






前言:
通过一个多月的shell学习,总共写出30个案例,分批次进行发布,这次总共发布了5个案例,希望能够对大家的学习和使用有所帮助,更多案例会在下期进行发布。
案例十六、检测本地网络中设备在线状态
1.问题:
在一个局域网环境中,有大量的设备(如服务器、打印机、IP 电话等),需要定期检查这些设备是否在线,以便及时发现设备故障或网络问题,保障网络的正常运行。
2.分析:
确定要检测的设备 IP 列表:可以将设备的 IP 地址存储在一个文本文件中,每行一个 IP 地址。
选择检测设备在线状态的方法:使用ping命令向设备的 IP 地址发送 ICMP 数据包(是网络层协议,用于在 IP 主机、路由器之间传递控制消息。它是 IP 协议的一个补充,主要用于报告错误、提供诊断功能以及协助进行网络控制等操作。ICMP 消息被封装在 IP 数据包中进行传输),如果在一定时间内收到回应,则设备在线;如果没有收到回应,则设备可能离线。
设置合适的超时时间和重试次数:为ping命令设置合理的超时时间(如 2 秒),避免等待时间过长。同时,可以设置重试次数(如 3 次),以提高检测的准确性。
记录检测结果:将每个设备的 IP 地址和在线状态(在线或离线)记录到一个日志文件中,方便查看和分析。
3.流程图:
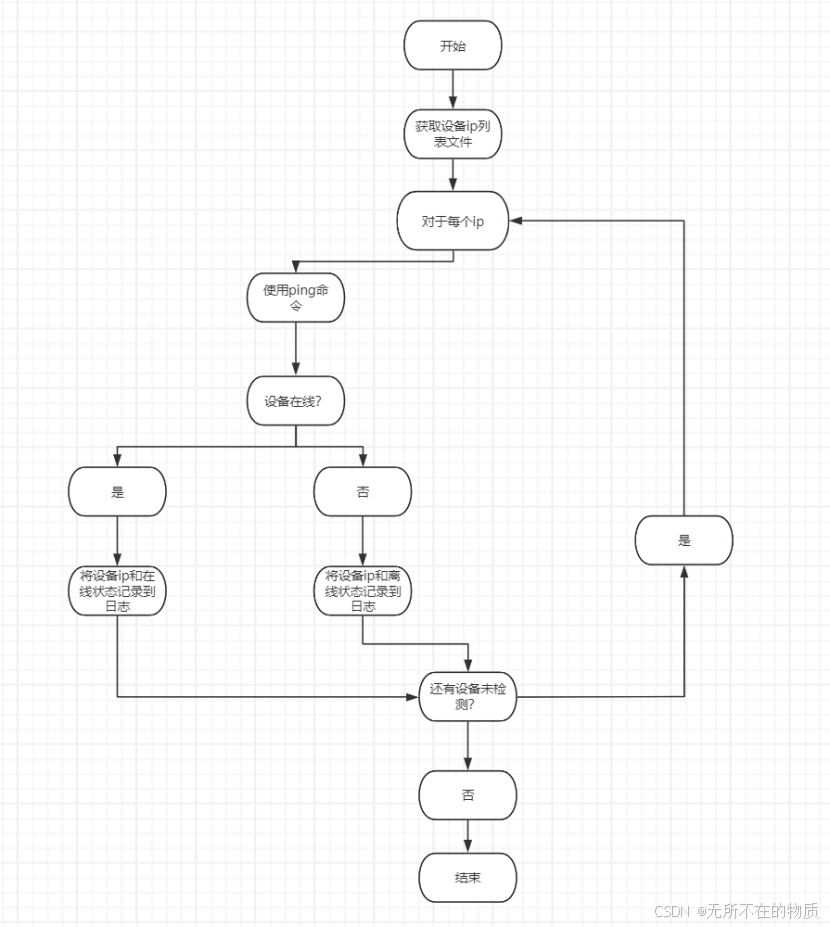
4.实现:
#!/bin/bash
# 设备 IP 列表文件路径
ip_list_file="device_ips.txt"
# 日志文件路径
log_file="device_status.log"
# 检测设备在线状态的函数
check_device_status() {
ip=$1
online=false
for ((i = 1; i <= 3; i++)); do
if ping -c 1 -W 2 $ip >/dev/null 2>&1; then
online=true
break
fi
done
if $online; then
echo "$ip - 在线" >> $log_file
else
echo "$ip - 离线" >> $log_file
fi
}
# 主程序
if [ -f $ip_list_file ]; then
> $log_file
while read ip; do
check_device_status $ip
done < $ip_list_file
else
echo "设备 IP 列表文件未找到。"
exit 1
fi5.实现解析:
ip_list_file="device_ips.txt"和log_file="device_status.log":分别指定存储设备 IP 地址列表的文件路径和记录检测结果的日志文件路径。
check_device_status() {... }:这是一个自定义函数,用于检测单个设备的在线状态。ip=$1:函数接收一个参数,即要检测的设备 IP 地址。
online=false:初始化设备在线状态为离线。
for ((i = 1; i <= 3; i++)); do...:设置一个循环,重试ping操作 3 次。
if ping -c 1 -W 2 $ip >/dev/null 2>&1; then...:使用ping命令向设备发送一个 ICMP 数据包(-c 1),设置超时时间为 2 秒(-W 2)。如果收到回应(ping命令正常退出),则将设备在线状态设置为true并跳出循环。
if $online; then...:根据online变量的值判断设备是否在线,并将设备 IP 地址和在线状态记录到日志文件中。
if [ -f $ip_list_file ]; then...:这是主程序部分,首先检查设备 IP 列表文件是否存在。> $log_file:如果文件存在,先清空日志文件内容。
while read ip; do... done < $ip_list_file:通过循环逐行读取设备 IP 列表文件中的 IP 地址,并调用check_device_status函数检测每个设备的在线状态。
如果设备 IP 列表文件不存在,则输出提示信息并以退出状态码 1 退出脚本。
6.结果验证:
首先创建一个device_ips.txt文本用来放置需要检测的服务器,只需要输入ip即可,如下所示
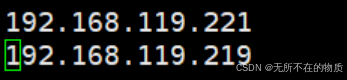
这是放置了两个ip。执行脚本,查看日志文件
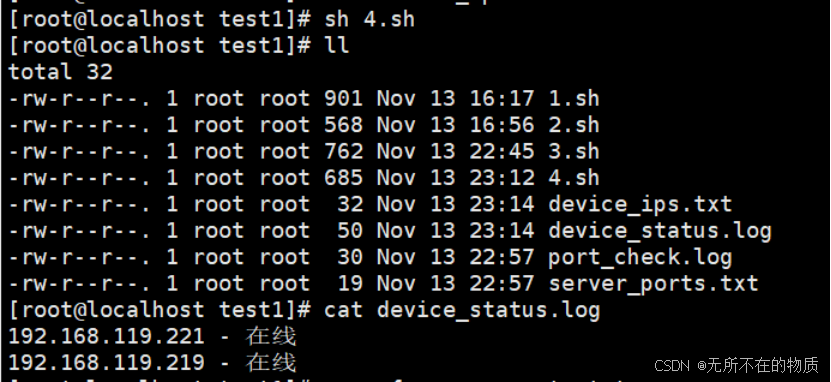
可以看到输入的两个服务器都是在线的,接下来在放置一个ip,再次执行脚本,查看日志
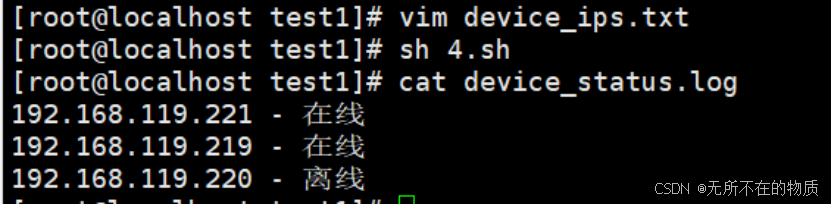
可以看到新放置的服务器处于离线状态
案例十七、nginx自启动
1.问题:
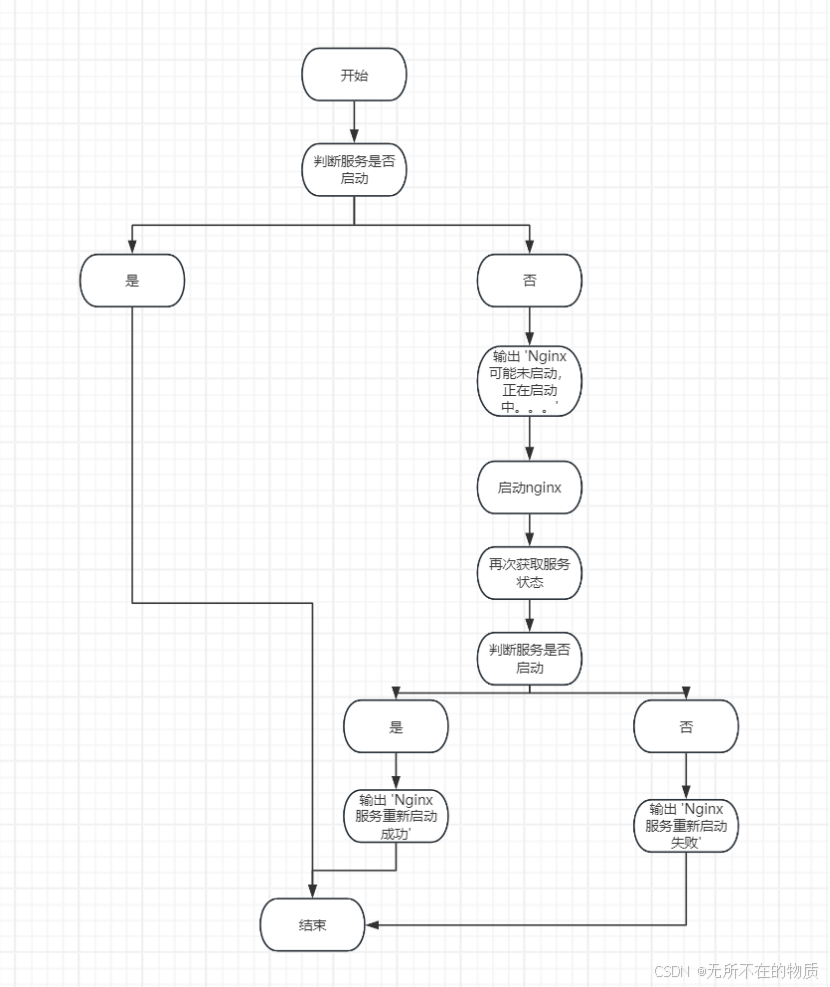
在服务器环境中,Nginx 服务对于网站的正常运行至关重要。但由于各种原因(如服务器重启、软件故障等),Nginx 服务可能会停止,需要一个脚本来自动检查 Nginx 服务的状态,若服务停止则尝试启动它,并反馈服务的状态信息,以确保 Nginx 服务持续稳定运行,减少因服务中断导致的网站不可访问问题。
2.分析:
服务状态获取:使用systemctl status nginx命令获取 Nginx 服务的状态信息,这会返回一个包含服务状态详情的文本。
状态判断:通过grep命令在返回的状态信息中查找active (running)字符串来判断服务是否正在运行。如果找不到该字符串,则认为服务可能未启动。
启动操作:若服务未启动,使用sudo systemctl start nginx命令尝试启动 Nginx 服务。然后再次检查服务状态,以确认启动是否成功。
反馈机制:根据不同的状态情况(服务正在运行、重新启动成功、重新启动失败),使用echo命令输出相应的信息,以便管理员了解 Nginx 服务的情况。
3.流程图:
4.实现:
#!/bin/bash
# 检查 Nginx 服务状态
check_nginx_status() {
# 设置变量 status
status=`systemctl status nginx`
# 使用 grep 查找 "active (running)"字符串
if echo "$status" | grep -q "active (running)"; then
echo "Nginx 服务正在运行"
else
echo "Nginx 可能未启动,正在启动中。。。"
sudo systemctl start nginx
status=`systemctl status nginx`
if echo "$status" | grep -q "active (running)"; then
echo "Nginx 服务重新启动成功"
else
echo "Nginx 服务重新启动失败"
fi
fi
}
check_nginx_status5.实现解析:
首先,在函数内部执行systemctl status nginx命令,并将结果存储在status变量中。这个命令会输出 Nginx 服务的详细状态信息。
接着,使用echo "$status" | grep -q "active (running)"语句来检查status变量中的内容是否包含active (running)字符串。grep -q选项表示安静模式,即只检查是否匹配,不输出匹配内容。如果匹配成功,说明 Nginx 服务正在运行,此时函数会输出Nginx 服务正在运行。
如果grep没有找到active (running)字符串,说明 Nginx 服务可能未启动。此时函数会输出Nginx 可能未启动,正在启动中。。。,然后使用sudo systemctl start nginx命令尝试启动 Nginx 服务。
在启动服务后,再次执行systemctl status nginx命令获取新的服务状态,并存储在status变量中。然后再次使用grep检查新的status变量内容是否包含active (running)字符串。如果匹配成功,说明服务重新启动成功,函数输出Nginx 服务重新启动成功;如果匹配失败,说明服务重新启动失败,函数输出Nginx 服务重新启动失败。
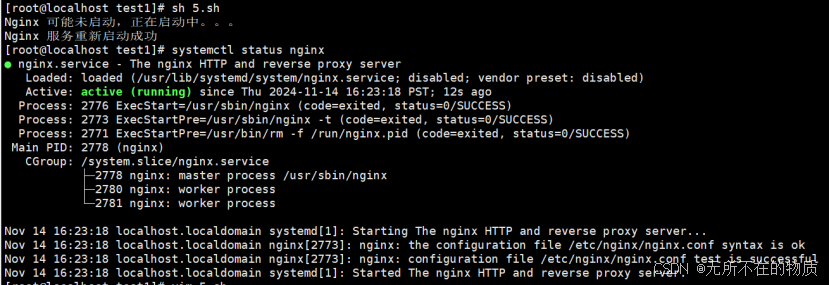
6.结果验证:
首先确保本服务器安装有nginx,执行脚本之后再查看nginx的服务状态,看服务是否启动成功
案例十八、配置阿里云yum源
1.问题:
在 CentOS 系统中,默认的 yum 源可能速度较慢,影响软件安装和更新效率。为了提高效率,需要将系统的 yum 源配置为阿里云的 yum 源。同时,要确保配置过程的准确性,并且在配置完成后能够验证配置是否成功。
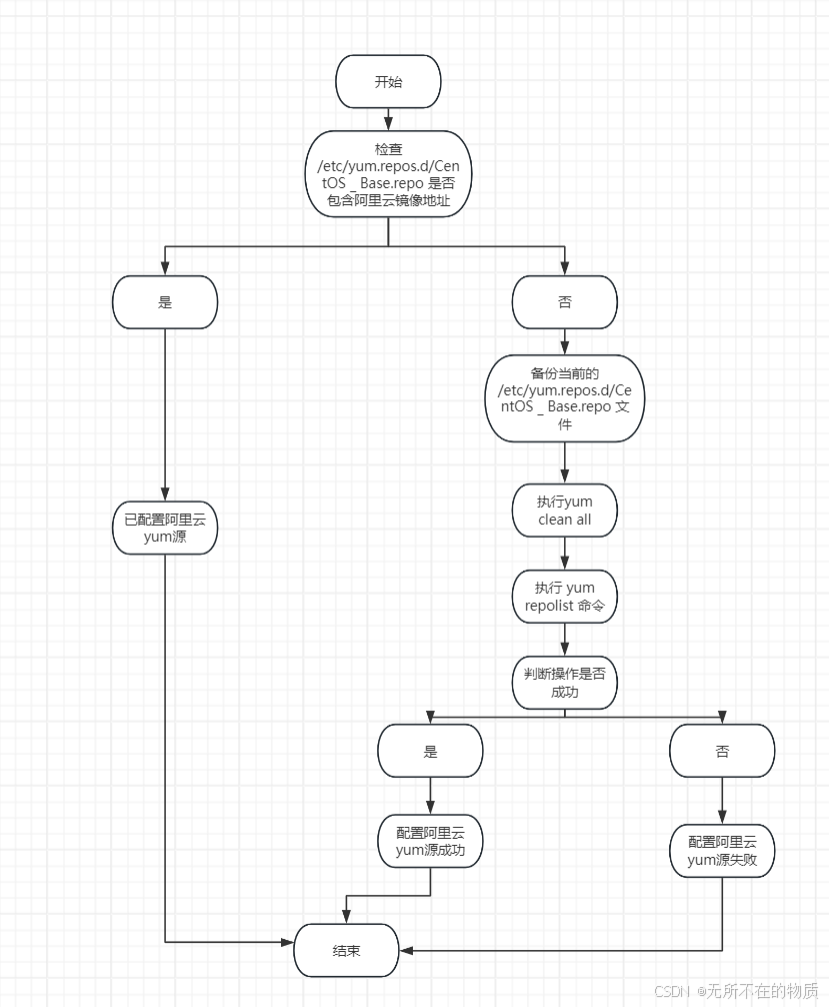
2.分析:
源文件定位与检查:确定系统中 yum 源配置文件的位置(这里是/etc/yum.repos.d/CentOS - Base.repo),通过grep命令检查该文件中是否已经包含阿里云的源地址(mirrors.aliyun.com),以此判断是否已经配置了阿里云 yum 源。
备份原有配置:如果尚未配置阿里云 yum 源,为了防止数据丢失,先将原有的CentOS - Base.repo文件重命名为CentOS - Base.repo.backup。
下载新配置文件:使用curl命令从阿里云的网址(http://mirrors.aliyun.com/repo/Centos - $(rpm - E %{rhel}).repo)下载新的 yum 源配置文件到原CentOS - Base.repo文件的位置。
验证与清理:执行yum clean all命令清理 yum 缓存,然后使用yum repolist命令列出 yum 源信息。根据curl命令和yum命令的执行结果判断配置是否成功,如果curl下载失败或者yum相关操作出现错误,则认为配置失败。
3.流程图:
4.实现:
#/bin/bash
repo_file="/etc/yum.repos.d/CentOS-Base.repo"
aliyun_url="http://mirrors.aliyun.com/repo/Centos-$(rpm -E %{rhel}).repo"
if grep -q "mirrors.aliyun.com" $repo_file; then
echo "已配置阿里云yum源"
else
mv $repo_file ${repo_file}.backup
curl -o $repo_file $aliyun_url && yum clean all && yum repolist && echo "配置阿里云yum源成功"
if [ $? -ne 0 ]; then
echo "配置阿里云yum源失败"
fi
fi5.实现解析:
变量定义:首先定义了两个变量。repo_file变量存储了系统中 yum 源配置文件的路径/etc/yum.repos.d/CentOS - Base.repo。aliyun_url变量存储了阿里云 yum 源配置文件的下载网址,其中$(rpm - E %{rhel})部分是根据系统的 RHEL 版本来确定具体的下载路径。
条件判断与操作:使用if grep -q "mirrors.aliyun.com" $repo_file语句检查repo_file所指向的文件内容中是否包含mirrors.aliyun.com字符串。如果包含,则直接输出已配置阿里云yum源,表示已经是阿里云 yum 源,不需要进行配置操作。
如果不包含该字符串,说明还未配置阿里云 yum 源。此时执行mv $repo_file ${repo_file}.backup,将原有的 yum 源配置文件重命名为CentOS - Base.repo.backup,进行备份。
接着执行curl - o $repo_file $aliyun_url && yum clean all && yum repolist && echo "配置阿里云yum源成功"语句。curl - o $repo_file $aliyun_url部分使用curl命令从aliyun_url指定的网址下载新的 yum 源配置文件到$repo_file指定的路径。如果curl下载成功,继续执行yum clean all命令清理 yum 缓存,然后执行yum repolist命令列出 yum 源信息,最后输出配置阿里云yum源成功。
在整个curl - o $repo_file $aliyun_url && yum clean all && yum repolist操作完成后,通过检查上一个命令的返回值($?)来判断操作是否成功。如果$?的值不为 0,表示操作过程中出现了错误,此时输出配置阿里云yum源失败。
6.结果验证:
由于本机配置过阿里云yum源。所以直接执行脚本,可以看到显示如下

将阿里云yum源删掉,再次执行脚本
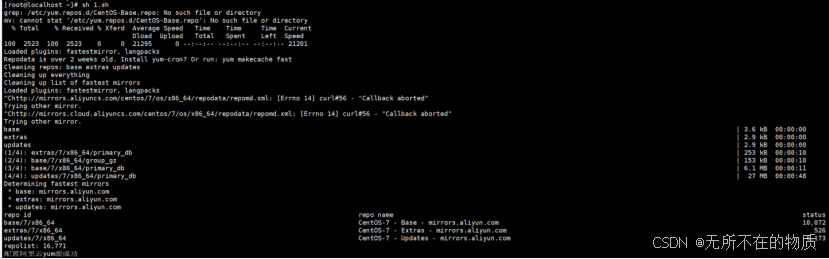
可以看到最后显示阿里云yum源配置成功
案例十九、nginx访问日志分析
1.问题:
在服务器的日志分析场景中,需要从特定格式的访问日志文件中获取一些关键的统计信息,包括访问量最多的 10 个 IP、特定时间段内访问最多的 IP、访问量最多的 10 个页面以及访问页面状态码的数量信息,以便了解服务器的访问情况,为性能优化、安全分析等后续操作提供数据支持。
2.分析:
日志格式理解:
日志文件遵循$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"的格式,其中不同字段存储了不同的信息,如$remote_addr是访问者的 IP 地址,$time_local是访问时间,$request是请求内容,$status是状态码等。
IP 统计分析:
访问最多的 10 个 IP:通过awk命令以$remote_addr作为数组索引,每次出现则计数加 1。最后在END块中输出不同 IP 的数量(UV)以及每个 IP 及其访问次数。然后使用sort按访问次数(第二列)降序排序,并使用head取前 10 个。
特定时间段访问最多的 IP:使用awk命令根据$time_local字段筛选出在指定时间段内的日志记录,同样以$remote_addr为索引计数,最后输出每个 IP 及其访问次数,再进行排序和截取前 10 个操作。但原脚本中时间范围判断可能存在逻辑问题(结束时间早于开始时间)。
页面统计分析:访问最多的 10 个页面:以$request中的页面部分($7)作为索引进行计数,在END块中输出不同页面的数量(PV)以及访问次数大于 10 的页面及其访问次数,然后按访问次数降序排序。
访问页面状态码数量:
将页面($7)和状态码($9)组合作为索引进行计数,最后输出访问次数大于 5 的页面 - 状态码组合及其访问次数,并按访问次数降序排序。
3.流程图:
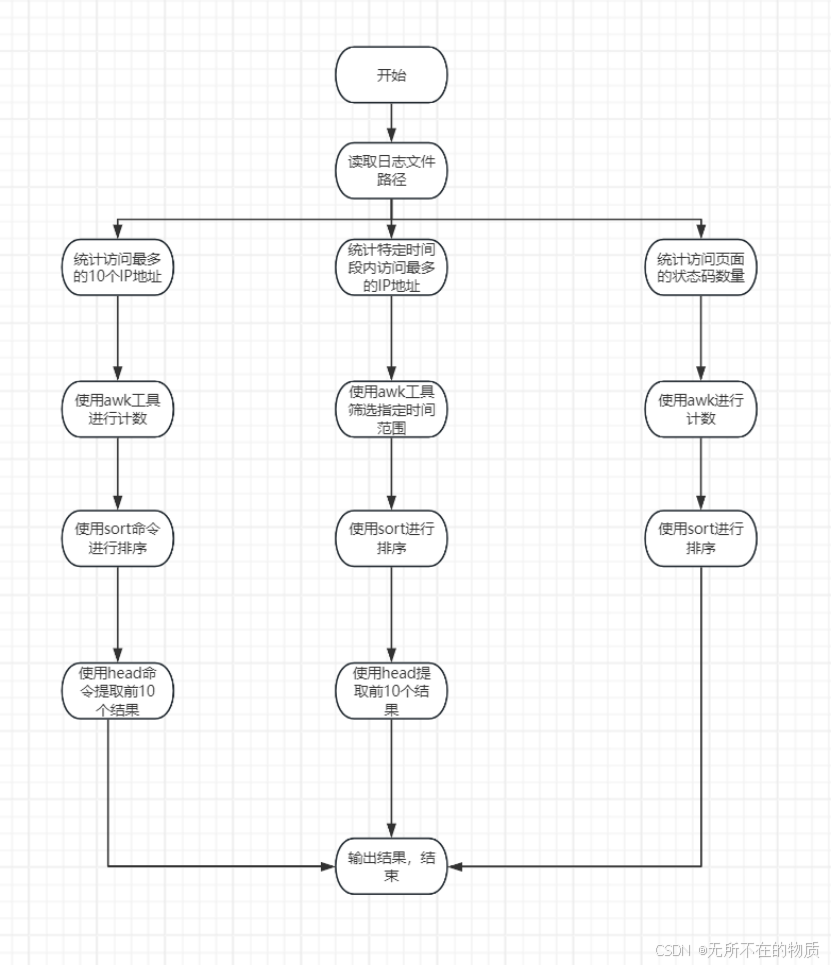
4.实现:
#!/bin/bash
# 日志格式: $remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"
LOG_FILE=$1
echo "统计访问最多的10个IP"
awk '{a[$1]++}END{print "UV:",length(a);for(v in a)print v,a[v]}' $LOG_FILE |sort -k2 -nr |head -10
echo "----------------------"
echo "统计时间段访问最多的IP"
awk '$4>="[01/Dec/2018:13:20:25" && $4<="[27/Nov/2018:16:20:49"{a[$1]++}END{for(v in a)print v,a[v]}' $LOG_FILE |sort -k2 -nr|head -10
echo "----------------------"
echo "统计访问最多的10个页面"
awk '{a[$7]++}END{print "PV:",length(a);for(v in a){if(a[v]>10)print v,a[v]}}' $LOG_FILE |sort -k2 -nr
echo "----------------------"
echo "统计访问页面状态码数量"
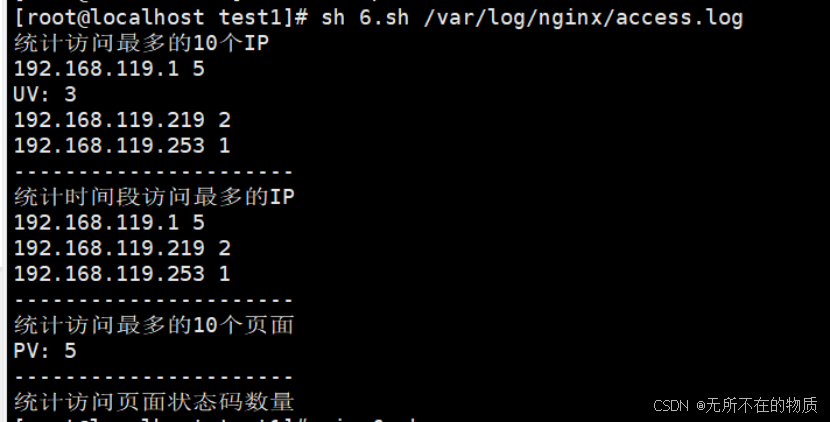
awk '{a[$7" "$9]++}END{for(v in a){if(a[v]>5)print v,a[v]}}' $LOG_FILE |sort -k3 -nr5.结果验证:
首先确保本机安装有nginx,找到nginx的日志文件,执行脚本
案例二十、一键部署jdk
1.问题:
在开发或运行 Java 相关的应用程序时,需要在服务器或本地环境中部署 JDK(Java Development Kit)。手动安装和配置 JDK 过程繁琐,容易出错,而且在有多个 JDK 版本或需要更新 JDK 时,操作更加复杂。因此需要一个自动化的脚本,可以根据用户选择来安装指定版本的 JDK(这里是 Oracle JDK 或 OpenJDK),同时要处理好旧版本的卸载、安装目录创建、文件下载、解压以及环境变量配置等问题。
2.分析:
版本选择与处理:脚本提供了 Oracle JDK 和 OpenJDK 两种选择。对于每种选择,需要从特定的 URL 下载相应版本的 JDK 压缩包。
在安装之前,需要检查系统中是否已经存在其他版本的 JDK,并在用户确认的情况下将其卸载(使用rpm -qa|grep java检查,rpm -e --nodeps卸载),以避免版本冲突。
目录操作:确定 JDK 的安装目录(/usr/local/java)。如果该目录不存在,则创建它;如果已存在,提示用户。
文件下载与解压:根据用户选择的 JDK 版本,使用wget从指定的 URL 下载相应的压缩包(如 Oracle JDK 的https://repo.huaweicloud.com/java/jdk/8u202 - b08/jdk - 8u202 - linux - x64.tar.gz)。
使用tar -zxvf命令将下载的压缩包解压到安装目录。
环境变量配置:根据不同的 JDK 版本,修改/etc/profile文件,添加JAVA_HOME、JRE_HOME、CLASSPATH和PATH等环境变量的设置,使系统能够正确识别和使用新安装的 JDK。最后使用source /etc/profile使环境变量生效,并通过java -version验证安装结果。
3.流程图:
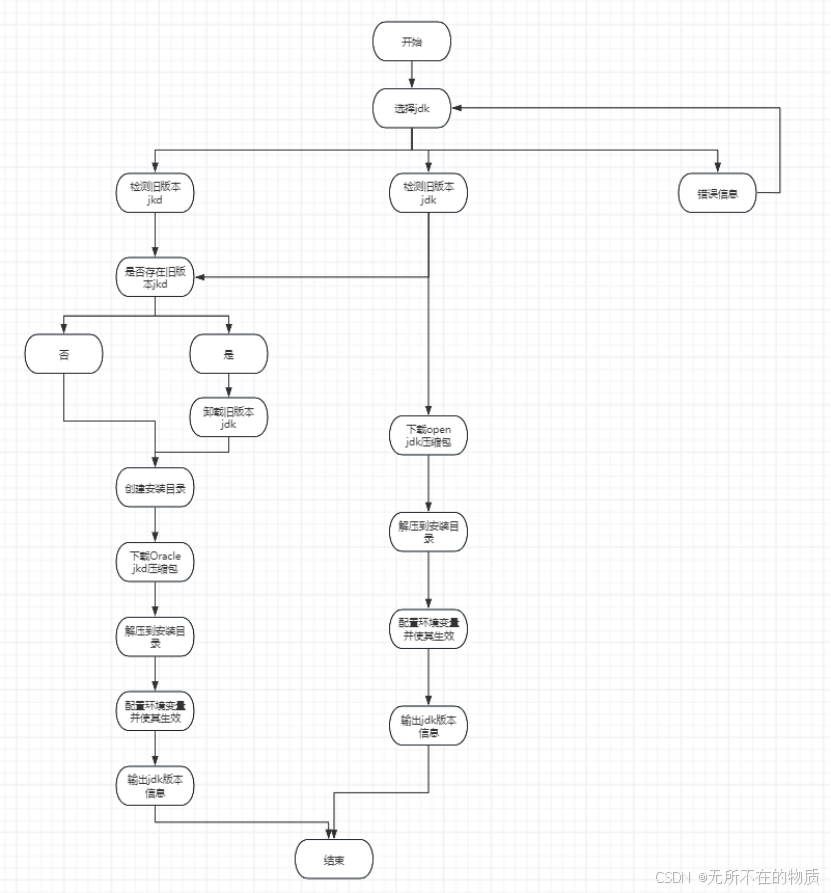
4.实现:
#定义运行成功、失败、警告的格式
function echo_info() {
echo -e "[\033[36m$(date +%T)\033[0m] [\033[32mINFO\033[0m] \033[37m$@\033[0m"
}
function echo_warning() {
echo -e "[\033[36m$(date +%T)\033[0m] [\033[1;33mWARNING\033[0m] \033[1;37m$@\033[0m"
}
function echo_error() {
echo -e "[\033[36m$(date +%T)\033[0m] [\033[41mERROR\033[0m] \033[1;31m$@\033[0m"
}
#自定义变量
JDK_URL="https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz"
OPENJDK_URL="https://github.com/adoptium/temurin8-binaries/releases/download/jdk8u352-b08/OpenJDK8U-jdk_x64_linux_hotspot_8u352b08.tar.gz"
JDK_DAR="jdk-8u202-linux-x64.tar.gz"
OPENJDK_DAR="OpenJDK8U-jdk_x64_linux_hotspot_8u352b08.tar.gz"
INSTALL_DAR="/usr/local/java"
#定义Oracle_jdk函数
function Oracle_jdk () {
if [ ! -d "${INSTALL_DAR}" ];
then
echo_info 创建目录
mkdir "${INSTALL_DAR}"
else
echo_warning 该目录已存在,无需创建
fi
restart=$(rpm -qa|grep java)
if [ -z "${restart}" ];
then
echo_warning 无其他版本
else
echo_info 开始删除旧版本的jdk
echo -------------------删除中------------------
rpm -e --nodeps $restart
fi
echo_info 下载jdk压缩包
echo ------------------下载中-------------------
#定义main函数
function main(){
wget "${JDK_URL}"
tar -zxvf "${JDK_DAR}" -C "${INSTALL_DAR}" >>2.sh
echo 'export JAVA_HOME=/usr/local/java/jdk1.8.0_202' >> /etc/profile
echo 'export JRE_HOME=${JAVA_HOME}/jre' >> /etc/profile
echo 'export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib' >> /etc/profile
echo 'export PATH=${JAVA_HOME}/bin:$PATH' >> /etc/profile
source /etc/profile
echo_info 环境变量生效中
echo "jdk的版本为:"
java -version
}
main
}
#定义 open_jdk函数
function open_jdk () {
if [ ! -d "${INSTALL_DAR}" ];
then
echo_info 创建目录
mkdir "${INSTALL_DAR}"
else
echo_warning 该目录已存在,无需创建
fi
restart=$(rpm -qa|grep java)
if [ -z "${restart}" ];
then
echo_warning 无其他版本
else
echo_info 开始删除旧版本的jdk
echo -------------------删除中------------------
rpm -e --nodeps $restart
fi
echo_info 下载jdk压缩包
echo ------------------下载中-------------------
#定义Main函数
function Main () {
wget "${OPENJDK_URL}"
tar -zxvf "${OPENJDK_DAR}" -C "${INSTALL_DAR}"
echo 'export JAVA_HOME=/usr/java/jdk8u352-b08' >> /etc/profile
echo 'export JRE_HOME=$JAVA_HOME/jre' >> /etc/profile
echo 'export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib' >> /etc/profile
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile
source /etc/profile
echo_info 环境变量生效中
echo "jdk的版本为:"
java -version
}
Main
}
#定义install函数
function install () {
read -p "请选择需要部署的jdk:" n
case $n in
1)
echo_info 即将安装Oracle jdk
sleep 1
Oracle_jdk
;;
2)
echo_info 即将安装open jdk
sleep 1
open_jdk
;;
esac
}
echo -e "\033[31m请选择使用哪种jdk下载方式:\033[0m"
echo -e "\033[36m[1]\033[32m Oracle jdk\033[0m"
echo -e "\033[36m[2]\033[32m open jdk\033[0m"
install5.实现解析:
信息输出函数定义:定义了echo_info、echo_warning和echo_error三个函数,用于以不同的颜色和格式输出信息、警告和错误消息,方便用户在脚本执行过程中区分不同类型的输出。这些函数使用echo -e和 ANSI 转义序列来实现彩色输出,例如[\033[36m$(date +%T)\033[0m]用于以青色显示当前时间。
变量定义:JDK_URL和OPENJDK_URL分别是 Oracle JDK 和 OpenJDK 的下载 URL。
JDK_DAR和OPENJDK_DAR是下载的压缩包文件名。
INSTALL_DAR指定了 JDK 的安装目录。
Oracle_jdk 函数:首先,通过if [! -d "${INSTALL_DAR}" ];检查安装目录是否存在,如果不存在,则使用mkdir创建。如果目录已存在,使用echo_warning函数输出提示信息。
接着,使用restart=$(rpm -qa|grep java)获取系统中已安装的 Java 相关的 RPM 包列表,并通过if [ -z "${restart}" ];判断是否有其他版本的 JDK。如果有,则使用rpm -e --nodeps $restart卸载这些旧版本,同时输出相应的信息。
在下载部分,使用echo_info输出下载提示信息,然后在内部定义的main函数中:使用wget "${JDK_URL}"从指定 URL 下载 Oracle JDK 压缩包。
使用tar -zxvf "${JDK_DAR}" -C "${INSTALL_DAR}" >>2.sh将下载的压缩包解压到安装目录,并将解压过程的输出重定向到2.sh文件(这里可能是用于记录解压过程或临时处理解压相关的输出,不过这种重定向可能需要进一步确认其用途)。
通过echo命令向/etc/profile文件添加 Oracle JDK 的环境变量设置,包括JAVA_HOME、JRE_HOME、CLASSPATH和PATH。
使用source /etc/profile使环境变量生效,并通过java -version输出 JDK 的版本信息,以验证安装是否成功。
open_jdk 函数:与Oracle_jdk函数类似,先检查安装目录是否存在并进行相应处理,然后检查和卸载旧版本的 JDK。
在下载部分,输出下载提示信息后,在内部定义的Main函数中:使用wget "${OPENJDK_URL}"下载 OpenJDK 压缩包。
使用tar -zxvf "${OPENJDK_DAR}" -C "${INSTALL_DAR}"解压压缩包到安装目录。
向/etc/profile文件添加 OpenJDK 的环境变量设置,与 Oracle JDK 的设置略有不同(路径等相关内容根据 OpenJDK 的实际情况)。
使用source /etc/profile使环境变量生效,并输出 JDK 版本信息进行验证。
install 函数:使用read -p提示用户选择要安装的 JDK 版本,通过case语句根据用户输入调用Oracle_jdk函数或open_jdk函数来执行相应的安装过程。
6.结果验证:
执行脚本,会出现如下选项
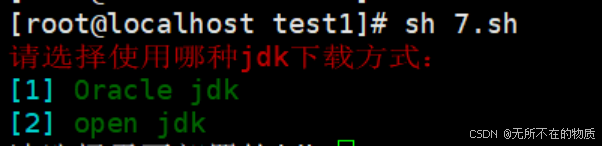
输入数字1或2即可进行部署想要的jdk版本。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









