






目录
一.栈(stack)
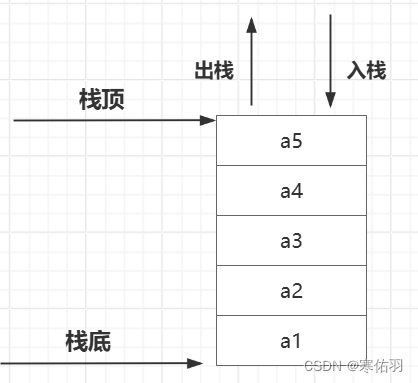
栈是数据结构中线性表的一种(stack),它的特点主要在于“后进先出”,它只允许一端入栈,同一端出栈;它有很多种表现方式,如链栈,顺序栈。
压栈:栈的插入操作叫作进栈/压栈/入栈,入数据只能从栈顶入
出栈:栈的删除操作叫作出栈,出数据也从栈顶出
空栈:不包含任何元素
1.顺序栈的主要功能
stackinit();//初始化
stackpush();//进栈
stackpop();//出栈
stacktop();//读取栈顶元素
stackdestroy();//销毁
stackempty();//判断栈是否为空2.顺序栈的主要框架
顺序栈采用数组的方式储存,我用的是由一个指针指向一组连续的储存单元,一个值储存栈顶数据的位置,还有一个值用来判断是否需要扩容,这个是否需要扩容的值capacity的主要用法会在入栈讲到
typedef int TYPE; //自定义类型可以方便类型替换,这里设定为int
typedef struct STACK
{
TYPE* a;
int top;
int capacity;
}stack;(1)初始化
定义结构体后进行初始化操作,这里我将top初始化为0
void stackinit(stack* pst)
{
assert(pst);
pst->a = NULL;
pst->top = 0;
pst->capacity = 0;
}注意:这里初始化top的时候需要注意赋值它会影响后续的取栈顶元素和判断是否为空栈
top为-1时为空栈,随着数据入栈它的数字就是栈顶元素的下标:
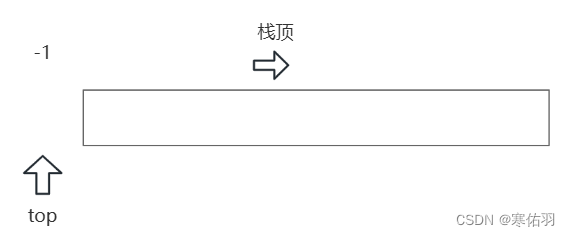
插入后:

top为0时为空栈,随着数据入栈它的数字就是栈顶元素的下一个:

插入后:

(2)判栈是否为空
这里使用布尔类型作为返回值
bool stackempty(stack* pst)
{
assert(pst);
return pst->top == 0;
}(3)入栈
注意:capacity在顺序栈中的主要作用就是动态扩容,并没有直接限制数组大小,当top与capacity一致时就会进行空间扩容
top与capacity是否相等,如果相等则扩容,在进行扩容时不必担心realloc会因为指向数组的指针为空无效,如果为空时realloc的效果与malloc一致。
为什么为与malloc效果一致可以进这个地址自查:realloc - C++ Reference (cplusplus.com)
void stackpush(stack* pst, TYPE x)
{
assert(pst);
if (pst->top == pst->capacity)
{
//如果capacity为0,则直接给4的大小
int new = pst->capacity == 0 ? 4 : pst->capacity * 2;//扩容至原来的两倍
TYPE* newnode = (TYPE*)realloc(pst->a, sizeof(TYPE) * new); //分配TYPE*new个空间
if (newnode == NULL)
{
perror("newnode");
return;
}
pst->a = newnode; //指针指向这块开辟出来的空间
pst->capacity = new;//不要忘了重新赋值判定扩容的值
}
pst->a[pst->top] = x;//将新插入元素赋值给栈顶空间
pst->top++;//栈顶指针加一
}(4)出栈
void stackpop(stack*pst)
{
assert(pst);
assert(pst->top>0);//判断是否为空栈
pst->top--;//栈顶指针减一
}(5)取栈顶元素
TYPE stacktop(stack* pst)
{
assert(pst);
assert(pst->top > 0);
return pst->a[pst->top-1];//top此时指向的是栈顶下一个的下标,所以需要-1才可以访问栈顶元素
}(6)销毁
void stackdestroy(stack* pst)
{
assert(pst);
free(pst->a);//释放空间
pst->a = NULL;//指针置空
pst->stop = pst->capacity = 0;
}以上就是顺序栈的形成
2.链栈的形成
使用链式结构储存的栈被称之为链栈,链栈的优点是每一个节点的空间都是分别开辟的,不会存在栈满溢出的情况。链式栈通常采用单链表的结构形成,并在表头进行后续的各项操作,这里top指向栈顶元素。
typedef int Typedata; typedef struct MyStruct { Typedata data; //数据域 struct MyStruct* next;//指针域 }Stacknode; typedef struct stacklink { Stacknode* top; //指向栈顶元素 int count; //用于判断是否为空栈 }Stack;
(1)链栈初始化
void Stackinit(Stack* sta)
{
assert(sta);
sta->top=NULL;
sta->count = 0;
}(2)链栈入栈
将新节点赋予空间后它的next指针指向top所指向的空间,然后将top改为指向新节点,计数count++
void Stackpush(Stack* sta, Typedata x)
{
assert(sta);
Stacknode* newnode = (Stacknode*)malloc(sizeof(Stacknode));
newnode->data = x;
newnode->next = sta->top; //初始化的时候top已经是空
sta->top = newnode;
sta->count++;
}(3)链栈出栈
new储存栈顶元素的下一个,然后释放栈顶元素,记得将new设为新的栈顶元素,计数count--
void Stackpop(Stack* sta)
{
assert(sta);
assert(sta->count > 0);
Stack* new = sta->top->next;
free(sta->top);
sta->top = new;
sta->count--;
}其余各项操作都是以链表的方式进行访问难度不大就略过,链栈的压栈出栈可以粗略的理解为单链表头插和头删这样写过程会更好理解一点。
3.顺序栈和链栈的差别
在空间性能上,原本的顺序栈是使用固定长度的,在这一点上会容易出现栈溢出或者空间浪费的情况,而链栈的每个节点使用动态内存开辟,且长度无限制,所以顺序栈略输于链栈。如果使用栈时元素不可控制那么最好使用链栈,反之则是顺序栈更好用。
二.队列(queue)
队列和栈有相似的地方,栈式后进先出,而队列则式先进先出,它入数据由一端输入,出数据则从另一端出,允许入数据的一头为队尾,出数据为队头
队头:进行数据删除的一端
队尾:进行入数据的一端
1.队列的主要功能
Queueinit();//初始化
Queuepush();//入队列
Queuepop();//出队列
Queuetop();//读取队头元素
Queuedestroy();//销毁
Queueempty();//判断队列是否为空队列同样也可以使用数组,但于删除和增加数据太过麻烦所以不考虑数组实现,使用链表的方式实现更佳。调用两个指针指向头和尾,所以额外定义一个结构体用于保存头和尾,还有一个进行数据个数的记录,将它当作同时带头尾指针的单链表就可以了。
typedef int INT;
typedef struct MyStruct
{
INT val;
struct MyStruct* next;
}Qnode;
typedef struct Queue
{
Qnode* head; //指向头节点
Qnode* ptail; //指向尾节点
int size; //记录数据个数
}Queue;(1)初始化
定义一个保存头和尾节点的结构体进行初始化
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->ptail = NULL;
pq->size = 0;
}(2)入队列
void Queuepush(Queue* pq, INT x)
{
Qnode* newnode = (Qnode*)malloc(sizeof(Qnode));//创建新节点
if (newnode == NULL)
{
perror("newnode");
return;
}
newnode->val = x;//节点赋值
newnode->next=NULL;
if (pq->ptail == NULL)//判断队列是否为空
{
pq->head = pq->ptail = newnode;//头和尾指针都指向同一个节点
}
else
{
pq->ptail->next = newnode;//将新节点插入在尾节点的后面
pq->ptail = newnode;//此时新节点就是尾节点
}
pq->size++;//计数加一
}(3)出队列
size计数在这里起到判空作用,但实际上判断头指针或者尾指针也是可行的
void Queuepop(Queue* pq)
{
assert(pq);
assert(pq->size != 0); //判断队列是否为空
Qnode* next = pq->head->next; //记录头节点下一个节点
free(pq->head); //释放当前头节点
pq->head = next; //头指针改为保存的节点
//如果只有一个节点的情况
if (pq->head == NULL)//判断此时的头节点是否为空
{
pq->ptail = NULL;//头节点为空此时为空队列,尾指针置空
}
pq->size--;计数减一
}(4)读取队头元素
INT Queuetop(Queue* pq)
{
assert(pq);
assert(pq->head);//判断头指针是否为空
return pq->head->val;
}(5)判断队列是否为空
这里使用布尔类型作为返回值判断size是否为0
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}(6)销毁
销毁就使用正常单链表的销毁方式即可
void QueueDestroy(Queue* pq)
{
assert(pq);
while (pq)
{
Qnode* next=pq->head->next;
free(pq->head);
pq->head = next;
}
pq->head=pq->ptail=NULL;
pq->size=0;
}本篇文章就到这里了,希望能够对你产生帮助,感谢你的阅读。















 6317
6317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









