






软件制作过程
1. 数据获取与初步探查
- 首先从指定的 Excel 文件中读取数据,使用
pandas库的ExcelFile类来处理文件,获取文件中名为 ' 软件 222' 的工作表。 - 接着查看该工作表的数据基本信息和内容,包括数据的行数、列数、各列的数据类型以及前几行或全量数据(根据数据规模),从而对数据有一个初步的认识。
2. 数据分析与可视化
- 同学性别饼状图:使用
pandas的value_counts()方法统计不同性别的人数,然后利用matplotlib库绘制饼状图,以直观展示班级内男女生的占比情况。 - 同学所在省份中国地图可视化:通过
pandas统计各省份的学生人数,再使用pyecharts库创建中国地图,将各省份的学生数量映射到地图上,生成一个交互式的可视化图表,并保存为 HTML 文件。 - 所在城市柱状图:同样使用
pandas统计各城市的学生人数,利用matplotlib绘制柱状图,设置 x 轴标签旋转 90 度以避免标签重叠,清晰展示不同城市的学生分布数量。 - 签名词云化:提取所有签名数据,去除缺失值后合并为一个文本,使用正则表达式分割文本为单词,再用
collections.Counter统计词频。最后使用pyecharts库创建词云图,将词云图渲染为 HTML 文件。 - 成绩分布折线图:提取各学期的成绩列,计算每个学期的平均名次,使用
matplotlib绘制折线图,直观呈现成绩随学期的分布情况。 - 宿舍分布关系图:去除宿舍号为空的数据,使用
networkx和graphviz库创建有向图,将宿舍和学生作为节点,学生与所属宿舍之间的居住关系作为边,渲染图形为 PNG 图像并使用matplotlib显示。
设计思想
- 模块化设计:将整个数据分析和可视化过程拆分成多个独立的步骤,每个步骤完成一个特定的任务,如数据读取、统计分析、图形绘制等。这样可以提高代码的可读性和可维护性,便于后续的扩展和修改。
- 数据驱动:以数据为核心,根据数据的特点和需求选择合适的分析方法和可视化工具。例如,对于分类数据(如性别、省份、城市)使用饼状图、柱状图和地图可视化;对于文本数据(如签名)使用词云图;对于连续数据(如成绩)使用折线图。
- 用户友好性:在可视化过程中,尽量选择直观、易懂的图表类型,并添加必要的标题、标签和注释,方便用户理解数据。同时,将部分可视化结果保存为 HTML 文件,支持交互操作,提高用户体验。
一、微信好友
1、性别饼状图
import os
from pyecharts.charts import Pie
import csv
from pyecharts import options as opts
# 打印当前工作目录
print(f"当前工作目录: {os.getcwd()}")
# 1.读取csv文件,把性别信息读取出来
def getSex(filename):
lstsex = []
try:
with open(filename, 'r') as fr:
reader = csv.reader(fr)
for i in reader:
lstsex.append(i[4])
except FileNotFoundError:
print(f"错误:未找到文件 {filename},请检查文件路径和文件名。")
return lstsex
# 2.性别pyechart可视化
def VisualSexpyechart(lstsex):
if not lstsex:
return
sex = dict()
# 2.1提取好友性别信息,从1开始,因为第0个是自己
for f in lstsex[1:]:
if f == '1': # 男
sex["man"] = sex.get("man", 0) + 1
elif f == '2': # 女
sex["women"] = sex.get("women", 0) + 1
else: # 未知
sex["unknown"] = sex.get("unknown", 0) + 1
# 在屏幕上打印出来
total = len(lstsex[1:])
# 2.2打印出自己的好友性别比例
male_count = sex.get("man", 0)
female_count = sex.get("women", 0)
unknown_count = sex.get("unknown", 0)
print(f"男性好友:{male_count / total * 100:.2f}%\n女性好友:{female_count / total * 100:.2f}%\n不明性别好友:{unknown_count / total * 100:.2f}%")
# 2.3使用echarts饼状图
attr = ['男性好友', '女性好友', '不明性别好友']
value = [male_count, female_count, unknown_count]
# 饼状图用的数据格式是[(key1,value1),(key2,value2)],所以先使用zip函数将二者进行组合
data_pair = [list(z) for z in zip(attr, value)]
# 初始化配置项,内部可设置颜色
(
Pie(init_opts=opts.InitOpts(bg_color="white"))
.add(
# 系列名称,即该饼图的名称
series_name="性别分析",
# 系列数据项,格式为[(key1,value1),(key2,value2)]
data_pair=data_pair,
# 通过半径区分数据大小 radius 和 area 两种
rosetype='radius',
# 饼图的半径,设置成默认百分比,相对于容器高宽中较小的一项的一半
radius="55%",
# 饼图的圆心,第一项是相对于容器的宽度,第二项是相对于容器的高度
center=["50%", "50%"],
# 标签配置项
label_opts=opts.LabelOpts(is_show=True, position="center"),
)
# 全局设置
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(
# 名字
title="微信好友性别比例",
# 组件距离容器左侧的位置
pos_left="center",
# 组件距离容器上方的像素值
pos_top="20",
# 设置标题颜色
title_textstyle_opts=opts.TextStyleOpts(color="black"),
),
# 图例配置项,参数是否显示图里组件
legend_opts=opts.LegendOpts(is_show=True),
)
# 系列设置
.set_series_opts(
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a}<br/>{b}:{c}({d}%)"),
# 设置标签颜色
label_opts=opts.LabelOpts(color="teal"),
)
.render('好友性别比例饼状图.html')
)
# 3.执行主程序,得到所有好友性别
# 请确保文件路径和扩展名正确
VisualSexpyechart(getSex("D:\\pycharm\\pythonAndDataAnalysis\\我的微信好友信息.csv"))
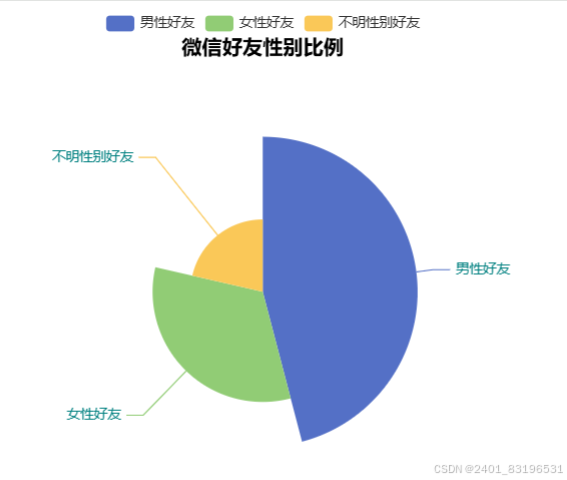
2、省份城市
from pyecharts import options as opts
from collections import Counter
from pyecharts.charts import Map
import csv
import re
import jieba
import operator
import os
# 分析好友所在省份及城市
def getcvsData(filename, index):
lstdata = []
with open(filename, 'r') as fr:
reader = csv.reader(fr)
for i in reader:
lstdata.append(i[index])
return lstdata
def VisualPropyecharts(lstprovince):
lstprovinceNew = []
lst1 = []
lst2 = []
# 2.1去掉空白的项
for i in lstprovince:
if i == "" or i == 'Province':
pass
else:
lstprovinceNew.append(i)
# 2.2统计每个城市出现的次数
data = Counter(lstprovinceNew).most_common(2) # 使用Counter类统计出现的次数,并转换为元组列表
for j in data:
lst1.append(j[0] + "省") # 省份必须写完整,比如山东省,黑龙江省,北京市,上海市
lst2.append(j[1])
print(lst1)
print(lst2)
# 根据省份数据生成地图
c = (
Map()
.add(
"例子",
[list(z) for z in zip(lst1, lst2)],
"china" # 显示省份
# "china-cities",#显示城市
)
.set_global_opts(
title_opts=opts.TitleOpts(title="微信好友省份分布图", subtitle="数据来源:微信好友", pos_right="center"),
visualmap_opts=opts.VisualMapOpts(max_=95),
legend_opts=opts.LegendOpts( # 设置图例配置项
pos_right="right", # 设置为水平居右
pos_bottom="bottom" # 设置为垂直居下
)
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 是否显示省市名称
)
return c
# 打印当前工作目录
print(f"当前工作目录: {os.getcwd()}")
# 好友所在城市及省份分布地图
try:
alist = getcvsData('我的微信好友信息.csv', 3)
VisualPropyecharts(alist).render(path='好友所在城市及省份分布.html')
print("文件渲染成功")
except Exception as e:
print(f"文件渲染出错: {e}")
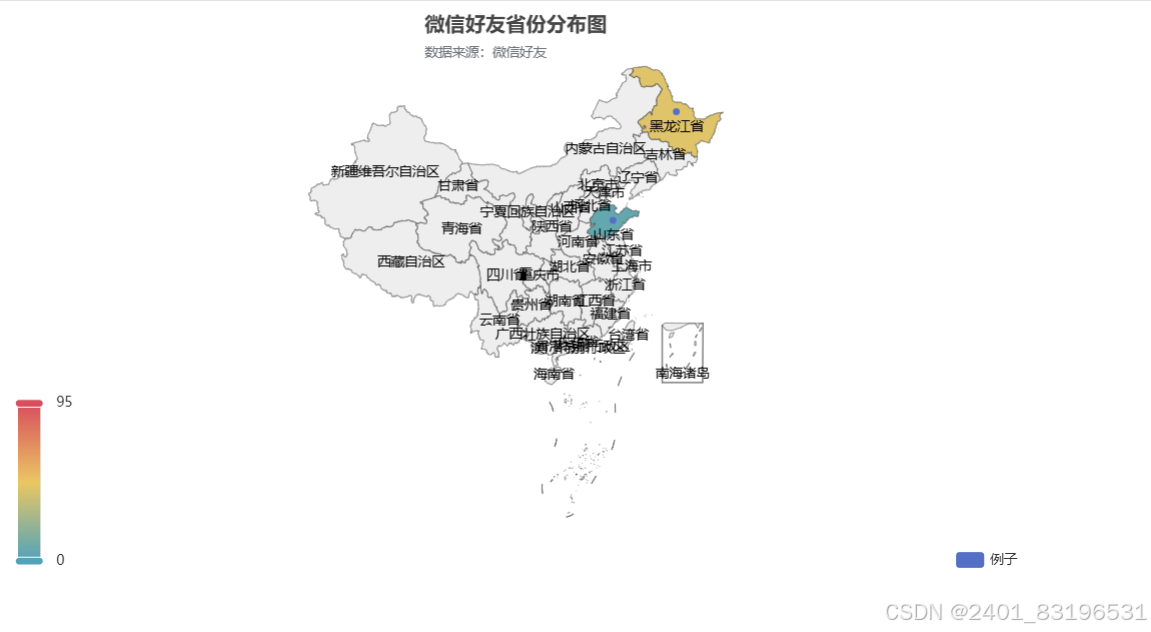
3、好友签名
import re
import jieba
import operator
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 对签名进行分词
def wordCloud():
# 加载文本数据
text_road = '好友个性签名.txt'
try:
with open(text_road, 'r', encoding='utf-8') as f:
sentence = f.read()
except FileNotFoundError:
print(f"未找到文件 {text_road}")
return
# 去掉标点符号
r = r"[_.!+-=——,$%^~,。?、~@#¥%……&*《》<>「」【】/0-9]"
text = re.sub(r, '', sentence)
# 对文本进行分词
wordlist_after_jieba = jieba.lcut(text)
# 去掉空格
words_dropped_space = [i.strip() for i in wordlist_after_jieba if i.strip()]
# 获取停用词 list
try:
with open('停用词.txt', encoding='UTF-8') as f:
stopwords = [line.strip() for line in f.readlines()]
except FileNotFoundError:
print("未找到停用词文件")
return
# 去停用词
words_dropped_stopwords = [i for i in words_dropped_space if i not in stopwords]
# 统计词及词数量,并按降序排序
words_count = {}
for word in words_dropped_stopwords:
words_count[word] = words_count.get(word, 0) + 1
sorted_words_count = sorted(words_count.items(), key=operator.itemgetter(1), reverse=True)
sorted_words_count = dict(sorted_words_count)
# 创建词云对象
wordcloud = WordCloud(font_path='simhei.ttf', background_color='white').generate_from_frequencies(sorted_words_count)
# 显示词云
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
return sorted_words_count
if __name__ == "__main__":
result = wordCloud()
if result:
print("词频统计结果:", result)

二、学生信息
1、性别
import os
from pyecharts.charts import Pie
import pandas as pd
from pyecharts import options as opts
# 打印当前工作目录
print(f"当前工作目录: {os.getcwd()}")
# 1. 读取 Excel 文件,把性别信息读取出来
def getSex(filename):
lstsex = []
try:
df = pd.read_excel(filename)
# 性别数据在第 5 列
lstsex = df.iloc[:, 5].tolist()
except FileNotFoundError:
print(f"错误:未找到文件 {filename},请检查文件路径和文件名。")
return lstsex
# 2. 性别 pyechart 可视化
def VisualSexpyechart(lstsex):
if not lstsex:
return
sex = dict()
# 2.1 提取性别信息
for f in lstsex[1:]:
if f == '男': # 修改为匹配实际数据中的男性标识
sex["man"] = sex.get("man", 0) + 1
elif f == '女': # 修改为匹配实际数据中的女性标识
sex["women"] = sex.get("women", 0) + 1
else: # 未知
sex["unknown"] = sex.get("unknown", 0) + 1
# 在屏幕上打印出来
total = len(lstsex[1:])
# 2.2 打印出性别比例
male_count = sex.get("man", 0)
female_count = sex.get("women", 0)
unknown_count = sex.get("unknown", 0)
print(f"男性:{male_count / total * 100:.2f}%\n女性:{female_count / total * 100:.2f}%\n不明性别:{unknown_count / total * 100:.2f}%")
# 2.3 使用 echarts 饼状图
attr = ['男性', '女性', '不明性别']
value = [male_count, female_count, unknown_count]
# 饼状图用的数据格式是[(key1,value1),(key2,value2)],所以先使用 zip 函数将二者进行组合
data_pair = [list(z) for z in zip(attr, value)]
# 初始化配置项,内部可设置颜色
(
Pie(init_opts=opts.InitOpts(bg_color="white"))
.add(
# 系列名称,即该饼图的名称
series_name="性别分析",
# 系列数据项,格式为[(key1,value1),(key2,value2)]
data_pair=data_pair,
# 通过半径区分数据大小 radius 和 area 两种
rosetype='radius',
# 饼图的半径,设置成默认百分比,相对于容器高宽中较小的一项的一半
radius="55%",
# 饼图的圆心,第一项是相对于容器的宽度,第二项是相对于容器的高度
center=["50%", "50%"],
# 标签配置项
label_opts=opts.LabelOpts(is_show=True, position="center"),
)
# 全局设置
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(
# 名字
title="软件222学生性别比例",
# 组件距离容器左侧的位置
pos_left="center",
# 组件距离容器上方的像素值
pos_top="20",
# 设置标题颜色
title_textstyle_opts=opts.TextStyleOpts(color="black"),
),
# 图例配置项,参数是否显示图里组件
legend_opts=opts.LegendOpts(is_show=True),
)
# 系列设置
.set_series_opts(
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a}<br/>{b}:{c}({d}%)"),
# 设置标签颜色
label_opts=opts.LabelOpts(color="teal"),
)
.render('学生性别比例饼状图.html')
)
# 3. 执行主程序,得到所有学生性别
VisualSexpyechart(getSex("D:\\pycharm\\pythonAndDataAnalysis\\软件222学生详细名单.xlsx"))
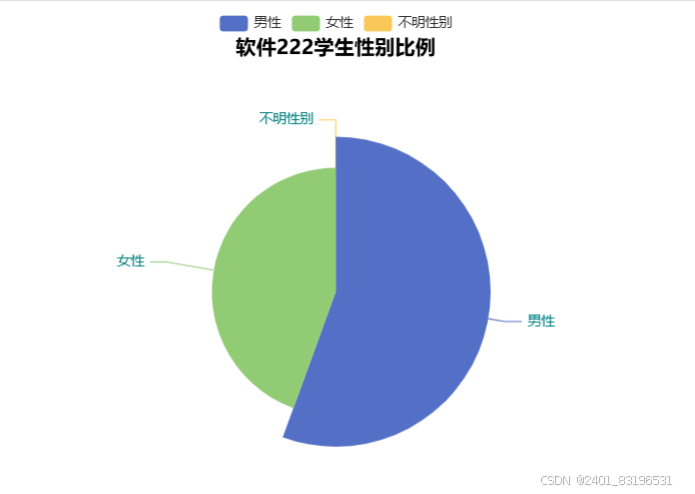
2、同学所在省份中国地图可视化
from pyecharts import options as opts
from collections import Counter
from pyecharts.charts import Map
import pandas as pd
import os
# 分析好友所在省份及城市
def getcvsData(filename, index):
lstdata = []
try:
# 使用 pandas 读取 Excel 文件
df = pd.read_excel(filename)
# 提取指定列的数据
lstdata = df.iloc[:, index].tolist()
except Exception as e:
print(f"读取文件时出错: {e}")
return lstdata
def VisualPropyecharts(lstprovince):
lstprovinceNew = []
lst1 = []
lst2 = []
# 2.1 去掉空白的项
for i in lstprovince:
if i == "" or i == 'Province':
continue
lstprovinceNew.append(i)
# 2.2 统计每个省份出现的次数
data = Counter(lstprovinceNew).most_common(2) # 使用 Counter 类统计出现的次数,并转换为元组列表
for j in data:
# 处理直辖市和特别行政区
if j[0] in ['北京', '天津', '上海', '重庆', '香港', '澳门']:
lst1.append(j[0] + "市" if j[0] != '香港' and j[0] != '澳门' else j[0] + "特别行政区")
else:
lst1.append(j[0] + "省")
lst2.append(j[1])
print(lst1)
print(lst2)
# 根据省份数据生成地图
c = (
Map()
.add(
"例子",
[list(z) for z in zip(lst1, lst2)],
"china" # 显示省份
# "china-cities",#显示城市
)
.set_global_opts(
title_opts=opts.TitleOpts(title="同学省份分布图", subtitle="数据来源:软件222班同学", pos_right="center"),
visualmap_opts=opts.VisualMapOpts(max_=95),
legend_opts=opts.LegendOpts( # 设置图例配置项
pos_right="right", # 设置为水平居右
pos_bottom="bottom" # 设置为垂直居下
)
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 是否显示省市名称
)
return c
# 打印当前工作目录
print(f"当前工作目录: {os.getcwd()}")
# 好友所在城市及省份分布地图
try:
alist = getcvsData('软件222学生详细名单.xlsx', 6)
VisualPropyecharts(alist).render(path='同学所在城市及省份分布.html')
print("文件渲染成功")
except Exception as e:
print(f"文件渲染出错: {e}")

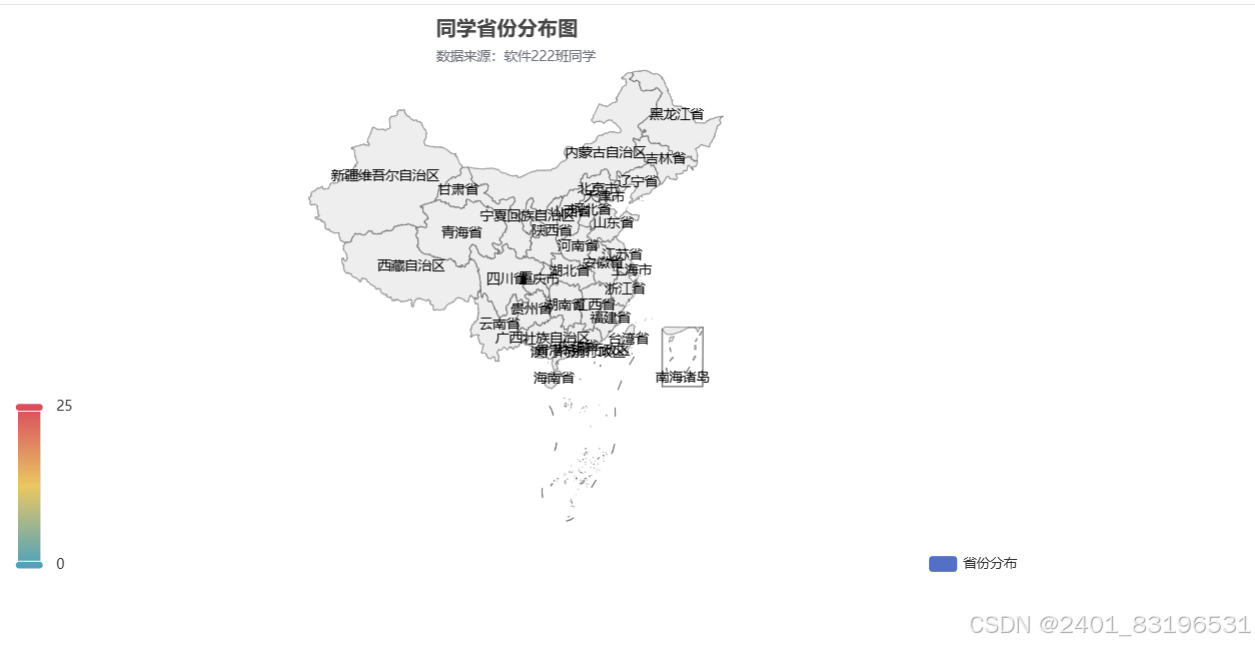
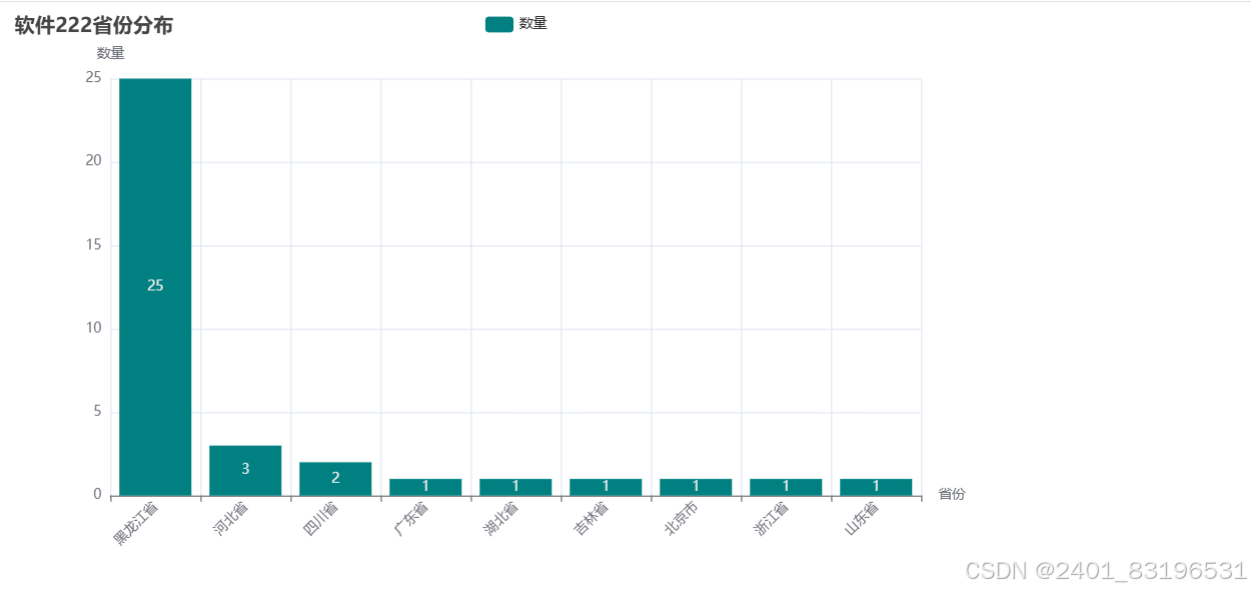
3、所在城市柱状图可视化
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
from collections import Counter
def getPro(filename):
lst1 = []
try:
df = pd.read_excel(filename)
# 假设省份信息在第7列(索引为6)
lst1 = df.iloc[:, 6].tolist()
# 处理可能存在的空值
lst1 = [str(i).strip() if pd.notna(i) else '' for i in lst1]
except FileNotFoundError:
print(f"错误:文件 {filename} 未找到。")
except UnicodeDecodeError:
print(f"错误:无法使用 utf - 8 编码解码文件,请尝试其他编码。")
except Exception as e:
print(f"错误:读取文件时出现异常:{e}")
return lst1
def filter_empty(lst):
result = []
for i in lst:
if isinstance(i, str) and i.strip():
result.append(i)
return result
def get_top_n(lst, n):
data = Counter(lst).most_common(n)
keys = [j[0] for j in data]
values = [j[1] for j in data]
return keys, values
def Visualpropyechart(lstprovince):
lstprovinceNew = filter_empty(lstprovince)
lst1, lst2 = get_top_n(lstprovinceNew, 100)
bar = (
Bar()
.add_xaxis(lst1)
.add_yaxis("数量", lst2, color='teal')
.set_global_opts(
title_opts=opts.TitleOpts(title='软件222省份分布'),
yaxis_opts=opts.AxisOpts(name="数量"),
xaxis_opts=opts.AxisOpts(
name="省份",
axislabel_opts=opts.LabelOpts(rotate=45)
)
)
.render('软件222省份分布.html')
)
return bar
# 执行主程序
if __name__ == "__main__":
filename = "软件222学生详细名单.xlsx"
a = getPro(filename)
if a:
Visualpropyechart(a)
4、签名词云化

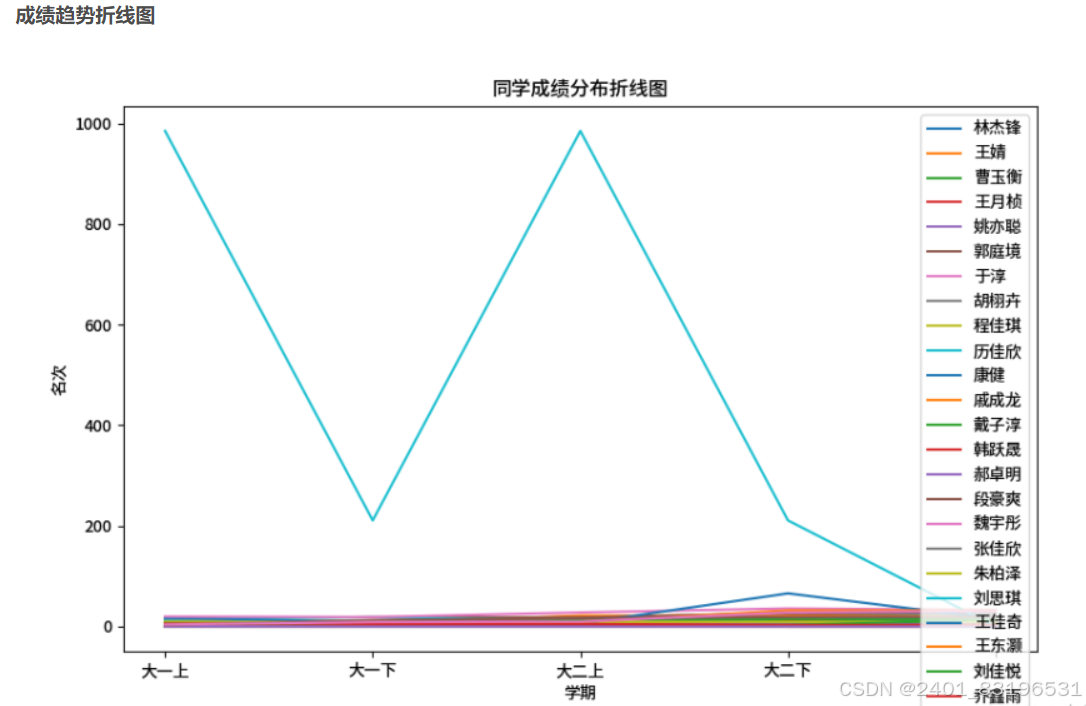
5、成绩分布折线图可视化
6、宿舍分布关系图
import openpyxl
from pyecharts.charts import Graph
from pyecharts import options as opts
def getRoom(filename):
Room = {}
try:
# 打开 Excel 文件
workbook = openpyxl.load_workbook(filename)
# 获取第一个工作表
sheet = workbook.active
rows = sheet.max_row
for i in range(1, rows + 1):
if i == 1: # 跳过第一行
continue
# 获取指定列的值
Room[sheet.cell(row=i, column=4).value] = sheet.cell(row=i, column=10).value
except FileNotFoundError:
print(f"错误:未找到文件 {filename}")
except Exception as e:
print(f"发生未知错误:{e}")
print(Room)
return Room
# 性别 pyechart 可视化
def RoomSee(Room):
nodes = []
for i in Room:
nodes.append({"name": i, "symbolSize": 5})
print(nodes)
links = []
for i in Room:
for j in Room:
if Room[i] == Room[j]:
links.append({"source": i, "target": j})
print(links)
graph = (
Graph()
.add(
"",
nodes,
links,
categories=None, # 结点分类的类目,结点可以指定分类,也可以不指定。
is_focusnode=True, # 是否在鼠标移到节点上的时候突出显示节点以及节点
is_roam=True,
layout="force", # 布局类型,默认 force=力引导图,_circular=环形布局
edge_length=220, # 力布局下边的两个节点之间的距离,这个距离也
gravity=0.5, # 点受到的向中心的引力因子。TODO 该值越大节点越往
repulsion=100, # 节点之间的斥力因子。默认为 50,TODO 值越大则
label_opts=opts.LabelOpts(is_show=True, rotate=0 if not True else None), # 设置标签显示和旋转
linestyle_opts=opts.LineStyleOpts(curve=0.2) # 线的弯曲度
)
.set_global_opts(title_opts=opts.TitleOpts(title="关系图示例"))
)
graph.render("1.html")
RoomSee(getRoom("软件222学生详细名单.xlsx"))

总结
- 成果:通过对学生信息表的数据分析和可视化,成功展示了班级学生的性别分布、生源地分布、签名关键词、成绩变化以及宿舍居住关系等信息。这些可视化结果能够帮助我们快速了解班级学生的整体情况,发现潜在的规律和趋势。
- 技术应用:在整个过程中,充分利用了
pandas进行数据处理和统计分析,matplotlib和pyecharts进行可视化,networkx和graphviz进行关系图绘制。这些工具的结合使用,使得数据处理和可视化变得高效和便捷。 - 局限性:数据集中可能存在部分缺失值,在分析过程中简单地进行了忽略处理,可能会对结果产生一定的影响。此外,可视化结果主要基于现有的数据,缺乏对数据的深入挖掘和预测分析。
未来展望
- 数据补充与清洗:进一步收集和补充相关数据,减少数据缺失值的影响。同时,对数据进行更严格的清洗和预处理,提高数据质量。
- 深入分析:除了现有的描述性统计分析和可视化,尝试进行更深入的数据分析,如相关性分析、聚类分析、预测分析等,以挖掘更多有价值的信息。
- 用户交互:将可视化结果集成到一个 Web 应用程序中,提供更多的交互功能,如数据筛选、排序、钻取等,方便用户根据自己的需求进行个性化的数据分析和探索。
- 实时更新:如果学生信息表是动态更新的,可以实现数据的实时同步和可视化结果的实时更新,确保信息的及时性和准确性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









