






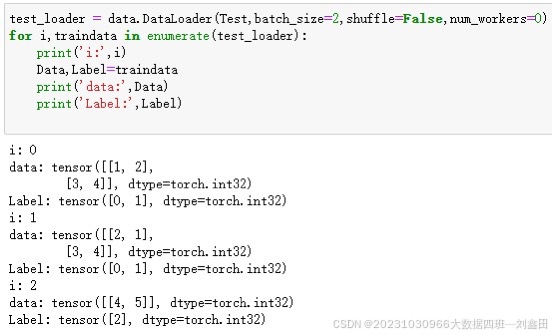
课堂总结:
DataLoader:可以批量处理。
语法结构如右所示。
data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
)
DataLoader:可以批量处理。相关参数介绍如下所示。
| dataset | 加载的数据集。 |
| batch_size | 批大小。 |
| shuffle | 是否将数据打乱。 |
| sampler | 样本抽样。 |
| num_workers | 使用多进程加载的进程数,0代表不使用多进程。 |
| collate_fn | 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可。 |
| pin_memory | 是否将数据保存在锁页内存(pin memory区),其中的数据转到GPU会快一些。 |
| drop_last | dataset 中的数据个数可能不是 batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。 |
DataLoader:可以批量处理。
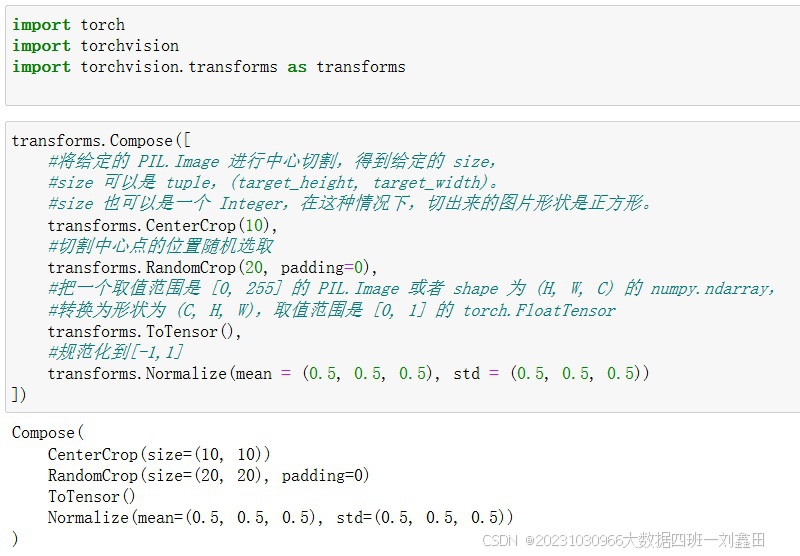
提供了对PIL Image对象和Tensor对象的常用操作。
2)对Tensor的常见操作如下
如果要对数据集进行多个操作,可通过Compose将这些操作像管道一样拼接起来,类似于nn.Sequential
transforms提供了对PIL Image对象和Tensor对象的常用操作。
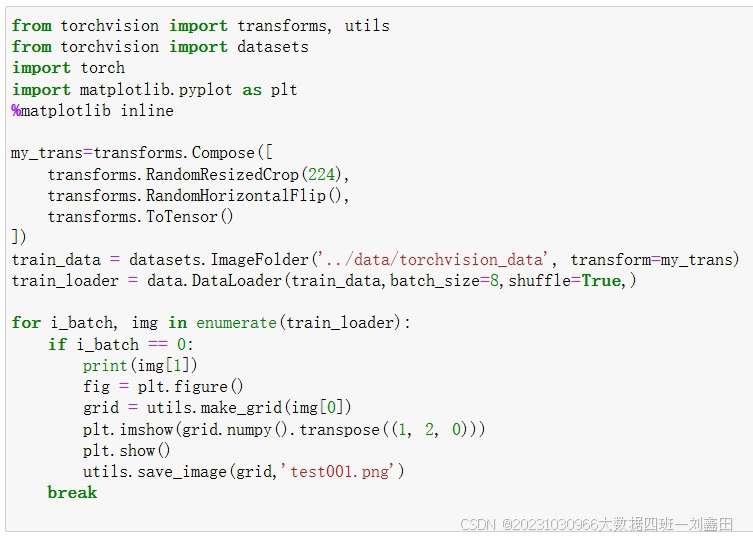
ImageFolder可以读取不同目录下的图像数据。
TensorBoard简介
TensorBoard的使用一般步骤如下。
1) 导入tensorboard,实例化SummaryWriter类,指明记录日志路径等信息
from torch.utils.tensorboard import SummaryWriter
#实例化SummaryWriter,并指明日志存放路径。在当前目录没有logs目录将自动创建。
writer = SummaryWriter(log_dir='logs')
#调用实例
writer.add_xxx()
#关闭writer
writer.close()
使用TensorBoard的一般步骤如下。
2)调用相应的API接口,接口一般格式为:
add_xxx(tag-name, object, iteration-number)
#即add_xxx(标签,记录的对象,迭代次数)
使用TensorBoard的一般步骤如下。
3)启动tensorboard服务。cd到logs目录所在的同级目录,在命令行输入如下命令,logdir等式右边可以是相对路径或绝对路径。
tensorboard --logdir=logs --port 6006
#如果是windows环境,要注意路径解析,如
#tensorboard --logdir=r'D:\myboard\test\logs' --port 6006
4)Web展示。在浏览器输入:
http://服务器IP或名称:6006 #如果是本机,服务器名称可以使用localhost
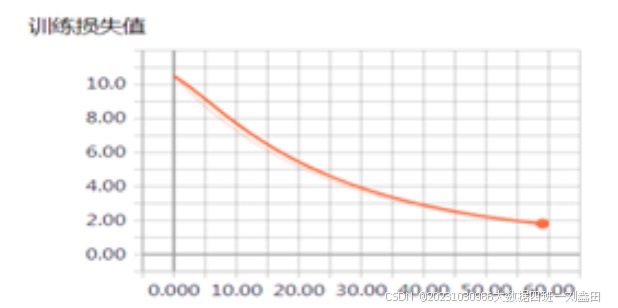
用TensorBoard可视化损失值

运行结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









