






达梦数据库是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,以下是其详细介绍:
发展历程
达梦数据库的发展起源于 2000 年,其前身是华中科技大学数据库与多媒体研究所,经过多年的研发与积累,逐渐成为国产数据库领域的重要力量,为中国数据库技术的自主可控发展做出了重要贡献
技术特点
- 存储引擎:采用自主研发的高效存储引擎,能有效管理和优化存储资源,在大数据量场景下,数据读写性能出色,可快速响应复杂查询与高并发访问
- SQL 引擎:经过多年优化的 SQL 引擎,支持复杂查询优化、多表关联、并行查询等高级功能,处理复杂 SQL 查询时执行性能高效
- 并发处理:支持高并发处理,通过多线程、多进程设计,配合高效的锁机制和事务管理,在高并发环境下性能稳定,适用于大型应用系统
- 数据压缩:采用智能压缩策略,自动选择合适的压缩算法对数据进行压缩,显著提升数据压缩比,减少系统空间资源开销
- 架构支持:采用完全对等无共享(share-nothing)的 MPP 架构,支持 SQL 并行处理,可自动化分区数据和并行查询,无 I/O 冲突,为大规模数据和复杂查询提供先进的软件级解决方案
功能特性
- 高可用性:提供数据库或整个服务器的冷 / 热备份以及对应的还原功能,支持物理备份、逻辑备份,可实现全库、表空间、B 树等多个级别的备份及增量备份,并以检查点进行还原。还提供事务级的同步复制和异步复制功能,支持多种复制模式,主备系统可在主机故障时快速切换,保障业务连续性
- 高安全性:通过公安部安全四级评测和中国信息安全测评中心的 EAL4 级评测,是目前安全等级最高的商业数据库之一。提供多种用户身份鉴别功能、数据库审计功能、强大的实时侵害检测功能、系统权限和对象权限管理功能以及强制访问控制功能等,同时支持基于 SSL 协议的通讯加密和存储数据的多种加密模式
- 兼容性:在体系结构、应用开发接口、维护管理方式等方面与 Oracle 有良好的兼容性,降低用户学习和迁移成本。还兼容多种硬件体系和主流操作系统,支持多种主流集成开发环境、开发框架技术和系统中间件,以及 SQL92 的特性和 SQL99 的核心级别,支持多种数据库开发接口和网络协议,完全支持 Unicode、GBK18030 等常用字符集,并提供国际化支持1.
- 特色功能:提供全文检索服务,支持中、英、俄文等多种语言的全文索引和检索。支持多种字符集存储和访问数据,物理数据页大小可选,代理服务与作业调度功能可自动执行部分管理任务,还支持多媒体和空间信息管理,具备地理信息的多种检索和操作功能
应用领域
- 政府机构:广泛应用于各级政府部门的电子政务系统、人口管理系统、税务系统、社保系统等,实现数据的集中管理和快速访问,提高行政效率和公共服务水平
- 金融行业:在银行、证券、保险等金融机构的核心业务系统中得到应用,凭借高并发处理能力和数据安全性,处理大量金融交易数据,保障金融业务的高效运行,还可用于风险控制、客户关系管理和资产管理等方面
- 能源领域:在电力、石油等能源行业的电力调度系统、油气管理系统、设备监控系统和能源管理系统等项目中发挥重要作用,满足能源行业对实时数据处理和分析的需求,保障设备的实时监控和故障预测
- 教育和科研:被高校和科研机构广泛应用于数据管理和分析系统,支持教育信息化和科研数据的存储与处理
- 其他行业:还在电信、医疗、交通运输、制造、零售、航空航天等多个行业有着广泛的应用,满足各行业对大规模数据处理、实时数据分析、数据安全等多样化的需要
达梦数据库备份与还原详细教程
备份数据库
- 使用 DM 管理工具备份:
- 打开 DM 管理工具并连接数据库:启动达梦数据库 DM 管理工具,输入数据库的连接信息,包括主机名、端口、数据库名、用户名和密码,然后点击 “连接” 按钮。
- 执行备份操作:在工具的菜单或导航栏中找到 “备份” 或 “维护” 相关的选项,选择 “备份数据库”,在弹出的对话框中,选择备份类型,如全量备份、增量备份等,指定备份目标路径和备份文件名等信息,确认设置无误后,点击 “开始备份”,等待备份完成。
- 使用 SQL 命令备份:
- 全库备份:执行以下 SQL 命令进行全库备份,例如
BACKUP DATABASE TO '/your_backup_path/backup.dmp' WITH FORMAT;,其中/your_backup_path/backup.dmp是备份文件的保存路径和名称。 - 增量备份:如果要进行增量备份,可以使用类似
BACKUP DATABASE INCREMENT WITH BACKUPDIR '/dbbak/dmbak' BACKUPSET '/dbbak/dmbak/db_increment_bak_02';的命令,指定增量备份的基础备份目录和生成的增量备份集名称。
- 全库备份:执行以下 SQL 命令进行全库备份,例如
还原数据库
- 使用 DM 管理工具还原:
- 连接数据库:打开 DM 管理工具,输入相应的连接信息,连接到需要恢复数据的数据库实例。
- 选择还原:在工具中找到 “还原” 或 “恢复” 相关的功能项,选择 “还原数据库”。
- 设置还原参数:选择或浏览之前备份的文件,设置还原的目标数据库,如果需要的话,还可以确认其他高级选项。
- 执行还原:确认设置后,点击 “开始还原”,等待操作完成。
- 使用 DMRMAN 命令行工具还原:
- 进入 DMRMAN 系统:在数据库的 bin 目录下,执行
./dmrman命令进入 DMRMAN 系统。 - 校验备份:执行
CHECK BACKUPSET '/dbbak/dmbak/db_full_bak_01';命令校验备份集的完整性。 - 还原数据库:执行
RESTORE DATABASE '/dbdata/dmdata/DAMENG/dm.ini' FROM BACKUPSET '/dbbak/dmbak/db_full_bak_01';命令,从指定的备份集中还原数据库到目标数据库实例。 - 恢复数据库:执行
RECOVER DATABASE '/dbdata/dmdata/DAMENG/dm.ini' FROM BACKUPSET '/dbbak/dmbak/db_full_bak_01';命令,对还原后的数据库进行恢复操作,使其达到可用状态。
- 进入 DMRMAN 系统:在数据库的 bin 目录下,执行
脱机备份与还原
- 脱机备份:
- 关闭数据库服务:使用 DM 服务查看器或命令行工具停止需要备份的数据库实例服务,例如
systemctl stop DmServiceDAMENG.service。 - 打开 DM Console:使用 dmdba 用户打开 DM Console 工具,进入控制台界面。
- 创建备份:在 DM Console 中点击 “New backup” 按钮,选择备份的相关设置,如备份类型、备份路径等,然后点击 “确定” 开始备份。
- 关闭数据库服务:使用 DM 服务查看器或命令行工具停止需要备份的数据库实例服务,例如
- 脱机还原:
- 关闭数据库服务:同样先关闭数据库服务。
- 进入 console:启动 console 的控制台程序。
- 选择还原文件:点击 “指定搜索目录” 后面的配置操作,选择还原的数据库目录,点击 “获取备份”,显示备份文件,点击要还原的备份文件,然后再点击 “还原” 操作。
- 执行库还原:选择 “库还原” 操作,然后点击 “确定”。
- 恢复数据库:点击 “恢复” 操作,实现数据库的恢复。
- 更新 DB_Magic:最后点击 “更新 DB_Magic” 操作,完成脱机还原。
联机备份与还原
- 联机备份568:
- 开启相关服务和归档:确保 DmAPService 服务已开启,并且数据库已开启归档模式。可以通过查询语句
SELECT ARCH_DEST, ARCH_FILE_SIZE, ARCH_SPACE_LIMIT FROM V$DM_ARCH_INI WHERE ARCH_TYPE='LOCAL' AND ARCH_IS_VALID='Y';检查归档是否开启,若未开启则需要执行相应的配置语句来开启归档。 - 使用客户端工具备份:使用 DM 管理工具或 disql 命令行工具连接到数据库实例,执行 SQL 语句进行联机备份,如全库备份
BACKUP DATABASE FULL BACKUPSET '/dbbak/dmbak/db_full_bak_01' compressed;或增量备份等操作。
- 开启相关服务和归档:确保 DmAPService 服务已开启,并且数据库已开启归档模式。可以通过查询语句
- 联机还原:联机还原相对复杂,一般仅支持表级还原,且在 MPP 和分布式数据库等环境下存在一些限制,如 PRIMARY 模式支持联机还原,而 MPP 和分布式数据库不支持等
达梦数据库JDBC
-
JDBC 简介
- JDBC(Java Database Connectivity)是 Java 语言中用于连接数据库的标准 API。它提供了一套统一的接口,使得 Java 程序能够与各种不同的数据库进行交互,包括达梦数据库。通过 JDBC,开发人员可以在 Java 应用程序中执行 SQL 语句,实现对数据库的查询、插入、更新和删除等操作。
-
环境准备
- 添加达梦数据库 JDBC 驱动:首先需要获取达梦数据库的 JDBC 驱动包(dm - jdbc - driver - xxx.jar,其中 “xxx” 是版本号)。将该驱动包添加到 Java 项目的类路径中。如果是使用 Maven 构建的项目,可以在项目的 pom.xml 文件中添加以下依赖(假设驱动版本为 8.1.2):

- 确保数据库服务已启动:在使用 JDBC 连接达梦数据库之前,要确保达梦数据库服务已经正常启动,并且数据库已经创建好,同时知道数据库的连接参数,如主机地址、端口号、数据库名称、用户名和密码等。
- 建立数据库连接
- 在 Java 代码中,首先需要导入 JDBC 相关的包:

- 然后使用以下方式建立与达梦数据库的连接:
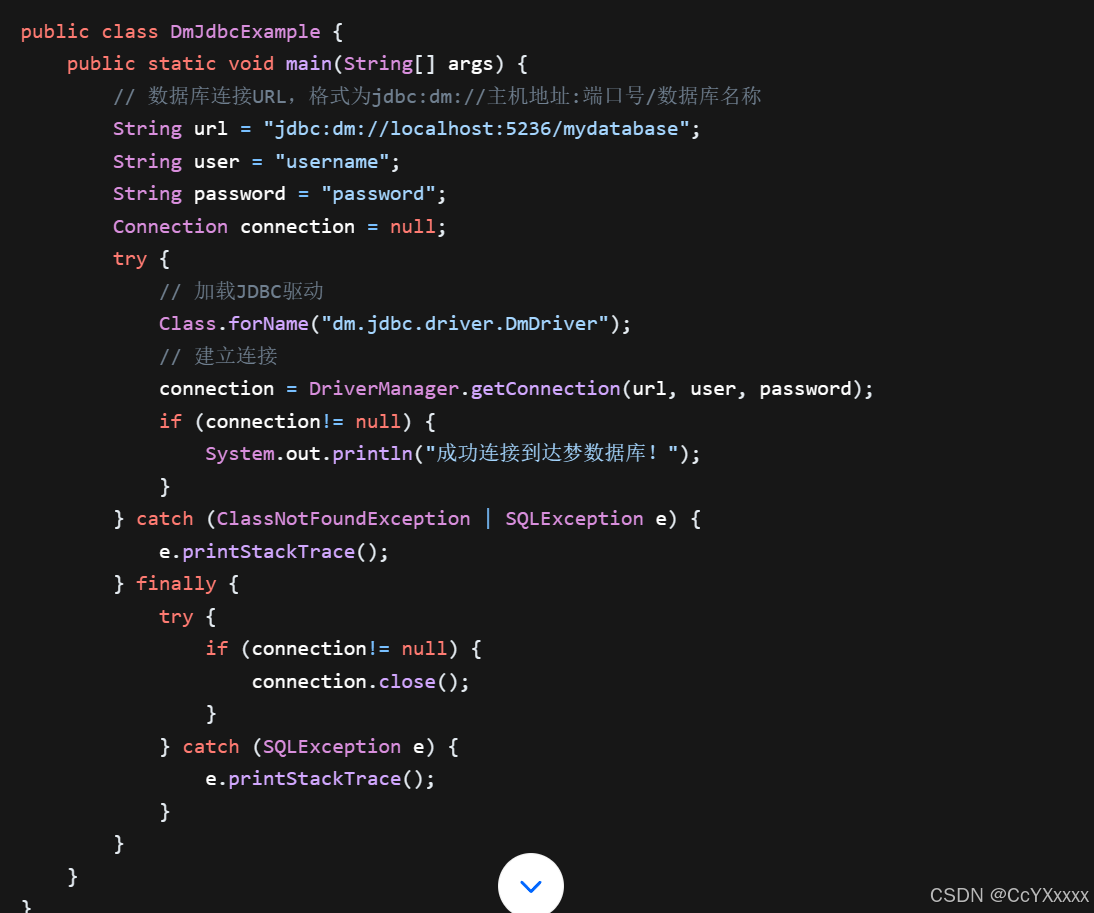
- 在上述代码中:
url变量定义了数据库的连接字符串,其中localhost是数据库服务器地址(如果是本地数据库),5236是达梦数据库的默认端口号,mydatabase是要连接的数据库名称。user和password分别是用于登录数据库的用户名和密码。- 通过
Class.forName("dm.jdbc.driver.DmDriver")加载达梦数据库的 JDBC 驱动,然后使用DriverManager.getConnection(url, user, password)建立连接。在finally块中,确保在连接使用完毕后关闭连接,以释放资源。
- 执行 SQL 操作
- 查询操作:
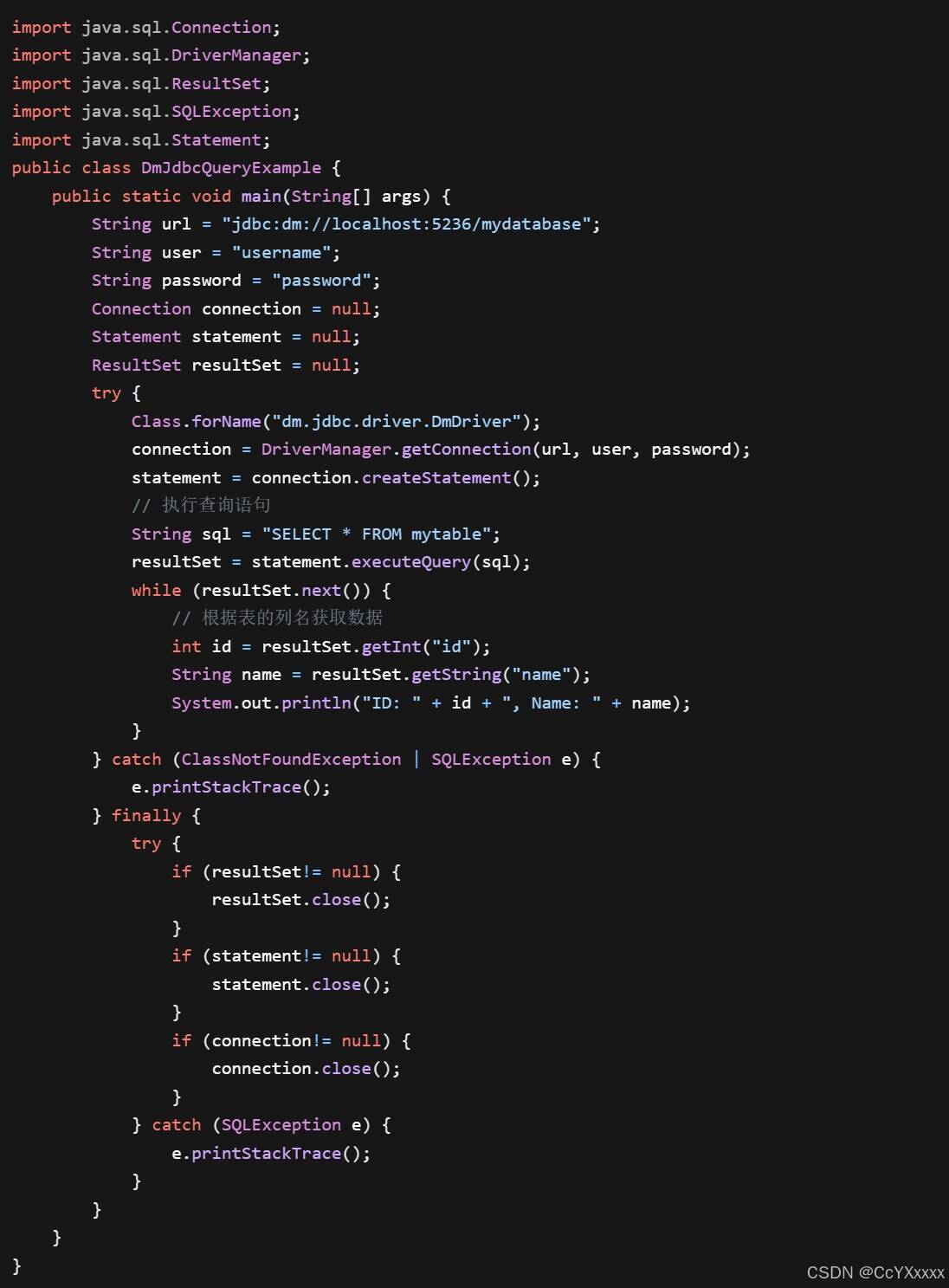
- 在查询操作中,通过
connection.createStatement()创建一个Statement对象,用于执行 SQL 语句。使用statement.executeQuery(sql)执行查询语句,并将结果存储在ResultSet对象中。然后通过resultSet.next()遍历结果集,使用resultSet.getInt("id")、resultSet.getString("name")等方法获取表中每一行的数据。 - 插入、更新和删除操作:
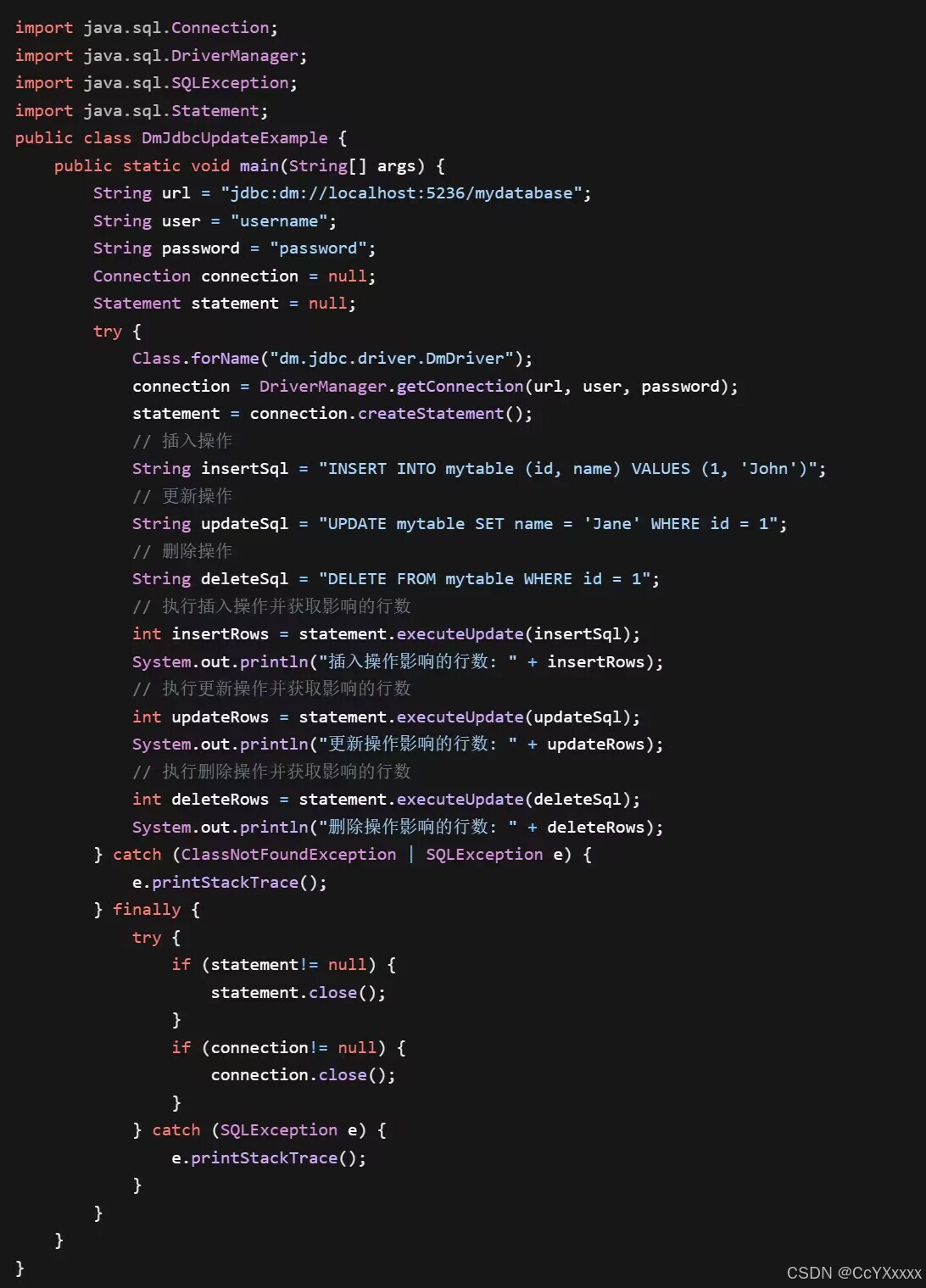
- 对于插入、更新和删除操作,使用
statement.executeUpdate(sql)方法执行 SQL 语句,并返回受影响的行数。可以根据返回值判断操作是否成功以及影响的范围。
有哪些常见的达梦数据库JDBC连接问题及解决方法?
- 驱动加载问题
- 解决方法:
- 检查项目的依赖配置。如果是使用 Maven 构建的项目,确认
pom.xml文件中达梦数据库 JDBC 驱动的依赖是否正确添加,包括 groupId、artifactId 和 version 是否与实际使用的驱动版本匹配。并且确保在执行 Maven 构建时,驱动能够正确下载并添加到项目的类路径中。 - 如果是手动添加驱动 JAR 包,检查 JAR 包是否已经添加到项目的类路径下。在 Java 项目中,可以将 JAR 包添加到项目的
lib文件夹下,并在项目的构建路径(Build Path)设置中包含该文件夹。在 Web 项目中,对于一些应用服务器,可能需要将 JAR 包放置在特定的目录下,如WEB - INF/lib目录。
- 检查项目的依赖配置。如果是使用 Maven 构建的项目,确认
- 问题描述:
- 当执行
Class.forName("dm.jdbc.driver.DmDriver")语句加载达梦数据库 JDBC 驱动时,可能会出现ClassNotFoundException异常。这通常是因为驱动类路径没有正确配置,导致 Java 虚拟机无法找到驱动类。
- 当执行
-
连接参数错误
- 问题描述:
- 在使用
DriverManager.getConnection(url, user, password)建立连接时,可能会出现SQLException异常,提示连接被拒绝或者无法识别的数据库等错误信息。这可能是因为数据库连接 URL、用户名或者密码错误。例如,连接 URL 中的主机地址、端口号或者数据库名称有误,或者用户名和密码不匹配。
- 在使用
- 解决方法:
- 仔细检查数据库连接 URL。确认主机地址是否正确,如果数据库在本地,通常是
localhost或者127.0.0.1;端口号是否是达梦数据库正在使用的端口(默认是 5236);数据库名称是否拼写正确并且是实际存在的数据库。 - 检查用户名和密码是否正确。可以通过使用数据库管理工具或者命令行工具(如
disql)尝试使用相同的用户名和密码登录数据库,验证其正确性。
- 仔细检查数据库连接 URL。确认主机地址是否正确,如果数据库在本地,通常是
- 问题描述:
-
数据库服务未启动或网络问题
- 问题描述:
- 出现连接超时或者无法连接到数据库的错误。这可能是因为达梦数据库服务没有启动,或者网络配置存在问题,导致无法与数据库服务器通信。
- 解决方法:
- 检查达梦数据库服务是否已经启动。可以在操作系统的服务管理界面(在 Windows 系统中)或者使用命令行工具(如
systemctl命令在 Linux 系统中)查看数据库服务的状态。如果服务没有启动,启动数据库服务。 - 检查网络连接。确保数据库服务器和客户端之间的网络是畅通的。可以使用
ping命令测试与数据库服务器的连接,例如ping localhost(如果数据库在本地)或者ping <数据库服务器IP地址>。如果网络存在问题,检查网络配置、防火墙设置等,确保数据库端口(5236)没有被防火墙阻止。
- 检查达梦数据库服务是否已经启动。可以在操作系统的服务管理界面(在 Windows 系统中)或者使用命令行工具(如
- 问题描述:
-
数据库权限问题
- 问题描述:
- 成功连接数据库后,在执行 SQL 操作(如查询、插入、更新、删除)时,可能会出现权限不足的错误。例如,执行插入操作时,提示没有权限向表中插入数据。
- 解决方法:
- 使用具有足够权限的用户账户连接数据库。可以通过数据库管理工具检查用户账户的权限设置。在达梦数据库中,权限是通过角色(Role)和用户权限(User Privilege)来管理的。确保连接数据库的用户被授予了执行相应操作的权限,如对表的 SELECT、INSERT、UPDATE 和 DELETE 权限等。如果权限不足,可以通过数据库管理员账户(如
SYSDBA)为用户授予适当的权限。
- 使用具有足够权限的用户账户连接数据库。可以通过数据库管理工具检查用户账户的权限设置。在达梦数据库中,权限是通过角色(Role)和用户权限(User Privilege)来管理的。确保连接数据库的用户被授予了执行相应操作的权限,如对表的 SELECT、INSERT、UPDATE 和 DELETE 权限等。如果权限不足,可以通过数据库管理员账户(如
- 问题描述:
-
字符编码问题
- 问题描述:
- 在插入或者查询包含特殊字符的数据时,可能会出现乱码问题。这是因为数据库的字符编码与客户端的字符编码设置不一致。
- 解决方法:
- 确保数据库的字符编码和 Java 应用程序中的字符编码设置一致。在达梦数据库中,可以通过配置文件(如
dm.ini)设置数据库的字符编码。在 Java 应用程序中,在建立连接时,可以在连接 URL 中添加字符编码参数,例如jdbc:dm://localhost:5236/mydatabase?characterEncoding=UTF - 8,将字符编码设置为 UTF - 8。同时,在处理字符串数据时,确保在数据库和应用程序之间的编码转换是正确的。
- 确保数据库的字符编码和 Java 应用程序中的字符编码设置一致。在达梦数据库中,可以通过配置文件(如
- 问题描述:
-
版本兼容性问题
- 问题描述:
- 使用的 JDBC 驱动版本与达梦数据库服务器版本不兼容,可能会导致一些功能无法正常使用或者出现异常。例如,某些新的 SQL 特性或者数据库管理功能在旧的驱动版本中可能不支持。
- 解决方法:
- 参考达梦数据库的官方文档,确保使用的 JDBC 驱动版本与数据库服务器版本兼容。如果发现不兼容问题,更新 JDBC 驱动到与数据库服务器版本匹配的最新版本。同时,注意在更新驱动时,可能需要对应用程序中的一些代码进行适当的调整,以适应新驱动的变化。
- 问题描述:
- 解决方法:
- 达梦数据库中,索引是如何优化查询性能的?
-
索引的基本原理
- 在达梦数据库中,索引是一种数据结构,类似于书籍的目录。它是对数据库表中一列或多列的值进行排序后的存储结构。以 B - Tree 索引(达梦数据库常用的索引类型)为例,B - Tree 索引以平衡树的形式组织数据,使得在查询数据时能够快速定位到满足条件的数据记录所在的位置,而不必全表扫描。
-
通过索引加速数据定位
- 精确查询加速
- 场景示例:假设有一个包含用户信息的表
users,其中有列user_id(用户 ID)、user_name(用户姓名)和email(电子邮件)。在user_id列上建立了索引。当执行查询语句SELECT * FROM users WHERE user_id = 123;时,如果没有索引,数据库可能需要遍历整个users表来查找user_id为 123 的用户记录。而有了索引,数据库可以通过索引结构快速定位到user_id为 123 的记录在表中的位置,大大减少了查询时间。
- 场景示例:假设有一个包含用户信息的表
- 范围查询加速
- 场景示例:对于一个订单表
orders,有列order_date(订单日期),并且在该列上建立了索引。当执行查询语句SELECT * FROM orders WHERE order_date BETWEEN '2024 - 01 - 01' AND '2024 - 02 - 01';时,索引可以帮助数据库快速定位到满足日期范围的订单记录的起始位置,然后按照索引的顺序依次读取范围内的记录,而不是扫描整个订单表,提高了范围查询的效率。
- 场景示例:对于一个订单表
- 精确查询加速
-
索引对连接(JOIN)操作的优化
- 场景示例:假设有两个表,
customers(顾客表)和orders(订单表)。customers表中有customer_id(顾客 ID)和customer_name(顾客姓名)列,orders表中有order_id(订单 ID)、customer_id(顾客 ID)和order_date(订单日期)列。在customers表的customer_id列和orders表的customer_id列都建立了索引。 - 当执行连接查询
SELECT * FROM customers c JOIN orders o ON c.customer_id = o.customer_id;时,数据库可以利用索引快速定位到两个表中具有相同customer_id的记录,而不是对两个表进行笛卡尔积操作后再筛选,从而大大提高了连接操作的性能。
- 场景示例:假设有两个表,
-
索引减少数据读取量
- 场景示例:假设一个数据表有 100 万行记录,总数据量为 1GB。执行一个查询语句
SELECT * FROM large_table WHERE indexed_column = 'specific_value';,如果没有索引,数据库可能需要读取整个 1GB 的数据来查找满足条件的记录。而如果在indexed_column列上有索引,数据库可能只需要读取包含满足条件记录的索引页(通常比整个表的数据量小得多)以及对应的少量数据页,从而大大减少了数据读取量,提高了查询性能。
- 场景示例:假设一个数据表有 100 万行记录,总数据量为 1GB。执行一个查询语句
-
索引与排序操作的协同优化
- 场景示例:在一个成绩表
scores中,有列student_id(学生 ID)、course_id(课程 ID)和score(成绩)。如果在score列上建立了索引,当执行查询语句SELECT * FROM scores WHERE course_id = 123 ORDER BY score DESC;时,数据库可以利用索引的排序特性来满足排序要求。因为索引本身是按照索引列的值进行排序存储的,所以在这种情况下,数据库可以直接按照索引的顺序读取满足course_id条件的记录,并按照成绩降序返回,避免了额外的排序操作,提高了查询性能。
- 场景示例:在一个成绩表
-
需要注意的是,虽然索引能够显著优化查询性能,但索引也有一定的成本。索引会占用额外的存储空间,并且在数据插入、更新和删除操作时,需要同时维护索引结构,这可能会导致这些操作的性能下降。因此,在实际应用中,需要合理地创建和使用索引
-
达梦数据库的B-Tree索引和其他类型索引相比,有哪些优缺点?
-
B - Tree 索引的优点
-
广泛适用性
- 原理:B - Tree 索引适用于各种类型的查询操作,包括精确匹配查询(如
WHERE column = value)、范围查询(如WHERE column BETWEEN value1 AND value2)、前缀匹配查询(对于字符串类型列,如WHERE column LIKE 'prefix%')等。这种通用性使得它在大多数业务场景下都能发挥作用。 - 示例:在一个电商数据库的
products表中,对于product_id(精确匹配)、price(范围查询)和product_name(前缀匹配)等列建立 B - Tree 索引,都可以有效提升相应查询的性能。例如,查询价格在某个区间内的产品SELECT * FROM products WHERE price BETWEEN 100 AND 200;,B - Tree 索引能够快速定位符合条件的产品记录。
- 原理:B - Tree 索引适用于各种类型的查询操作,包括精确匹配查询(如
-
高效的数据结构平衡性
- 原理:B - Tree 是一种平衡树结构,这意味着树的高度相对稳定,不会因为数据的插入或删除而出现过高或过低的情况。在查询数据时,每次磁盘 I/O 操作能够读取到更多的数据节点,减少磁盘 I/O 次数。
- 示例:假设有一个存储大量用户信息的
users表,随着用户数据的不断增加或删除,B - Tree 索引能够保持较好的平衡性。当查询用户记录时,数据库可以通过较少的磁盘读取操作定位到目标记录,提高查询效率。
-
支持排序和分组操作
- 原理:由于 B - Tree 索引本身是按照索引列的值进行排序存储的,所以在执行排序(
ORDER BY)或分组(GROUP BY)操作时,如果排序或分组的列上有 B - Tree 索引,数据库可以利用索引的顺序来减少额外的排序工作。 - 示例:在一个订单表
orders中,对于order_date列建立 B - Tree 索引。当执行查询SELECT customer_id, SUM(total_amount) FROM orders GROUP BY order_date;时,数据库可以利用order_date列的索引顺序来进行分组操作,减少排序开销。
- 原理:由于 B - Tree 索引本身是按照索引列的值进行排序存储的,所以在执行排序(
-
数据更新维护相对简单
- 原理:与一些复杂的索引结构相比,B - Tree 索引在数据更新(插入、更新和删除)时的维护操作相对简单。虽然数据更新会导致索引的调整,但 B - Tree 索引的平衡调整算法相对成熟,不会产生过高的维护成本。
- 示例:在一个库存表
inventory中,产品的库存数量会经常更新。如果在product_id列上建立 B - Tree 索引,尽管库存数量的更新会引起索引的变化,但数据库能够有效地进行索引维护,不会对整体性能造成过大的影响。
-
-
B - Tree 索引的缺点
-
占用较多存储空间
- 原理:B - Tree 索引需要存储索引列的值以及指向表中数据记录的指针等信息。对于包含大量数据的表和长字符串类型的索引列,B - Tree 索引可能会占用相当可观的存储空间。
- 示例:在一个存储文档内容的表
documents中,若对document_content(文档内容)列建立 B - Tree 索引,由于文档内容通常较长,索引存储这些内容的副本以及相关指针会占用大量的磁盘空间。
-
对于高基数列可能不是最优选择
- 原理:高基数列是指列中的不同值数量接近或等于表中的行数。对于这样的列,B - Tree 索引的优势可能不明显。因为在这种情况下,索引可能需要维护大量的不同值,导致索引结构庞大,查询时虽然能够定位数据,但在比较和筛选索引节点时可能效率不高。
- 示例:在一个用户表
users中,user_id列是唯一标识每个用户的列,属于高基数列。如果大部分查询都是基于user_id进行精确查询,哈希索引可能在这种情况下比 B - Tree 索引更高效,因为哈希索引可以直接通过哈希函数快速定位到记录。
-
不适合全文检索场景
- 原理:B - Tree 索引主要基于索引列的值进行比较和排序,对于包含大量文本内容的列进行全文检索(如查找文本中包含特定关键词的记录)时,B - Tree 索引的效果不佳。它无法像专门的全文检索索引那样理解文本的语义和词汇关系。
- 示例:在一个博客文章表
blog_posts中,对于article_text(文章内容)列,使用 B - Tree 索引来进行全文检索(如查找包含 “数据库优化” 关键词的文章)会非常困难和低效,需要使用专门的全文检索索引工具或技术来解决此类问题。
-
达梦数据库中如何选择合适的索引类型?
-
考虑查询需求特点
- 精确查询为主的场景
- 哈希(Hash)索引适用情况:如果查询主要是精确匹配,例如通过唯一标识符(如用户 ID、订单 ID 等)来查找记录,哈希索引是一个不错的选择。哈希索引通过哈希函数将索引键直接映射到存储位置,能够在常数时间内进行精确查找。
- 示例:在一个电商系统的订单表中,
order_id是唯一的。如果经常执行SELECT * FROM orders WHERE order_id = 12345;这样的查询,使用哈希索引可以快速定位订单记录。
- 范围查询和排序操作频繁的场景
- B - Tree 索引适用情况:B - Tree 索引在范围查询(如查询价格在某个区间内的商品)和排序操作(如按照时间顺序查询订单)方面表现出色。它以平衡树的结构存储数据,使得在进行范围查询时能够高效地遍历索引树,并且在排序操作中可以利用索引的顺序性减少额外的排序成本。
- 示例:在产品表中,对于
price列建立 B - Tree 索引,当执行SELECT * FROM products WHERE price BETWEEN 100 AND 200 ORDER BY price;查询时,B - Tree 索引可以同时满足范围查询和排序的需求。
- 模糊查询和前缀匹配查询场景
- B - Tree 索引部分适用情况:对于字符串类型列的模糊查询,如
WHERE column LIKE 'prefix%'(前缀匹配)这种查询,B - Tree 索引可以发挥一定作用。它可以利用索引的排序特性快速定位以指定前缀开头的记录。但对于WHERE column LIKE '%suffix'(后缀匹配)或WHERE column LIKE '%middle%'(中间包含匹配)这种查询,B - Tree 索引效率较低。 - 全文检索索引适用情况:如果需要对文本内容进行复杂的模糊查询,如在文章内容中查找包含特定关键词的记录,就需要使用全文检索索引。达梦数据库提供了全文检索功能,可以对文本列建立全文检索索引来满足这种需求。
- 示例:在一个文档管理系统中,对于文档内容列,如果经常执行
SELECT * FROM documents WHERE content LIKE '%database%';这样的查询,建立全文检索索引会比 B - Tree 索引更有效。
- B - Tree 索引部分适用情况:对于字符串类型列的模糊查询,如
- 精确查询为主的场景
-
考虑数据的基数(Cardinality)
- 低基数数据列
- 位图(Bitmap)索引适用情况:当列中的不同值数量较少(低基数),如性别(男 / 女)、状态(有效 / 无效)等列,位图索引是一个很好的选择。位图索引通过使用位图来表示列中每个值在表中的位置,对于基于这些列的查询和统计操作(如
SELECT COUNT(*))效率较高。 - 示例:在员工表中,对于
gender(性别)列建立位图索引。当查询男员工或女员工的数量时,位图索引可以快速进行统计,如SELECT COUNT(*) FROM employees WHERE gender = '男';。
- 位图(Bitmap)索引适用情况:当列中的不同值数量较少(低基数),如性别(男 / 女)、状态(有效 / 无效)等列,位图索引是一个很好的选择。位图索引通过使用位图来表示列中每个值在表中的位置,对于基于这些列的查询和统计操作(如
- 高基数数据列
- 哈希或 B - Tree 索引适用情况:对于高基数列(列中的不同值数量接近或等于表中的行数),如用户表中的
user_id、产品表中的product_id等,如果是精确查询为主,哈希索引可能更高效;如果涉及范围查询、排序等操作,B - Tree 索引更合适。 - 示例:在用户登录系统时,通过
user_id进行用户身份验证,哈希索引可以快速定位用户记录;而在查询用户注册时间顺序并进行范围筛选时,B - Tree 索引在registration_date列上更能发挥优势。
- 哈希或 B - Tree 索引适用情况:对于高基数列(列中的不同值数量接近或等于表中的行数),如用户表中的
- 低基数数据列
-
考虑数据更新频率和索引维护成本
- 数据更新频繁的列
- 简单索引结构优先:如果列的数据更新频繁(如库存表中的库存数量列),选择索引结构相对简单的索引类型可以减少索引维护成本。B - Tree 索引在这种情况下相对比较合适,因为它在数据更新时的维护操作相对成熟和高效。哈希索引在数据更新时可能需要重新计算哈希值并调整存储位置,维护成本可能较高。
- 谨慎使用复杂索引:对于复杂的索引结构,如组合索引(多个列构成的索引)或函数索引(基于列的函数结果建立的索引),在数据更新频繁的列上使用要更加谨慎。因为每次数据更新可能会导致这些复杂索引的重新计算和调整,增加系统负担。
- 示例:在一个实时库存管理系统的库存表中,对于
stock_quantity列,频繁的库存增减操作使得使用简单的 B - Tree 索引更为合适,避免使用可能会增加维护成本的复杂索引结构。
- 数据更新频繁的列
-
考虑存储空间限制
- 空间占用大的索引类型权衡:B - Tree 索引和全文检索索引可能会占用较多的存储空间,因为 B - Tree 索引存储了索引列的值和指针等信息,全文检索索引可能需要存储词汇表、倒排索引等结构。如果数据库的存储空间有限,需要权衡这些索引类型的使用。
- 紧凑索引结构选择:在存储空间紧张的情况下,位图索引相对比较紧凑,对于低基数列可以考虑使用位图索引来减少存储空间占用,同时满足相应的查询需求。
- 示例:在一个存储大量日志数据的数据库中,对于一些低基数的状态列(如日志级别:DEBUG、INFO、WARN、ERROR),使用位图索引可以在节省存储空间的同时,提供有效的查询支持。

















 3091
3091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









