






论文简介
- 作者
Mingkai Chen, Minghao Liu, Wenjun Wang, Haie Dou, Lei Wang - 发表期刊or会议
《IEEE》 - 发表时间
2023年
摘要:
本文提出了一种基于深度学习的跨模态语义通信方法,其中语义编码和解码都有独特的设计。在低信噪比场景下。 与传统方法相比,跨模态语义通信的相似度提高了53%以上,证明了该方法的优越性和可行性。按照我的理解,主要将该文章分为三个重点,笔记也就只记录这三个重点,其他细节请读原文获悉。
一、系统模型框架
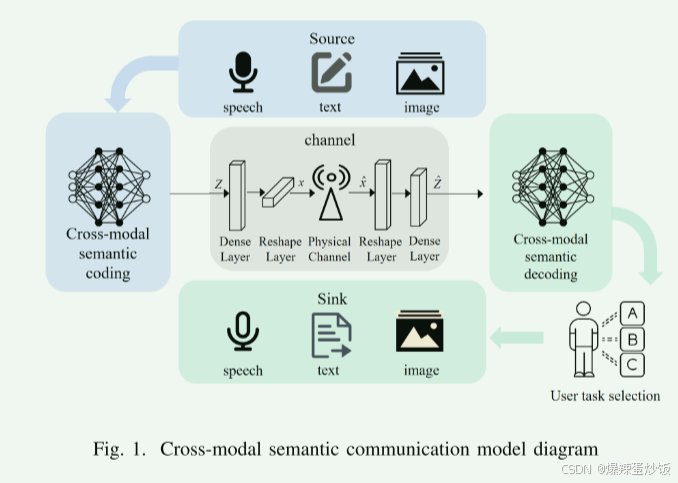
首先区别语义通信和传统通信(香农..),传统通信确保数据(比特流)的可靠传输,不关心数据内容的意义。而语义通信理解和传递信息的语义(含义、意图、上下文),以实现高效的信息交互。此外在处理层次上传统通信基于语法层(物理层、数据链路层等),关注信号编码、信道纠错、数据包完整性。而语义通信基于语义层(知识层、意图层),结合自然语言处理(NLP)、知识图谱、AI模型,提取信息的意义。其他异同自行索搜。
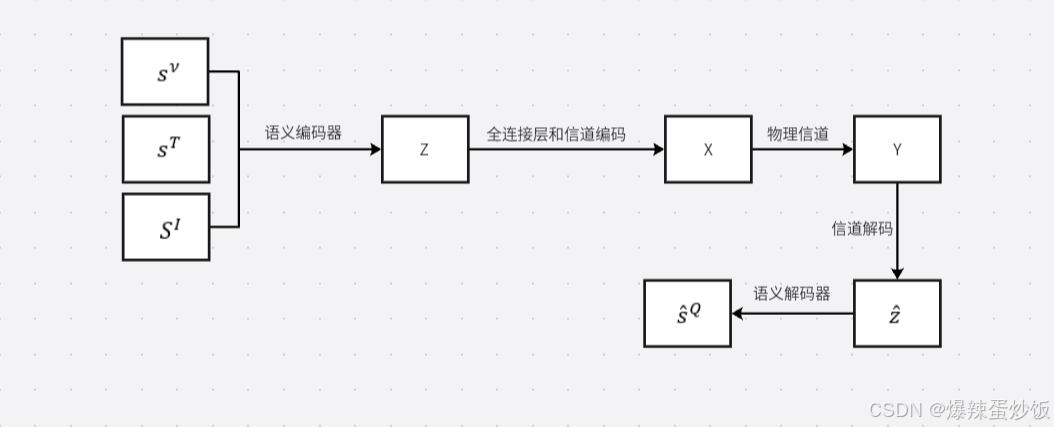
图1为原论文中给出的系统模型。显然,整个过程为:输入数据经过跨模态语义编码器后,在经过一个密度层(也叫全连接层),在经过一层Reshape layer(需要转换成适应无线信道环境的编码形式),经过物理信道传输后,再进行信道解码和语义解码最后输出数据。
流程图如下:
二、跨模态语义通信评估
为了满足对多模态甚至跨模态数据内容进行差异化评估的需求,论文提出了一种跨模态语义通信评估。 它包含一个孪生网络和一个伪孪生网络融合架构。(不了解孪生网络的可以参考下面的文章)孪生网络(Siamese Network)。伪孪生网络就是不共享参数。
1. Siamese网络(相同模态评估)
-
适用场景:当发送端和接收端处理的是同一模态(例如均为文本或图像)时,使用Siamese网络。
-
网络结构:
-
发送端和接收端的信号通过同一个编码子网络处理,且该子网络的权重完全共享。
-
输入信号被映射到同一向量空间,生成两个嵌入向量(发送端的 U 和接收端的 Û)。
-
相似度计算:通过余弦相似度衡量两个嵌入向量的相似性:
-
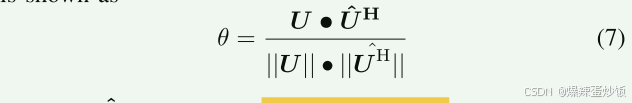
值越接近1,相似度越高。
2. 伪Siamese网络(跨模态评估)
-
适用场景:当发送端和接收端处理的是不同模态(例如文本与图像、语音与文本)时,使用伪Siamese网络。
-
网络结构:
-
两路输入分别通过独立的编码子网络处理,权重不共享。
-
不同模态的嵌入向量(如文本的 U 和图像的 Ĝ)被映射到不同向量空间。
-
-
相似度计算:同样使用余弦相似度,但需适应不同向量空间:
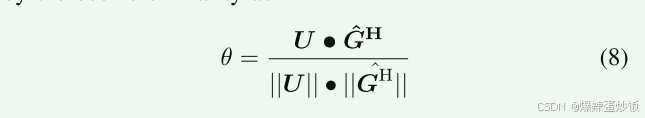
此时,相似度反映跨模态语义的关联性。
同时,还有一项我认为很重要的作用,反向传播优化:相似度计算结果(θ)作为损失函数的一部分,反向传播调整编码器(α、β)和解码器(γ、φ)的参数,从而提升语义传输的鲁棒性。
核心:
-
权重共享:Siamese网络通过共享权重强制同一模态的编码一致性,而伪Siamese网络通过独立权重适配跨模态差异。
-
余弦相似度:作为衡量标准,其值直接反映语义保留程度,指导网络优化。
-
任务驱动:用户需求动态调整解码策略,确保输出模态与任务高度匹配。
三、语义编码过程
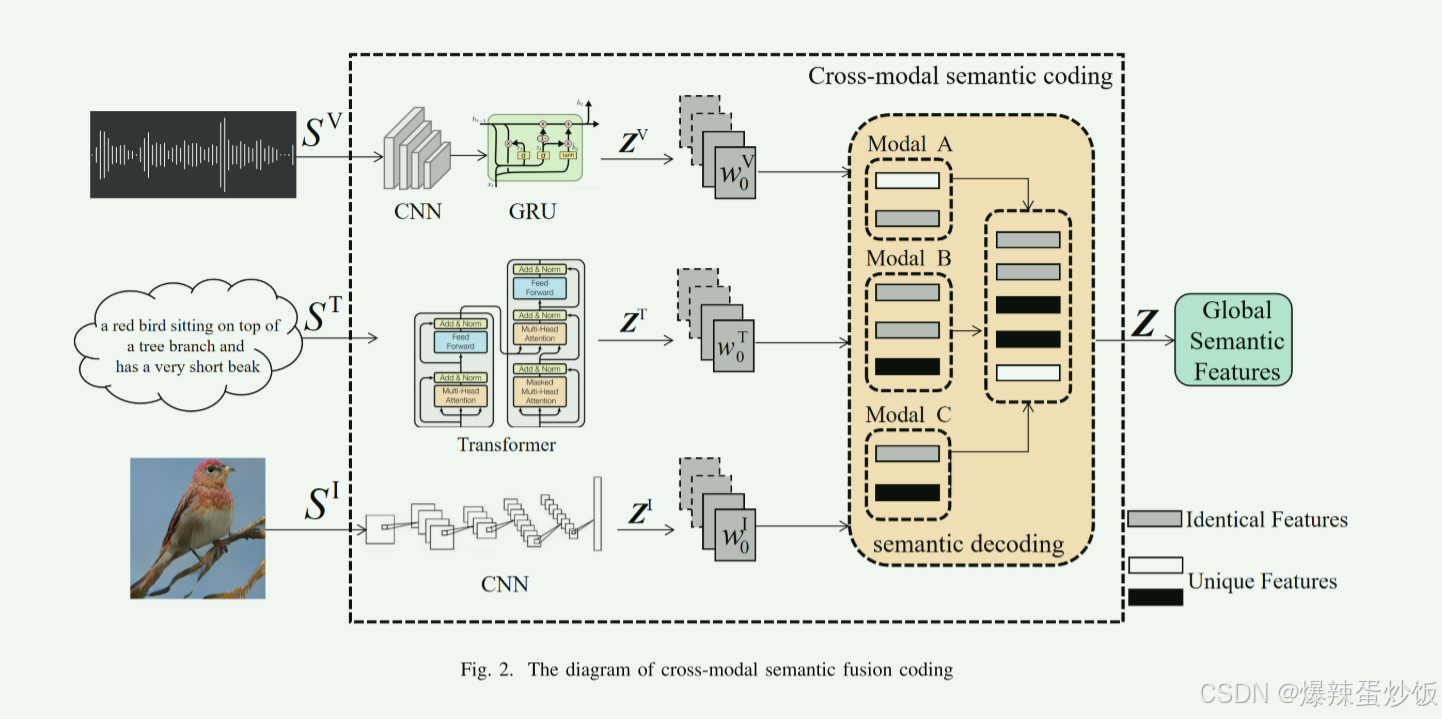
1.中间语义向量
首先要将不同模态的数据提取为中间语义向量,由于模态数据的特点和处理方法不同,预处理过程中需要针对模态数据的结构设计相应的语义提取方法。(就是不同模态需要不同的语义特征提取方法)。
(1)speech类型:
由于语音信号输入容易产生噪声,需要先经过去噪模块(谱减法),将去噪后的频谱输入门递归单元(GRU)和卷积神经网络(CNN),最后输出中间向量。参考文章:语音去噪——谱减法(Spectral Subtraction)
(2)text类型:
对于文本,在语义提取中引入了Transformer,用于自然语言处理中提取文本语义和压缩语义信息。 提取中间语义向量。
(3)Image类型:
对于图像信号,需要将图像映射到CNN之后的中间语义向量。
2.特征融合通过Frobenius norm.
论文在语义编码这一部分设计了中间语义特征融合,旨在通过衡量不同模态特征之间的相似性,保留独特特征并融合共性特征(就是高相似度舍去,低相似度保留)。
首先要了解什么是Frobenius norm。可以参考下面文章:弗罗贝尼乌斯范数(Frobenius norm)
它本质上是将矩阵“展开”为一个向量后计算其欧氏范数(L2范数)。
整个过程为,先确定某个模态为主模态(三者都可以作为主模态),通过引入Frobenius norm,计算主模态和其他加权模态的相似性,通过Sigmoid函数将范数值压缩到[0,1],通过1−σ(⋅)反转逻辑,使得高相似性对应低η值{(公式9和10)}。最后融合(公式11)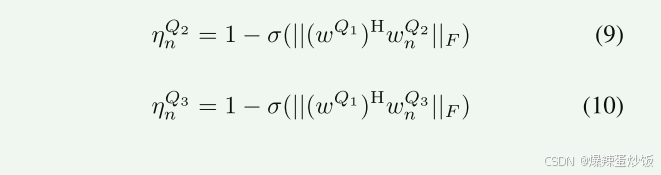
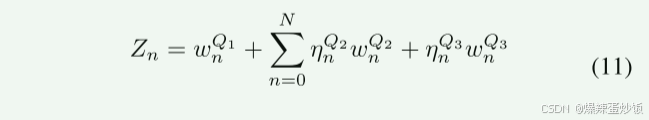
核心在于将高相似度的语义信息舍去,而留下低相似度信息。(因为高相似度会使η值为0,所以就形成了舍去。)
ps:还有我感觉需要注意的是,计算相似性就是F范数时候, 是主模态的某一时刻特征和加权模态的所有时刻特征计算(需要自己好好思考下)。
3.为什么舍去高相似度?
第一次读的时候不是很理解,为什么要舍去高相似度的信息,反而留下低相似度信息,难道不应该是根据高相似使跨模态之间对齐,减少语义失真度吗?然后我就问了AI,给出以下回答:
(1)语义互补性
-
多模态本质:不同模态(如文本、图像、语音)承载的语义信息可能部分重叠,但更多是互补的。例如:
-
文本描述“一只柯基在草地上玩球”,可能未提及“天空的蓝色”或“草的纹理”。
-
图像包含视觉细节(如颜色、空间布局),这些可能是文本未覆盖的独特信息。
-
-
保留独特信息可确保接收端恢复完整的语义场景,避免信息缺失。
(2)任务多样性
-
用户需求差异:接收端任务可能多样化,例如:
-
图像生成任务:需要文本未提及的细节(如背景环境)。
-
问答任务:需要跨模态关联的隐含信息(如通过图像推断文本未明示的动作)。
-
-
独特信息为下游任务提供灵活性和扩展性。
(3)抗噪声与鲁棒性
-
低信噪比(SNR)场景:在噪声干扰下,高相似性特征可能包含错误匹配(如噪声导致的虚假关联)。
-
独特信息因与其他模态关联度低,更可能是真实语义的补充,增强系统鲁棒性。
总结:
这篇文章和我读的上篇文章《CA DeepSC: Cross-Modal Alignment for
Multi-Modal Semantic Communications》应该非常有关联之处。感觉CA DeepSC这个系统模型就是根据这篇论文延申而来。按照时间顺序,应该先有这篇论文再有CA DeepSC这篇。
仔细想想也是很有意思,两篇论文在整个系统框架上大同小异,主要在语义编码部分有区别,一个是引入Frobenius norm进行语义特征相融,保留跨模态数据低相似度部分,舍去高相似部分。另一个是引入Shapley值,计算边际贡献度,从而训练语义编码器增强对齐,且能指导辅助修正网络。两个语义编码器正好相反,一个保留高相似度,一个保留低相似度。
连着读这两篇文章真的会引发自己脑中思想的博弈,一会儿想到这个文章中的某个点,一会儿想到另一个文章中的某个点,几个点有时候矛盾,有时候又相互证实,总体下来还是很有意思的。当然,我对着两篇的论文理解还有限,文中也有很多我在下面思考的东西没法描述,写出来的东西可能会有很多错误,希望各位指正(温柔一些,不要言语犀利)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









