







目录
一、任务概述
本周我们主要完成了模型的部署 和 原型设计 两部分工作。
在模型部署方面,我们取得了显著的进展。我们成功将大模型部署在服务器上,并且尝试对大模型进行了微调测试。
在原型设计方面,我们完成了对小程序前端的设计,为后续编写代码实现小程序的各种功能提供了前提保障。
二、完成情况
2.1 模型的接口与微调测试
2.1.1 模型的接口
在VisualGLM-6B的开源代码中,给出了一个网页版的demo以及对应的代码。
#!/usr/bin/env python
import gradio as gr
from PIL import Image
import os
import json
from model import is_chinese, get_infer_setting, generate_input, chat
import torch
def generate_text_with_image(input_text, image, history=[], request_data=dict(), is_zh=True):
input_para = {
"max_length": 2048,
"min_length": 50,
"temperature": 0.8,
"top_p": 0.4,
"top_k": 100,
"repetition_penalty": 1.2
}
input_para.update(request_data)
input_data = generate_input(input_text, image, history, input_para, image_is_encoded=False)
input_image, gen_kwargs = input_data['input_image'], input_data['gen_kwargs']
with torch.no_grad():
answer, history, _ = chat(None, model, tokenizer, input_text, history=history, image=input_image, \
max_length=gen_kwargs['max_length'], top_p=gen_kwargs['top_p'], \
top_k = gen_kwargs['top_k'], temperature=gen_kwargs['temperature'], english=not is_zh)
return answer
def request_model(input_text, temperature, top_p, image_prompt, result_previous):
result_text = [(ele[0], ele[1]) for ele in result_previous]
for i in range(len(result_text)-1, -1, -1):
if result_text[i][0] == "" or result_text[i][1] == "":
del result_text[i]
print(f"history {result_text}")
is_zh = is_chinese(input_text)
if image_prompt is None:
if is_zh:
result_text.append((input_text, '图片为空!请上传图片并重试。'))
else:
result_text.append((input_text, 'Image empty! Please upload a image and retry.'))
return input_text, result_text
elif input_text == "":
result_text.append((input_text, 'Text empty! Please enter text and retry.'))
return "", result_text
request_para = {"temperature": temperature, "top_p": top_p}
image = Image.open(image_prompt)
try:
answer = generate_text_with_image(input_text, image, result_text.copy(), request_para, is_zh)
except Exception as e:
print(f"error: {e}")
if is_zh:
result_text.append((input_text, '超时!请稍等几分钟再重试。'))
else:
result_text.append((input_text, 'Timeout! Please wait a few minutes and retry.'))
return "", result_text
result_text.append((input_text, answer))
print(result_text)
return "", result_text
DESCRIPTION = '''# <a href="https://github.com/THUDM/VisualGLM-6B">VisualGLM</a>'''
MAINTENANCE_NOTICE1 = 'Hint 1: If the app report "Something went wrong, connection error out", please turn off your proxy and retry.\nHint 2: If you upload a large size of image like 10MB, it may take some time to upload and process. Please be patient and wait.'
MAINTENANCE_NOTICE2 = '提示1: 如果应用报了“Something went wrong, connection error out”的错误,请关闭代理并重试。\n提示2: 如果你上传了很大的图片,比如10MB大小,那将需要一些时间来上传和处理,请耐心等待。'
NOTES = 'This app is adapted from <a href="https://github.com/THUDM/VisualGLM-6B">https://github.com/THUDM/VisualGLM-6B</a>. It would be recommended to check out the repo if you want to see the detail of our model and training process.'
def clear_fn(value):
return "", [("", "Hi, What do you want to know about this image?")], None
def clear_fn2(value):
return [("", "Hi, What do you want to know about this image?")]
def main(args):
gr.close_all()
global model, tokenizer
model, tokenizer = get_infer_setting(gpu_device=0, quant=args.quant)
with gr.Blocks(css='style.css') as demo:
gr.Markdown(DESCRIPTION)
with gr.Row():
with gr.Column(scale=4.5):
with gr.Group():
input_text = gr.Textbox(label='Input Text', placeholder='Please enter text prompt below and press ENTER.')
with gr.Row():
run_button = gr.Button('Generate')
clear_button = gr.Button('Clear')
image_prompt = gr.Image(type="filepath", label="Image Prompt", value=None)
with gr.Row():
temperature = gr.Slider(maximum=1, value=0.8, minimum=0, label='Temperature')
top_p = gr.Slider(maximum=1, value=0.4, minimum=0, label='Top P')
with gr.Group():
with gr.Row():
maintenance_notice = gr.Markdown(MAINTENANCE_NOTICE1)
with gr.Column(scale=5.5):
result_text = gr.components.Chatbot(label='Multi-round conversation History', value=[("", "Hi, What do you want to know about this image?")]).style(height=550)
gr.Markdown(NOTES)
print(gr.__version__)
run_button.click(fn=request_model,inputs=[input_text, temperature, top_p, image_prompt, result_text],
outputs=[input_text, result_text])
input_text.submit(fn=request_model,inputs=[input_text, temperature, top_p, image_prompt, result_text],
outputs=[input_text, result_text])
clear_button.click(fn=clear_fn, inputs=clear_button, outputs=[input_text, result_text, image_prompt])
image_prompt.upload(fn=clear_fn2, inputs=clear_button, outputs=[result_text])
image_prompt.clear(fn=clear_fn2, inputs=clear_button, outputs=[result_text])
print(gr.__version__)
demo.queue(concurrency_count=10)
demo.launch(share=args.share)
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--quant", choices=[8, 4], type=int, default=None)
parser.add_argument("--share", action="store_true")
args = parser.parse_args()
main(args)Gradio 是一个用于构建交互式应用程序的 Python 框架,它使得创建用户友好的界面和功能强大的机器学习模型变得简单和快速。在上述代码中,使用了 Gradio 框架来构建一个交互式应用程序,用于生成文本描述图片。
对于小程序后端,我们使用Python的Flask框架实现相似的功能,代码如下:
import os
from flask import Flask, request, jsonify
from PIL import Image
import torch
from model import is_chinese, get_infer_setting, generate_input, chat
app = Flask(__name__)
UPLOAD_FOLDER = 'uploads'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
def generate_text_with_image(input_text, image, history=[], request_data=dict(), is_zh=True):
input_para = {
"max_length": 2048,
"min_length": 50,
"temperature": 0.8,
"top_p": 0.4,
"top_k": 100,
"repetition_penalty": 1.2
}
input_para.update(request_data)
input_data = generate_input(input_text, image, history, input_para, image_is_encoded=False)
input_image, gen_kwargs = input_data['input_image'], input_data['gen_kwargs']
with torch.no_grad():
answer, history, _ = chat(None, model, tokenizer, input_text, history=history, image=input_image,
max_length=gen_kwargs['max_length'], top_p=gen_kwargs['top_p'],
top_k=gen_kwargs['top_k'], temperature=gen_kwargs['temperature'], english=not is_zh)
return answer
@app.route('/process', methods=['POST'])
def process():
input_text = request.form.get('text')
image_file = request.files.get('image')
if not input_text or not image_file:
return jsonify({'error': 'Missing text or image'}), 400
# 保存上传的图片
image_path = os.path.join(UPLOAD_FOLDER, image_file.filename)
image_file.save(image_path)
image = Image.open(image_path)
is_zh = is_chinese(input_text)
history = []
request_data = {
"temperature": float(request.form.get('temperature', 0.8)),
"top_p": float(request.form.get('top_p', 0.4))
}
try:
answer = generate_text_with_image(input_text, image, history, request_data, is_zh)
except Exception as e:
print(f"error: {e}")
return jsonify({'error': 'Error processing request'}), 500
return jsonify({'result': answer})
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--quant", choices=[8, 4], type=int, default=None)
parser.add_argument("--share", action="store_true")
args = parser.parse_args()
global model, tokenizer
model, tokenizer = get_infer_setting(gpu_device=0, quant=args.quant)
app.run(debug=True, host='0.0.0.0', port=5000)这段代码使用 Flask 框架构建了一个简单的 Web 服务,接收客户端上传的文本和图片,通过调用预训练的深度学习模型生成文本描述,并返回结果。主要包括设置上传目录、定义生成文本描述的函数、处理请求的路由以及启动应用。
2.1.2 模型微调测试
成功部署理论大模型后,我们使用初始模型参数进行模型推理。按照官方教程,运行命令行代码python cli_demo.py ,期望程序自动下载sat模型,并在命令行中进行交互式的对话,输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
运行cli_demo.py文件,成功,显示提示内容“欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序”
“请输入图像路径或URL(回车进入纯文本对话)”
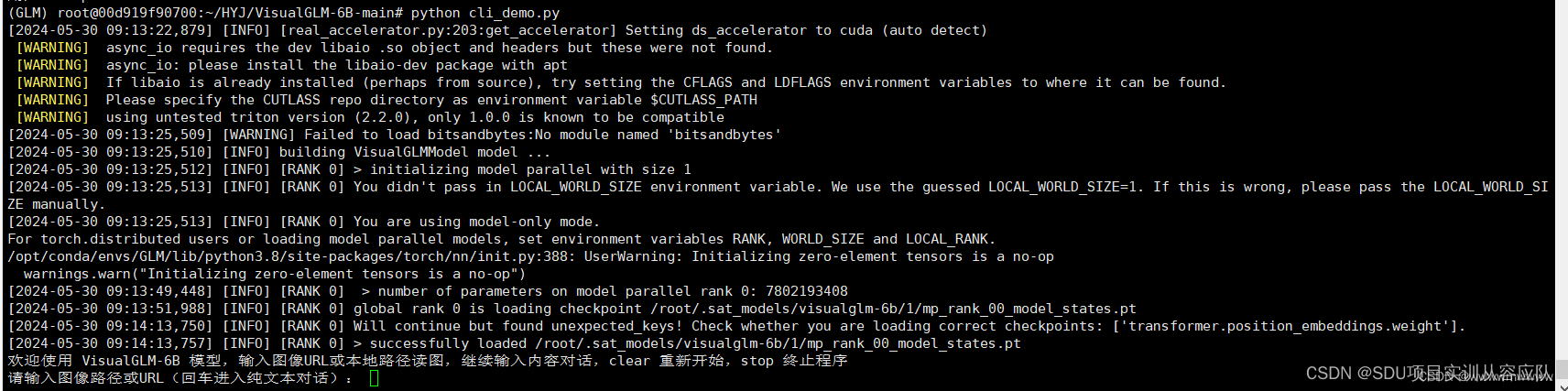
输入图像路径或URL并回车后即可生成答案,如下:
图片(本地保存):

模型回答:可以看到模型对图片的内容进行了描述,说明了图片的主要内容,包括整体建筑、屋顶、植物,但是回答不够准确,比如植物是两颗,图片中没有窗户。
此外,模型也具有多轮对话的推理能力,在用户:提示符下输入想要提问的问题,模型可以进行相关的回答,在上面的图片输出下进行如下提问:

可以看到,模型能够理解用户的提问并做出较符合的回答,这表明模型在多轮交互对话上有一定潜力。后续可以使用自己构建的数据集微调模型,增强对景点识别和介绍的能力。
2.2 原型设计
我们的小程序最主要的功能为 多模态大模型问答 和 定位实时导游 两部分,因此我们的小程序设计主要分为三个页面,即 主页 、问答系统页面 、导航系统页面 。
泉城济南、趵突泉景区以 泉 扬名,趵突泉景区内 绿 意盎然,因此我们小程序设计的色调为蓝色和绿色。
2.2.1 主页设计
主页的设计必须要抓眼,且能够让用户清晰地了解如何使用我们小程序的各个模块,因此我们的主页面必须有能够跳转到其他功能页面的组件。综上,我将我们小程序主页设计为顶端为 轮播图 ,下方为 跳转到各个功能页面的组件 。
2.2.2 问答系统页面设计
问答系统由于由于要调用多模态大模型,因此必须有多个按钮用以上传 语音、文字、图像 信息,且我们小程序主打的内容是快捷的 语音 交互,因此我将语音识别按钮放大且居中,让用户一目了然。我们倾向于将我们小程序设计成用户的 伙伴 ,因此我将上方显示大模型解答的模块设计成为微信式的气泡窗口模式,且可以进行语音朗读。
2.2.3 导航系统页面设计
我对导航页面的设计则是以地图为主,地图用以定位用户和显示附近的重要景点。下方为我们小程序实时定位导航的播放器,除了实时定位解说外,便于用户选择景点、选择播放进度等。
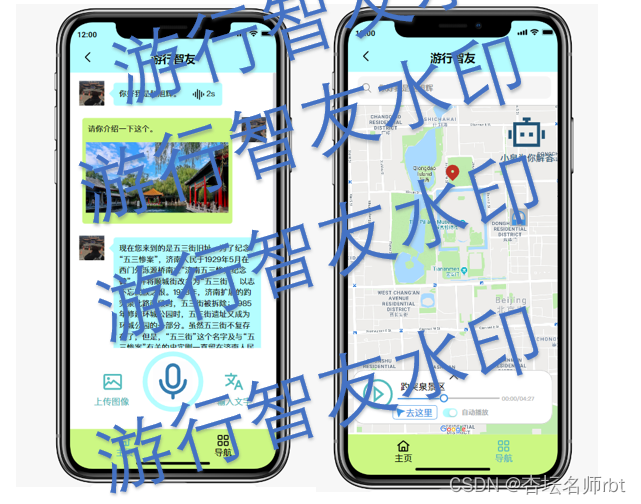
2.2.4交互设计
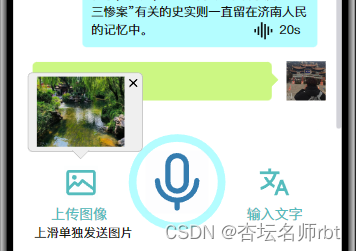
在 问答系统页面 我们点击 语音 按钮会进行语音识别,点击 输入文字 会弹出对话框以便我们在嘈杂、不方便说话的场合进行问答,点击 上传图片 会上传图像,但图像并不会单独上传,而是停留等待语音(文字)信息一同上传。
在 导航系统页面 我们上拉下方播放器,可以选择景点的解说词,并且可以拖动解说词播放的进度等功能。同时地图上也有可以交互的 “耳机” ,用以标识可以进行解说的景点,点击后会对该景点进行介绍。由于我们主打的是智能问答,因此在导航页面也有明显的机器人图标以便我们可以快速跳转到问答系统页面。
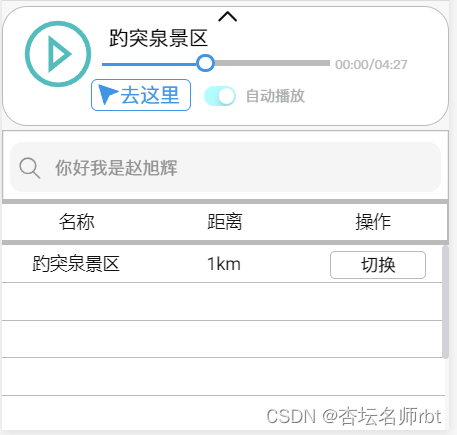
此外,一些基础的交互,如 导航条 等不过多赘述。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









