






前言
本文篇幅较长,涵盖多个内容的讲解和补充。如有需要,请找对应篇幅学习,如有内容歧义,请留言指正!!
关于链表,你需要知道这些
-
链表的理论基础
- 链表的组成
- 链表的类型
- 怎么定义构建一个链表
- 链表的基本操作:增删改查
- 链表和数组的差别
额外补充:构造函数和析构函数的解析
-
链表的经典题目
- 反转链表
- 两两交换链表中的元素
- 删除链表的倒数第n个元素
- 链表相交
- 环形链表
额外不成:虚拟头节点
如果还有其他链表知识点,后续我会进行补充~
链表的理论基础
链表的组成
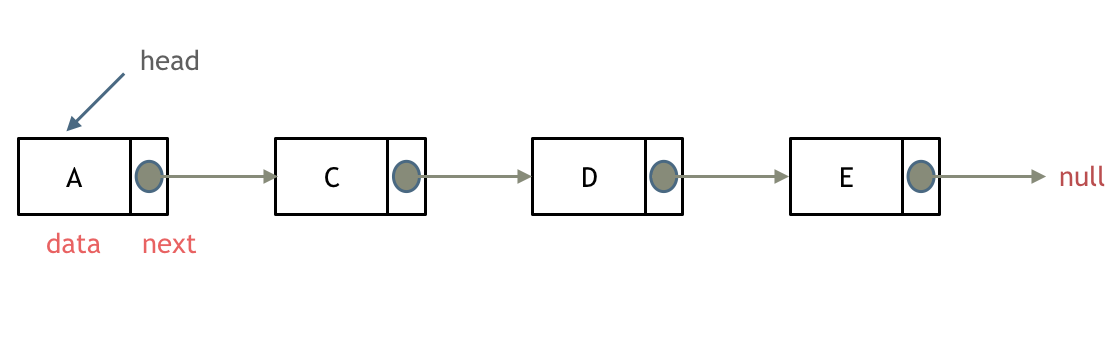
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。
如图所示:
链表的类型
单链表
上图就是单链表
双链表
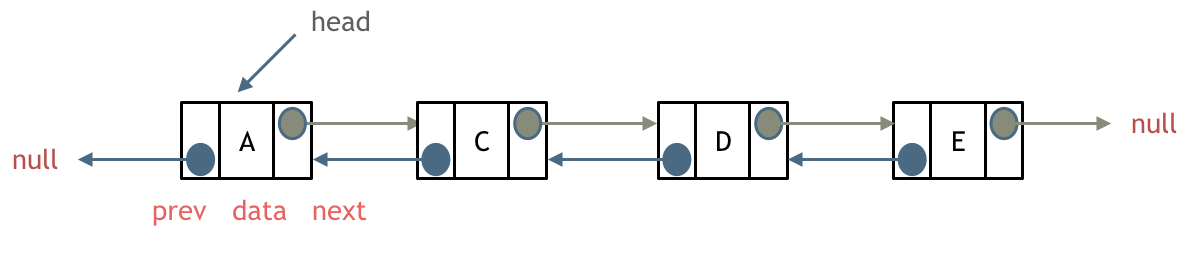
单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。
如图所示:
循环链表
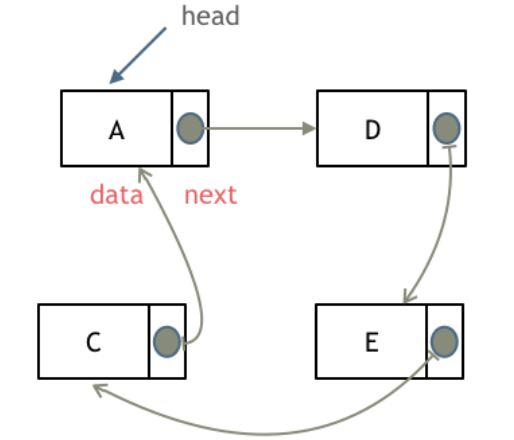
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
如图所示:
怎么定义构建一个链表
构造链表分两步:
- 构造链表节点结构体
- 构造链表类结构体
我们先来实现构造链表节点结构体
首先,我们定义一个结构体/类(C++中结构体和类的含义大致相同,此处不作区分,根据个人习惯,下文统一两者按“类”讨论)
其成员变量有两个:
- 节点上储存的元素val
- 指向下一个节点的指针next
struct ListNode{
int data; //整型数据
ListNode* next; //节点指针
};
我们定义完链表节点了吗?还没有,我们需要用一个函数来实现对链表节点的初始化
对此,我们还差一个内容需要补充:构造函数和析构函数
构造函数
在C++中,类有六个默认成员函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 赋值操作符重载
- 取地址操作符重载
- const修饰的取地址操作符重载
其中常用的是构造函数和析构函数
默认成员函数是指:当你构造一个类时,编译器会自动默认在类中定义上述空成员函数(空:没有任何含义和作用),哪怕你没有定义说明上述6个成员函数。如果你定义了其中一个或多个成员函数,编译器会将其替换掉空成员函数
例如:
class Student{
int number;
int year;
int score;
//Student(){}
};
建议看完下面,再反过来看这个例子
构造函数是用来初始化类成员的一种函数
我们都知道每一个类Class,都可以定义很多成员类,每一个成员子类也都包含类Class中的成员变量。那一个个定义成员子类太过麻烦,程序员就想到:不妨在类中构造一个函数接口来定义成员子类,这个接口就是构造函数
怎么写一个构造函数,或者说,构造函数有什么特性?
-
构造函数名与类名相同
我们规定:类是什么名,构造函数就是什么名
比如:定义一个类Class Student,那他的构造函数名就是Student
-
无返回值
即构造函数是void类型,调用时直接构造定义一个成员子类
-
对象实例化时编译器自动调用对应的构造函数
-
构造函数可以重载
-
如果用户没有定义构造函数,编译器会自动生成一个无参的默认构造函数;如果用户定义了构造函数,编译器将不再生成。
-
无参的构造函数和全缺省的构造函数都称为默认构造函数,并且默认构造函数只能有一个。注意:无参构造函数、全缺省构造函数、我们没写编译器默认生成的构造函数,都可以认为是默认构造函数。
构造函数的写法分为有参和无参
#include<iostream>
using namespace std;
class Date
{
public:
Date()//构造函数1(无参)
{
_year = 0;
_month = 0;
_day = 0;
}
Date(int year, int month, int day)//构造函数2(有参)
{
_year = year;
_month = month;
_day = day;
}
Date(int year)//构造函数3(有参)
{
_year = year;
_month = 12;
_day = 30;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
//实例化对象就会自动调用构造函数,因此在实例化时可以执行直接传参
Date dt1;//调用时没有传递实参,调构造函数1
Date dt2(2022,2,22);//调用时传递了实参,则调构造函数2
Date dt3(2022);//调用时只传入一个参数,则调构造函数3
return 0;
}
对于有参而言,既可以传入一个变量,也可以传入多个变量
上述代码体现了构造函数的特性
析构函数
构造函数是用来删除类成员的一种函数
当我们定义了许多类Class的诸多成员子类,并且想删除其中的某个或多个成员子类来释放空间时,我们就需要使用析构函数
析构函数命名与构造函数命名不同,需要在类名前加" ~ "表示析构函数
例:
class Student{
int year;
int number;
int score;
~Student(); //表示析构函数
};
析构函数的特征:
- 函数名是在类名前加“ ~ “
- 一个类只存在一个析构函数
- 析构函数由系统自动调用
- 无返回值
- 不能带有形参
即不需要输入变量
析构函数与构造函数不同,需要详细对函数进行定义。对于面向不同的数据结构和类时,析构函数的写法也不同,但总体思想是对成员子类进行删除和释放内存
struct ListNode{
int data; //整型数据
ListNode* next; //节点指针
};
书归上回,所以,对于这串代码,我们并没有写完对链表节点的初始化。因为一个链表不可能只有一个节点,那么对于ListNode类来说,我们需要定义一个构造函数,不断调用该函数接口生成成员子类节点。
struct ListNode{
int data;
ListNode* next;
ListNode(int x) : data(x), next(NULL) {} //单参构造函数
};
接下来我们就需要初始化链表类
对于一个链表,主要包含两个信息(即成员变量)
- 头节点 head
- 长度 size
因为链表是连续的,所以我们只需要知道头节点,通过不断循环遍历,指向下一节点指针,我们就可以实现遍历整个链表
构造如下:
class LinkedList{
public:
ListNode* head;
int size;
LinkedList() : head(NULL), size(0) {}
};
对于链表来说,我们还需要对他实现增删改查的操作
链表的基本操作:增删改查
删除节点
删除节点D,如图:
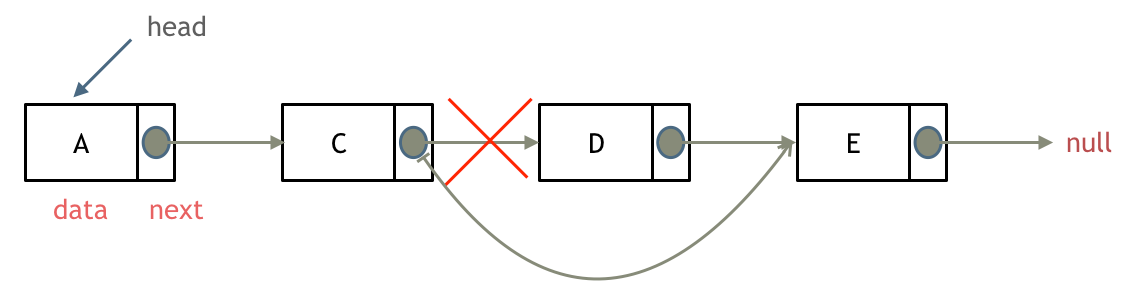
只要将C节点的next指针 指向E节点就可以了。
那有同学说了,D节点不是依然存留在内存里么?只不过是没有在这个链表里而已。
是这样的,所以在C++里最好是再手动释放这个D节点,释放这块内存。
其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
void LinkedList::remove(int i){
if(i < 0 || i > size){
throw std::out_of_range( " Invalid position ");
}
if(i == 0){
ListNode* temp = head;
head = head->next;
delete temp;
}else{
ListNode* curr = head;
for(int j = 0;j < i - 1;j++){
curr = curr->next;
}
ListNode* temp = curr->next;
curr->next = curr->next->next;
delete temp;
}
size--;
}
添加节点
如图:
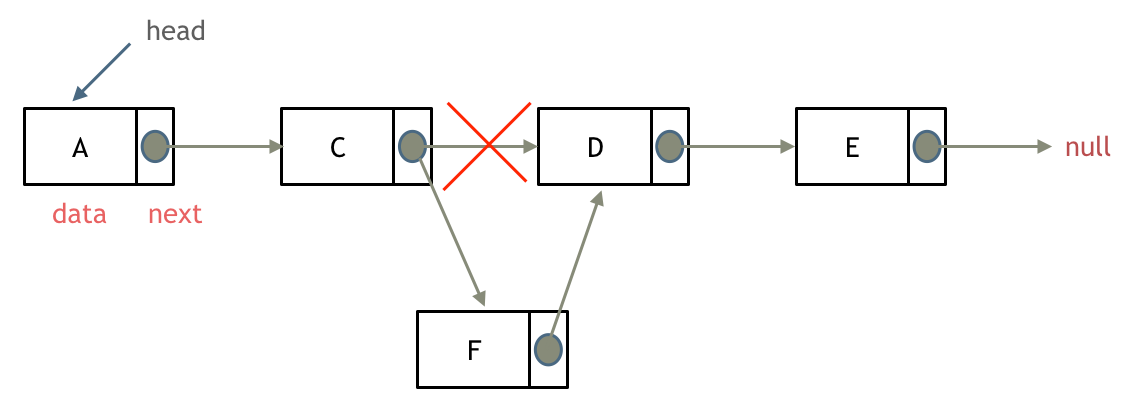
可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
void LinkedList::insert(int i, int value){
if(i < 0 || i > size){
throw std::out_of_range( " Invalid position ");
}
ListNode* newNode = new ListNode(value);
if(i == 0){
newNode->next = head;
head = newNode;
}else{
ListNode* curr = head;
for(int j = 0; j < i - 1;j++){
curr = curr->next;
}
newNode->next = curr->next;
curr->next = newNode;
}
++size;
}
更改元素
就是遍历链表,直至找到目标节点,将该节点的数据data变换成新值,即可完成
void LinkedList::updata(int i, eleType value){
get(i)->data = value;
}
查找元素
同理更改元素,遍历链表,直至找到目标节点,将该节点的指针地址返回,即可完成
ListNode *LinkedList::find(int value){
ListNode* curr = head;
while(curr && curr->data != value){
curr->next;
}
return curr;
}
ListNode *LinkedList::get(int i){
if(i < 0 || i > size){
throw std::out_of_range( " Invalid position ");
}
ListNode* curr = head;
for(int j = 0;j < i;j++){
curr = curr->next;
}
return curr;
}
所以,链表的构建的总代码:
#include <iostream>
#include <stdexcept>
using namespace std;
#define eleType int
//初始化链表节点
struct ListNode{
eleType data;
ListNode* next;
ListNode(eleType x) : data(x), next(NULL) {} //调用时,传入变量x,构造节点
};
//初始化链表类
class LinkedList {
public:
ListNode* head;
int size;
LinkedList() : head(NULL), size(0) {} //调用时,不传入变量,构造链表类
//调用类时,自动执行
void insert(int i , eleType value); //增
void remove(int i); //删
ListNode* find(eleType value); //查 <<返回ListNode* 指针(即节点本身)>>
ListNode* get(int i); //查 <<返回ListNode* 指针(即节点本身)>>
void updata(int i, eleType value); //改
void print(); //打印
~LinkedList(); //析构函数
};
//析构函数————析构掉每个节点的内存空间
LinkedList::~LinkedList(){
ListNode* curr = head;
while(curr != NULL){
ListNode* tmp = curr; //往下移动
curr = curr->next;
delete tmp;
}
}
void LinkedList::insert(int i, eleType value){
if(i < 0 || i > size){
throw std::out_of_range( " Invalid position ");
}
ListNode* newNode = new ListNode(value);
if(i == 0){
newNode->next = head;
head = newNode;
}else{
ListNode* curr = head;
for(int j = 0; j < i - 1;j++){
curr = curr->next;
}
newNode->next = curr->next;
curr->next = newNode;
}
++size;
}
void LinkedList::remove(int i){
if(i < 0 || i > size){
throw std::out_of_range( " Invalid position ");
}
if(i == 0){
ListNode* temp = head;
head = head->next;
delete temp;
}else{
ListNode* curr = head;
for(int j = 0;j < i - 1;j++){
curr = curr->next;
}
ListNode* temp = curr->next;
curr->next = curr->next->next;
delete temp;
}
size--;
}
ListNode *LinkedList::find(eleType value){
ListNode* curr = head;
while(curr && curr->data != value){
curr->next;
}
return curr;
}
ListNode *LinkedList::get(int i){
if(i < 0 || i > size){
throw std::out_of_range( " Invalid position ");
}
ListNode* curr = head;
for(int j = 0;j < i;j++){
curr = curr->next;
}
return curr;
}
void LinkedList::updata(int i, eleType value){
get(i)->data = value;
}
void LinkedList::print(){
ListNode* curr = head;
while(curr){
cout << curr->data << " ";
curr = curr->next;
}
cout << endl;
}
链表和数组的区别
1. 内存
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
2.性能
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。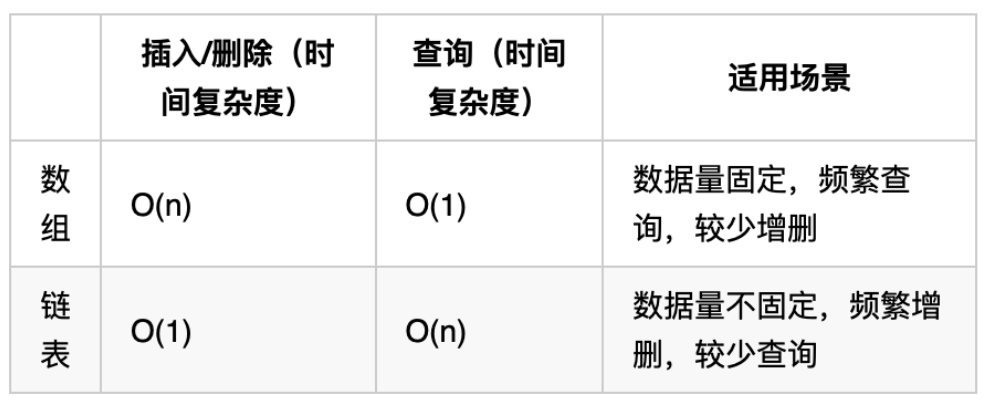
链表的经典题目
主要精选LeetCode上有代表性的题目,后续会更新其他学校OJ系统或平台的题
反转链表
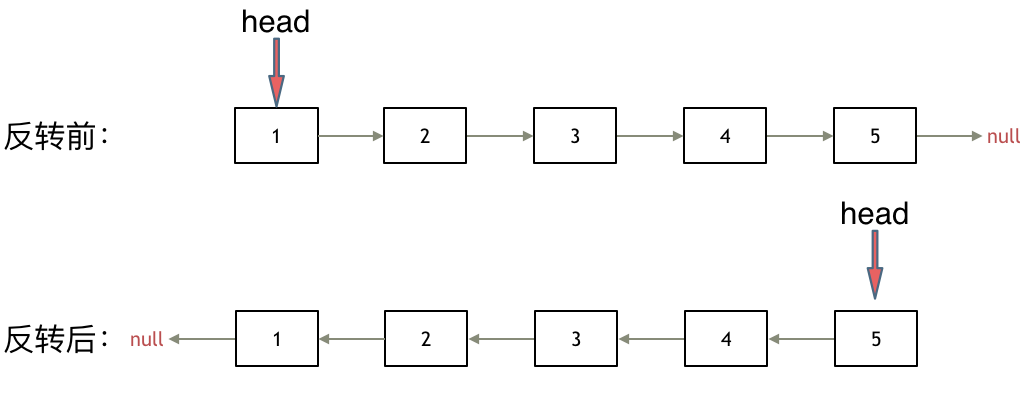
之前链表的头节点是元素1, 反转之后头结点就是元素5 ,这里并没有添加或者删除节点,仅仅是改变next指针的方向。

使用双指针法
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。
为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* temp; // 保存cur的下一个节点
ListNode* cur = head;
ListNode* pre = NULL;
while(cur) {
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
cur->next = pre; // 翻转操作
// 更新pre 和 cur指针
pre = cur;
cur = temp;
}
return pre;
}
};
两两交换链表中的节点
这里推荐看一下B站视频,通过文字讲解不太好理解(本人就是如此(哭))
链接:[“两两交换链表的节点”][【LeetCode 每日一题】24. 两两交换链表中的节点 | 手写图解版思路 + 代码讲解_哔哩哔哩_bilibili]
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead->next = head; // 将虚拟头结点指向head,这样方便后面做删除操作
ListNode* cur = dummyHead;
while(cur->next != nullptr && cur->next->next != nullptr) {
ListNode* tmp = cur->next; // 记录临时节点
ListNode* tmp1 = cur->next->next->next; // 记录临时节点
cur->next = cur->next->next; // 步骤一
cur->next->next = tmp; // 步骤二
cur->next->next->next = tmp1; // 步骤三
cur = cur->next->next; // cur移动两位,准备下一轮交换
}
ListNode* result = dummyHead->next;
delete dummyHead;
return result;
}
};
删除链表的倒数第N个节点
双指针的经典应用,如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。
思路是这样的,但要注意一些细节。
分为如下几步:
- 定义fast指针和slow指针,初始值为虚拟头结点,如图:
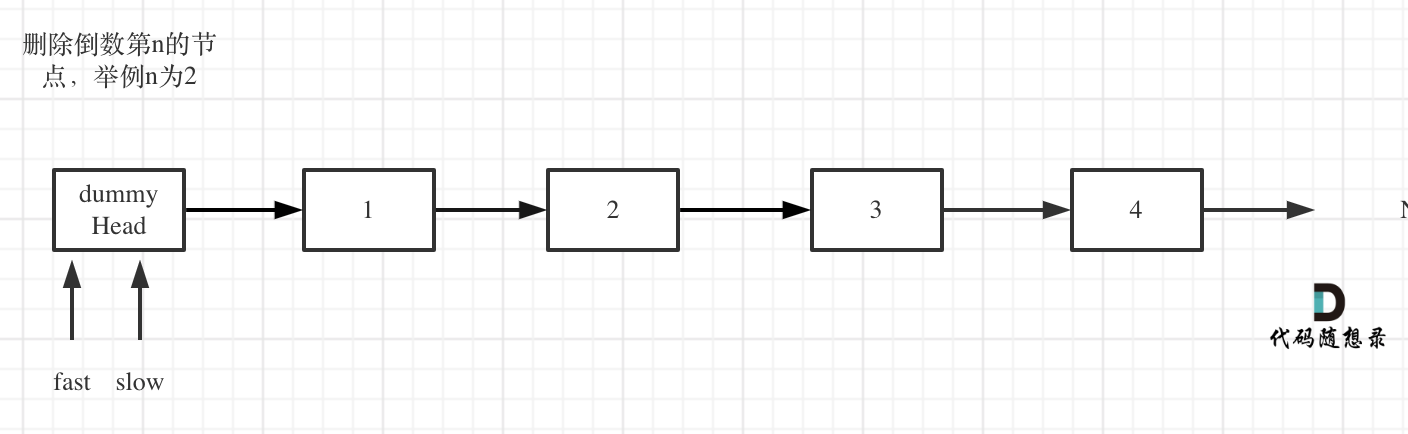
- fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
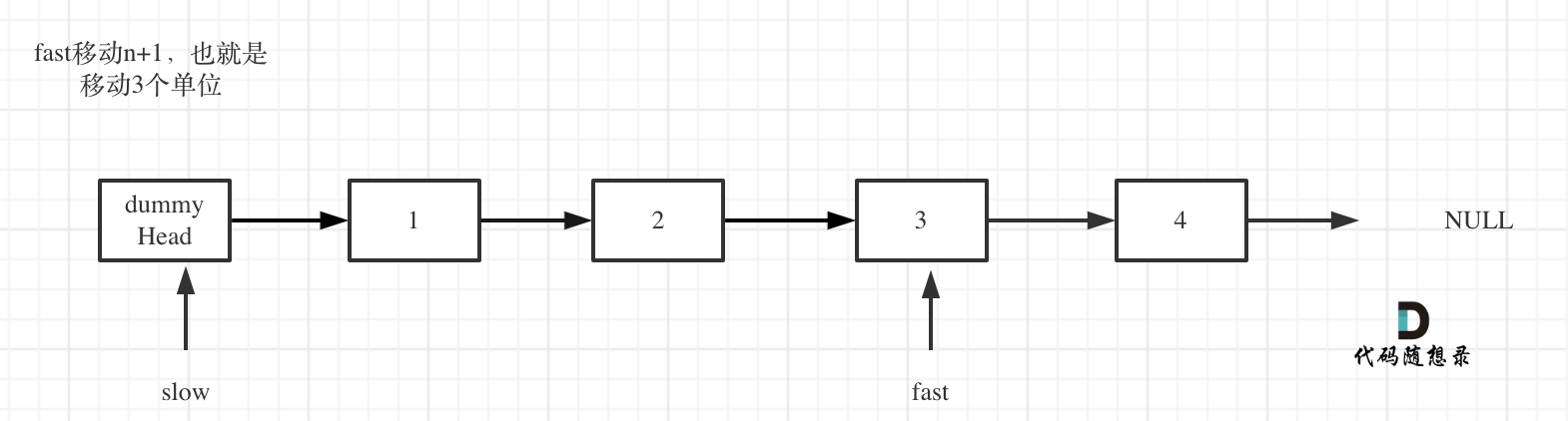
- fast和slow同时移动,直到fast指向末尾,如题:
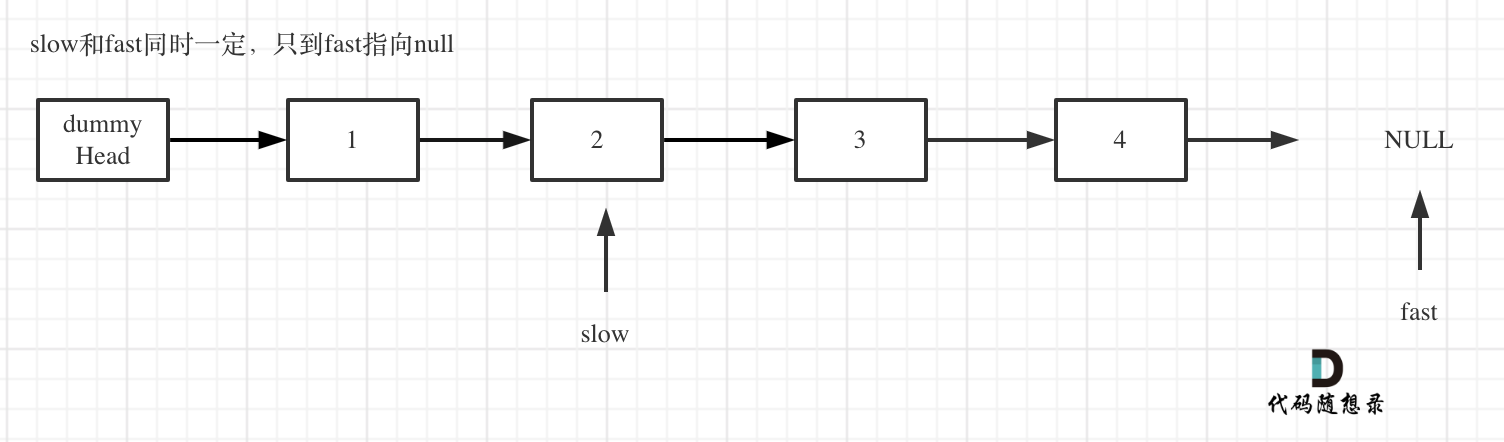
- 删除slow指向的下一个节点,如图:
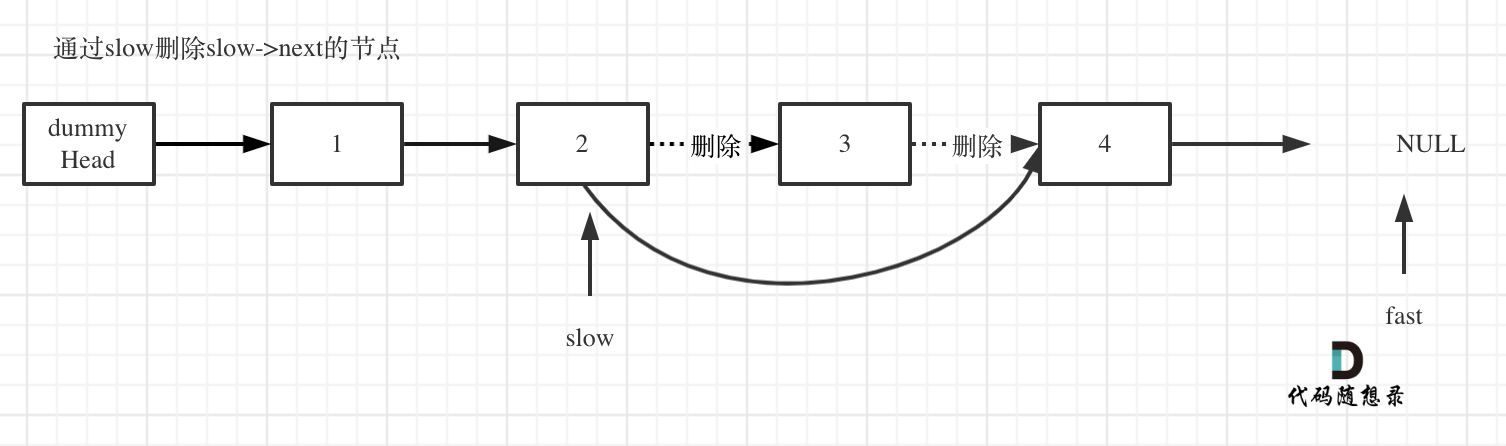
代码如下:
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* slow = dummyHead;
ListNode* fast = dummyHead;
while(n-- && fast != NULL) {
fast = fast->next;
}
fast = fast->next; // fast再提前走一步,因为需要让slow指向删除节点的上一个节点
while (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;
// ListNode *tmp = slow->next; C++释放内存的逻辑
// slow->next = tmp->next;
// delete tmp;
return dummyHead->next;
}
};
链表相交
两个链表相交,那么两个链表中的节点一定有相同地址。
两个链表相交,那么两个链表从相交节点开始到尾节点一定都是相同的节点。因此在相交节点之后,链表不可能再分为两个链表

简单来说,就是求两个链表交点节点的指针。 这里要注意,交点不是数值相等,而是指针相等。
为了方便举例,假设节点元素数值相等,则节点指针相等。
看如下两个链表,目前curA指向链表A的头结点,curB指向链表B的头结点:
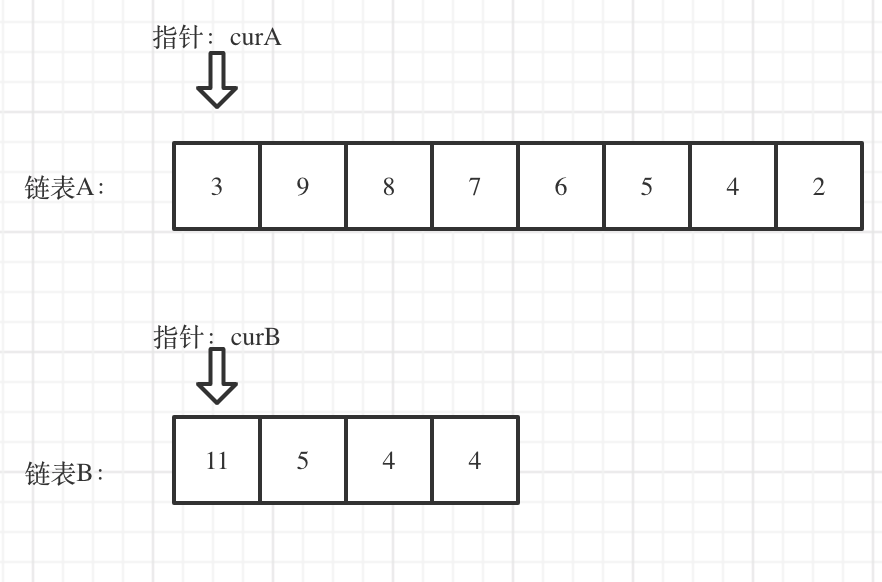
我们求出两个链表的长度,并求出两个链表长度的差值,然后让curA移动到,和curB 末尾对齐的位置,如图:
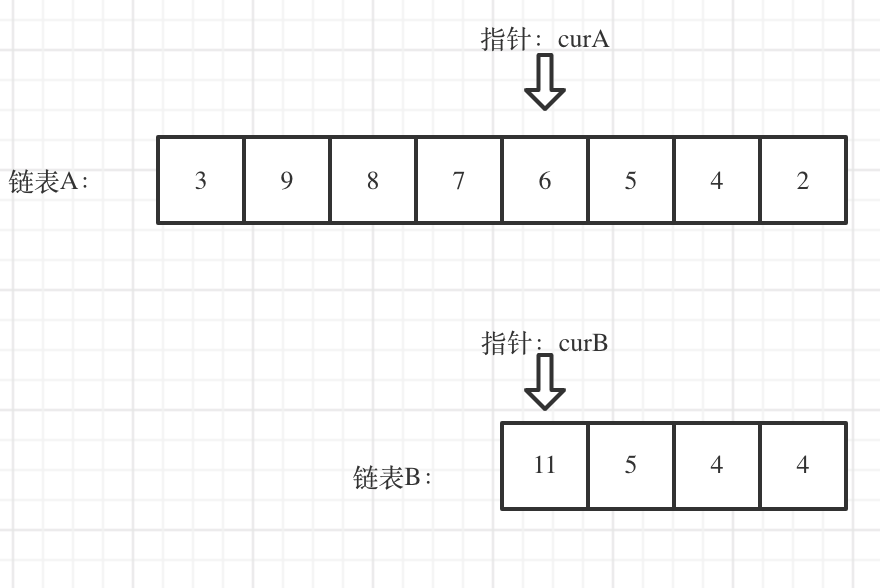
此时我们就可以比较curA和curB是否相同,如果不相同,同时向后移动curA和curB,如果遇到curA == curB,则找到交点。
否则循环退出返回空指针。
代码如下:
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode* curA = headA;
ListNode* curB = headB;
int lenA = 0, lenB = 0;
while (curA != NULL) { // 求链表A的长度
lenA++;
curA = curA->next;
}
while (curB != NULL) { // 求链表B的长度
lenB++;
curB = curB->next;
}
curA = headA;
curB = headB;
// 让curA为最长链表的头,lenA为其长度
if (lenB > lenA) {
swap (lenA, lenB);
swap (curA, curB);
}
// 求长度差
int gap = lenA - lenB;
// 让curA和curB在同一起点上(末尾位置对齐)
while (gap--) {
curA = curA->next;
}
// 遍历curA 和 curB,遇到相同则直接返回
while (curA != NULL) {
if (curA == curB) {
return curA;
}
curA = curA->next;
curB = curB->next;
}
return NULL;
}
};
环形链表
此处参考文章[环形列表][https://programmercarl.com/0142.%E7%8E%AF%E5%BD%A2%E9%93%BE%E8%A1%A8II.html]
讲的非常详细,我感觉我重新赘述一遍反而会误导(哭)
代码如下:
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* fast = head;
ListNode* slow = head;
while(fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
// 快慢指针相遇,此时从head 和 相遇点,同时查找直至相遇
if (slow == fast) {
ListNode* index1 = fast;
ListNode* index2 = head;
while (index1 != index2) {
index1 = index1->next;
index2 = index2->next;
}
return index2; // 返回环的入口
}
}
return NULL;
}
};
总结
每天学习一点数据结构,100天后一定会有大不同!
于高山之巅,方见大河奔涌;于群峰之上,更觉长风浩荡
2024/4/22
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









