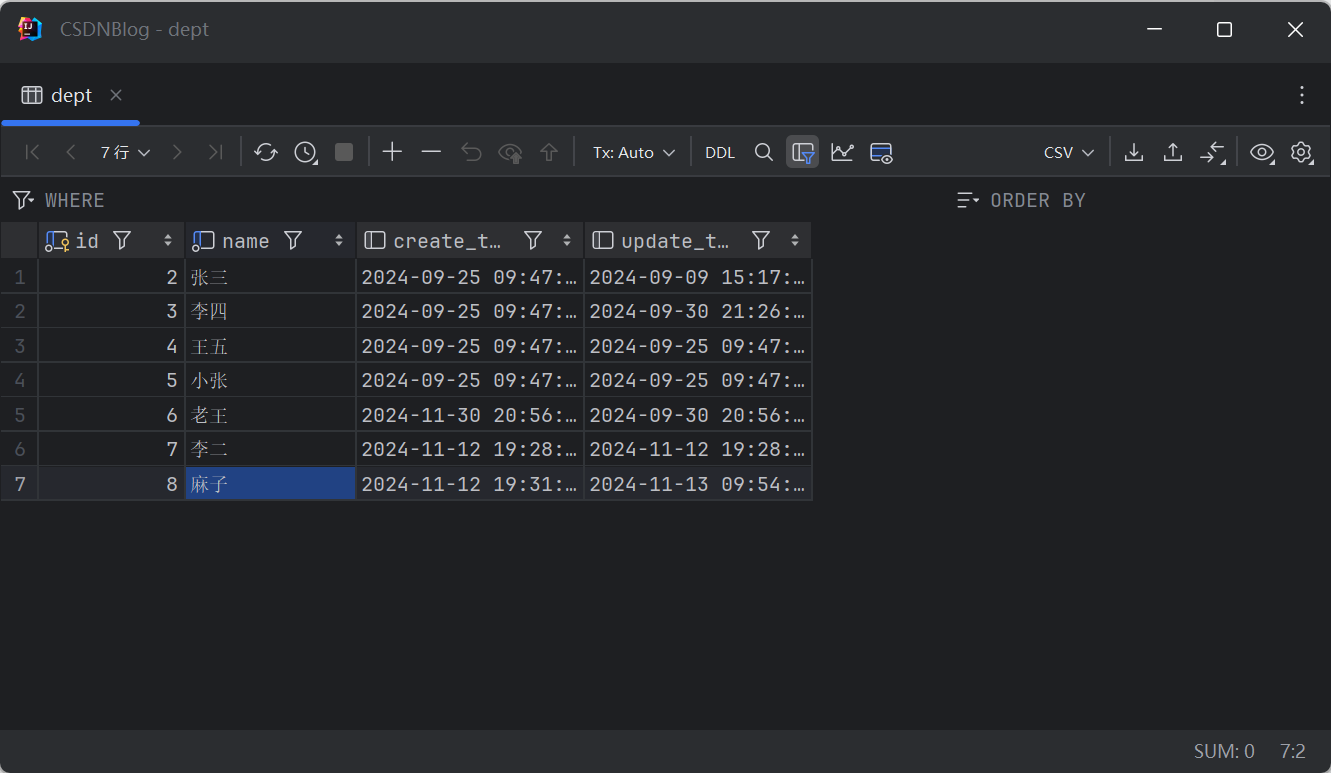
实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Dept {
private Long id;
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
Mapper层相关使用
@Mapper
public interface DeptMapper extends BaseMapper<Dept> {
}跟Mybatis里面一样我们只需要去定义一个Mapper层接口,在接口里面去定义相关方法去实现数据的访问。
但是在MP里面我们对于单表的查询和更新甚至不用定义方法就能使用,因为我们这里继承了BaseMapper接口,他会帮我们封装相关的操作方法去实现对应的功能,而这个接口有一个泛型,这个泛型是指定一个实体类。实际上这个实体类就是我们对于数据库进行查询访问和更新的时候,比如说在Select的时候,接收数据用的Dept,在更新的时候,传递数据也用的Dept,而Dept对象里面跟要操作的数据库表里面的字段一一对应
我们在下面通过依赖注入的方式获取对应的mapper,以此来调用里面对应的方法
selectList查询数据返回List
首先我们先来一个无条件查询,最简单的调用
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
List<Dept> depts = deptMapper.selectList(null);
for (Dept dept : depts) {
System.out.println(dept);
}
}
}这个方法里面我们调用了对应的mapper数据访问层,调用了selectList他时返回查询后的数据的List集合,然而里面null原本是一个queryWrapper条件对象,这个对象是用来设置查询条件的,我们后面再讲。
运行这个结果为
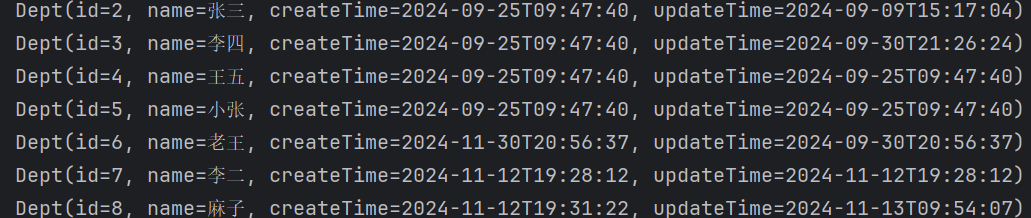
他会把对应数据库dept的数据全部查询出来,封装到一个List集合里面
有些人可能会注意到他为什么会去查询dept这个表,而不去查其他的表?
在MybatisPlus里面我们对数据访问层继承的BaseMapper<>里面的泛型设置对应的实体类之后,他默认要查询的数据库是这个实体类小写之后对应的数据库即这里的dept,我们还可以通过注解的方式来对实体类指定对应的数据库,这个后面会讲。
insert插入操作
我们调用对应的mapper里面的insert来实现数据的插入
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
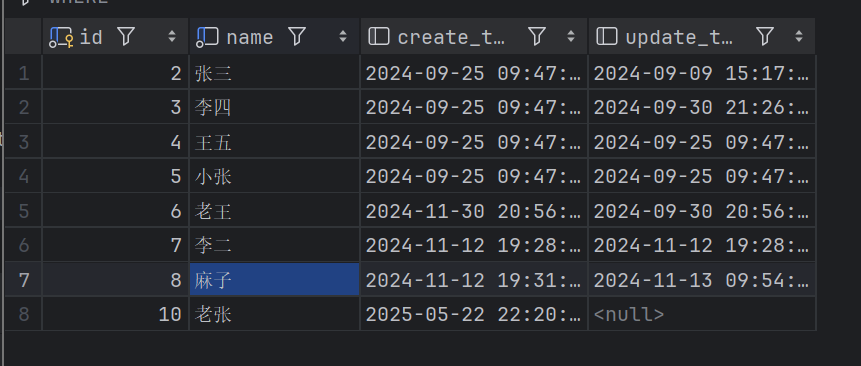
Dept dept = new Dept(10L,"老张", LocalDateTime.now(), null);
deptMapper.insert(dept);
}
}这里可以注意到我们插入的数据是可以为null值的,只要数据库中对对应的字段没有做非空约束的话是能够插入空值的
deleteById根据id删除
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
deptMapper.deleteById(10L);
}
}这个没什么好说的了
updateById根据id更新数据
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
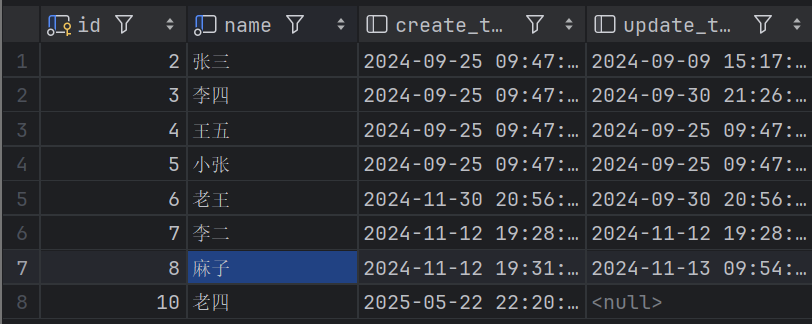
Dept dept = new Dept();
dept.setId(10L);
dept.setName("老四");
deptMapper.updateById(dept);
//其余不修改的字段就不设置值
}
}首先我们创建的实体类实例里面一定要设置对应的id,因为是根据id去做update操作的,然后讲我们要更新的数据设置在这个实体类里面,若其他字段没有要更新的,就不设置值。
selectById根据id查询
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
Dept dept = deptMapper.selectById(10L);
System.out.println(dept);
}
}这个没什么好说的
分页查询
我们在Mybatis里面做条件查询的时候,要基于PageHelper来实现分页查询,而在MP中他自带了分页查询的操作,只是要配置一些东西
在Mybatis里面我们要去new一个PageHelper通过调用startPage方法去设置返回的页数和每页的数量
在MP中,我们要写一个分页查询的拦截器配置类,通过这个拦截器实现分页查询,因为分页查询的本质其实是增加limit操作,而分页查询拦截器的作用就是去帮我们设置limit。
分页查询拦截器设置
我们要去通过配置类返回一个Bean,这个bean是MybatisPlusInterceptor
@Configuration
public class MpConfig {
@Bean
public MybatisPlusInterceptor mpInterceptor() {
//先new一个MybatisPlusInterceptor,这个是 MybatisPlus的总的拦截器,我们要往这个总的拦截器里面加具体的拦截器
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
//添加分页查询的拦截器
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mybatisPlusInterceptor;
}
}首先是new一个MybatisPlusInterceptor拦截器,我们在这个拦截器里面添加具体的拦截器
具体来说的话我们可以源码
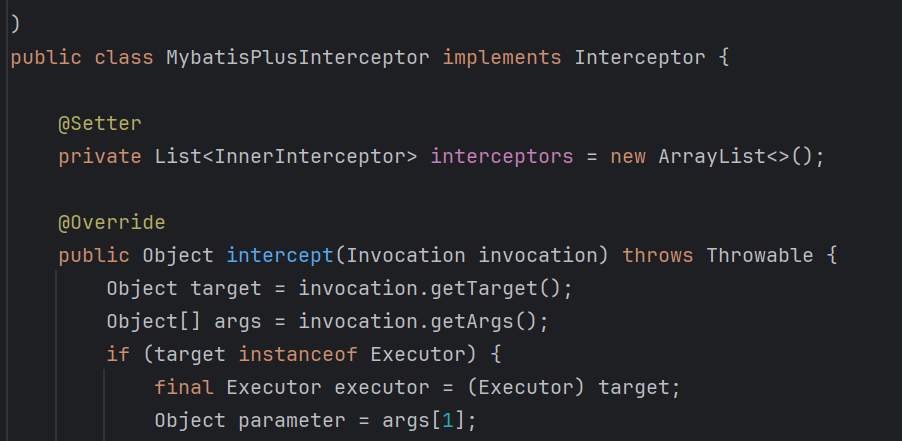
在MybatisPlusInterceptor里面有一个私有属性即interceptors,这个属性是一个列表,这个列表接收的InnerInterceptor类型的对象,
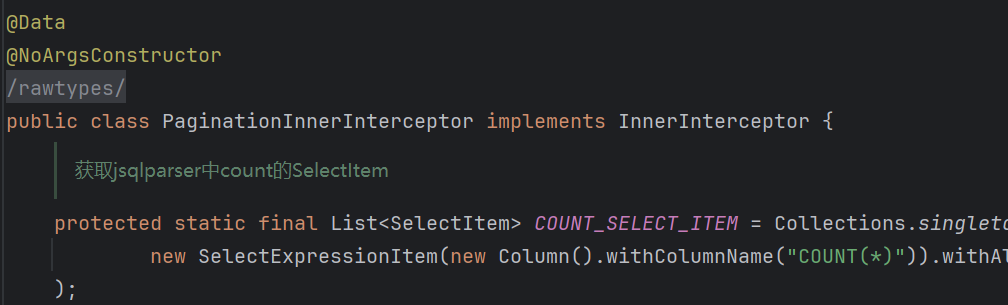
而PaginationInnerInterceptor是实现了InnerInterceptor接口的,所以我们调用addInnerInterceptor就相当于往上面的列表里面增加拦截器
设置Page(即页码数和每页数据量)
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
Page page = new Page(1,2);//添加分页信息,第一个是第几页,第二个是每页返回的数据
deptMapper.selectPage(page,null);
System.out.println("当前页码值:"+page.getCurrent());
System.out.println("每页显示数:"+page.getSize());
System.out.println("一共多少页:"+page.getPages());
System.out.println("一共多少条数据:"+page.getTotal());
System.out.println("返回的查询数据:"+page.getRecords());
}
}然后new一个Page对象,要注意这个类的包,第一个数据是返回的第几页的数据,第二个是每页返回的页数,最后调用selectPage来完成查询
在selectPage里面的第二个参数是QueryWrapper对象来设置查询的条件的,后面讲。
而返回的相关消息是在我们开始定义的page对象里面存着的,所以我们调用里面的方法来拿到数据
Wrapper(条件构造器)
Wraper有很多实现类,我们挑几个出来讲queryWrapper
queryWrapper
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
QueryWrapper queryWrapper = new QueryWrapper();
// QueryWrapper是Wrapper的继承类,是做条件查询的
queryWrapper.gt("id",5L);//第一个指定对应的列,第二个指定对应的数据
List<Dept> list = deptMapper.selectList(queryWrapper);
System.out.println(list);
}
}在实现的QueryWrapper里面方法名对应着我们在sql语句里面写的条件,上面的例子是将dept表中的id大于5的数据输出出来,在selectList里面加入这个条件对象来实现条件查询,注意lt是小于
而小于等于是le,大于等于是ge。
LambdaQueryWrapper
这个对象跟我们在上面做的QueryWrapper的区别在于,当我们做基于某个字段的条件查询的时候,QueryWrapper是通过字符串的形式来设置条件,可能会出错,以此我们就通过LambdaQueryWrapper来实现,LambdaQueryWrapper支持lambda表达式来设置条件查询的值
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
//方式三:lambda格式查询二
LambdaQueryWrapper<Dept> lambdaQueryWrapper = new LambdaQueryWrapper();
//依然要指定泛型,否则下面报错
lambdaQueryWrapper.gt(Dept::getId,5L);
List<Dept> depts = deptMapper.selectList(lambdaQueryWrapper);
System.out.println(depts);
//注意上面的条件可以设置多个,且可支持链式编程
//lambdaQueryWrapper.gt(Dept::getId,5L).lt(Dept::getId,10L);
//上面这个链式之后其实是and关系
}
}在LambdaQueryWrapper指对应的实体类就能在LambdaQueryWrapper中通过lambda表达式设置条件字段,否则检测不到
注意LambdaQueryWrapper支持链式编程,且我们上面例如lambdaQueryWrapper.gt(Dept::getId,5L).lt(Dept::getId,10L);这个是一个and关系
如果我们要将他改成or的关系就要在他们之间添加一个or方法如上图
基于条件查询的空值处理
当我们要对于前端的数据查询,例如我要查询在某个数据范围内的数据,这里设置两个上下限,即我们要查询在上下限里面的数据,如果当前端传递的数据里面没有下限呢?那么我们此时就会默认其是从最小值查询到上限的数据,如果前端传递的下限是一个null,那么我们不做空值处理的话,带入到查询语句里面就查不出数据。所以我们要做空值处理
这里我们设置一个对象假定是前端传递的数据
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DeptQuerycondition extends Dept{
private Long id2;//用于设置id的上限
}
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
DeptQuerycondition deptQuerycondition = new DeptQuerycondition();
deptQuerycondition.setId(2L);
deptQuerycondition.setId2(8L);
// //deptQuerycondition是用来模拟前端传来的查询数据的,一般是会有上下限,根据上下限查询
//若我们不设置控制处理的话,它会把null带入sql查询,就查不出来
LambdaQueryWrapper<Dept> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.gt(null!=deptQuerycondition.getId(),Dept::getId,deptQuerycondition.getId())
.lt(null!=deptQuerycondition.getId2(),Dept::getId,deptQuerycondition.getId2());
//他们都有重载方法,第一个参数是决定是否添加对应的语句,true就加,false就不加
List<Dept> depts = deptMapper.selectList(queryWrapper);
System.out.println(depts);
}
}这里我们查询id大于2小于8的id对应的数据,而在LambdaQueryWrapper里面他们都有重载方法,即第一个参数变成了判断是否要加这个条件,若是true则代表加,反之则不加,所以上面我们通过对应的重载方法来判断是否要加这个值(有点像我们在myatis的xml文件里面写的<if>判断标签)
查询投影(控制查询返回的字段数据)
有时候我们并不想将数据库表中的某些字段返回,比如说密码等等,那么在sql语句里面我们就不会去select *而是手动去控制要输出的字段
在LambdaQueryWrapper中
LambdaQueryWrapper有一个select方法用于控制返回的字段
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
//Lambda格式
//在这里我们将其设置为返回的数据我们只要对应数据的id
LambdaQueryWrapper<Dept> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.select(Dept::getId,Dept::getName);//设置只返回查询结果的id和name
List<Dept> depts = deptMapper.selectList(queryWrapper);
System.out.println(depts);
//发现封装的对象里面除了id有值其余全是null
}
}我们在select方法里面填对应要返回的参数就行了
非lambda格式
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
//非lambda格式
QueryWrapper<Dept> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id","name");//非lambda格式的是填的是字符串
List<Dept> depts = deptMapper.selectList(queryWrapper);
System.out.println(depts);
}
}跟lambda格式差不多
分组和数量查询
当我们的sql语句涉及到了groupby和count的时候这个时候我们就不能去使用LambdaQueryWrapper去查询了,而是要用字符串格式即QueryWrapper
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
//非lambda格式下的使用
//当我们要分组和数量统计即count(*)的时候我们就不能使用lambda格式了
QueryWrapper<Dept> queryWrapper = new QueryWrapper<>();
queryWrapper.select("count(*) as count,name");
//count(*)能单独用,但是搭配着其他字段就是分组了,分组就要调用groupBy方法去分组
queryWrapper.groupBy("name");
//这里就是返回的是基于name分组后的每个组里面的数值及其名字
//当涉及到count和分组的时候我们就不是selectList了,因为它不是Dept对应的List了
List<Map<String, Object>> maps = deptMapper.selectMaps(queryWrapper);
System.out.println(maps);
//排序,having和所有的聚合函数都是通过这个实现的(queryWrapper)
}
}当我们涉及到分组和数量统计的时候就不能依据于Dept实体类里面的属性去做映射,我们在select方法里面写的就是在sql语句中的select后面from前面的东西,支持重命名,而调用查询的时候也不能直接用selectList方法来返回数据了,而是selectMaps,因为count和分组之后的数据不能映射到Dept中,而是通过键值对方式得到的
说到这里,当我们确定只返回一个数据的时侯是用的是selectOne方法
模糊查询like
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
LambdaQueryWrapper<Dept> queryWrapper = new LambdaQueryWrapper<>();
// queryWrapper.eq(Dept::getName,"李四").eq(Dept::getId,100L);
// //eq是等匹配
// //当要精确的查一个数据的时候selectOne
// queryWrapper.eq(Dept::getName,"李四").eq(Dept::getId,100L);
// Dept dept = deptMapper.selectOne(queryWrapper);
// //范围查询lt(不带等号) le(带) gt(不带) ge(带) eq(等号) between
// queryWrapper.between(Dept::getId,3L,9L);
//模糊匹配,主要将三个
queryWrapper.like(Dept::getName,"部");//这个是在给的字符串左右两边加%的即%部%
queryWrapper.likeRight(Dept::getName,"部");//部%
queryWrapper.likeLeft(Dept::getName,"部");//%部
//left和right是%的位置
//其他具体的按官网
List<Dept> depts = deptMapper.selectList(queryWrapper);
System.out.println(depts);
}
}实体类相关注解
@TableName(用于实体类上的)
当我们的实体类跟数据库中的表的名字无法映射的时候我们可以通过@TableName(value = "对应表名称")
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
private Long id;
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}@TableField(用于实体类属性上的)
这个注解是加在实体类的具体属性上的,他有多个常用属性
value(映射表中字段)
当我们实体类中的名字无法映射在表中字段的时候,我们可以显式的设置属性于字段的映射关系
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
private Long id;
@TableField(value = "name")//映射到表中的name字段
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
exist(该属性是否存在于表中)
当我们使用exist的时候是判断添加这个注解的属性是否在对应的表中,false则不在,默认为true
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
private Long id;
@TableField(value = "name")
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@TableField(exist = false)
private String stl;
}
就像上面的stl我们设置的exist是false那么在后续的数据查询和数据更新的时候就会忽略这个字段,即查询出来的数据对应的stl属性一直为null
这个属性于value冲突,即不能于value同时加
select(是否在数据查询时返回对应数据)
select属性是判定我们在查询的数据在返回的时候是否返回对应属性的值,如果为false就不返回该属性的值,即一直为null
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
private Long id;
@TableField(value = "name")
private String name;
@TableField(select = false)//不返回该属性的值
private LocalDateTime createTime;
private LocalDateTime updateTime;
@TableField(exist = false)
private String stl;
}主键id生成策略
我们最常见的id生成策略就是主键自增策略,但是还有其他生成的策略
IdType.AUTO
这个就是主键自增策略,我们在插入数据的时候就不需要主动去设置id了
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
Dept dept = new Dept(null,"sjs",LocalDateTime.now(),LocalDateTime.now());
deptMapper.insert(dept);
}
}实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
@TableId(type = IdType.AUTO)//主键自增
private Long id;
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
Dept dept = new Dept();
dept.setName("sjs");
dept.setCreateTime(LocalDateTime.now());
dept.setUpdateTime(LocalDateTime.now());
deptMapper.insert(dept);
}
}注意,该功能是要将数据库里面的主键id设置为自增属性,不是这个注解添加后MP帮我们自动生成id,而是在数据插入的时候就不会插入id这个值,数据库主键自增功能和这个注解缺一不可,否则就会报错

IdType.INPUT
当我们设置的是这个类型的时候就不要再让数据库有自增策略了,INPUT是让我们自己去设置id,这时候我们就要自己去设置id
IdType.ASSIGN_ID
这个是基于雪花算法去生成的一个数字类型的id,是它自己生成的,注意,如果我们设置的是在类型的同时我们还自己设置了id的话,它依旧会使用我们自己设置的id,若没有自己设置就会使用它基于雪花算法生成的id
这里我改了一下表的id的类型因为雪花算法生成的数据类型为Long类型的
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
@TableId(type = IdType.ASSIGN_ID)//主键自增
private Long id;
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
Dept dept = new Dept();
dept.setName("cfy");
dept.setCreateTime(LocalDateTime.now());
dept.setUpdateTime(LocalDateTime.now());
deptMapper.insert(dept);
}
}

就能发现成功插入了数据
IdType.ASSIGN_UUID
通过UUID生成算法生成的id,是BigInt类型的(64位的)

首先占位符默认是0,因为0代表正数,后面的41位是代表着时间戳,当有多态服务器同时向数据库中插入数据的时候,我们要分开他们的区别,所以引入机器码,这个机器码可以认为是服务器的地址(唯一的),当一个服务器里面同时插入多条数据的时候,序列号来做差异
这里就不做实例了跟前面一样的
逻辑删除
当我们在业务中的时候,我们删除了数据库中的数据,在某些场景下我们查询对应的数据,会存在数据缺失,所以我们不能真正的删除一个字段,所以我们要新增一个字段,在逻辑上删除,但实际上没有真正的删除它,只是给他做了一个标记,我们在数据库里面假定0是没有删除的状态,1是删除的状态
然后在实体类里面新增逻辑字段,但是这个字段要加注解即@TableLogic注解
这个注解里面要设置两个值:
value是指的是没有删除的标记
delval是删除了的标记
注意一定要在数据库里面再去新增一个字段,来设置逻辑删除的标记
如果我们加了这个逻辑字段之后,它在select查询里面就会新增一个条件即是否对应的字段是未删除的标记
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
private Long id;
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@TableLogic(value = "0",delval = "1")//设置未删除的数据是0,删除的是1
private Integer deleted;
}
如果我们此时要查询逻辑删除后的数据就是跟mbatis里面一样的了
你会发现我们此时再去调用删除的方法就是执行的update语句去修改逻辑字段了
全局配置
spring:
application:
name: MybatisPlus
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/tlias?
username: root
password: 1234
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
# 驼峰命名法
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 日志打印,打印到控制台,即那些sql执行语句输出到控制台
cache-enabled: false
# 是否开启二级缓存
global-config:
db-config:
id-type: auto
# id生成策略
table-prefix:
# 前缀设置,即当我们的表名于实体名只有前缀区别,我们可以再这里设置前缀
logic-delete-field:
# 设置逻辑删除对应字段
logic-not-delete-value:
# 未删除数据标记
logic-delete-value:
# 删除数据标记乐观锁
乐观锁(Optimistic Locking)是一种并发控制机制,它假设多个事务之间不会发生冲突,因此在执行操作时不进行加锁,而是在提交数据时进行检查,确认数据在操作期间没有被其他事务修改过。如果数据没有被修改过,则允许提交;如果数据在此期间已经被修改,则操作会失败,需要重新尝试。
乐观锁的核心思想是“乐观”地认为不会发生冲突,因此在操作过程中不会加锁,而是在提交时通过某种方式(如版本号、时间戳等)检测数据是否被其他事务修改过,从而保证数据的一致性。
-
版本号机制:在数据表中添加一个版本号字段,每次更新数据时,版本号会自动递增。操作时,先检查当前数据的版本号是否和数据库中的版本号一致,如果一致则更新,并将版本号加一。如果不一致,则说明数据被其他事务修改过,更新操作会失败。
-
时间戳机制:在数据表中添加一个时间戳字段,每次数据更新时,时间戳会更新。操作时,先检查当前数据的时间戳与数据库中的时间戳是否一致,如果一致,则进行更新。如果不一致,则说明数据已经被其他事务修改,更新操作会失败。
-
优点:
-
不需要像悲观锁一样频繁加锁,减少了锁竞争,性能较好。
-
适用于读多写少的场景,能够提高系统的吞吐量。
-
-
缺点:
-
如果冲突频繁,乐观锁的重试机制可能导致性能下降。
-
对比悲观锁,乐观锁需要额外的版本号或时间戳字段来维护数据一致性。
-
乐观锁常用于高并发的系统中,特别是对于读取远多于写的场景,例如电子商务平台、社交网络等,适合那些并发冲突较少的场景。
总结就是会先设置新增数据库字段version,然后拿到对应的数据,然后在更新数据的时候会先判断(即加where)是否在我们更新数据的时候还是之前的version,不是的话就更新失败了
举个例子:
假设有一个products表,包含字段id, name, price和version,其中version字段用来标识版本号。
-
读取数据:
-
用户A读取
id=1的商品数据,得到version=5,并对价格进行修改。
-
-
提交数据:
-
在用户A准备提交更新时,系统会检查当前
id=1的商品记录的version字段是否还是5。 -
如果没有其他事务修改该数据,那么提交会成功,
version字段会加1,变成6,并保存更新后的价格。
-
-
冲突检测:
-
假设此时用户B也读取了同一条记录,并尝试修改价格。在用户B提交数据时,系统会检查
version字段,发现version=6(而不是5),说明用户A已经修改了数据,用户B的更新会被拒绝,提示冲突。 -
用户B可能需要重新读取数据、更新价格并提交,或者根据业务需求做其他处理。
-
MP中的实现方式
首先我们要在数据库添加对应字段version,
然后再实体中添加对应属性,然后给该属性添加注解@Version
给属性添加@Version注解
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dept")//映射对应的表
public class Dept {
private Long id;
private String name;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@Version
private Integer version;
}
添加乐观锁拦截器
@Configuration
public class MpConfig {
@Bean
public MybatisPlusInterceptor mpInterceptor() {
//先new一个MybatisPlusInterceptor,这个是 MybatisPlus的总的拦截器,我们要往这个总的拦截器里面加具体的拦截器
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
//添加分页查询的拦截器
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
mybatisPlusInterceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
//添加乐观锁拦截器
return mybatisPlusInterceptor;
}
}
这里添加拦截器的作用就是做sql语句增强的,他一个作用是若能够更新数据的话,就在version字段在原来基础上加一,另外一个作用就是增加where条件,即判断当前表中对应数据的version是否是我们提前查询出来的version数据,若是的话就能修改
在数据更新前要先拿到对应数据的版本号
注意我们在更新前一定要先拿到版本号version才能去做更新操作,否则拦截器是不会生效的
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
Dept dept = deptMapper.selectById(5L);//一定要先拿到version
dept.setName("张三");//更新数据
deptMapper.updateById(dept);
}
}Delete操作的的条件设置
我们在delete操作的时候就直接使用QueryWrapper对象来设置条件就行了,因为查询和删除里面where是差不多的
LambdaUpdateWrapper和UpdateWrapper
他们的区别跟查询的一样的LambdaUpdateWrapper支持lambda表达式做条件限制而UpdateWrapper是字符串形式做条件形式,他们的使用跟查询对应的两个条件对象是一样的,这里就不做解释了
QueryWrapper中有一个select方法这是LambdaQueryWrapper没有的
而在UpdateWrapper有setsql方法,用于设置sql语句里面的set里面数据的更新
@SpringBootTest
public class MPTest {
@Autowired
private DeptMapper deptMapper;
@Test
public void test(){
UpdateWrapper wrapper = new UpdateWrapper();
wrapper.setSql("name = '胖猫'");
wrapper.eq("id",10L);
deptMapper.update(wrapper);
}
}UpdateWrapper不像LambdaUpdateWrapper一样,LambdaUpdateWrapper支持链式编程,但是不建议像上面这个一样做,因为sql对应的语句应该是写在数据访问层里面,而不是在其他地方。
持久层(Service层)
在MP中也封装了service层相关的方法去访问数据访问层
使用步骤
首先给对应的Service层接口继承IService接口其泛型里面填的是用于数据访问层数据封装的实体类

然后在这个Service层对应的实现类里面继承ServiceImpl接口,其泛型类型指定对应数据访问层的接口,和要操作的实体类

注意是先继承再实现,否则会出语法错误
此时我们就在Service去调用一些写好的方法,其本质就是帮我们去调用之前继承于BaseMapper的数据访问层,即我们上面指定的DeptMapper,这时候我们就不需要自己在Service层操作数据访问层了,而是调用方法自动实现
save相关操作
save
我们这里在TestService里面创建saveDept让实现类去实现这个方法

实现类实现对应方法
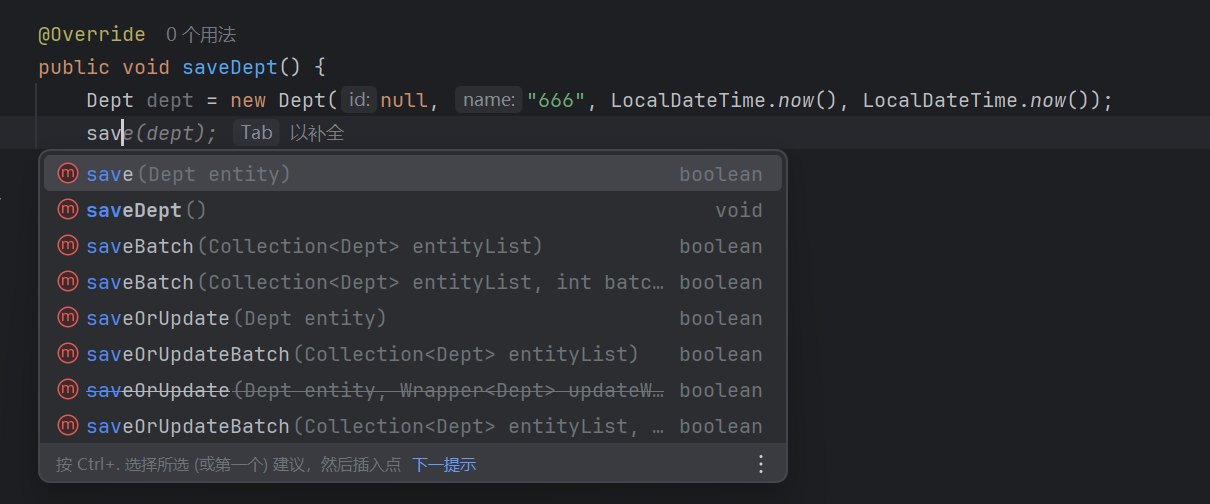
可以发现我们点save的时候他指定的类型就是指定的Dept类型,因为我们在实现类继承的ServiceImpl里面泛型就指定了实体类
save是保存的一条数据
我们这里依旧是同单元测试来测试,就不写controller层了

成功的插入了数据,注意我设置id的时候weinull是因为表里面的id字段我设置的是自增功能且在对应实体类上写了@TableId(type = IdType.AUTO)才能实现不插入id的
saveBatch保存多条数据
@Service
public class TestServiceImpl extends ServiceImpl<DeptMapper, Dept> implements TestService {
@Override
public void saveDept() {
List<Dept> depts = new ArrayList<Dept>();
depts.add(new Dept(null, "777", LocalDateTime.now(), LocalDateTime.now()));
depts.add(new Dept(null, "888", LocalDateTime.now(), LocalDateTime.now()));
depts.add(new Dept(null, "999", LocalDateTime.now(), LocalDateTime.now()));
saveBatch(depts);
}
}在测试单元里面测试

remove操作
// 根据 queryWrapper 设置的条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);其他的都大差不差这里主要讲一下removeByMap
// 假设有一个 columnMap,设置删除条件为 age = 30
Map<String, Object> columnMap = new HashMap<>();
columnMap.put("age", 30);
boolean result = userService.removeByMap(columnMap); // 调用 removeByMap 方法
if (result) {
System.out.println("Records deleted successfully.");
} else {
System.out.println("Failed to delete records.");
}生成的sql语句
DELETE FROM user WHERE age = 30Update操作
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);如果我们使用的是第一个方法的话就要在updateWrapper里面调用setsql方法去指定要更新的数据
get(查询数据,查询单条数据)
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);list(查询多条数据)
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);其他的大差不差,这里主要挑几个出来
listByMap方法
// 假设有一个 columnMap,设置查询条件为 age = 30
Map<String, Object> columnMap = new HashMap<>();
columnMap.put("age", 30);
Collection<User> users = userService.listByMap(columnMap); // 调用 listByMap 方法
for (User user : users) {
System.out.println("User: " + user);
}生成的sql
SELECT * FROM user WHERE age = 30listMaps QueryWrapper 形式
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,并将结果映射为 Map
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);
List<Map<String, Object>> userMaps = userService.listMaps(queryWrapper); // 调用 listMaps 方法
for (Map<String, Object> userMap : userMaps) {
System.out.println("User Map: " + userMap);
}生成的sql
SELECT * FROM user WHERE age > 25上面的代码我们主要使用的就那么几个,具体的可以上官网去看操作步骤
Page分页查询
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);有条件的Page分页查询
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,进行有条件的分页查询
IPage<User> page = new Page<>(1, 10);
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);
IPage<User> userPage = userService.page(page, queryWrapper); // 调用 page 方法
List<User> userList = userPage.getRecords();
long total = userPage.getTotal();
System.out.println("Total users (age > 25): " + total);
for (User user : userList) {
System.out.println("User: " + user);
}生成的sql
SELECT * FROM user LIMIT 10 OFFSET 0pageMaps QueryWrapper 形式
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,进行有条件的分页查询,并将结果映射为 Map
IPage<Map<String, Object>> page = new Page<>(1, 10);
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);
IPage<Map<String, Object>> userPageMaps = userService.pageMaps(page, queryWrapper); // 调用 pageMaps 方法
List<Map<String, Object>> userMapList = userPageMaps.getRecords();
long total = userPageMaps.getTotal();
System.out.println("Total users (age > 25): " + total);
for (Map<String, Object> userMap : userMapList) {
System.out.println("User Map: " + userMap);
}sql语句
SELECT * FROM user WHERE age > 25 LIMIT 10 OFFSET 0注意:我们只要是使用了分页查询就必须去设置分类拦截器!!!
count
// 查询总记录数
int count();
// 根据 Wrapper 条件,查询总记录数
int count(Wrapper<T> queryWrapper);
//自3.4.3.2开始,返回值修改为long
// 查询总记录数
long count();
// 根据 Wrapper 条件,查询总记录数
long count(Wrapper<T> queryWrapper);count QueryWrapper 形式
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,查询满足条件的用户总数
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);
int totalUsers = userService.count(queryWrapper); // 调用 count 方法
System.out.println("Total users (age > 25): " + totalUsers);生成的sql
SELECT COUNT(*) FROM user WHERE age > 25总结
到这里基本上大多数情况下的使用就这些了,我们一定要注意当涉及到多表的时候我们就要回归到MyBatis去写xml配置文了,因为MP设计的这些方法其实是对单表操作的
本人的第十五篇博客,以此来记录我的后端java学习。如文章中有什么问题请指出,非常感谢!!!


















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









