






一、Hadoop生态圈相关组件
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。Hadoop 的核心是 HDFS 和 Mapreduce,HDFS 还包括 YARN。
Hadoop核心组件
1.HDFS
HDFS:分布式文件存储系统,解决海量数据存储
2.YARN
YARN:集群资源管理和任务调度框架,解决资源任务调度
3.MapReduce
MapReduce:分布式计算框架,解决海量计算
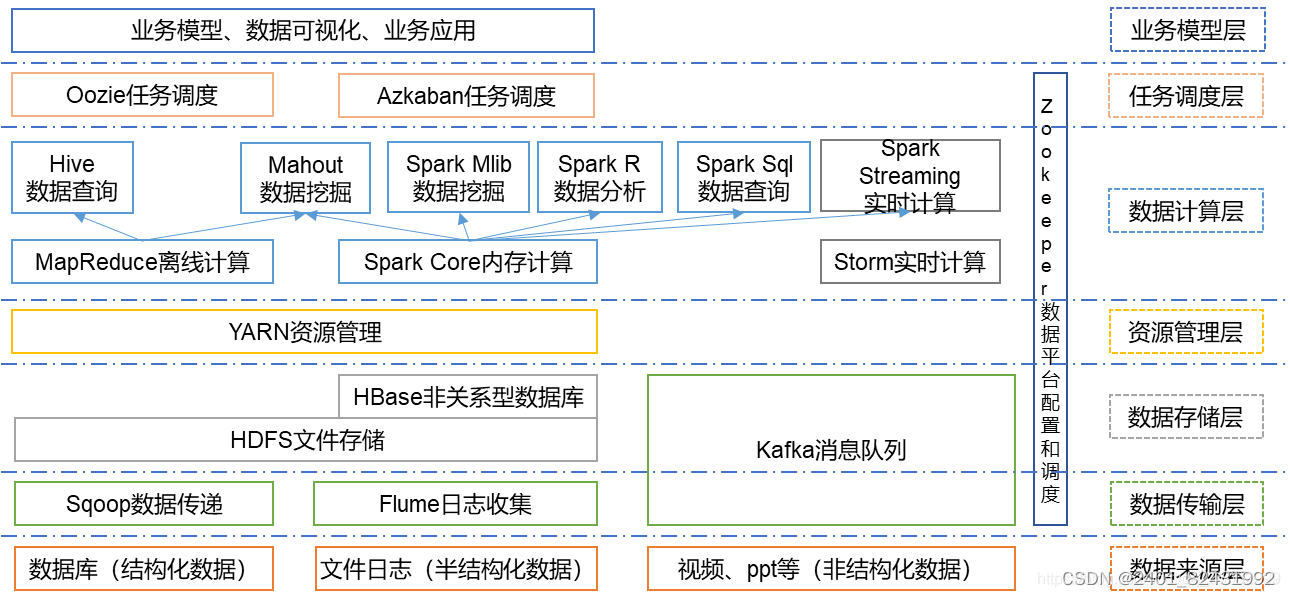
根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层。接下来对Hadoop生态圈中出现的相关组件做一个简要介绍
组件
1、HDFS(分布式文件系统)
HDFS是整个Hadoop体系的基础,负责数据的存储与管理,Hdfs有着高容错性的特点,并且设计用来部署在低廉的硬件上,适合那些有着超大数据集的应用程序。HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。

1.1 client
切分文件,访问HDFS时,首先与NameNode交互,获取目标文件的位置信息,然后与DataNode交互,读写数据
1.2 NameNode
master节点(名称节点),每个HDFS集群只有一个,管理HDFS的名称空间和数据块映射信息,配置相关副本信息,处理客户端请求。
1.3 DataNode
slave节点(数据节点),存储实际数据,并汇报状态信息给NameNode,默认一个文件会备份3份在不同的DataNode中,实现高可靠性和容错性。
1.4 Secondary NameNode
辅助NameNode,实现高可靠性,定期合并fsimage和fsedits,推送给NameNode;紧急情况下辅助和恢复NameNode,但其并非NameNode的热备份。
2、MapReduce(分布式计算框架)
MapReduce是一种基于磁盘的分布式并行批处理的计算模型,用于大数据量的计算。MapReduce是一种基于磁盘的分布式并行批处理的计算模型,用于处理和生成大型数据集,他将计算任务分为两个阶段:map阶段和reduce阶段,MapReduce用于在HDFS上处理大量数据,尤其是批量处理任务。
3、Spark(分布式计算框架)
Spark是一种基于内存的分布式并行计算框架,与MapReduce不同的是-----Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好的适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
二、MapReduce的特点及运行架构
1 MapReduce概述
1.1 定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1.2 特点
优点:
易于编程
良好的扩展性
高容错性
适合PB级以上海量数据的离线处理
缺点
不擅长实时计算(MySQL)
不擅长流式计算:输入数据集是静态的,不能动态变化
不擅长DAG(有向无环图)计算,MR结果输出到 磁盘,造成大量磁盘IO,性能低下
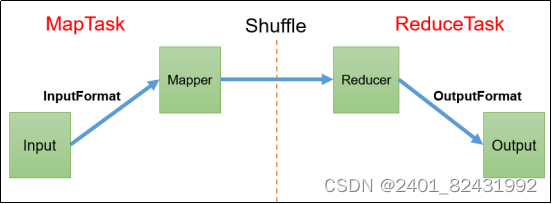
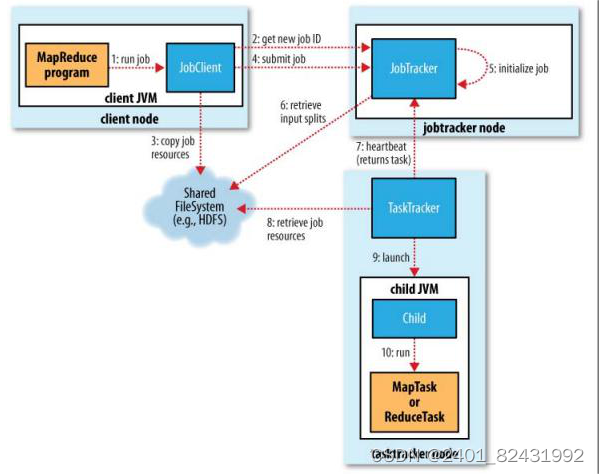
1.3运行架构
三、详细介绍spark的特点,并与MapReduce作对比说明区别
1.spark的特点
(1)运行速度快,如果数据由磁盘读取,速度是hadoop mapreduce的10倍以上,如果数据从内存读取,速度是hadoop mapreduce的100倍以上。主要原因是因为基于内存计算和引入DAG执行引擎。
(2)易用性好,spark支持scala、Python、Java、R等语言快速编写应用。
(3)通用性好,可以与SQL语句、实时计算及其他复杂的分析计算进行良好结合,并包含多个紧密集成的组件。
(4)随处运行
(5)代码简洁,支持Scala、Python等语言编写代码,spark使用Scala语言实现只需一行。
2.MapReduce和Spark的对比
1.通用性
Spark不仅仅可以进行离线计算(SparkCore),同时还可以进行良好结合,Spark框架包含:即席查询(SparkSQL) ,实时流处理(SparkStreaming),图计算(SparkGraphx),机器学习(SparkMLLib),这 是Spark相比较于其它框架最大的优势。可以使用多中语言进行编程
MapReduce主要是擅长离线的计算,不擅长实时计算
2.内存和磁盘的使用情况
Spark是基于RDD,主要使用内存进行储存计算的源数据及过程的数据,避免了写磁盘的IO操作,速度自然比较快
MapReduce基于磁盘的计算,计算的过程中需要大量的溢写磁盘的操作,IO瓶颈比较明显,速度自然不好
3.API
Spark编程过程中系统提供了大量的算子,transformation和action算子,功能之强大是MR无法比拟的,编程自由度比较高
MapReduce的编程API只是提供了 map和reduce的操作,编程局限性比较大,什么操作都需要往规定好的模式上去套,死板
4.系统自由度
Spark给用户提供了诸多的参数进行设置,适应不同场景的应用,比如sort,系统并没有强制进行sort,如果需要可以进行相应参数的设置,去掉自动排序的功能之后提高效率
Mapreduce的shuffle的过程中相当的复杂,虽然shuffle的过程是奇迹发生的地方,但是这里边做的事太多了,很多没有法子去掉,也就是说有可能对于场景无用的操作也做了,比如排序,本身其实我们有可能不需要sort,但是基于MR的特性,它必须依靠sort,这样白白浪费了性能
5.系统容错性
Spark中有个血缘关系,在计算过程中如果出现问题造成数据丢失,系统不用重新计算,只需要根据血缘关系找到最近的中间过程数据进行计算,而且基于内存的中间数据存储增加了再次使用的读取的速度
MapReduce的过程中的中间文件溢写磁盘,如计算过程中出现数据的丢失,只能重新来过.严重影响时效性
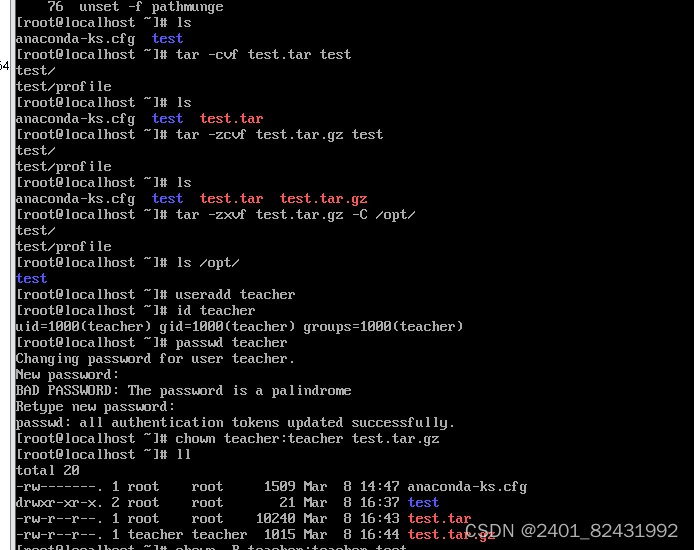
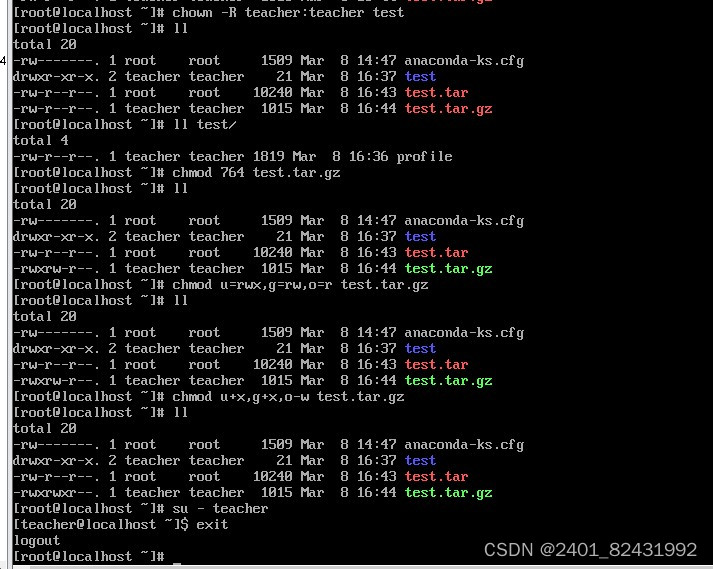
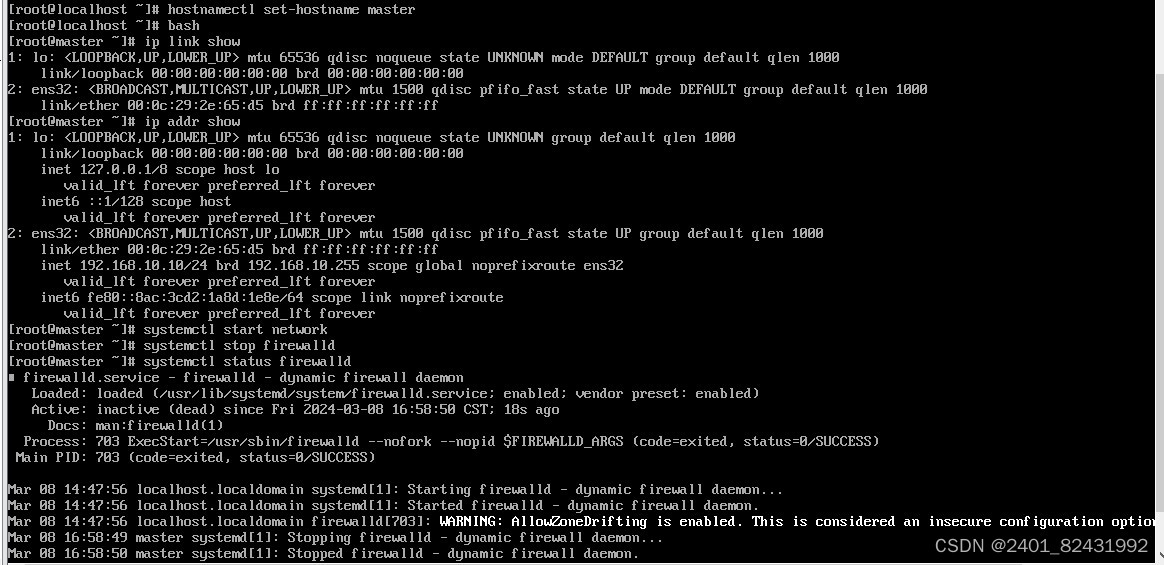
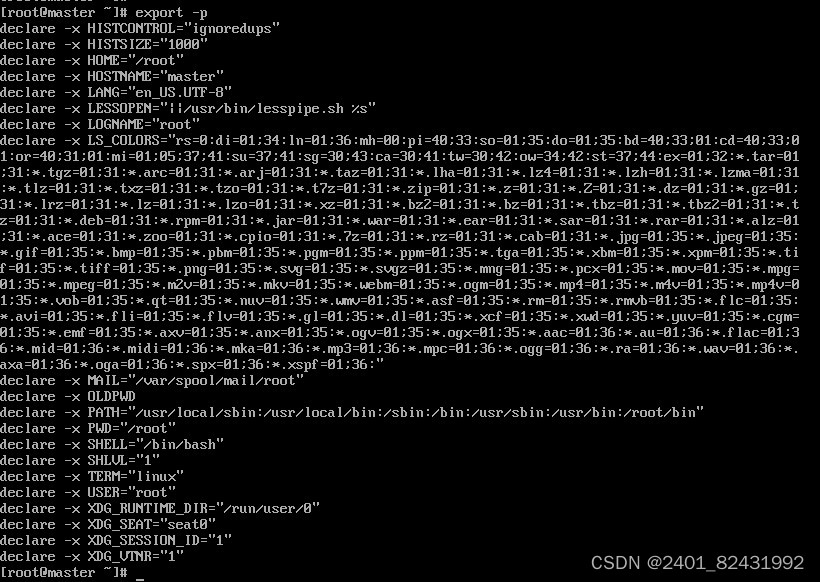
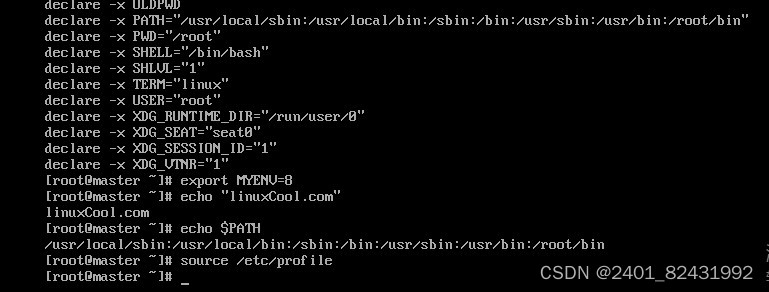
四、熟练掌握Linux操作命令并演示说明

五、介绍冷备 温备 热备
1、热备
热备是指与目标设备共同运转,当目标设备发生故障或停机时,热备设备立即承担起故障设备的工作任务。
2、冷备
冷备是指当目标设备发生故障或停机后,冷备设备才开始由停机等待状态进入启动运转状态,并承担起故障设备的工作任务
冷备优点
备份简单,只需要复制相关文件即可。
恢复简单而且速度快,不需要执行任何 SQL 语句,也不需要重建索引。
3.温备
温备:在数据库运行时加全局读锁备份,保证了备份数据的一致性,但对性能有影响。
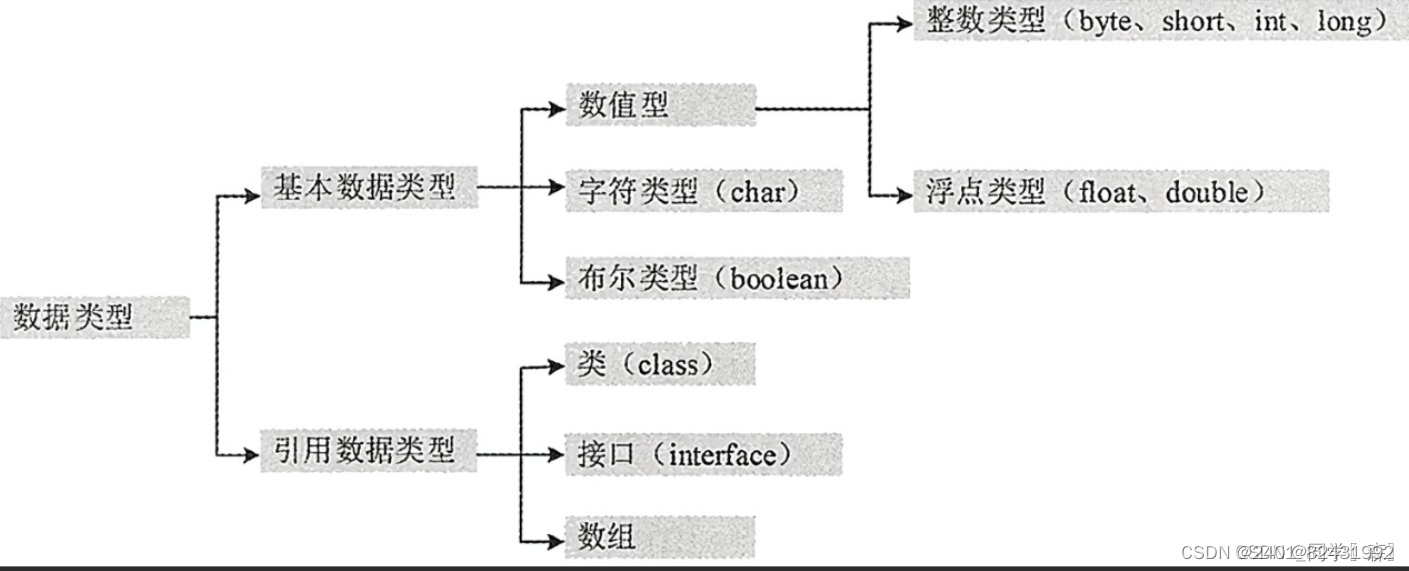
六、数据类型
基本数据类型
字节是计算机中存储的最小单位,一个字节等于八位。1字节 = 8 bit(对应二进制中的位数)
1.整数类型
byte(字节型):1个字节8位
取值范围:-128~127
short(短字符型):2个字节16位
int(整型):4个字节32位
取值范围:-21亿~21亿
long(长整型):8个字节64位
2.浮点类型
float(单精度浮点型):4个字节32位
注意:float的值一定要加上 f
double(双精度浮点型):8个字节64位
3.字符类型
char(字符类型):2个字节16位
取值范围:0~65535
注意:必须使用单引号括起来,只能是一个字符,比如 ‘男’ 或 ‘女’
4.布尔类型
boolean(布尔类型):4个字节32位,只有真-true 和 假-false















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









