







经过研究,发现RSRS的正确用法其实是需要用到两个数据,分别是
n: 一阶拟合样本数,m:求均值方差样本数,其中n比较小 如18,m比较大 如1100
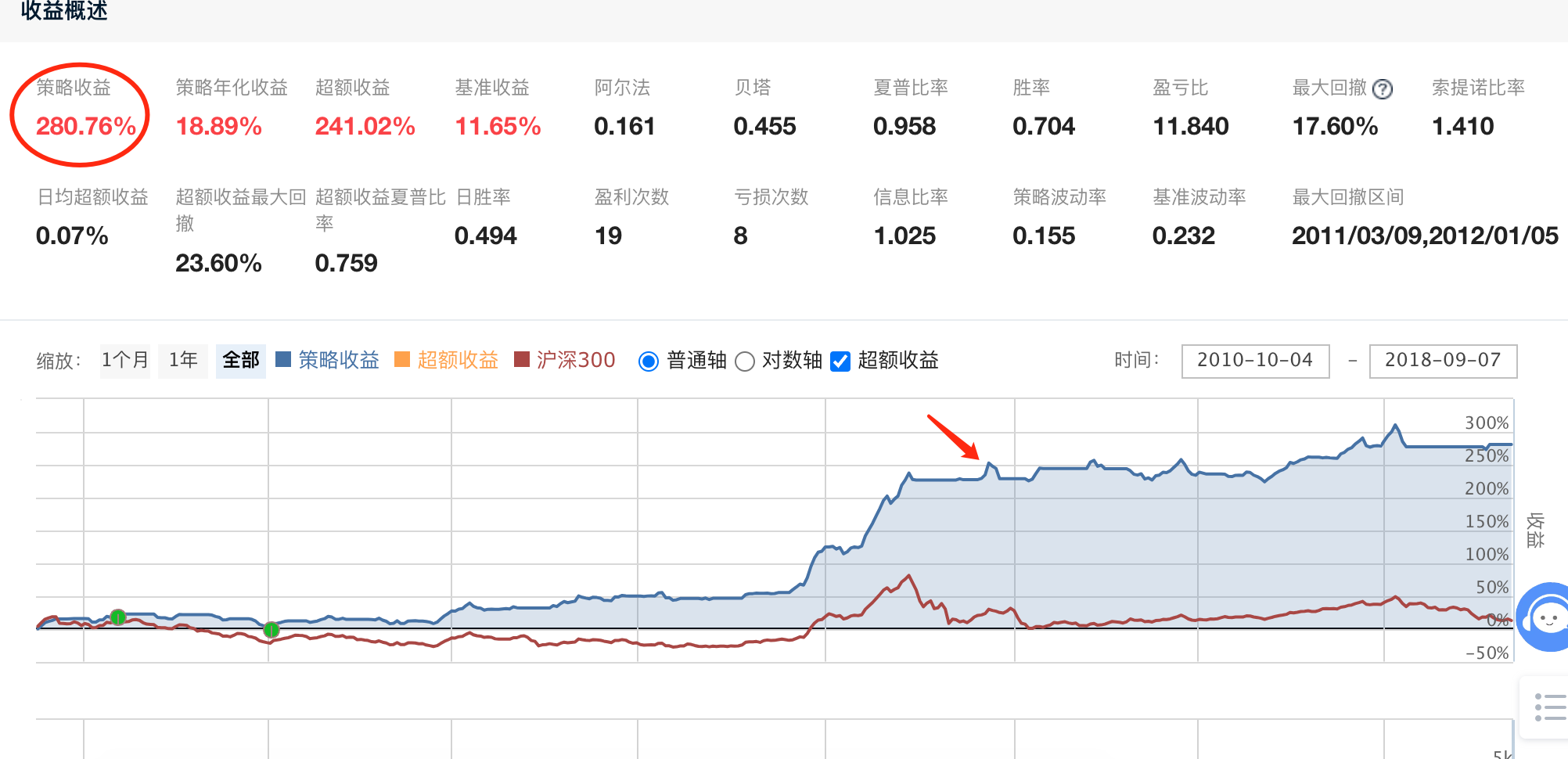
经过调优后,收益率显著上升! 如下图:
(并且算法上优化,不重复计算)
将源码贴出来,感兴趣的点个赞和关注,谢谢!
# 导入函数库
from jqdata import *
import pandas as pd
import numpy as np
import statsmodels.api as sm
def initialize(context):
set_benchmark('000300.XSHG')
set_option('use_real_price', True)
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
g.security = '000300.XSHG'
g.buy_beta, g.sell_beta = 0.7, -0.7
g.is_first, g.beta_list, g.r2_list = True, [], []
run_daily(market_open, time='open', reference_security='000300.XSHG')
def calculate_rsrs(end_date='', n=18, m=1100):
# n: 一阶拟合样本数,m:求均值方差样本数; 采用普通最小二乘法拟合,前面算过的就不重复计算了
if g.is_first:
df = get_price(g.security, end_date=end_date, count=m+n, frequency='daily', fields=['high','low'])
else:
df = get_price(g.security, end_date=end_date, count=n, frequency='daily', fields=['high','low'])
for i in range(len(df))[(-m if g.is_first else -1):]:
x = sm.add_constant(df['low'][i-n+1:i+1])
y = df['high'][i-n+1:i+1]
model = sm.OLS(y, x).fit()
beta = model.params[1]
r2 = model.rsquared
g.beta_list.append(beta)
g.r2_list.append(r2)
section = g.beta_list[-m:]
mu = np.mean(section)
sigma = np.std(section)
z_score = (section[-1] - mu)/sigma
z_score_right = z_score * beta * r2
g.is_first = False
return z_score_right
def market_open(context):
cash = context.portfolio.available_cash
z_score_right = calculate_rsrs(context.previous_date)
if z_score_right>g.buy_beta and cash>0:
order_value(g.security, cash)
elif z_score_right<g.sell_beta and context.portfolio.positions[g.security].closeable_amount > 0:
order_target(g.security, 0)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









