






本期学习活动我们一起来看一下数学建模导论的后半部分,使用语言为Python,本教程开源地址:
https://github.com/datawhalechina/intro-mathmodel
这一章我们主要介绍评价模型。评价类模型是初次接触数学建模竞赛的同学非常喜爱的一类题型,因为代码量小,原理通俗易懂。这类问题主要是用以解决对于一个目标不同方案之间比较或不同影响因素之间比较的问题。
7.1 层次分析法
7.1.1 原理
首先,层次分析法的流程分五步走:
1.选择指标,构建层次模型。
2.对目标层到准则层之间和准则层到方案层之间构建比较矩阵。
3.对每个比较矩阵计算CR值检验是否通过CR检验,如果没有通过检验需要调整比较矩阵。
4.求出每个矩阵最大的特征值对应的归一化权重向量。
5.根据不同矩阵的归一化权向量计算出不同方案的得分进行比较。
首先第一步,选择指标。针对评价类问题,可能会给出一些评价的指标准则,但很多情况下它并不会给你明确的指标。这个时候就需要我们自己去找合适的指标,当然不可能随便编,需要经过大量文献考证或社会调查后选取的,或者发放问卷获取数据。把指标按照一定的层级结构组织起来就构成了一个指标体系。
接下来是构建层次模型。那么“层次”是什么?从结构上看,层次分析法将模型大致分为目标层、准则层和方案层。目标层是你的评价目标,准则层是你的评价指标体系,方案层是多个对比方案。注意,方案层是一定要有多个对象进行比较的,因为层次分析法是基于比较的方法。
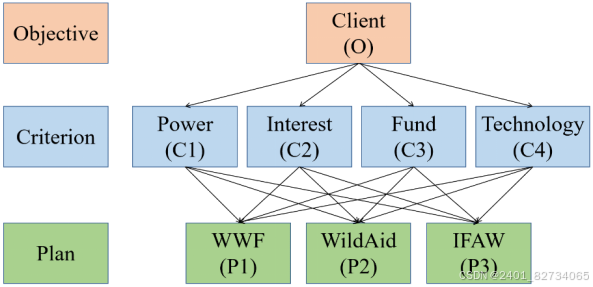
例如本图中就是利用层次分析法选择合适的委托组织进行野生动物保护,从上往下三个颜色分别是目标层、准则层、方案层。
两个相邻的层次之间是需要构建成对比较矩阵的。比方说在上图,我们在目标层和准则层之间就需要构建第一层比较矩阵,这个矩阵的大小是行列均为4。矩阵的每一项表示因素和因素
的相对重要程度。由于对角线上元素都是自己和自己做比较,所以对角线上元素为1。另外,还有一条重要性质:
关于这个矩阵的每一项取值多少,若因素笔因素
重要,为了描述重要程度,我们用1~9中间的整数描述,如下表所示:
| 取值 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 相对重要程度 | 同等重要 | 介于1、3之间 | 相对重要一些 | 介于3、5之间 | 相对比较重要 | 介于5、7之间 | 相比明显重要 | 介于7、9之间 | 相比非常重要 |
这个比较矩阵每一项的确定具有较强的主观性,因为究竟二者重要程度是比较重要还是非常重要也是不同的人可能有不同的理解。
注意:通常来说,对重要性的取值都是取奇数,也就是1、3、5、7、9,偶数是当你不太确定,也就是认为介于两个奇数程度之间时再取偶数。
除了准则层外,方案层也需要构建成对比较矩阵。但不同的是,假如有个准则
个样本,需要构建的矩阵数量为
,矩阵大小为
。每个成对比较矩阵是需要我们自己手动确定的。在人工商定了这些成对比较矩阵后,接下来的操作是对每个成对比较矩阵进行一致性检验。在前面我们已经知道如何对矩阵进行特征值分解,那么对于成对比较矩阵可以很容易地计算出它最大的特征值及其对应的特征向量。那么,定义
值:
这里取4的话很容易计算出
值为0.0145。而除了
,还有一个
值(随机一致性指标),在不同的
的取值下
值也不同。这个值是通过大量随机实验得到的统计规律,数值可以查表获得,将
表列在下表中。
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.52 | 0.89 | 1.12 | 1.26 | 1.32 |
| n | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| RI | 1.41 | 1.46 | 1.49 | 1.52 | 1.54 | 1.56 | 1.58 |
计算CI和RI的比值也就是CR。查表计算可以得到这个矩阵的CR值为0.0161。通常来说,当CR值超过0.1时,就可以认为这个矩阵是不合理的,需要被修改、被调整。这里由于没有超过这个阈值,所以可以认为这个比较矩阵通过了一致性检验。于是,剩下的过程便可以如法炮制,计算出准则层到方案层的4个矩阵了。
得到一致性检验结果后,还需要对最大特征值对应的特征向量进行归一化得到权重向量。归一化的方法为将特征向量除以该向量所有元素之和:
最终可以得到每个指标的权重,以及每个样本在不同指标上的归一化得分。通过加权折算就可以得到评价的最终分数。
7.1.2 案例
例:某日从三条河流的基站处抽检水样,得到了水质的四项检测指标如表所示。请根据提供数据对三条河流的水质进行评价。其中,DO代表水中溶解氧含量,越大越好;CODMn表示水中高锰酸盐指数,NH3-N表示氨氮含量,这两项指标越小越好;pH值没有量纲,在6~9区间内较为合适。
| 地点名称 | pH* | DO | CODMn | NH3-N |
|---|---|---|---|---|
| 四川攀枝花龙洞 | 7.94 | 9.47 | 1.63 | 0.077 |
| 重庆朱沱 | 8.15 | 9.00 | 1.4 | 0.417 |
| 湖北宜昌南津关 | 8.06 | 8.45 | 2.83 | 0.203 |
该评价问题一共有三个样本,四个评价指标。不同的评价指标还不太一样,有的越大越好有的越小越好。
我们构建层次模型图:
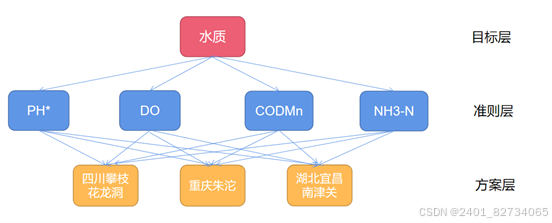
接下来的操作就是对目标层到准则层构建一个大小为4的方阵,准则层到方案层构建4个大小为3的方阵。我们先来计算一下这个目标层到准则层,至于准则层到方案层的矩阵都是如法炮制的过程。例如,创建了这么一个矩阵:
| 变量 | pH* | DO | CODMn | NH3-N |
|---|---|---|---|---|
| pH* | 1 | 1/5 | 1/3 | 1 |
| DO | 5 | 1 | 3 | 5 |
| CODMn | 3 | 1/3 | 1 | 3 |
| NH3-N | 1 | 1/5 | 1/3 | 1 |
对这个矩阵做特征值分解的代码如下:
# -*- coding: gbk -*-
import numpy as np
# 构建矩阵
A = np.array([[1, 1/5, 1/3, 1],
[5, 1, 3, 5],
[3, 1/3, 1, 3],
[1, 1/5, 1/3, 1]])
# 获得指标个数
m = len(A)
n = len(A[0])
RI = [0, 0, 0.58, 0.90, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49, 1.51]
# 求判断矩阵的特征值和特征向量,V为特征值,D为特征向量
V, D = np.linalg.eig(A)
list1 = list(V)
# 求矩阵的最大特征值
B = np.max(list1)
index = list1.index(B)
C = D[:, index] # 修正了这里,使用大写的 D
print("最大特征值:", B)
print("对应的特征向量:", C)运行结果为:

很容易地,我们定位到了最大的特征值与特征向量。进而我们计算CI和CR,代码与完整结果如下:
CI=(B-n)/(n-1)
CR=CI/RI[n]
if CR<0.10:
print("CI=",CI)
print("CR=",CR)
print("对比矩阵A通过一致性检验,各向量权重向量Q为:")
C_sum=np.sum(C)
Q=C/C_sum
print(Q)
else:
print("对比矩阵A未通过一致性检验,需对对比矩阵A重新构造")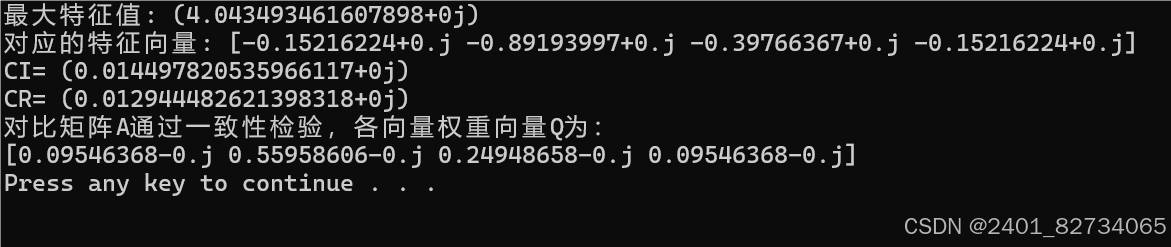
计算出目标层到准则层的1个权重向量和4个准则层到方案层的权重向量以后,可以列出表将权重向量进行排布。
| 地点名称 | pH* | DO | CODMn | NH3-N | 得分 |
|---|---|---|---|---|---|
| 0.0955 | 0.5596 | 0.2495 | 0.0955 | ||
| 四川攀枝花龙洞 | 0.4166 | 0.5396 | 0.2970 | 0.6370 | 0.4767 |
| 重庆朱沱 | 0.3275 | 0.2970 | 0.5396 | 0.1047 | 0.3421 |
| 湖北宜昌南津关 | 0.2599 | 0.1634 | 0.1634 | 0.2583 | 0.1817 |
将准则层到方案层得到的7个成对比较矩阵对应的权重向量排列为一个矩阵,矩阵的每一行表示对应的方案,矩阵的每一列代表评价准则。将这一方案权重矩阵与目标层到准则层的权重向量进行数量积,得到的分数就是最终的评分。最终得到的一个结论是:在评价过程中水中溶解氧含量与钴金属含量占评价体系比重最大,而四川攀枝花龙洞的水质虽然含钴元素比另外两个更高,但由于溶解氧更多,NH3-N的含量更小,水体不显富营养化。就整体而言,四川攀枝花龙洞得分高于重庆朱沱和湖北宜昌南津关。
7.2 熵权分析法
7.2.1 原理
熵权法是一种客观赋权方法,基于信息论的理论基础,根据各指标的数据的分散程度,利用信息熵计算并修正得到各指标的熵权,较为客观。相对而言这种数据驱动的方法就回避了上面主观性因素造成的重复修正的影响。
在7.1的案例中,我们发现:衡量好坏的标准因指标而异。由于指标的多样性,有些指标越大越好,如成绩;有些越小越好,如房贷;有些在特定区间过高或过低都不佳,如血压;还有些存在最优值,偏差越大越差。
若模型未经数据预处理直接计算,可能出现问题。因此,第一步是指标正向化。它涉及将原本的负向指标转为正向指标,例如将死亡率转为生存率、故障率转为可靠度。通过正向化,目标或结果的达成情况更直观,提高指标的可解释性和可操作性。
-
对于极大型指标:指标越大越好,不需要正向化。只需要通过min-max规约或Z-score规约进行规约即可。
-
对于极小型指标:此类指标越小越好。它的正向化方式比较简单,可以取相反数;如果指标全部为正数,也可以取其倒数。
-
对于区间型指标:它的规约方法遵循下面的式子。
-
对于中值型指标:它的正向化操作为:
在进行指标正向化以后,所有的指标全部被变换为越大越好。而为了进一步消除量纲这些的影响,需要进一步进行min-max规约化或z-score规约化消除量纲差异。
熵权法的主要计算步骤如下。
(1)构建m个事物n个评价指标的判断矩阵R(i=1,2,3,…,n;j=1,2,…,m)
(2)将判断矩阵进行归一化处理,得到新的归一化判断矩阵B。
(3)熵权法可利用信息熵计算出各指标的权重,从而为多指标评价提供依据。
(4)计算权重系数。
7.2.2 案例
在例7.1的基础上采集到了更多基站的数据,现在需要对指标进行熵值赋权。新的数据表格如表所示。
| 地点名称 | pH* | DO | CODMn | NH3-N | 鱼类密度 | 垃圾密度 |
|---|---|---|---|---|---|---|
| 四川攀枝花龙洞 | 7.94 | 9.47 | 1.63 | 0.08 | 6.78 | 4.94 |
| 重庆朱沱 | 8.15 | 9.00 | 1.40 | 0.42 | 5.27 | 4.47 |
| 湖北宜昌南津关 | 8.06 | 8.45 | 2.83 | 0.20 | 2.50 | 7.03 |
| 湖南岳阳城陵矶 | 8.05 | 9.16 | 3.33 | 0.29 | 5.65 | 5.26 |
| 江西九江河西水厂 | 7.60 | 7.93 | 2.07 | 0.13 | 5.26 | 6.39 |
| 安徽安庆皖河口 | 7.39 | 7.12 | 2.23 | 0.20 | 6.21 | 7.50 |
| 江苏南京林山 | 7.74 | 7.29 | 1.77 | 0.06 | 6.44 | 3.93 |
| 四川乐山岷江大桥 | 7.38 | 6.51 | 3.63 | 0.41 | 3.17 | 5.75 |
| 四川宜宾凉姜沟 | 8.32 | 8.47 | 1.60 | 0.14 | 3.32 | 6.29 |
| 四川泸州沱江二桥 | 7.69 | 8.50 | 2.73 | 0.28 | 7.25 | 8.21 |
| 湖北丹江口胡家岭 | 8.15 | 9.88 | 2.00 | 0.08 | 7.22 | 3.82 |
| 湖南长沙新港 | 6.88 | 7.59 | 1.77 | 0.92 | 2.94 | 8.03 |
| 湖南岳阳岳阳楼 | 8.00 | 8.15 | 4.87 | 0.33 | 4.68 | 5.01 |
| 湖北武汉宗关 | 7.94 | 7.48 | 3.30 | 0.13 | 5.81 | 4.87 |
| 江西南昌滁槎 | 8.01 | 7.76 | 2.67 | 6.36 | 4.52 | 3.22 |
| 江西九江蛤蟆石 | 7.91 | 7.93 | 5.47 | 0.21 | 7.48 | 2.40 |
| 江苏扬州三江营 | 8.04 | 8.34 | 3.87 | 0.20 | 3.73 | 4.05 |
首先,读取数据并对指标进行正向化。首先,pH这一列虽然是区间型指标,但是可以用pH=7作为最优值将其看作中间值型指标处理,与7的偏差越大则得分越小。DO和鱼类密度是极大型指标,剩下三个是极小型指标,所以用倒数的方法正向化。
import numpy as np
import pandas as pd
# 确保文件路径正确
file_path = "test.xlsx" # 或者使用完整路径
try:
# 读取 Excel 文件
newdata = pd.read_excel(file_path, sheet_name='Sheet5')
except FileNotFoundError:
print(f"文件 {file_path} 未找到,请检查文件名和路径。")
else:
# 数据处理
newdata['pH*'] = 1 - abs(newdata['pH*'] - 7)
newdata['CODMn'] = 1 / newdata['CODMn']
newdata['NH3-N'] = 1 / newdata['NH3-N']
newdata['垃圾密度'] = 1 / newdata['垃圾密度']
newdata = newdata.set_index('地点名称').dropna()
# 定义熵权法函数
def entropyWeight(data):
data = np.array(data)
# 归一化
P = data / data.sum(axis=0)
# 计算熵值
E = np.nansum(-P * np.log(P) / np.log(len(data)), axis=0)
# 计算权系数
return (1 - E) / (1 - E).sum()
# 示例:计算权系数(假设 newdata 是一个 DataFrame)
weights = entropyWeight(newdata)
print("权系数:", weights)通过调用函数,可以得到权重分别为:

7.3 TOPSIS分析法
7.3.1 原理
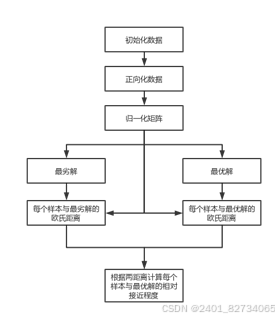
TOPSIS评价法是有限方案多目标决策分析中常用的一种科学方法,其基本思想为,对原始决策方案进行归一化,然后找出最优方案和最劣方案,对每一个决策计算其到最优方案和最劣方案的欧几里得距离,然后再计算相似度。若方案与最优方案相似度越高则越优先。
在TOPSIS分析法中,我们通过计算每个方案离理想解和负理想解的距离来判断优劣。理想解是最佳方案,各项指标最优;负理想解是最差方案,各项指标最差。这种方法就像“近朱者赤近墨者黑”,离最好的方案越近,表现就越优秀,离最差的方案越远,表现就越差。简化多个指标问题为距离问题,如图所示。
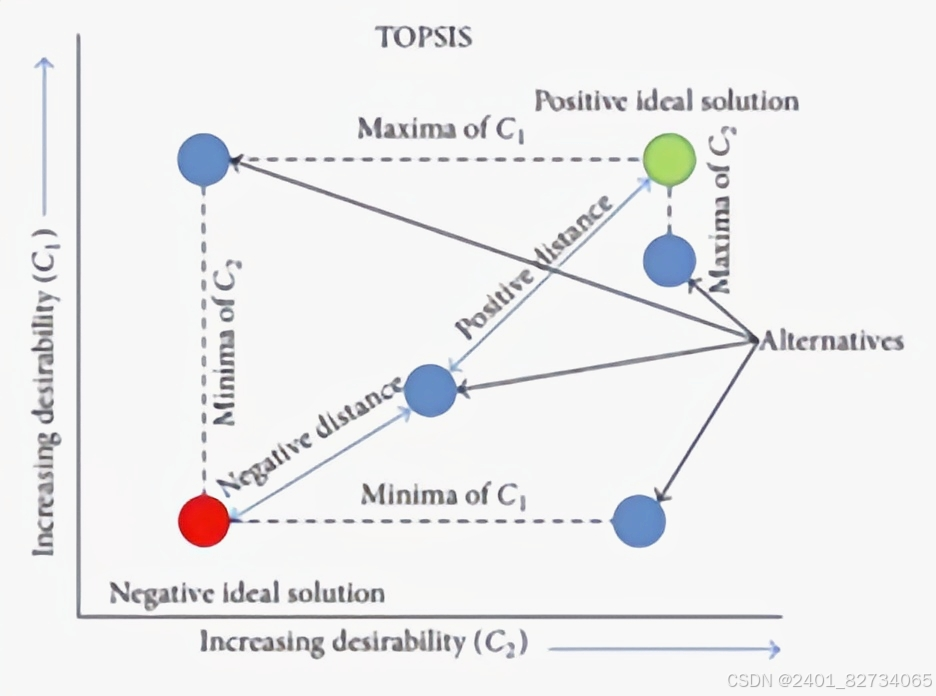
对于距离,有多种方式可以衡量它。包括最常用的欧几里得距离、曼哈顿距离、余弦距离等多种计算方式。
TOPSIS分析法的基本流程为:
-
数据预处理:
对原始数据进行指标正向化和归一化操作得到矩阵 Z。 -
确定理想解:
确定正理想解和负理想解
:
-
计算距离:
计算各评价对象 i 到正理想解和负理想解的欧几里得距离
4. 计算相似度:
计算各评价对象的相似度:
5. 结果排序:
根据 大小排序可得到结果。
7.3.2 案例
仍然以例7.2为例,实现TOPSIS代码如下:
import numpy as np
import pandas as pd
#TOPSIS方法函数
def TOPSIS(A1,w):
Z=np.array(A1)
#计算正、负理想解
Zmax=np.ones([1,A1.shape[1]],float)
Zmin=np.ones([1,A1.shape[1]],float)
for j in range(A1.shape[1]):
if j==1:
Zmax[0,j]=min(Z[:,j])
Zmin[0,j]=max(Z[:,j])
else:
Zmax[0,j]=max(Z[:,j])
Zmin[0,j]=min(Z[:,j])
#计算各个方案的相对贴近度C
C=[]
for i in range(A1.shape[0]):
Smax=np.sqrt(np.sum(w*np.square(Z[i,:]-Zmax[0,:])))
Smin=np.sqrt(np.sum(w*np.square(Z[i,:]-Zmin[0,:])))
C.append(Smin/(Smax+Smin))
C=pd.DataFrame(C)
return C利用上一节里面讲到的归一化方法进行数据处理并通过熵权法获得权重,调用代码可以得到最终结果。得分最高的是江苏南京林山,为0.657;得分最低的是湖北宜昌南津关,得分仅0.232。
可以看到,TOPSIS方法与层次分析法和熵权法都不同,它不是一个构造权重的方法,而是根据权重去进行得分折算的方法。这为我们分析评价类模型提供了一个新思路。
7.4 CRITIC方法
7.4.1 原理
一种基于数据波动性的客观赋权法。其思想在于两项指标,分别是波动性(对比强度)和 冲突性(相关性)指标。对比强度使用标准差进行表示,如果数据标准差越大说明波动越大,权重会越高; 冲突性使用相关系数进行表示,如果指标之间的相关系数值越大,说明冲突性越小,那么其权重也就越低。权重计算时,对比强度与冲突性指标相乘,并且进行归一化处理,即得到最终的权重。CRITIC权重法适用于数据稳定性可视作一种信息,并且分析的指标或因素之间有着一定的关联关系的数据。
数学原理不赘叙,以应用为主。
7.4.2 案例
还是以例7.2为例,代码如下
def CRITIC(df):
std_d=np.std(df,axis=1)
mean_d=np.mean(df,axis=1)
cor_d=np.corrcoef(df)
# 也可以使用df.corr()
w_j=(1-cor_d).sum(0) *std_d
print(w_j)
w=(mean_d/(1-mean_d)*w_j)/sum(mean_d/(1-mean_d)*w_j)
print(w)经过计算,结果为:
pH* 0.180598
DO 0.199151
CODMn 0.185891
NH3-N 0.097907
鱼类密度 0.248081
垃圾密度 0.0883727.5 主成分分析法
7.5.1 原理
在CRITIC方法一节中我们看到了一个事实:数据列之间是存在关联的。例如,在分析数据时,有一列数据是用kg表示的重量,一列数据是用g表示的重量,两列数据的信息是一样的,所以完全可以去掉其中一列。这是个极限情况,但是事实上数据中确实可能存在相关性很高的几列,原本10列的数据集,实际上用3列就有可能表示了。如果能够通过删减或变换的方式减少列数,那么处理的难度可就大大减小了。这种操作被称为降维。
另外,即使不去减少列数,削弱相关性也是很重要的操作。例如,我们看下面这张图:
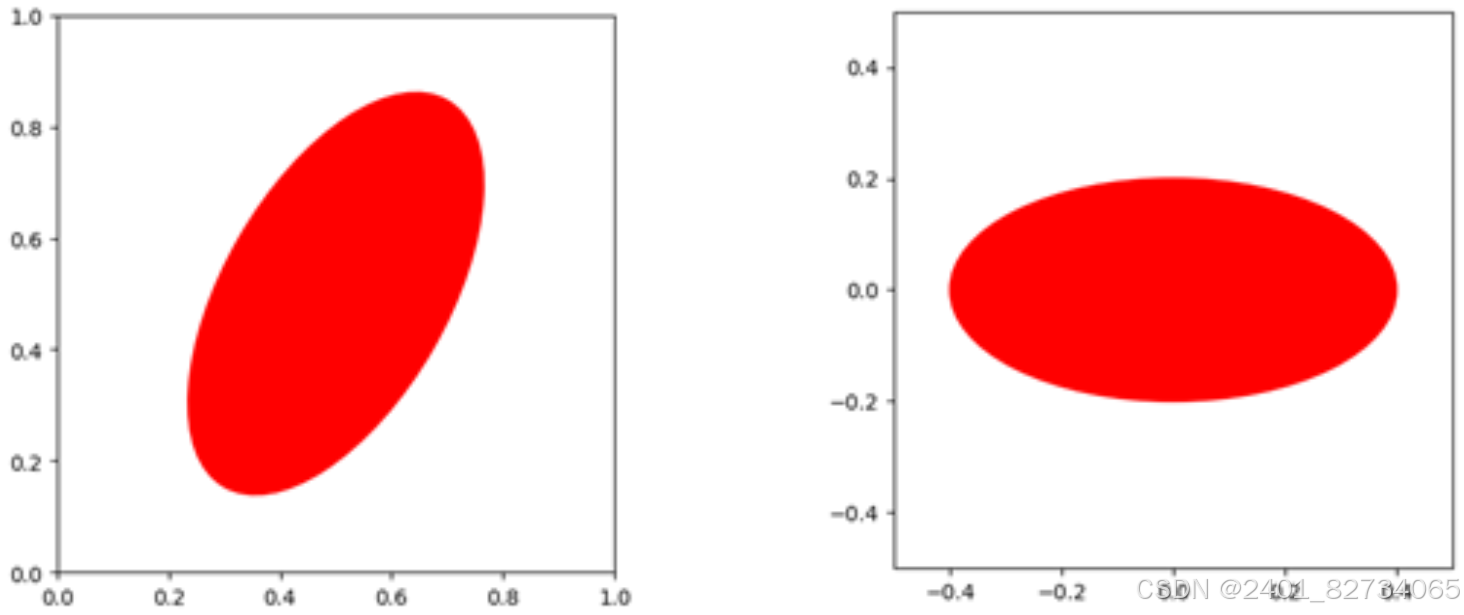
通过变换将其修正到正交基下的椭圆,后续的处理就比斜着的椭圆更好处理了。所以,哪怕变量个数不会减少,削弱相关性的操作仍然是很重要的。
主成分分析的主要目的是希望用较少的变量去解释原来资料中的大部分变异,将原始数据中许多相关性较高的变量转化成彼此相互独立或不相关的变量。通常是选出比原始变量个数少,能解释大部分资料中的变异的几个新变量(也就是主成分)。因此,我们可以知道主成分分析的一般目的是:
(1)数据的降维
(2)主成分的解释
主成分分析(PCA)包括以下几个步骤:
-
数据的去中心化:对数据表 X 中每个属性减去这一列的均值。这样做的目的在于消除数据平均水平对它的影响。
-
求协方差矩阵:注意这里需要除以 n−1。
-
对协方差矩阵进行特征值分解。
-
特征值排序:挑选更大的 k 个特征值,将特征向量组成矩阵 P。
-
进行线性变换 F=PX,从而得到主成分分析后的矩阵。矩阵中的每一列称作一个主成分,选择的特征值经过归一化就变成了权重。
7.5.2 案例
主成分分析在数据处理和评价中有很大应用。首先,我们通过鸢尾花数据集的例子来看到它是如何减少数据列数的。鸢尾花数据集是一个在机器学习和统计学领域广泛使用的经典数据集。它包含了150个样本,每个样本有4个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度,这四个特征都是以厘米为单位。这些特征用于描述鸢尾花的外观。数据集中的样本分为三类,每类50个样本,分别代表山鸢尾、变色鸢尾和维吉尼亚鸢尾三种不同的鸢尾属植物。这个数据集在第9章会被再一次搬上舞台,这里主要是测试主成分分析法。
通过sklearn.datasets的接口导入数据,可以发现其中有四列自变量,再使用sklearn.decomposition提供的PCA函数进行主成分分析即可。代码形如:
import matplotlib.pyplot as plt
import sklearn.decomposition as dp
from sklearn.datasets import load_iris
x,y=load_iris(return_X_y=True) #加载数据,x表示数据集中的属性数据,y表示数据标签
pca=dp.PCA(n_components=0.99) #加载pca算法,设置降维后主成分数目为2
reduced_x=pca.fit_transform(x,y) #对原始数据进行降维,保存在reduced_x中
red_x,red_y=[],[]
blue_x,blue_y=[],[]
green_x,green_y=[],[]
for i in range(len(reduced_x)): #按鸢尾花的类别将降维后的数据点保存在不同的表表中
if y[i]==0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i]==1:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
else:
green_x.append(reduced_x[i][0])
green_y.append(reduced_x[i][1])
plt.scatter(red_x,red_y,c='r',marker='x')
plt.scatter(blue_x,blue_y,c='b',marker='D')
plt.scatter(green_x,green_y,c='g',marker='.')
plt.show()这里参数中PCA的参数设置有两种方法:如果n_components为整数,说明希望取到几个主成分;如果为小数,则说明希望保留多少的信息量,也就是取前几个特征值它们的和能够超过参数给定的阈值。
主成分分析法如何应用于评价呢?其实非常简单,将所有的主成分乘上对应的权重就可以得到最终的评分了。
我们还还以7.2为例,如果想使用主成分分析法对数据进行综合评价,可以怎么做呢?首先,在经过数据的正向化和归一化以后,可以手动实现PCA如下:
def pca(X,n_components):
X=np.array(X)
X=X-np.mean(X)
n=len(X)
A=np.dot(X.T,X)/(n-1)
V,D=np.linalg.eig(A)
idx = (-V).argsort(axis=None)[:n_components]
P=D[idx]
F=np.dot(X,P.T)
return V[idx]/sum(V),F在使用同样的正向化和归一化手段以后,可以给出对应的主成分评分。值得注意的是,主成分评分可能会出现负数,但并不影响。得分越高则说明评价结果越好,越低甚至为负数则评价结果越差。
7.6 因子分析法
7.6.1 异同
因子分析和主成分分析虽然都是用于评价模型的方法,但二者有很大的不同:
-
原理不同:主成分分析是利用降维(线性变换)的思想,每个主成分都是原始变量的线性组合,使得主成分比原始变量具有某些更优越的性能,从而达到简化系统结构,抓住问题实质的目的。而因子分析更倾向于从数据出发,描述原始变量的相关关系,将原始变量进行分解。
-
线性表示方向不同:主成分分析中是把主成分表示成各变量的线性组合,而因子分析是把变量表示成各公因子的线性组合。说白了,一个是组合,一个是分解。
-
假设条件不同:因子分析需要一些假设。因子分析的假设包括:各个共同因子之间不相关,特殊因子之间也不相关,共同因子和特殊因子之间也不相关。
-
主成分分析的主成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等),实际应用时会根据帕累托图提取前几个主要的主成分。而因子分析的因子个数需要分析者指定,指定的因子数量不同而结果也不同。
-
应用范围不同:在实际的应用过程中,主成分分析常被用作达到目的的中间手段,而非完全的一种分析方法,提取出来的主成分无法清晰的解释其代表的含义。而因子分析就是一种完全的分析方法,可确切的得出公共因子。
7.6.2 原理
在进行因子分析之前,需要先进行巴雷特检验或KMO检验。巴雷特特球形检验(Barlett's Test)是一种统计方法,用于检验多个变量之间是否存在相关性。它的基本思想是,如果多个变量之间彼此独立,那么它们的方差应该与它们的相关系数矩阵的行列式值成正比。如果实际观察到的行列式值与预期的行列式值相差很大,那么可以认为这些变量之间存在相关性。通过比较实际观察到的行列式值与预期的行列式值,我们可以决定是否拒绝零假设,即这些变量是独立的。简单来说,巴雷特特球形检验的作用就是帮助我们判断多个变量之间是否存在相关性,从而决定是否适合进行因子分析。如果得到的统计概率小于0.05,那么它是适合做因子分析的。
KMO检验用于评估一组数据是否适合进行因子分析。它的基本作用是检测数据是否符合因子分析的基本假设,即变量之间应该呈现出一定程度的相关性。KMO检验的基本思想是通过比较变量之间的简单相关系数和偏相关系数来进行评估。简单相关系数描述了两个变量之间的直接关系,而偏相关系数则描述了在控制其他变量影响后,两个变量之间的净关系。KMO检验通过计算这些相关系数的平方和来比较这两种关系,以确定数据是否适合进行因子分析。KMO统计量的取值范围在0-1之间。当KMO值越接近1时,表示变量间的相关性越强,原有变量越适合作因子分析;当KMO值越接近0时,表示变量间的相关性越弱,原有变量越不适合作因子分析。在实际分析中,KMO统计量在0.7以上时效果比较好;当KMO统计量在0.5以下时,则不适合应用因子分析法,可能需要重新设计变量结构或者采用其他统计分析方法。
如果能够通过这两个检验中的一个,就可以开始做因子分析了。它的基本流程如下:
-
首先,我们要选出一组变量来进行因子分析。选择的方法有两种:定性和定量。如果原始变量之间的相关性不好,那它们就很难被分解成几个公共因子。所以,原始变量之间应该有较强的相关性。
-
接着,我们要计算这些选定的原始变量的相关系数矩阵。这个矩阵能告诉我们各个变量之间的关系是什么样的。这一步特别重要,因为如果变量之间没什么关系,那把它们分解成几个因子就没什么意义了。这个相关系数矩阵也是我们进行因子分析的基础。
-
然后,我们要从这些原始变量中提取出公共因子。具体要提取几个,需要我们来做决定。这个决定可以基于我们的先验知识或者实验假设。不过,通常我们会看提取的因子的累计方差贡献率是多少。一般来说,累计的方差贡献率达到70%或以上,就算是满足了要求。
-
之后,我们要对提取出来的公共因子进行旋转。这样做的目的是为了让因子的意义更明确,更容易理解。
-
最后,我们要计算出因子的得分。这些得分可以在后续的研究中使用,比如在因子回归模型中。这样,我们就能更好地理解这些变量的关系,并找出影响结果的关键因素。
7.6.3 案例
例:
我们从国家统计局获取了自2005—2012年间各类学校的生师比(学生数量与教师数量的比值),数据如表5.9所示,试对数据进行因子分析并进行一定解释。
| 年份 | 小学生师比 | 初中生师比 | 普通高中生师比 | 职业高中生师比 | 本科院校生师比 | 专科院校生师比 |
|---|---|---|---|---|---|---|
| 2005年 | 19.98 | 18.65 | 18.65 | 19.1 | 17.44 | 13.15 |
| 2006年 | 19.43 | 17.8 | 18.54 | 20.62 | 17.75 | 14.78 |
| 2007年 | 19.17 | 17.15 | 18.13 | 22.16 | 17.61 | 18.26 |
| 2008年 | 18.82 | 16.52 | 17.48 | 23.5 | 17.31 | 17.2 |
| 2009年 | 18.38 | 16.07 | 16.78 | 23.47 | 17.21 | 17.27 |
| 2010年 | 17.88 | 15.47 | 16.3 | 23.65 | 17.23 | 17.35 |
| 2011年 | 17.7 | 14.98 | 15.99 | 23.66 | 17.38 | 17.21 |
| 2012年 | 17.71 | 14.38 | 15.77 | 21.59 | 17.48 | 17.28 |
首先,我们需要对数据进行预处理:
import pandas as pd
import numpy as np
data=pd.read_csv("查询数据.csv",encoding='gbk')
data=data.interpolate('linear')
data=data.fillna(method='bfill')
newdata=data[['小学生师比(教师人数=1)', '初中生师比(教师人数=1)',
'普通高中生师比(教师人数=1)', '职业高中生师比(教师人数=1)', '普通中专生师比(教师人数=1)',
'普通高校生师比(教师人数=1)', '本科院校生师比(教师人数=1)', '专科院校生师比(教师人数=1)', '教育经费(万元)',
'国家财政性教育经费(万元)', '国家财政预算内教育经费(万元)', '各类学校教育经费社会捐赠经费(万元)',
'各类学校教育经费学杂费(万元)']]通过插值与填充,我们对数据中的空缺进行了处理。下面对数据进行巴雷特球形检验和KMO检验:
from factor_analyzer import FactorAnalyzer
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
import numpy as np
import math
from scipy.stats import bartlett
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.style.use("ggplot")
n_factors=3#因子数量
cols=['小学生师比(教师人数=1)', '初中生师比(教师人数=1)',
'普通高中生师比(教师人数=1)', '职业高中生师比(教师人数=1)', '普通中专生师比(教师人数=1)',
'普通高校生师比(教师人数=1)', '本科院校生师比(教师人数=1)', '专科院校生师比(教师人数=1)']
#用检验是否进行
df=newdata[cols]
corr=list(df.corr().to_numpy())
print(bartlett(*corr)) #巴雷特方法
def kmo(dataset_corr): #KMO方法
corr_inv = np.linalg.inv(dataset_corr) #求逆
nrow_inv_corr, ncol_inv_corr = dataset_corr.shape
A = np.ones((nrow_inv_corr,ncol_inv_corr))
for i in range(nrow_inv_corr):
for j in range(i,ncol_inv_corr,1):
A[i,j] = -(corr_inv[i,j])/(math.sqrt(corr_inv[i,i]*corr_inv[j,j]))
A[j,i] = A[i,j]
dataset_corr = np.asarray(dataset_corr)
kmo_num = np.sum(np.square(dataset_corr)) - np.sum(np.square(np.diagonal(A)))
kmo_denom = kmo_num + np.sum(np.square(A)) - np.sum(np.square(np.diagonal(A)))
kmo_value = kmo_num / kmo_denom
return kmo_value
print(kmo(newdata[cols].corr().to_numpy())) 结果显示,KMO值为0.73可以进行因子分析。随后调用分析器并给出载荷矩阵:
#开始计算
fa = FactorAnalyzer(n_factors=n_factors,method='principal',rotation="varimax")
fa.fit(newdata[cols])
communalities= fa.get_communalities()#共性因子方差
loadings=fa.loadings_#成分矩阵,可以看出特征的归属因子
#画图
plt.figure(figsize=(9,6),dpi=800)
ax = sns.heatmap(loadings, annot=True, cmap="BuPu")
ax.set_xticklabels(['基础教育','职业教育','高等教育'],rotation=0)
ax.set_yticklabels(cols,rotation=0)
plt.title('Factor Analysis')
plt.show()
factor_variance = fa.get_factor_variance()#贡献率
fa_score = fa.transform(newdata[cols])#因子得分
#综合得分
complex_score=np.zeros([fa_score.shape[0],])
for i in range(n_factors):
complex_score+=fa_score[:,i]*factor_variance[1][i]#综合得分s我们可以看到,三列因子的累计解释率能到0.9以上,说明非常好。
7.7 后记
由于时间有限,还有一些方法为进行原理解释或者讲解,望周知。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









