







网站下载分析工具是一款能够抓取和分析网站前端代码的实用工具。最近我们对其进行了全面升级,新版本在多个方面取得了显著改进,同时也有一些值得注意的局限性。本文将分享这些改进与不足,帮助您选择合适的版本。
改进版的优势
1. 更全面的资源获取
新版工具不仅下载HTML、CSS和JavaScript文件,还能获取图片和字体文件,使本地化的网站呈现更为完整。这对于需要全面分析网站视觉元素的用户尤为重要。
2. 强化的编码处理
改进版通过多层次的编码检测机制,能够准确识别各种语言的编码格式,显著减少了中文、日文等非拉丁语系网站的乱码问题。这个改进对于国际化网站分析至关重要。
3. 本地浏览支持
最显著的改进是对路径的智能重写,使下载的网站可以在本地完整浏览,而不仅仅是查看代码。这使得分析工作更加直观,特别是对交互功能的测试。
4. CSS资源深度解析
新版本能够识别并下载CSS中引用的背景图片、字体等资源,大大提高了样式还原的准确性,让本地版本更接近原始网站的外观。
5. 增强的兼容性
通过添加正确的DOCTYPE和字符集声明,改进版生成的HTML文件在各种浏览器中的兼容性更好,减少了渲染异常。
存在的不足
1. 对简单网站的过度处理
改进版在处理某些结构简单的网站时可能过于复杂,有时反而会导致意外的编码问题或结构变形。简单的静态页面可能更适合使用基础版本处理。
2. 资源消耗增加
由于下载和处理的资源类型增多,改进版需要更多的存储空间和处理时间,对于快速分析简单网站可能显得有些"大材小用"。
3. 动态内容的局限性
尽管有了显著改进,但工具仍然难以完整捕获高度依赖JavaScript动态生成内容的现代网站,特别是单页应用(SPA)和重度依赖AJAX的网站。
4. 对特定网站的兼容性问题
某些使用非标准技术或特殊结构的网站可能与改进版的处理逻辑不兼容,导致下载或分析失败。
5. 安全限制
改进版虽然能下载更多资源,但仍受到跨域政策和网站安全措施的限制,无法获取需要身份验证的内容或受保护的资源。
适用场景建议
基于以上优势和不足,我们建议:
- 使用改进版:当您需要全面分析包含丰富多媒体资源的复杂网站,或希望在本地完整浏览下载的网站时
- 使用基础版:当您只需快速获取简单网站的代码结构,或处理编码敏感的特定网站时
理想的方案是提供两种模式的选择,让用户根据具体需求灵活切换,既能享受增强功能,又能避免不必要的复杂性。
改进版完整代码:
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse, urlunsplit
import time
import re
from openai import OpenAI
def download_web_content(url, output_dir="downloaded_website"):
"""
下载指定URL的HTML、CSS和JS文件,并重写资源路径
参数:
url (str): 要下载的网站URL
output_dir (str): 保存文件的目录
返回:
dict: 包含下载的文件信息,可以传递给AI分析
"""
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
os.makedirs(os.path.join(output_dir, "css"))
os.makedirs(os.path.join(output_dir, "js"))
os.makedirs(os.path.join(output_dir, "images"))
os.makedirs(os.path.join(output_dir, "fonts"))
# 解析基础URL信息
parsed_url = urlparse(url)
base_domain = f"{parsed_url.scheme}://{parsed_url.netloc}"
# 下载主HTML文件
print(f"正在下载页面: {url}")
try:
# 添加Accept-Encoding和Accept-Language头,尝试获取正确编码的内容
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
response.raise_for_status() # 确保请求成功
except requests.exceptions.RequestException as e:
print(f"下载HTML时出错: {e}")
return None
# 解析HTML,确保正确处理编码
# 尝试从响应头或内容中检测编码
encoding = response.encoding
# 如果检测到的编码是ISO-8859-1,这通常是requests的默认猜测
# 尝试从内容中更准确地检测编码
if encoding == 'ISO-8859-1':
# 尝试从HTML内容中检测编码
detected_encoding = None
content_type = response.headers.get('Content-Type', '')
charset_match = re.search(r'charset=(\S+)', content_type)
if charset_match:
detected_encoding = charset_match.group(1)
# 从HTML meta标签检测编码
meta_match = re.search(r'<meta\s+http-equiv=["\']Content-Type["\'][^>]*charset=([^\s"\'/>]+)', response.text,
re.IGNORECASE)
if not meta_match:
meta_match = re.search(r'<meta\s+charset=["\']?([^\s"\'/>]+)', response.text, re.IGNORECASE)
if meta_match:
detected_encoding = meta_match.group(1)
if detected_encoding:
try:
encoding = detected_encoding
print(f"从内容检测到编码: {encoding}")
except LookupError:
print(f"不支持的编码: {detected_encoding},使用默认编码")
# 使用检测到的编码重新解码内容
try:
html_content = response.content.decode(encoding)
print(f"使用编码 {encoding} 解析HTML内容")
except (UnicodeDecodeError, LookupError):
# 如果失败,尝试使用utf-8
try:
html_content = response.content.decode('utf-8')
print("使用UTF-8编码解析HTML内容")
except UnicodeDecodeError:
# 如果utf-8也失败,回退到requests自动检测的编码
html_content = response.text
print(f"使用requests自动检测的编码 {response.encoding} 解析HTML内容")
soup = BeautifulSoup(html_content, "html.parser")
# 跟踪下载的文件
downloaded_files = {
"html": [],
"css": [],
"js": [],
"images": [],
"fonts": []
}
# 重写base标签
base_tag = soup.find('base')
if base_tag:
if base_tag.has_attr('href'):
print(f"检测到<base>标签,原始href: {base_tag['href']}")
base_tag['href'] = './'
print("已将<base>标签修改为当前目录")
# 处理CSS链接并重写路径
css_links = {} # 存储原始URL到本地路径的映射
for css_link in soup.find_all("link", rel="stylesheet"):
if css_link.get("href"):
css_url = css_link.get("href")
# 处理不同类型的URL
if css_url.startswith('//'): # 协议相对URL
css_url = f"{parsed_url.scheme}:{css_url}"
elif css_url.startswith('/'): # 绝对路径(相对于网站根目录)
css_url = urljoin(base_domain, css_url)
else: # 相对路径
css_url = urljoin(url, css_url)
# 提取文件名,如果URL没有文件名则生成一个
css_path_parts = urlparse(css_url).path.split('/')
css_filename = css_path_parts[-1] if css_path_parts[-1] else f"style_{len(css_links)}.css"
# 确保CSS文件名唯一
if not css_filename.endswith('.css'):
css_filename += '.css'
local_css_path = os.path.join("css", css_filename)
css_links[css_url] = local_css_path
# 更新HTML中的链接
css_link["href"] = local_css_path
# 下载CSS文件
try:
css_response = requests.get(css_url, headers={"User-Agent": "Mozilla/5.0"})
css_response.raise_for_status()
# 保存并记录CSS文件
full_css_path = os.path.join(output_dir, local_css_path)
with open(full_css_path, "w", encoding="utf-8") as f:
# 处理CSS中的URL引用
css_content = css_response.text
css_content = rewrite_css_urls(css_content, css_url, output_dir)
f.write(css_content)
downloaded_files["css"].append(full_css_path)
print(f"CSS已保存到: {full_css_path}")
time.sleep(0.5) # 避免请求过快
except requests.exceptions.RequestException as e:
print(f"下载CSS出错 {css_url}: {e}")
# 处理JavaScript文件并重写路径
js_links = {} # 存储原始URL到本地路径的映射
for script in soup.find_all("script", src=True):
if script.get("src"):
js_url = script.get("src")
# 处理不同类型的URL
if js_url.startswith('//'): # 协议相对URL
js_url = f"{parsed_url.scheme}:{js_url}"
elif js_url.startswith('/'): # 绝对路径(相对于网站根目录)
js_url = urljoin(base_domain, js_url)
else: # 相对路径
js_url = urljoin(url, js_url)
# 提取文件名,如果URL没有文件名则生成一个
js_path_parts = urlparse(js_url).path.split('/')
js_filename = js_path_parts[-1] if js_path_parts[-1] else f"script_{len(js_links)}.js"
# 确保JS文件名唯一
if not js_filename.endswith('.js'):
js_filename += '.js'
local_js_path = os.path.join("js", js_filename)
js_links[js_url] = local_js_path
# 更新HTML中的链接
script["src"] = local_js_path
# 下载JS文件
try:
js_response = requests.get(js_url, headers={"User-Agent": "Mozilla/5.0"})
js_response.raise_for_status()
# 保存并记录JS文件
full_js_path = os.path.join(output_dir, local_js_path)
with open(full_js_path, "w", encoding="utf-8") as f:
f.write(js_response.text)
downloaded_files["js"].append(full_js_path)
print(f"JS已保存到: {full_js_path}")
time.sleep(0.5) # 避免请求过快
except requests.exceptions.RequestException as e:
print(f"下载JS出错 {js_url}: {e}")
# 处理图片链接并重写路径
for img in soup.find_all("img", src=True):
if img.get("src"):
img_url = img.get("src")
# 跳过数据URL(如 data:image/png;base64...)
if img_url.startswith('data:'):
continue
# 处理不同类型的URL
if img_url.startswith('//'): # 协议相对URL
img_url = f"{parsed_url.scheme}:{img_url}"
elif img_url.startswith('/'): # 绝对路径(相对于网站根目录)
img_url = urljoin(base_domain, img_url)
else: # 相对路径
img_url = urljoin(url, img_url)
# 提取文件名,如果URL没有文件名则生成一个
img_path_parts = urlparse(img_url).path.split('/')
img_filename = img_path_parts[-1] if img_path_parts[-1] else f"image_{len(downloaded_files['images'])}.png"
# 确保文件扩展名
if '.' not in img_filename:
img_filename += '.png'
local_img_path = os.path.join("images", img_filename)
# 更新HTML中的链接
img["src"] = local_img_path
# 下载图片文件
try:
img_response = requests.get(img_url, headers={"User-Agent": "Mozilla/5.0"})
img_response.raise_for_status()
# 保存并记录图片文件
full_img_path = os.path.join(output_dir, local_img_path)
with open(full_img_path, "wb") as f: # 图片用二进制写入
f.write(img_response.content)
downloaded_files["images"].append(full_img_path)
print(f"图片已保存到: {full_img_path}")
time.sleep(0.5) # 避免请求过快
except requests.exceptions.RequestException as e:
print(f"下载图片出错 {img_url}: {e}")
# 处理a标签的href属性,将绝对路径转为相对路径
for a_tag in soup.find_all('a', href=True):
href = a_tag.get('href')
# 只处理指向同一域名的链接
if href.startswith('/') and not href.startswith('//'):
a_tag['href'] = f".{href}"
elif href.startswith('//') and parsed_url.netloc in href:
# 协议相对URL,但指向同一域名
path = urlparse(href).path
a_tag['href'] = f".{path}"
elif href.startswith(base_domain):
# 完整URL,但指向同一域名
path = urlparse(href).path
a_tag['href'] = f".{path}"
# 保存修改后的HTML文件,确保使用正确的编码
html_path = os.path.join(output_dir, "index.html")
with open(html_path, "w", encoding="utf-8") as f:
# 添加编码声明,确保浏览器正确识别编码
html_str = str(soup)
# 如果没有doctype,添加doctype
if "<!DOCTYPE" not in html_str[:1000]:
html_str = "<!DOCTYPE html>\n" + html_str
# 如果没有charset声明,添加charset
if "<meta charset=" not in html_str[:1000]:
head_tag = soup.find('head')
if head_tag:
meta_charset = soup.new_tag('meta')
meta_charset['charset'] = 'utf-8'
head_tag.insert(0, meta_charset)
html_str = str(soup)
f.write(html_str)
downloaded_files["html"].append(html_path)
print(f"HTML已保存到: {html_path} (使用UTF-8编码)")
print(
f"完成! 已下载 {len(downloaded_files['html'])} HTML文件, "
f"{len(downloaded_files['css'])} CSS文件, "
f"{len(downloaded_files['js'])} JS文件, "
f"{len(downloaded_files['images'])} 图片文件."
)
return downloaded_files
def rewrite_css_urls(css_content, css_url, output_dir):
"""
重写CSS文件中的URL引用
参数:
css_content (str): CSS文件内容
css_url (str): CSS文件的原始URL
output_dir (str): 输出目录
返回:
str: 重写后的CSS内容
"""
# 解析CSS文件URL的基础部分
parsed_css_url = urlparse(css_url)
css_base_url = f"{parsed_css_url.scheme}://{parsed_css_url.netloc}"
css_dir_path = '/'.join(parsed_css_url.path.split('/')[:-1])
def replace_url(match):
url = match.group(1).strip('\'"')
# 跳过已经是数据URL的情况
if url.startswith('data:'):
return f"url({match.group(1)})"
# 处理不同类型的URL
if url.startswith('//'): # 协议相对URL
full_url = f"{parsed_css_url.scheme}:{url}"
elif url.startswith('/'): # 绝对路径(相对于网站根目录)
full_url = f"{css_base_url}{url}"
elif url.startswith('http://') or url.startswith('https://'): # 完整URL
full_url = url
else: # 相对路径
if css_dir_path:
full_url = f"{css_base_url}{css_dir_path}/{url}"
else:
full_url = f"{css_base_url}/{url}"
# 确定资源类型和目标路径
parsed_resource = urlparse(full_url)
resource_path = parsed_resource.path
filename = resource_path.split('/')[-1]
# 根据扩展名确定资源类型
if resource_path.endswith(('.png', '.jpg', '.jpeg', '.gif', '.webp', '.svg')):
resource_type = 'images'
elif resource_path.endswith(('.woff', '.woff2', '.ttf', '.eot')):
resource_type = 'fonts'
else:
# 对于未知类型,保留原始URL
return f"url({match.group(1)})"
if not filename:
# 如果没有文件名,生成一个(使用URL的哈希)
import hashlib
filename = f"{hashlib.md5(full_url.encode()).hexdigest()}.bin"
local_path = f"../{resource_type}/{filename}"
# 下载资源
try:
resource_response = requests.get(full_url, headers={"User-Agent": "Mozilla/5.0"})
resource_response.raise_for_status()
# 保存资源
save_path = os.path.join(output_dir, resource_type, filename)
with open(save_path, "wb") as f:
f.write(resource_response.content)
print(f"已保存资源: {save_path} (来自CSS中的URL引用)")
except Exception as e:
print(f"下载资源失败 {full_url}: {e}")
return f"url({match.group(1)})" # 保留原始URL
return f"url('{local_path}')"
# 查找并替换CSS中的所有URL引用
url_pattern = r"url\s*\(\s*([\"']?.*?[\"']?)\s*\)"
return re.sub(url_pattern, replace_url, css_content)
def analyze_with_grok(downloaded_files):
"""
使用grok-3-beta AI分析下载的网站文件
参数:
downloaded_files (dict): 包含下载的文件路径的字典
返回:
str: AI的分析结果
"""
# 读取文件内容
html_content = ""
for html_file in downloaded_files["html"]:
with open(html_file, "r", encoding="utf-8") as f:
html_content += f.read()
css_content = ""
for css_file in downloaded_files["css"][:3]: # 限制CSS文件数量,避免超出token限制
with open(css_file, "r", encoding="utf-8") as f:
css_content += f.read()
js_content = ""
for js_file in downloaded_files["js"][:3]: # 限制JS文件数量,避免超出token限制
with open(js_file, "r", encoding="utf-8") as f:
js_content += f.read()
# 创建提示信息
prompt = f"""请分析这个网站的HTML、CSS和JS代码,并提供以下信息:
1. 网站的整体结构和主要组件
2. 使用了哪些前端技术和框架
3. 网站布局和设计的特点
4. 实现了哪些交互功能
5. 网站开发的最佳实践和可改进之处
6. 特别分析路径引用方式(相对路径、绝对路径等)
HTML示例:
```html
{html_content[:5000]} # 截取部分内容以适应token限制
```
CSS示例:
```css
{css_content[:3000]} # 截取部分内容以适应token限制
```
JS示例:
```javascript
{js_content[:3000]} # 截取部分内容以适应token限制
```
"""
# 调用grok-3-beta API
client = OpenAI(
api_key="xai-xxx",
base_url="https://api.x.ai/v1",
)
try:
completion = client.chat.completions.create(
model="grok-3-beta",
messages=[
{"role": "system", "content": "你是一位资深的前端开发工程师,擅长分析网站结构和开发技术。"},
{"role": "user", "content": prompt}
],
)
analysis = completion.choices[0].message.content
return analysis
except Exception as e:
print(f"调用AI API时出错: {e}")
return "分析失败,请检查API密钥和连接。"
def main():
print("网站HTML、CSS、JS下载和分析工具 (支持URL重写)")
print("-" * 50)
# 默认下载CSDN首页
default_url = "https://csdn.net/"
url_input = input(f"请输入要下载的网站URL (默认为 {default_url}): ")
url = url_input if url_input.strip() else default_url
if not url.startswith(("http://", "https://")):
url = "https://" + url
# 默认使用当前目录下的网站名文件夹
website_name = urlparse(url).netloc.replace(".", "_")
default_output_dir = os.path.join(os.getcwd(), f"downloaded_{website_name}")
output_dir_input = input(f"请输入保存文件的目录名 (默认为 '{default_output_dir}'): ")
output_dir = output_dir_input if output_dir_input.strip() else default_output_dir
# 下载网站内容
downloaded_files = download_web_content(url, output_dir)
if downloaded_files:
# 询问是否使用AI分析
analyze = input("是否使用grok-3-beta分析网站? (y/n): ").lower()
if analyze == "y" or analyze == "yes":
print("\n正在分析网站,这可能需要一些时间...")
analysis = analyze_with_grok(downloaded_files)
# 保存分析结果
analysis_file = os.path.join(output_dir, "website_analysis.txt")
with open(analysis_file, "w", encoding="utf-8") as f:
f.write(analysis)
print(f"\nAI分析已保存到: {analysis_file}")
print("\n分析摘要:")
print("-" * 50)
print(analysis[:1000] + "..." if len(analysis) > 1000 else analysis)
print("\n程序执行完成!")
print(f"\n您可以通过打开 {os.path.join(output_dir, 'index.html')} 来查看下载的网站")
if __name__ == "__main__":
main()效果演示:

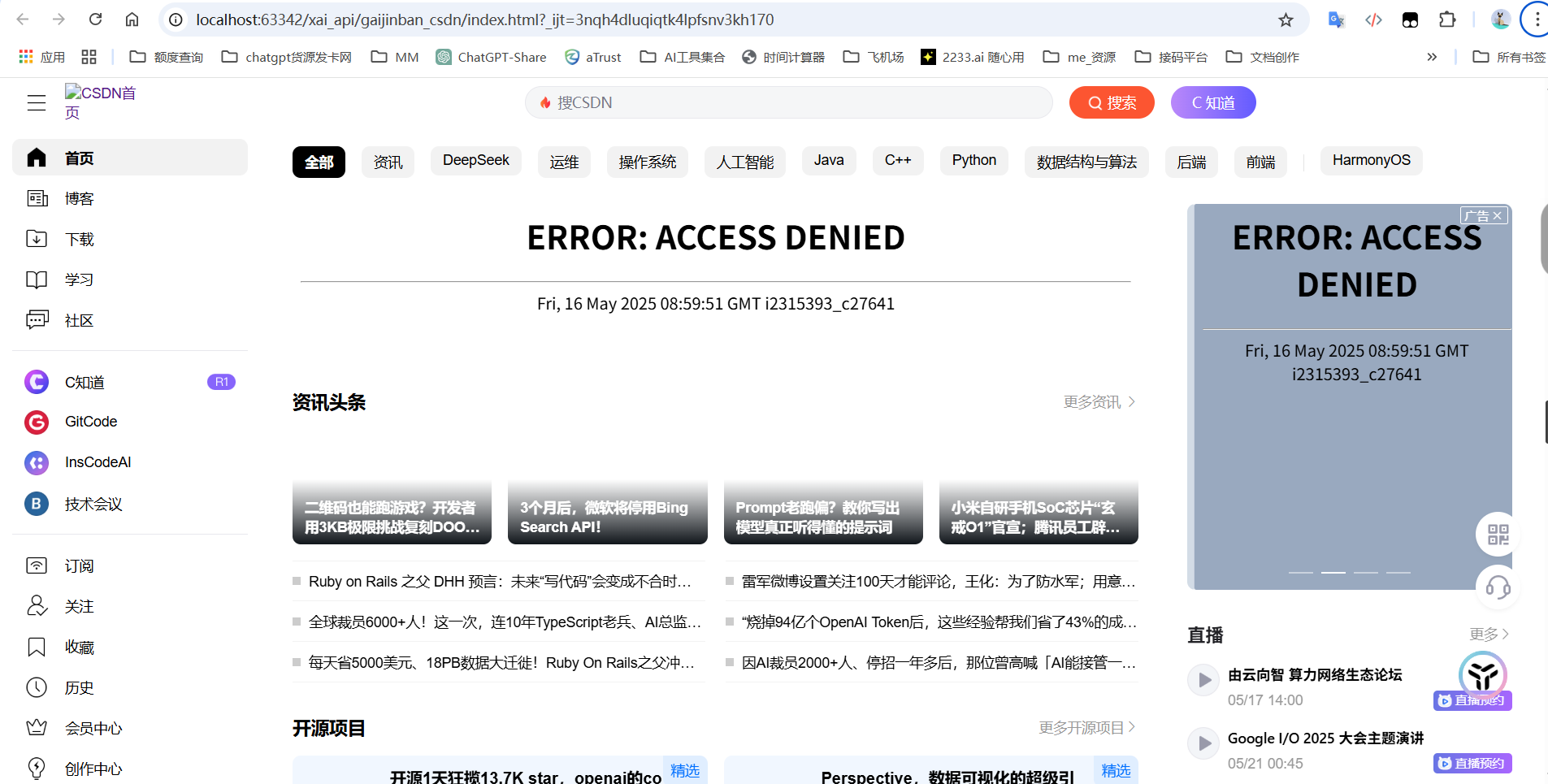
问题:
博客园的网站有一点问题:
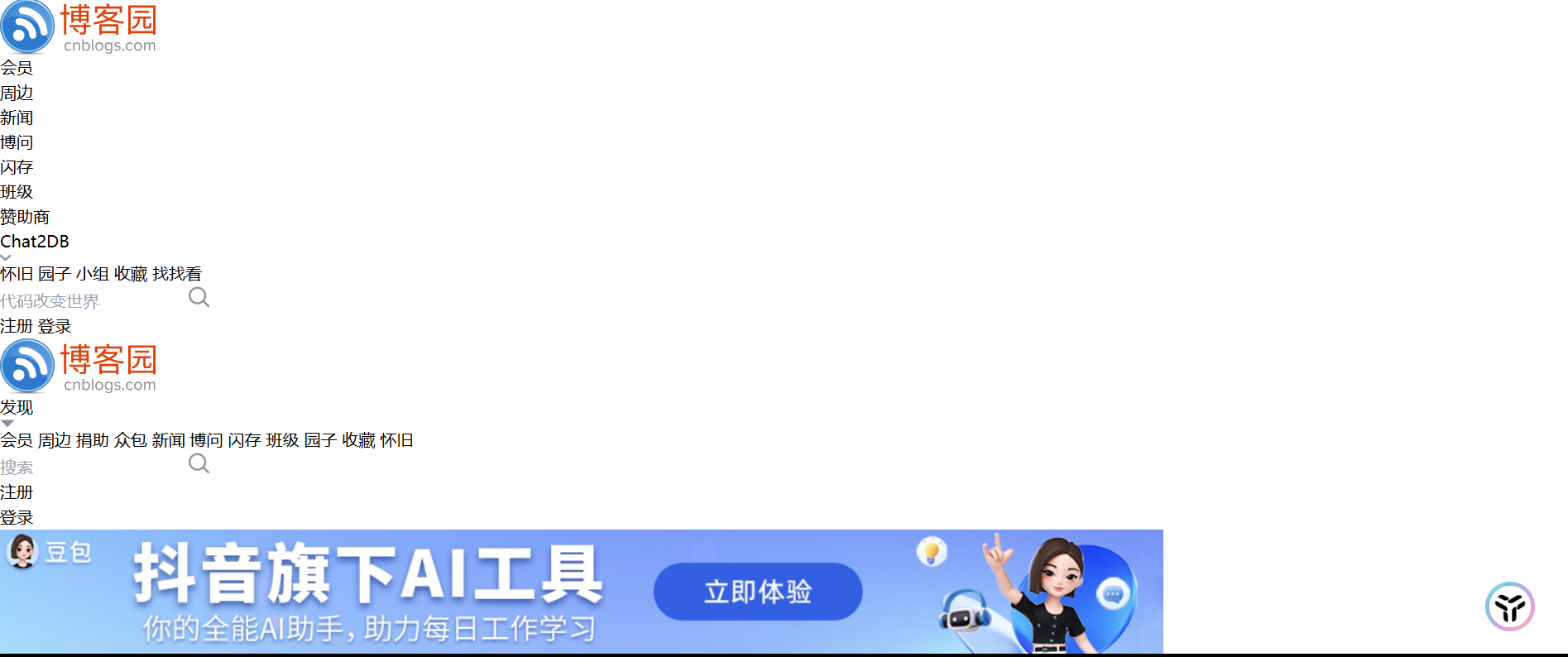
以后有时间看能不能搞一个通用的
目前就简单版和这个改进版先用着吧
这俩可以混合着用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









