






假如你正在使用关系型数据库开发一款健康类系统。业务发展很好,系统有很多活跃的新老用户,这些用户会和平台的医生团队进行交互,每天可能会生成数万甚至数十万级别的业务数据。这样的话,随着数据量越来越大,系统中的某些数据表的访问就会出现瓶颈,最典型的就是用于保存用户和医生日常交流数据的健康咨询表:

虽然从理论上讲,像健康咨询表这样位于关系型数据库中的单个表可以存储的数据能够达到亿条级别,但这时候访问性能就会变得很差。业界普遍认为,诸如MySQL这样的主流数据库,单表容量在千万以下是一项最佳实践,一旦超过这个量级,就需要考虑采用其他方案。那么问题就来了,我们如何应对日益增长的数据量呢?有没有成熟的解决方案呢?
答案是肯定的,这就是我们接下来要引入的分库分表技术。所谓分库分表,你可以简单理解为:将原来独立的数据库拆分成若干数据库,将原来数据量大的单个表拆分成若干个数据表,使得单一数据库、单一数据表的数据量变得足够小,从而达到提升数据库性能的效果。有时候,我们也把分库分表统称为是一种数据分片技术,因为从概念上讲,无论是分库还是分表,都是把一定数据划分成不同的数据片,并存储在不同的目标对象中。
讲到这里,你实际上已经明确了一点,无论是分库还是分表,本质上体现的都是一种对现有数据进行拆分的思想,而这种拆分思想又有两种不同的实现策略,即垂直拆分和水平拆分:

相比水平拆分,垂直拆分相对比较容易理解和实现,所以我们先来讨论这种拆分策略。在健康类系统中,用户在查看健康咨询表数据时,位于健康咨询首页的诸如咨询编号、医生编号等基础数据的访问频率显然要比咨询详情等明细数据更高,因为用户总是先定位到基础数据,然后再选择某一个咨询记录并查看明细。基于这两种数据的不同访问特性,我们可以把健康咨询这种单表进行拆分,根据访问频次来把咨询数据分别放在两张表中,如下所示:

由此可以,垂直分表的处理方式就是将一个表按照字段分成多张表,每个表存储其中一部分字段。在实现上,我们通常会把诸如详情类的低热度数据放在一张独立的表中。
通过垂直分表能得到来一定程度的性能提升,但毕竟拆分后的数据仍然都是位于同一个数据库实例中,每个表还是会竞争同一台数据库服务器中的CPU、内存、网络IO等资源,性能的提升限制很多。基于这一考虑,在有了垂直分表之后,我们就可以进一步引入垂直分库。
让我们回到案例,针对前面介绍的场景,分表之后的健康咨询表同样还是跟健康用户表等其他数据表存放在同一台服务器中。基于垂直分库思想,这时候,我们就可以把健康咨询相关的数据表单独拆分出来,放在一个独立的数据库中,如下图所示:

上图的效果就是垂直分库。从定义上讲,垂直分库是指将表进行分类,然后分布到不同的数据库实例上。显然,在高并发场景下,垂直分库能够一定程度的提升IO访问效率和数据库连接数,并降低单机硬件资源的瓶颈。
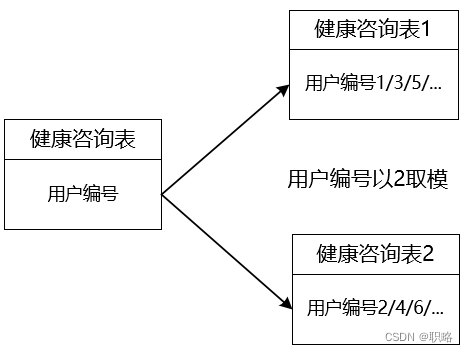
从前面的分析中我们不难明白,垂直拆分尽管实现起来比较简单,但并不能解决单表数据量过大这一核心问题。所以,现实中我们往往需要在垂直拆分的基础上再添加水平拆分机制。例如,我们可以对健康咨询库中的健康咨询表数据按照用户编号进行取模,然后分别存储在不同的数据库中,这就是水平分库的常见做法,如下所示:

可以看到,水平分库是把同一个表的数据按一定规则拆分到不同的数据库实例中。如果采用了上图中的水平分库方案,系统复杂度就会比垂直分库要高很多,因为我们就不得不面临一个问题,即如何知道目标数据位于哪一个数据库中呢?这就需要引入路由规则的概念。像上图中根据“用户编号以3取模”就是一条路由规则。
那么,我们如何来设计并实现这些路由规则呢?业界也存在一系列路由算法,常见的包括范围限定算法、预定义算法以及前面介绍的取模算法:

参照水平分库的思路,我们也可以对用户库中的用户表进行水平拆分,效果如下所示。也就是说,水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
到现在为止,我们已经把分库分表的基本概念梳理了一遍。你会发现这些概念理解起来并不是很复杂,但如何实现这些概念呢?你可以自己从零开始打造一套分库分表的实现工具,但显然并没有看上去那么简单,而我也不推荐你重复造轮子。幸好,目前业界已经存在一批分库分表的实现方案,主要分成客户端类分库分表和代理服务类分库分表两大类,接下去我也来介绍一下。

所谓客户端类分库分表,相当于在使用数据库的客户端应用程序中就完成了数据分片的实现。针对这种方案,因为没有独立的服务器组件,所以结构上比较简单。在Java世界中,通常做法会把客户端分片相关的处理逻辑单独抽离出来封装成一个独立的工具包,从而避免业务代码和分库分表逻辑过于耦合。而这个独立工具包的构建方法通常就是覆写现有的JDBC规范,这样,业务开发人员还是使用与JDBC规范完全兼容的一套API来操作数据库,但这套API的背后却自动完成了分库分表操作,效果如下:
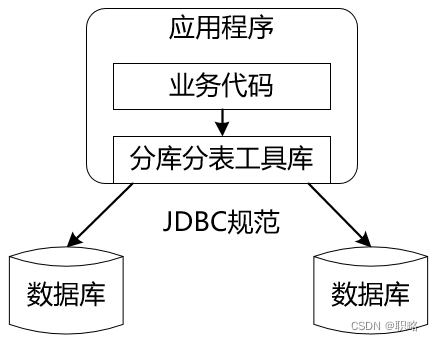
这种解决方案的优势在于分库分表操作对于业务而言是完全透明的。这样,普通业务开发人员只需要理解JDBC规范就可以自行实现分库分表,开发难度以及代码维护成本得到降低。
另一方面,代理服务类分库分表的解决方案也比较明确,顾名思义,就是采用了代理机制,也就是说在应用层和数据库层之间添加一个代理层。有了代理层之后,对内我们就可以把分片规则集中维护在这个代理层中,对外则同样提供与JDBC兼容的API给到应用层,其效果如下所示:
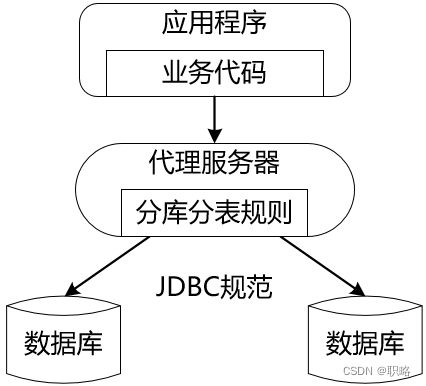
显然,代理服务器分库分表方案的优点在于解放了业务开发人员对分库分表规则的管理工作,而缺点就是添加了一层代理层,一方面会因为新增了一层网络传输而对性能产生一定的影响;另一方面,通常也需要专门的运维人员来确保代理服务器本身的稳定性。















 7459
7459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









