







我:kakfa的段号其实就是根据偏移量来的,它代表当前段内偏移量最小的那条数据的offset,比如:

segment1的段号是200,segment2的段号是500,那么segment1就存储了偏移量200-499的消息。
面试官:嗯嗯,那定位到段后,如何定位到具体的消息,直接遍历吗?
我:不是直接遍历,直接遍历效率太低,kafka采用稀疏索引的方式来搜索具体的消息,其实每个log分段后,除了log文件外,还有两个索引文件,分别是.index和.timeindex,

其中.index就是我说的偏移量索引文件,它不会为每条消息创建索引,它会每隔一个范围区间创建索引,所以称之为稀疏索引。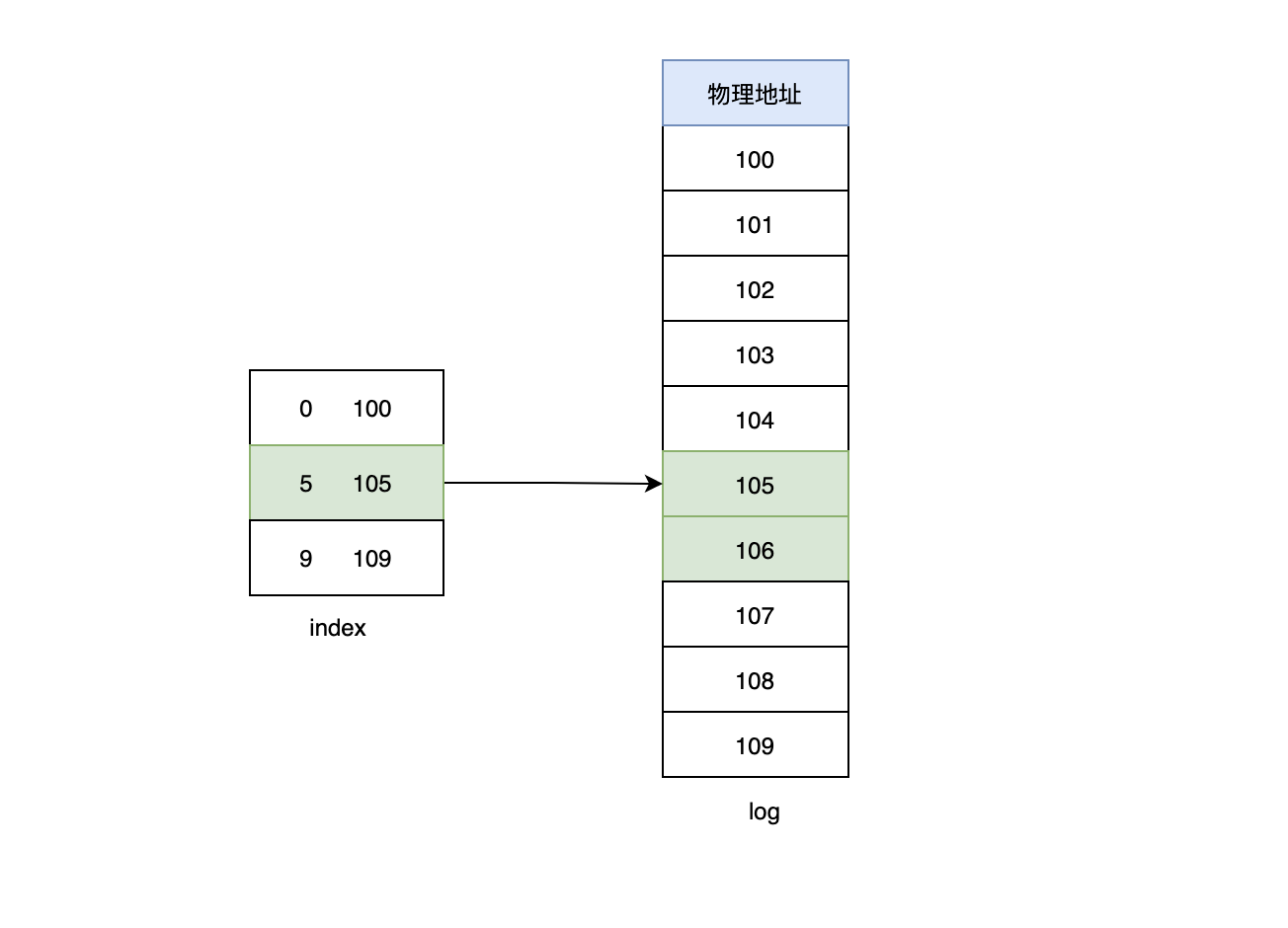 比如我们要查找消息6的时候,首先加载稀疏文件索引.index到内存中,然后通过二分法定位到消息5,最后通过消息5指向的物理地址接着向下顺序查找,直至找到消息6。
比如我们要查找消息6的时候,首先加载稀疏文件索引.index到内存中,然后通过二分法定位到消息5,最后通过消息5指向的物理地址接着向下顺序查找,直至找到消息6。
面试官:那稀疏索引的好处是什么?
我:稀疏索引是一个折中的方案,既不占用太多空间,也提供了一定的快速检索能力。
面试官:上面你说到了.timeindex文件,它是干嘛的?
我:这和kafka清理数据有着密切的关系,kafka默认保留7天内的数据,对于超过7天的数据,会被清理掉,这里的清理逻辑主要根据timeindex时间索引文件里最大的时间来判断的,如果最大时间与当前时间差值超过7天,那么对应的数据段就会被清理掉。
面试官:说到数据清理,除了你说的根据时间来判断的,还有哪些?
我:还有根据日志文件大小和日志起始偏移量的方式,对于日志文件大小,如果log文件(所有的数据段总和)大于我们设定的阈值,那么就会从第一个数据段开始清理,直至满足条件。对于日志起始偏移量,如果日志段的起始偏移量小于等于我们设定的阈值,那么对应的数据段就会被清理掉。
面试官:你知道消息合并吗?如果知道说说消息合并带来的好处。
我:了解一点,消息合并就是把多条消息合并在一起,然后一次rpc调用发给broker,这样的好处无疑会减少很多网络IO资源,其次消息会有个crc校验,如果不合并每条消息都要crc,合并之后,多条消息可以一起crc一次。
面试官:那合并之后的消息,什么时候会给broker?
我:合并的消息会在缓冲区内,如果缓冲区快满了或者一段时间内没有生产消息了,那么就会把消息发给broker。
面试官:那你知道消息压缩吗?
我:知道一点,压缩是利用cpu时间来节省带宽成本,压缩可以使数据包的体积变得更小,生产者负责将数据消息压缩,消费者拿到消息后自行解压。
面试官:所有只有生产者可以压缩?
我:不是的,broker也可以压缩,当生产者指定的压缩算法和broker指定压缩算法的不一样的时候,broker会先按照生产者的压缩算法解压缩一下,然后再按照自己的压缩算法压缩一下,这是需要注意的,如果出现这种情况会影响整体的吞吐。还有就是新老版本的问题,如果新老版本的压缩算法不兼容,比如broker版本比较老,不支持新的压缩算法,那么也会发生一样的事情。
面试官:我们知道kafka的消息是要写入磁盘的,磁盘IO会不会很慢?
我:是这样的,kafka的消息是磁盘顺序读写的,有关测试结果表明,一个由6块7200r/min的RAID-5阵列组成的磁盘簇的线性(顺序)写入速度可以达到 600MB/s,而随机写入速度只有 100KB/s,两者性能相差6000倍。操作系统可以针对线性读写做深层次的优化,比如预读(read-ahead,提前将一个比较大的磁盘块读入内存)和后写(write-behind,将很多小的逻辑写操作合并起来组成一个大的物理写操作)技术。顺序写盘的速度不仅比随机写盘的速度快,而且也比随机写内存的速度快。
面试官:顺序读写是为了解决了缓慢的磁盘问题,那在网络方面还有其他的优化吗?
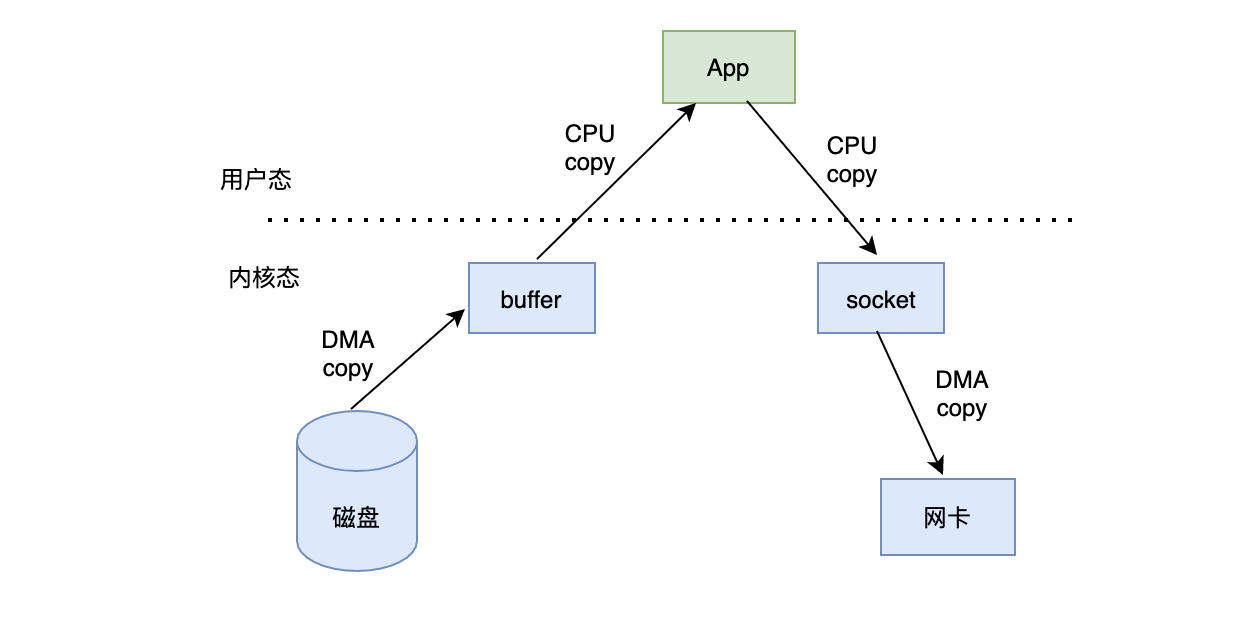
我:有,零拷贝,在没有零拷贝的时候,消息是这样交互的:
-
切到内核态:内核把磁盘数据copy到内核缓冲区
-
切到用户态:把内核的数据copy到用户程序
-
切到内核态:用户数据copy到内核socket缓冲区
-
socket把数据copy给网卡
可以发现一份数据经过多次copy,最终兜兜转转又回到了内核态,实属浪费。
当有了零拷贝之后:
-
磁盘数据copy到内核缓冲
-
内核缓冲把描述符和长度发给socket,同时直接把数据发给网卡
可以发现通过零拷贝,减少了两次copy过程,大大降低了开销。
可靠篇
面试官:(关于性能方面的问的差不多了,接下来换换口味吧),kafka的多消费者模型是怎么做到的?
我:如果要支持多个消费者同时消费一个topic,最简单的方式就是把topic复制一份,但这无疑会浪费很多空间,尤其在消费者很多的情况下,

于是kafka设计出一套offset机制,即一份数据,不同的消费者根据位置来获取不同的消息即可。
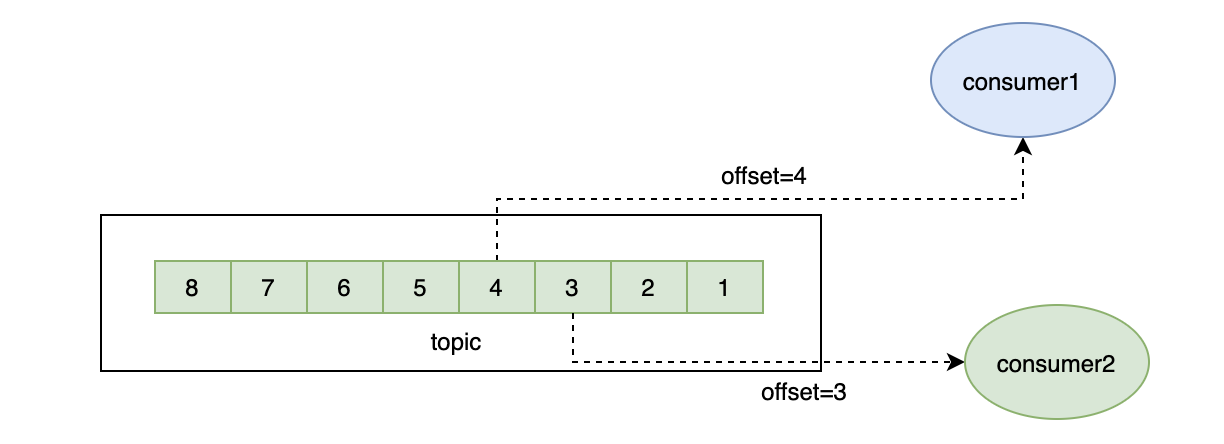
面试官:那你知道消费者的offset存在哪吗?
我:很久以前,是存在zookeeper中的,但是offset需要频繁更新,zookeeper又不适合频繁更新,所以后来就把消费者位移存在了一个叫_consumer_offset的topic中,这个topic会在第一个消费者启动的时候自动创建,默认50个分区,3个副本。
面试官:那你说说这个_consumer_offset里面具体存了什么?
我:这里其实主要分为key和value,value可以简单的认为就是我们的消费者位移,关于key,这里要细说下,由于每个消费者都属于一个消费者组,并且每个消费者其实消费的是某个topic的分区,所以通过group-topic-partition就可以关联上对应的消费者了,这也就是key的组成。
面试官:那你能介绍下消费者提交位移的方式吗?
我:这里分为自动提交和手动提交。自动提交的话,就不需要我们干预,我们消费完消息后,kafka会自动帮我们提交,手动提交的话,就需要我们在消费到消息后自己主动commit。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

写在最后
可能有人会问我为什么愿意去花时间帮助大家实现求职梦想,因为我一直坚信时间是可以复制的。我牺牲了自己的大概十个小时写了这片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。


上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
)]
上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!














 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









