






一. Pytorch数据处理工具箱
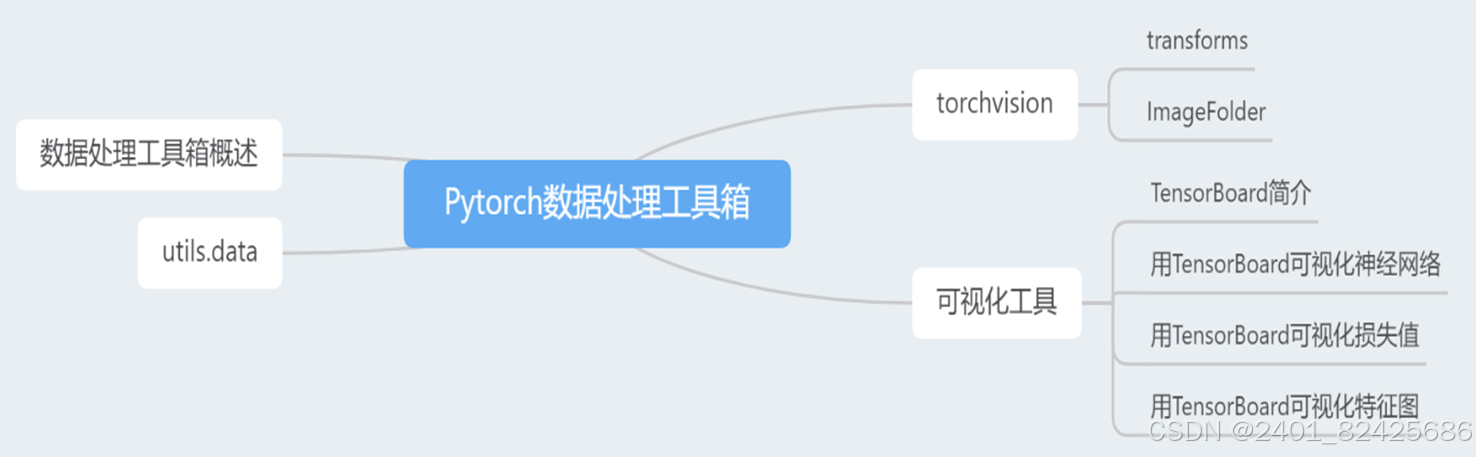
数据处理箱概述
1. torch.utils.data:
Dataset类:有 __getitem__ 和 __len__ 两个成员方法,用于构建自定义数据集。
DataLoader:可批量、并行加载数据集。
Random_split:随机划分数据。
Sampler:负责数据采样。
torchvision:包含计算机视觉常用数据集(如MNIST、CIFAR10 )和现代网络模型(如AlexNet ), transforms.compose 用于数据处理, utils.make_grid 和 utils.save_image 用于拼图和保存图。
2.torch.tensorboard:
是PyTorch较高版本推荐使用的可视化工具。
可可视化神经网络结构图、神经网络每一层的特征图以及损失值。

3.utis.dta
3.1 Dataset:
(1)_len_:提供数据大小
(2)_getitem_:通过给定索引获取数据,标签或一个样本
DataLoader:定义一个新的迭代器,实现批量读取
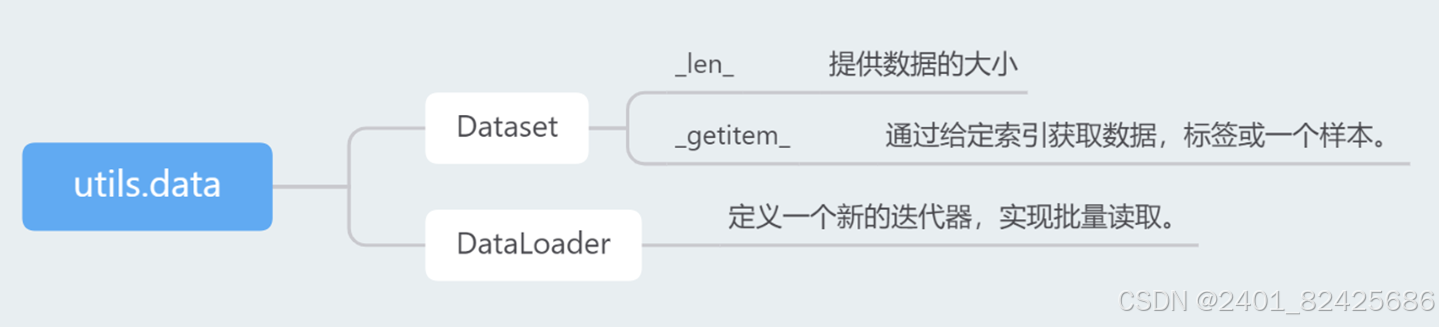
utils.data.Dataset:
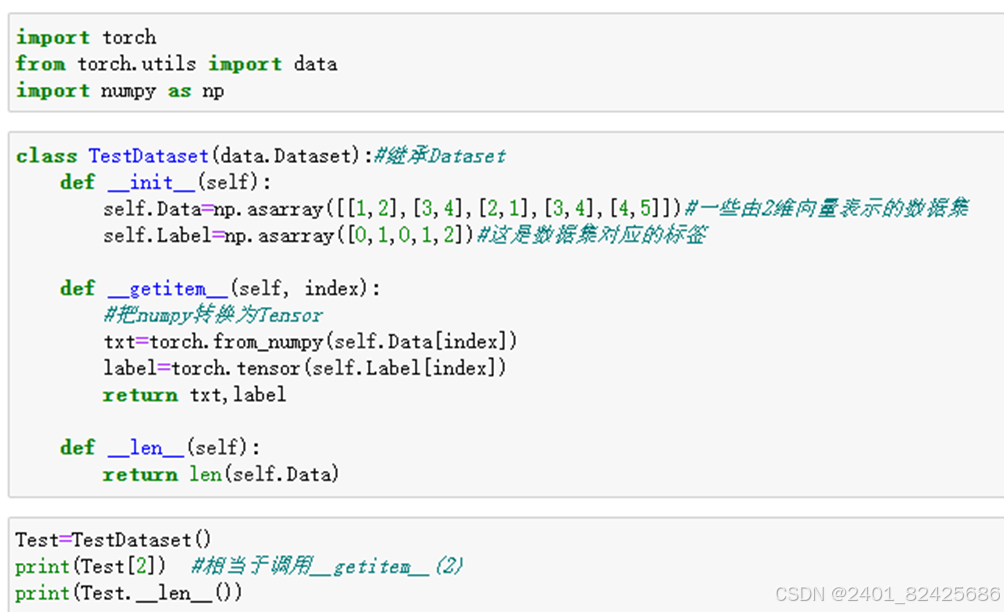
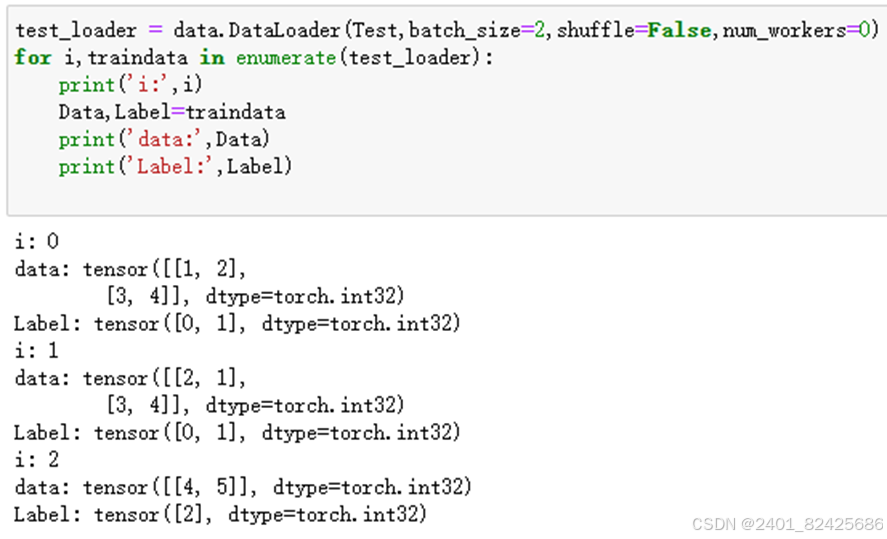
DataLoader:可以批量处理。 语法结构如图所示。
相关参数介绍如下
| dataset | 加载的数据集。 |
| batch_size | 批大小。 |
| shuffle | 是否将数据打乱。 |
| sampler | 样本抽样。 |
| num_workers | 使用多进程加载的进程数,0代表不使用多进程。 |
| collate_fn | 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可。 |
| pin_memory | 是否将数据保存在锁页内存(pin memory区),其中的数据转到GPU会快一些。 |
| drop_last | dataset 中的数据个数可能不是 batch_size的整数倍,drop_last为True会将多出来不足一个b atch的数据丢弃。 |
DataLoader:可以批量处理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









