






- **标识号:**在消息的定义中,每个字段等号后面都有唯一的标识号,用于在反序列化过程中识别各个字段的,一旦开始使用就不能改变。标识号从整数1开始,依次递增,每次增加1,标识号的范围为1~(2^99)-1,其中[19000-19999]为Protobuf协议预留字段,开发者不建议使用该范围的标识号;一旦使用,在编译时Protoc编译器会报出警告。
- **字段规则:**字段规则有三种:
- 1、required:该规则规定,消息体中该字段的值是必须要设置的。
- 2、optional:消息体中该规则的字段的值可以存在,也可以为空,optional的字段可以根据defalut设置默认值。
- repeated:消息体中该规则字段可以存在多个(包括0个),该规则对应java的数组或者go语言的slice。
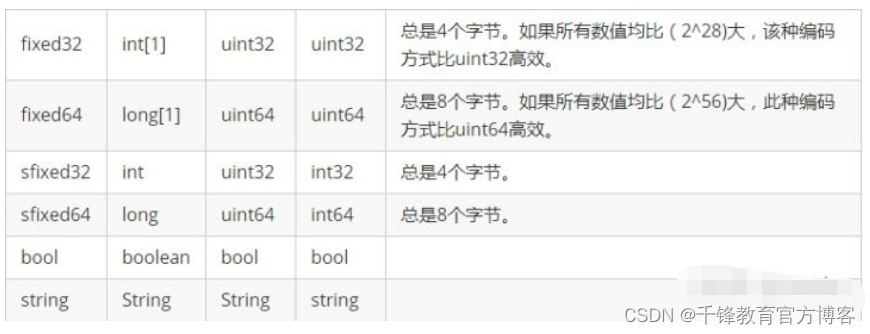
- **数据类型:**常见的数据类型与protoc协议中的数据类型映射如下:

- **枚举类型:**proto协议支持使用枚举类型,和正常的编程语言一样,枚举类型可以使用enum关键字定义在.proto文件中:
enum Age{
male=1;
female=2;
}
- 字段默认值:.proto文件支持在进行message定义时设置字段的默认值,可以通过default进行设置,如下所示:
message Address {
required sint32 id = 1 [default = 1];
required string name = 2 [default = '北京'];
optional string pinyin = 3 [default = 'beijing'];
required string address = 4;
required bool flag = 5 [default = true];
}
- **导入:**如果需要引用的message是写在别的.proto文件中,可以通过import "xxx.proto"来进行引入:
- **嵌套:**message与message之间可以嵌套定义,比如如下形式:
syntax = "proto2";
package example;
message Person {
required string Name = 1;
required int32 Age = 2;
required string From = 3;
optional Address Addr = 4;
message Address {
required sint32 id = 1;
required string name = 2;
optional string pinyin = 3;
required string address = 4;
}
}
- **message更新规则:**message定义以后如果需要进行修改,为了保证之前的序列化和反序列化能够兼容新的message,message的修改需要满足以下规则:
- 不可以修改已存在域中的标识号。
- 所有新增添的域必须是 optional 或者 repeated。
- 非required域可以被删除。但是这些被删除域的标识号不可以再次被使用。
- 非required域可以被转化,转化时可能发生扩展或者截断,此时标识号和名称都是不变的。
- sint32和sint64是相互兼容的。
- fixed32兼容sfixed32。 fixed64兼容sfixed64。
- optional兼容repeated。发送端发送repeated域,用户使用optional域读取,将会读取repeated域的最后一个元素。
Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf 采用的非常巧妙的 Encoding 方法。接下来看一看Protobuf协议是如何实现高效编码的。
Protobuf序列化原理
之前已经做过描述,Protobuf的message中有很多字段,每个字段的格式为:修饰符 字段类型 字段名 = 域号;
Varint
本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份我自己整理的网络安全入门工具以及使用教程和实战。
项目实战
最后就是项目实战,这里带来的是SRC资料&HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









