






Spark-SQL
一、Spark-SQL是什么
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
其中 SparkSQL 作为 Spark 生态的一员继续发展,而不再受限于 Hive,只是兼容 Hive;而 Hive on Spark 是一个 Hive 的发展计划,该计划将 Spark 作为 Hive 的底层引擎之一,也就是说,Hive 将不再受限于一个引擎,可以采用 Map-Reduce、Tez、Spark 等引擎。 对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发, 提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD
➢ DataFrame
➢ DataSet
二、Spark-SQL 特点
1.易整合。无缝的整合了 SQL 查询和 Spark 编程
2.统一的数据访问。使用相同的方式连接不同的数据源
3.兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL
4.标准数据连接。通过 JDBC 或者 ODBC 来连接
三、DataFrame 是什么
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观 RDD,由于无从得知所存数据元素的具体内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct、array 和 map)。从 API 易用性的角度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的 RDD API 要 更加友好,门槛更低。
四、DataSet 是什么
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)
➢ DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
➢ 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
➢ 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
➢ DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
➢ DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
五、DataFrame
Spark SQL 的 DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表或者生成 SQL 表达式。DataFrame API 既有 transformation 操作也有 action 操作。
创建 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame
有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive
Table 进行查询返回。
➢ 在 spark 的 bin/data 目录中创建 user.json 文件
{"username":"zhangsan","age":20}
{"username":"lisi","age":17}
➢ 读取 json 文件创建 DataFrame
val df = spark.read.json("data/user.json")
df.show
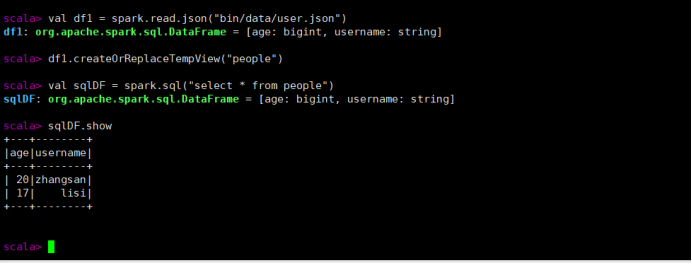
SQL 语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要
有临时视图或者全局视图来辅助
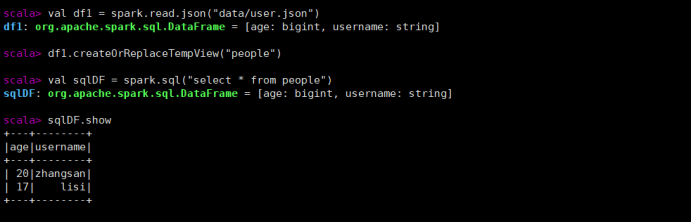
- 读取 JSON 文件创建 DataFrame
val df1 = spark.read.json("data/user.json")
- 对 DataFrame 创建一个临时表
df1.createOrReplaceTempView("people")
- 通过 SQL 语句实现查询全表
val sqlDF = spark.sql("select * from people")
- 结果展示
sqlDF.show
DataFrame
DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。 可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。
- 创建一个 DataFrame
val df = spark.read.json("data/user.json")
- 查看 DataFrame 的 Schema 信息
df.printSchema
- 只查看"username"列数据
df.select("username").show()
- 查看"username"列数据以及"age+1"数据
df.select($"username",$"age" + 1).show
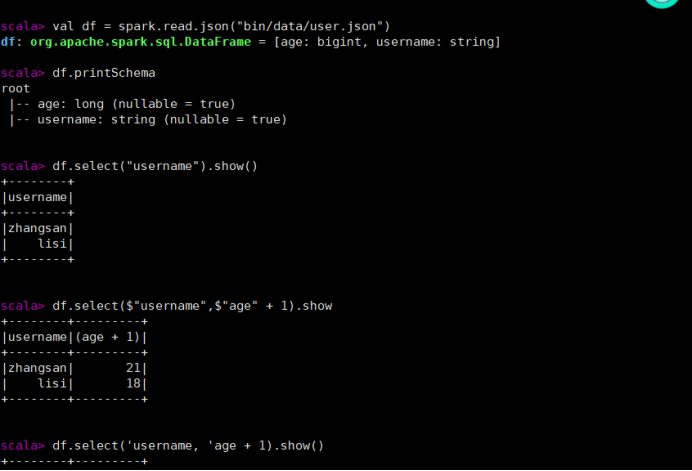
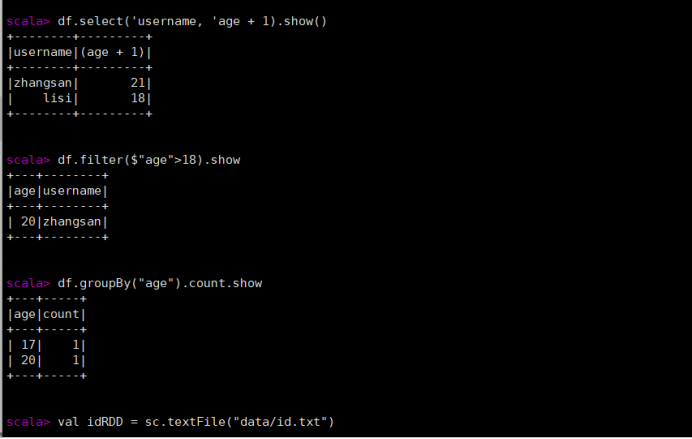
df.select('username, 'age + 1).show()
- 查看"age"大于"18"的数据
df.filter($"age">18).show
- 按照"age"分组,查看数据条数
df.groupBy("age").count.show
RDD 转换为 DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入 import spark.implicits._ 这里的 spark 不是 Scala 中的包名,而是创建的 sparkSession 对象的变量名称,所以必 须先创建 SparkSession 对象再导入。这里的 spark 对象不能使用 var 声明,因为 Scala 只支持 val 修饰的对象的引入。
spark-shell 中无需导入,自动完成此操作。
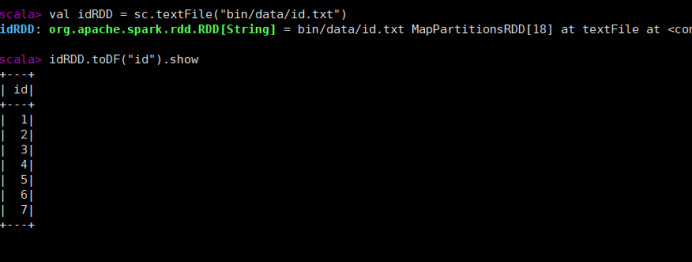
val idRDD = sc.textFile("data/id.txt")

idRDD.toDF("id").show
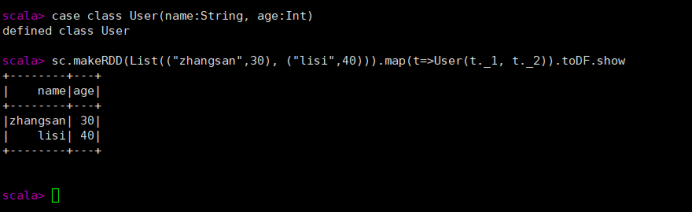
实际开发中,一般通过样例类将 RDD 转换为 DataFrame
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF.show
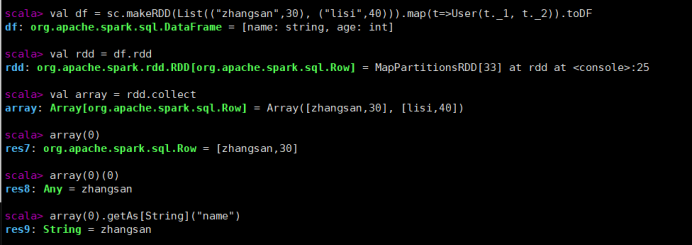
DataFrame 转换为 RDD
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF
val rdd = df.rdd
val array = rdd.collect
array(0)
array(0)(0)
array(0).getAs[String]("name")
第三章第四节 Spark-SQL核心编程(三)
DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
创建 DataSet
1) 使用样例类序列创建 DataSet
case class Person(name: String, age: Long)
val caseClassDS = Seq(Person("zhangsan",2)).toDS()

caseClassDS.show

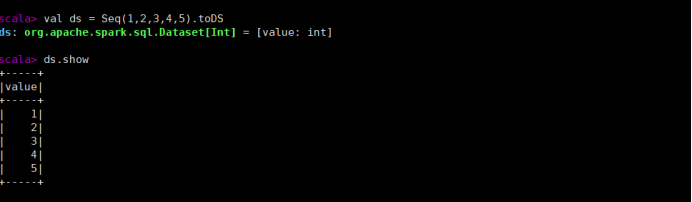
2) 使用基本类型的序列创建 DataSet
val ds = Seq(1,2,3,4,5).toDS
ds.show
RDD 转换为 DataSet
SparkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet,case 类定义了 table 的结 构,case 类属性通过反射变成了表的列名。Case 类可以包含诸如 Seq 或者 Array 等复杂的结构。
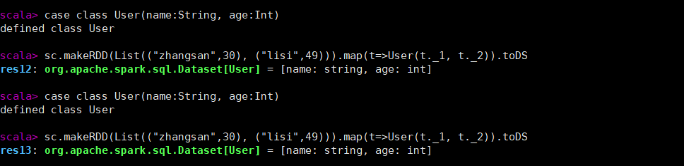
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS

DataSet 转换为 RDD
DataSet 其实也是对 RDD 的封装,所以可以直接获取内部的 RDD
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS
val rdd = res3.rdd
rdd.collect

DataFrame 和 DataSet 转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的。
DataFrame 转换为 DataSet
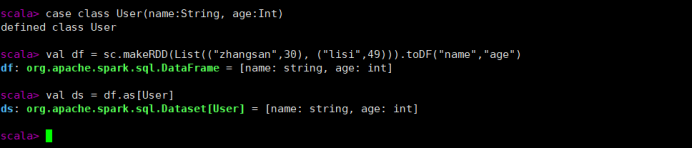
case class User(name:String, age:Int)
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",49))).toDF("name","age")
val ds = df.as[User]
DataSet 转换为 DataFrame
val ds = df.as[User]
val df = ds.toDF

RDD、DataFrame、DataSet 三者的关系
在 SparkSQL 中 Spark 为我们提供了两个新的数据抽象,分别是 DataFrame 和 DataSet。他们 和 RDD 有什么区别呢?
首先从版本的产生上来看:
➢ Spark1.0 => RDD
➢ Spark1.3 => DataFrame
➢ Spark1.6 => Dataset
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不
同是的他们的执行效率和执行方式。在后期的 Spark 版本中,DataSet 有可能会逐步取代 RDD和 DataFrame 成为唯一的 API 接口。
三者的共性
➢ RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利;
➢ 三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到
Action 如 foreach 时,三者才会开始遍历运算;
➢ 三者有许多共同的函数,如 filter,排序等;
➢ 在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:
import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
➢ 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会
内存溢出
➢ 三者都有分区(partition)的概念
➢ DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的区别
1) RDD
➢ RDD 一般和 spark mllib 同时使用
➢ RDD 不支持 sparksql 操作
2) DataFrame
➢ 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为Row,每一列的值没法直
接访问,只有通过解析才能获取各个字段的值
➢ DataFrame 与 DataSet 一般不与 spark mllib 同时使用
➢ DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能
注册临时表/视窗,进行 sql 语句操作
➢ DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表
头,这样每一列的字段名一目了然
3) DataSet
➢ Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪
些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性里提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息。
三者可以通过上图的方式进行相互转换。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









