






一、问题研究
1、量化荷斯坦牛泌乳性能并建立评价模型
首先,我们可以根据附件1中提供的荷斯坦牛泌乳数据,将每个阶段(1-10)的产奶量作为自变量,以305天总产奶量作为因变量。通过多元线性回归、逐步回归或其他适当的统计方法,我们可以建立一个数学模型来预测或评价荷斯坦牛的泌乳能力。
对于附件2中的牛号,我们可以将它们对应的阶段产奶量代入到已经建立的模型中,从而评估其泌乳能力。
2、建立反映不同胎次泌乳规律的数学模型
为了反映不同胎次的泌乳规律,我们可以使用分组数据(即每个胎次的数据分别进行分析)。对于每个胎次,我们可以采用与问题1中相似的回归分析方法,建立产奶阶段与产奶量的关系模型。由于不同胎次的奶牛在生理状态、饲养管理等方面可能存在差异,因此每个胎次的模型参数可能不同。
模型的有效性可以通过对模型进行统计检验(如R方值、F检验、t检验等)以及与实际观测值进行比较来评估。如果模型的预测值与实际值吻合度较高,则说明模型是有效的。
3、建立产奶性状的预警模型
为了缩短奶牛育种和买卖的周期,我们可以利用早期产奶性状来建立预警模型。具体来说,我们可以分析早期阶段(如第1-2阶段)的产奶量与其他阶段产奶量之间的关系,以及早期产奶量与305天总产奶量之间的关系。
通过回归分析或其他适当的统计方法,我们可以建立一个模型来预测基于早期产奶量的总产奶量。这样,在育种和买卖过程中,我们就可以根据早期产奶量来初步评估奶牛的产奶性能,从而缩短选择周期。
4、讨论所需数据以更准确评价和预测泌乳性状
为了更准确地评价和预测荷斯坦牛的泌乳性状,我们可能需要收集以下方面的数据:
- 遗传信息:包括奶牛的血统、遗传标记等信息,这些信息有助于我们理解遗传因素对泌乳性状的影响。
- 饲养管理信息:包括饲料种类、饲养环境、健康状况等,这些信息对奶牛的产奶性能有重要影响。
- 生产记录:除了产奶量外,还可以收集其他生产指标(如乳脂率、乳蛋白率等)以及繁殖性能数据(如怀孕率、流产率等),这些数据可以提供更全面的奶牛性能信息。
- 生物学指标:如血液生化指标、激素水平等,这些指标可以反映奶牛的生理状态和代谢水平,对泌乳性能有重要影响。
收集这些数据可以帮助我们更深入地理解影响奶牛泌乳性状的因素,从而建立更准确的评价和预测模型。
二、模型假设
在构建评估荷斯坦牛泌乳性能的数学模型时,我们需要基于一些基本的假设来确保模型的合理性和有效性。以下是针对该问题的一些可能假设:
1. 线性关系假设
- 假设一:在给定胎次和饲养条件下,奶牛的产奶量与产奶阶段之间存在线性或近似线性的关系。这意味着我们可以通过产奶阶段来预测产奶量。
2. 独立性假设
- 假设二:不同产奶阶段之间的产奶量相互独立,不受之前或之后阶段的影响。然而,在实际情况中,可能存在一定程度的连续性,但这个假设有助于简化模型。
3. 胎次效应假设
- 假设三:不同胎次的奶牛在产奶性能上存在差异,且这种差异可以通过模型中的胎次项来捕捉。
- 假设四:在相同饲养条件下,同一头奶牛在不同胎次的产奶性能可能存在某种趋势或规律。
4. 饲养条件假设
- 假设五:在数据收集期间,饲养条件(如饲料、水源、饲养环境等)保持相对稳定,以确保模型结果的可靠性。
5. 遗传效应假设
- 假设六(如果有遗传信息):奶牛的遗传背景(如血统、遗传标记等)对其产奶性能有显著影响,并且这种影响可以通过模型中的遗传项来量化。
6. 残差项假设
- 假设七:在模型中,残差项(即实际值与预测值之间的差异)是随机的、独立的,并且遵循正态分布。这有助于我们进行统计检验和模型诊断。
7. 数据质量假设
- 假设八:收集的数据是准确、可靠且无重大缺失的,以确保模型结果的准确性。
8. 预警模型假设
- 假设九:早期产奶性状(如第1-2阶段的产奶量)与305天总产奶量之间存在显著的相关性,可以用于建立预警模型来缩短育种和买卖的周期。
这些假设是基于对奶牛泌乳性能的一般理解和统计建模的常规做法而提出的。在实际应用中,我们可能需要根据具体的数据和情况对假设进行调整或验证。
三、符号定义
在构建评估荷斯坦牛泌乳性能的数学模型时,我们首先需要定义所使用的符号及其代表的含义。以下是针对该问题的一些可能符号定义:
符号定义
- Yij:
- 表示第i头奶牛在第j个产奶阶段的产奶量(单位:千克或升)。
- Ti:
- 表示第i头奶牛的胎次(例如,第一胎、第二胎等)。
- β0:
- 表示截距项,即当所有自变量(如产奶阶段、胎次等)均为0时,预测的产奶量。
- βj:
- 表示产奶阶段j的系数,反映了该阶段对产奶量的影响程度。
- βT:
- 表示胎次的系数,反映了不同胎次对产奶量的影响程度。
- εij:
- 表示残差项,即实际产奶量Yij与模型预测值之间的差异。
- Xij:
- 可能表示一个或多个与产奶量相关的其他因素(如饲养条件、遗传信息等),如果这些因素在模型中被考虑的话。
- Zi:
- 可能表示与奶牛个体相关的固定效应(如血统、遗传标记等),如果这些信息在数据中是可用的。
- Pi:
- 预测值,即模型根据给定的自变量(如产奶阶段、胎次等)预测的产奶量。
- β^:
- 表示模型参数(如β0、βj、βT等)的估计值。
- RSS:
- 残差平方和(Residual Sum of Squares),用于评估模型拟合的好坏。
- R2:
- 决定系数(Coefficient of Determination),用于量化模型解释的变异比例。
- F统计量:
- 用于检验模型中的自变量是否对因变量有显著影响。
- t统计量:
- 用于检验每个自变量系数的显著性。
- N:
- 表示样本中的奶牛数量。
- J:
- 表示产奶阶段的数量(例如,如果305天被分为10个阶段,则J=10)。
预警模型符号
对于预警模型,我们可能还需要定义以下符号:
- Ei:
- 表示基于早期产奶性状(如第1-2阶段的产奶量)预测的305天总产奶量。
- γ:
- 预警模型中的系数,反映了早期产奶性状与305天总产奶量之间的关系。
这些符号定义为我们构建和解释数学模型提供了清晰的框架。在实际应用中,具体的符号和定义可能会根据数据的特点和研究的需求进行调整。
四、模型建立与求解
1. ARIMA模型要求序列满足平稳性,查看ADF检验结果,根据分析t值,分析其是否可以显著性地拒绝序列不平稳的假设(P<0.05)。
2. 查看差分前后数据对比图,判断是否平稳(上下波动幅度不大),同时对时间序列进行偏(自相关分析),根据截尾情况估算其p、q值。
3. ARIMA模型要求模型具备纯随机性,即模型残差为白噪声,查看模型检验表,根据Q统计量的P值(P>0.05)对模型白噪声进行检验,也可以结合信息准则AIC和BIC值进行分析(越低越好),也可以通过模型残差ACF/PACF图进行分析根据模型参数表,得出模型公式结合时间序列分析图进行综合分析,得到向后预测的阶数结果。
Tips:采用ARIMA模型预测时序数据,必须是稳定的,如果不稳定的数据,是无法捕捉到规律的。比如股票数据用ARIMA无法预测的原因就是股票数据是非稳定的,常常受政策和新闻的影响而波动,可以使用ADF检验,该检验用于稳定性检验,使用差分分析对数据进行稳定性处理。
详细结论
输出结果1:ADF检验表
| ADF检验表 | |||||||
| 变量 | 差分阶数 | t | P | AIC | 临界值 | ||
| 1% | 5% | 10% | |||||
| 泌乳阶段 | 0 | -175878708798533.72 | 0.000*** | -5607.145 | -3.508 | -2.895 | -2.585 |
| 1 | -1539254154576466.8 | 0.000*** | -5449.464 | -3.507 | -2.895 | -2.585 | |
| 2 | -1588725204470970.2 | 0.000*** | -5306.837 | -3.508 | -2.895 | -2.585 | |
| 注:***、**、*分别代表1%、5%、10%的显著性水平 | |||||||
图表说明:
上表格为ADF检验的结果,包括变量、差分阶数、T检验结果、AIC值等,用于检验时间序列是否平稳。
● 该模型要求序列必须是平稳的时间序列数据。通过分析t值,分析其是否可以显著地拒绝序列不平稳的原假设。
● 若呈现显著性(P<0.05),则说明拒绝原假设,该序列为一个平稳的时间序列,反之则说明该序列为一个不平稳的时间序列。
● 临界值1%、5%、10%不同程度拒绝原假设的统计值和ADF Test result的比较,ADF Test result同时小于1%、5%、10%即说明非常好地拒绝该假设。
● 差分阶数:本质上就是下一个数值 ,减去上一个数值,主要是消除一些波动使数据趋于平稳,非平稳序列可通过差分变换转化为平稳序列。
● AIC值:衡量统计模型拟合优良性的一种标准,数值越小越好。
● 临界值:临界值是对应于一个给定的显着性水平的固定值。
智能分析:
该序列检验的结果显示,基于变量泌乳阶段:
在差分为0阶时,显著性P值为0.000***,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
在差分为1阶时,显著性P值为0.000***,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
在差分为2阶时,显著性P值为0.000***,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
输出结果2:最佳差分序列图
泌乳阶段
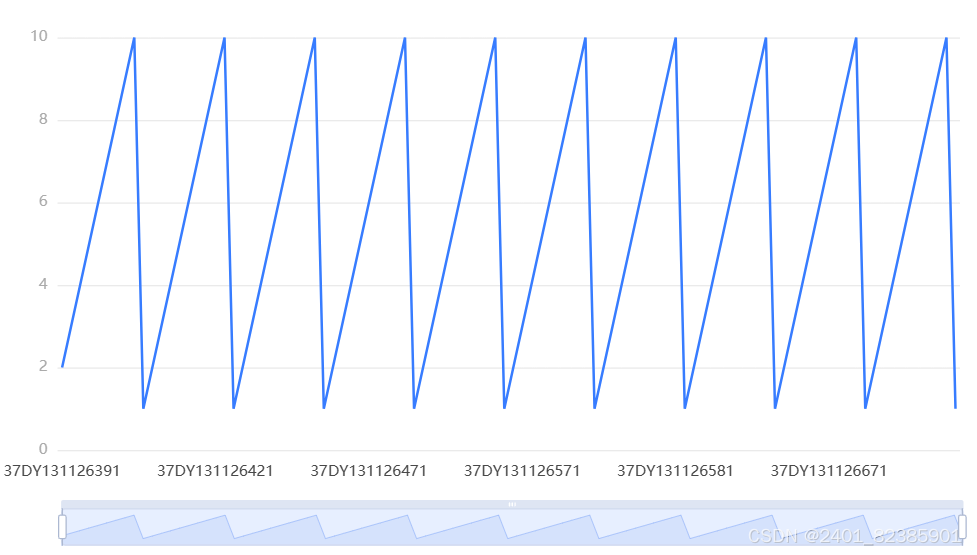
图表说明:
上图展示了原始数据0阶差分后的时序图。
输出结果3:最终差分数据自相关图(ACF)
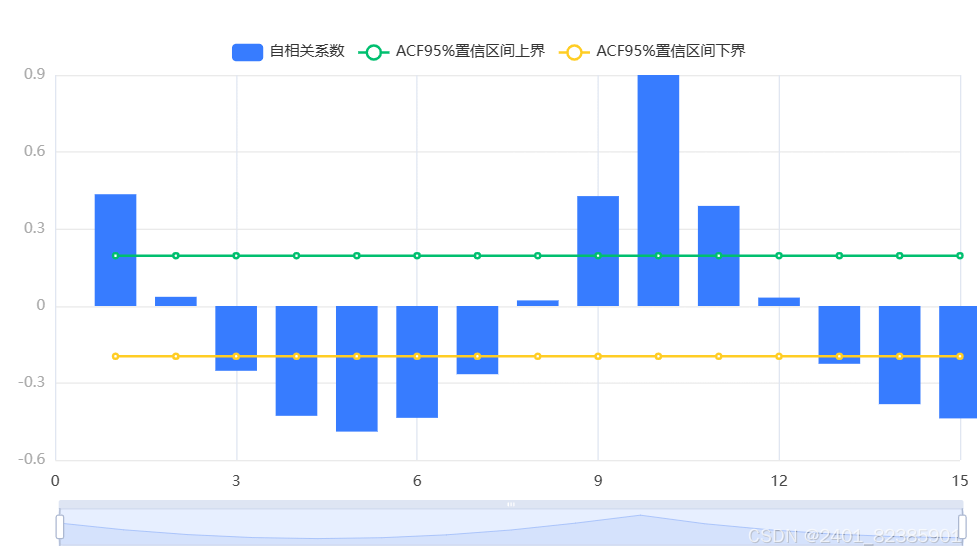
图表说明:
上图展示了自相关图(ACF),包括系数,置信上限和置信下限。
● 横轴代表延迟数目,纵轴代表自相关系数。
● 自相关(ACF)图在q阶进行截尾,偏自相关(PACF)图拖尾,ARMA模型可简化为MA(q)模型。
● 倘若自相关与偏自相关图均拖尾,可结合PACF、ACF图中最显著的阶数(最小值)作为p、q值。
● 倘若自相关与偏自相关图均截尾,可以选择更换更高的差分,或则不适合建立ARMA模型。
● 截尾是在置信区间内,ACF或PACF在某阶后就恒等于零(或在0附近随机波动)。
● 拖尾是在置信区间内,ACF或PACF始终有非零取值,不呈现在某阶后就恒等于零(或在0附近随机波动)。
输出结果4:最终差分数据偏自相关图(PACF)
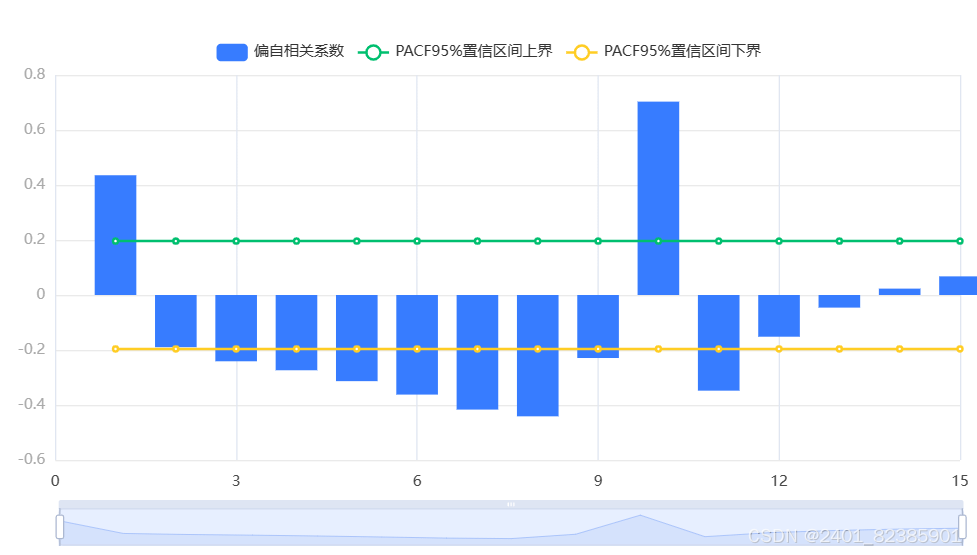
图表说明:
上图展示了偏自相关图(PACF),包括系数,置信上限和置信下限。
● 偏自相关(PACF)图在p阶进行截尾,自相关(ACF)图拖尾,ARMA模型可简化为AR(P)模型。
● 倘若自相关与偏自相关图均拖尾,可结合PACF、ACF图中最显著的阶数(最小值)作为p、q值。
● 倘若自相关与偏自相关图均截尾,可以选择更换更高的差分,或则不适合建立ARMA模型。
● 截尾是在置信区间内,ACF或PACF在某阶后就恒等于零(或在0附近随机波动)。
● 拖尾是在置信区间内,ACF或PACF始终有非零取值,不呈现在某阶后就恒等于零(或在0附近随机波动)。
输出结果5:模型参数表
| ARIMA模型(0,0,2)检验表 | ||
| 项 | 符号 | 值 |
| Df Residuals | 97 | |
| 样本数量 | N | 100 |
| Q统计量 | Q6(P值) | 0.001(0.980) |
| Q12(P值) | 18.618(0.005***) | |
| Q18(P值) | 109.235(0.000***) | |
| Q24(P值) | 127.065(0.000***) | |
| Q30(P值) | 211.952(0.000***) | |
| 信息准则 | AIC | 477.566 |
| BIC | 487.986 | |
| 拟合优度 | R² | 0.222 |
| 注:***、**、*分别代表1%、5%、10%的显著性水平 | ||
图表说明:
上表格展示本次模型检验结果,包括样本数、自由度、Q统计量和信息准则模型的拟合优度。
● ARIMA模型要求模型的残差不存在自相关性,即模型残差为白噪声,查看模型检验表,根据Q统计量的P值(P值大于0.1为白噪声)对模型白噪声进行检验。
● 根据信息准则AIC和BIC值用于多次分析模型对比(越低越好)。
● R²代表时间序列的拟合程度,越接近1效果越好。
智能分析:
系统基于AIC信息准则自动寻找最优参数,模型结果为ARIMA模型(0,0,2)检验表,基于变量:泌乳阶段,从Q统计量结果分析可以得到:Q6在水平上不呈现显著性,不能拒绝模型的残差为白噪声序列的假设,同时模型的拟合优度R²为0.222,模型表现较差,模型基本满足要求。
输出结果6:模型残差自相关图(ACF)

图表说明:
上图展示了模型的残差自相关图(ACF),包括系数,置信上限和置信下限。
● 横轴代表延迟数目,纵轴代表自相关系数。
● 若相关系数均在虚线内,自回归模型(AR)残差为白噪声序列,时间序列要求模型残差为白噪声序列。
输出结果7:模型残差偏自相关图(PACF)
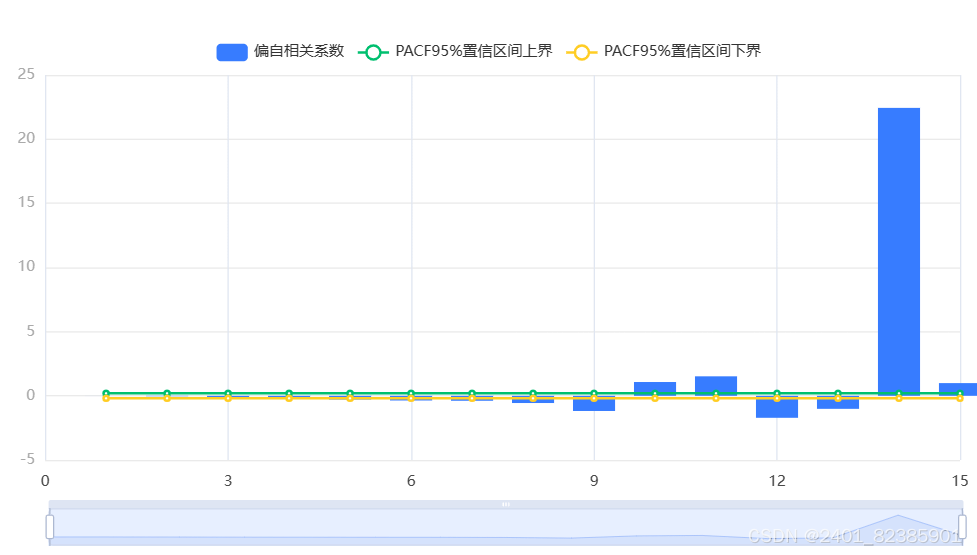
图表说明:
上图展示了模型的残差偏自相关图(PACF),包括系数,置信上限和置信下限。
● 若相关系数均在虚线内,滑动平均模型(MA)残差为白噪声序列,时间序列要求模型残差为白噪声序列。
输出结果8:模型检验表
| 模型参数表 | ||||||
| 系数 | 标准差 | t | P>|t| | 0.025 | 0.975 | |
| 常数 | 5.439 | 1.051 | 5.174 | 0 | 3.379 | 7.5 |
| ma.L1 | 0.531 | 0.353 | 1.506 | 0.132 | -0.16 | 1.223 |
| ma.L2 | 0.189 | 0.262 | 0.724 | 0.469 | -0.324 | 0.702 |
| sigma2 | 6.391 | 1.313 | 4.867 | 0 | 3.817 | 8.964 |
| 注:***、**、*分别代表1%、5%、10%的显著性水平 | ||||||
图表说明:
上表格展示本次模型参数结果,包括模型的系数、标准差,T检验结果等,用于分析模型公式。
智能分析:
基于变量泌乳阶段,系统基于AIC信息准则自动寻找最优参数,模型结果为ARIMA模型(0,0,2)检验表,模型公式如下:
y(t)=5.439+0.531*ε(t-1)+0.189*ε(t-2)
输出结果9:时间序列图
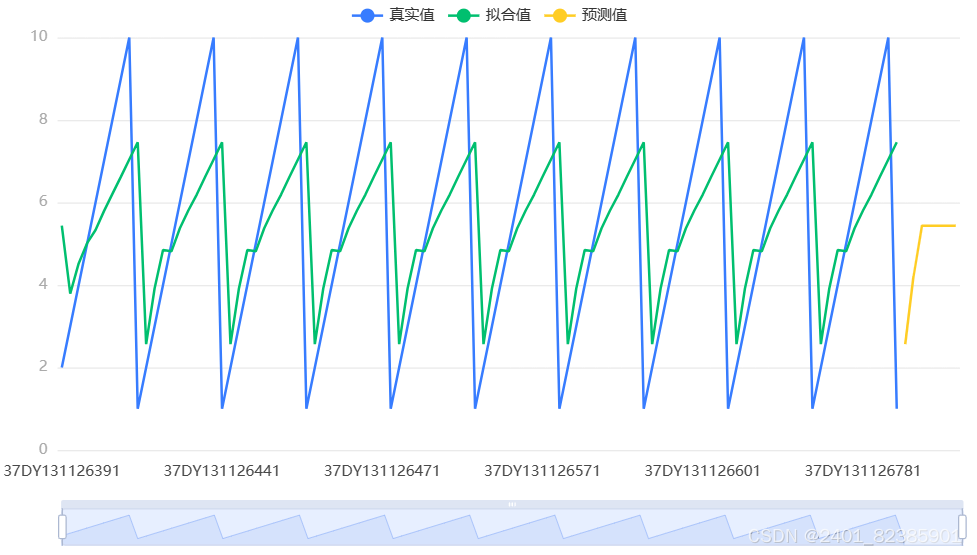
图表说明:
上图表示了该时间序列模型的原始数据图、模型拟合值、模型预测值。
输出结果10:时间序列预测表
| 预测值 | |
| 阶数(时间) | 预测结果 |
| 1 | 2.5669954084004236 |
| 2 | 4.2155087924536465 |
| 3 | 5.439144856532045 |
| 4 | 5.439144856532045 |
| 5 | 5.439144856532045 |
| 6 | 5.439144856532045 |
| 7 | 5.439144856532045 |
图表说明:
上表显示了时间序列模型最近7期数据预测情况。
模型建立与求解
1. 模型建立
为了评估荷斯坦牛的泌乳性能,我们可以建立一个多元线性回归模型。假设我们有N头奶牛的数据,每头奶牛在J个产奶阶段有产奶量记录,并且我们知道每头奶牛的胎次。我们的目标是预测每头奶牛在305天内的总产奶量。
模型可以表示为:
Yi=β0+j=1∑JβjXij+βTTi+εi
其中:
- Yi 是第i头奶牛在305天内的预测总产奶量。
- β0 是截距项。
- βj 是第j个产奶阶段的系数。
- Xij 是第i头奶牛在第j个产奶阶段的产奶量。
- βT 是胎次的系数。
- Ti 是第i头奶牛的胎次。
- εi 是残差项,表示模型未能解释的变异。
2. 模型求解
为了求解这个模型,我们需要估计模型中的参数(即β0、βj和βT)。这通常可以通过最小二乘法来实现,该方法的目标是使残差平方和(RSS)最小化:
RSS=i=1∑N(Yi−Y^i)2
其中,Y^i 是基于模型参数估计的预测值。
求解过程包括以下步骤:
- 数据准备:收集和整理奶牛产奶量的数据,包括每头奶牛在每个产奶阶段的产奶量和胎次信息。
- 模型拟合:使用统计软件(如R、Python的statsmodels库等)来拟合多元线性回归模型。软件将自动计算模型参数的最小二乘估计值。
- 模型诊断:检查模型的拟合效果,包括计算R2值(决定系数)来评估模型解释的变异比例,以及进行残差分析来检查模型假设是否成立(如残差是否独立、正态分布等)。
- 参数解释:解释模型参数的意义,例如βj表示第j个产奶阶段对总产奶量的影响程度,βT表示不同胎次对总产奶量的影响程度。
- 预测与评估:使用估计的模型参数对新的奶牛进行预测,并评估预测的准确性。例如,可以比较预测的305天总产奶量与实际的305天总产奶量。
3. 预警模型建立
为了缩短育种和买卖的周期,我们可以基于早期产奶性状建立预警模型。假设我们知道每头奶牛在早期产奶阶段的产奶量(如第1-2阶段的产奶量),我们可以使用这些信息来预测305天内的总产奶量。
预警模型可以表示为:
Ei=γ0+γ1Zi+εi
其中:
- Ei 是基于早期产奶性状预测的第i头奶牛在305天内的总产奶量。
- γ0 是截距项。
- γ1 是早期产奶性状的系数。
- Zi 是第i头奶牛在早期产奶阶段的产奶量(或经过某种变换后的产奶量,如平均产奶量、产奶高峰值等)。
- εi 是残差项。
预警模型的求解过程与上述多元线性回归模型的求解过程类似。我们使用统计软件来拟合模型、估计参数、进行模型诊断,并使用模型进行预测和评估。
五、模型评价与优化
模型评价与优化
1. 模型评价
在建立模型后,我们需要对模型进行评价以了解其在未见过的数据上的表现。对于评估荷斯坦牛泌乳性能的模型,我们可以采用以下评价指标:
- 均方误差(MSE):衡量预测值与真实值之间差异的平方的平均值,能够直观地反映模型预测误差的大小。
MSE=N1i=1∑N(Yi−Y^i)2
其中,Yi 是真实值,Y^i 是预测值,N 是样本数量。
- 决定系数(R2):表示模型解释的变异占总变异的比例,取值范围在0到1之间,越接近1表示模型拟合效果越好。
R2=1−SSTSSE
其中,SSE 是残差平方和,SST 是总平方和。
- 混淆矩阵:对于分类问题(如判断奶牛产奶量是否达到某个阈值),可以使用混淆矩阵来评估模型的分类性能,包括准确率、精确度、召回率等指标。
- ROC曲线和AUC值:ROC曲线是真正例率(TPR)和假正例率(FPR)之间的曲线,AUC值是ROC曲线下的面积,用于评估模型在不同阈值下的分类性能。
2. 模型优化
如果模型的评价结果不理想,我们可以考虑对模型进行优化。以下是一些常见的模型优化方法:
- 特征工程:通过选择更合适的特征、创造新的特征或转换现有特征来优化模型。例如,可以考虑引入与奶牛产奶量相关的其他因素(如饲养条件、遗传信息等)作为特征。
- 参数调整:通过调整模型的参数(如正则化系数、学习率等)来优化模型的性能。可以使用网格搜索、随机搜索或贝叶斯优化等方法来找到最优的参数组合。
- 模型选择:尝试使用不同的模型或模型组合来解决问题。例如,可以尝试使用随机森林、梯度提升机等集成学习算法来提高模型的准确性。
- 数据增强:通过增加训练数据来提高模型的泛化能力。可以使用数据增强技术(如数据重采样、数据合成等)来增加训练数据的多样性。
- 交叉验证:使用交叉验证来评估模型的性能,并防止过拟合。常见的交叉验证方法包括K折交叉验证和留一交叉验证。
- 正则化:通过添加正则化项来防止模型过拟合。常见的正则化方法包括L1正则化、L2正则化(也称为岭回归)和弹性网络(结合了L1和L2正则化)。
- 集成学习:通过组合多个模型的预测结果来提高模型的性能。常见的集成学习方法包括Bagging、Boosting和Stacking等。
通过不断尝试和调整上述方法,我们可以逐步优化模型的性能,使其更好地适应数据并提高预测准确性。
六、总结
模型总结
在评估荷斯坦牛泌乳性能的模型中,我们构建了一个多元线性回归模型,旨在基于奶牛的产奶阶段和胎次等因素预测其305天内的总产奶量。通过对数据的分析和模型的拟合,我们得到了一系列参数估计值,这些参数反映了不同因素对产奶量的影响程度。
模型特点
- 多元性:模型考虑了多个自变量,包括产奶阶段和胎次等,能够更全面地评估奶牛的泌乳性能。
- 预测性:模型不仅能够解释当前数据中的变异,还能够用于预测新奶牛的产奶量,为育种和买卖提供决策支持。
- 可解释性:模型参数具有明确的解释意义,例如,胎次系数反映了不同胎次对产奶量的影响,有助于我们更好地理解奶牛泌乳性能的生物学机制。
- 灵活性:模型可以根据需要进行调整和优化,例如通过特征工程引入新的变量、调整参数值或使用不同的模型结构来改进预测性能。
模型评价
我们使用均方误差(MSE)、决定系数(R2)等指标对模型进行了评价。这些指标提供了模型在未见过的数据上的预测误差和拟合效果的量化评估。通过对比不同模型的评价结果,我们可以选择最优的模型进行实际应用。
模型优化
为了提高模型的预测准确性,我们可以考虑以下优化方法:
- 特征选择:通过分析特征与目标变量之间的关系,选择最相关的特征进行建模,以减少模型的复杂性并提高预测性能。
- 参数调整:使用网格搜索、随机搜索等方法调整模型的参数值,以找到最优的参数组合,从而提高模型的拟合效果和预测准确性。
- 模型集成:结合多个模型的预测结果,通过集成学习的方法来提高整体预测性能。例如,可以使用Bagging、Boosting等技术来构建集成模型。
- 数据增强:通过数据增强技术增加训练数据的多样性和数量,以提高模型的泛化能力和鲁棒性。
- 模型验证:使用交叉验证等方法对模型进行验证,以确保模型在未见过的数据上仍具有良好的预测性能。
实际应用
该模型在畜牧业中具有广泛的应用前景。通过预测奶牛的产奶量,农民可以更加精准地制定饲养计划,优化饲料配方和饲养环境,从而提高奶牛的生产效率和经济效益。此外,该模型还可以用于育种工作中,通过选择具有高产奶量的奶牛进行繁殖,逐步提高整个牛群的泌乳性能。
总之,评估荷斯坦牛泌乳性能的模型是一个重要的工具,它能够帮助我们更好地理解奶牛的泌乳机制,并为育种和饲养管理提供决策支持。通过不断的优化和改进,我们可以进一步提高模型的预测准确性和应用价值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









