






Hystrix的设计思路
下面从4个方面介绍一下Hystrix的设计思路。
1)线程隔离机制。
2)熔断机制。
3)滚动(滑动)时间窗口。
4)Hystrix调用接口的请求处理流程。
线程隔离机制
在Hystrix机制中,当前服务与其他接口存在强依赖关系,且每个依赖都有一个隔离的线程池。
如图10-3所示,当前服务调用接口A时,并发线程的最大个数是10,调用接口M时,并发线程的最大个数是5。

• 图10-3 隔离线程池示意图
一般来说,当前服务依赖的一个接口响应慢时,正在运行的线程就会一直处于未释放状态,最终把所有的连接线程都卷入慢接口中。为此,在隔离线程的过程中,Hystrix的做法是每个依赖接口(也可以配置成几个接口共用)维护一个线程池,然后通过线程池的大小、排队数等隔离每个服务对依赖接口的调用,这样就不会出现前面的问题。
当然,在Hystrix机制中,除了使用线程池来隔离线程,还可以使用信号量(计数器)。
仍以调用接口A为例,因并发线程的最大个数是10,在信号量隔离的机制中,Hystix并不是使用size为10的线程池,而是使用一个信号量semaphoresA来 隔 离 , 每 当 调 用 接 口 A 时 即 执 行 semaphoresA++ , 调 用 之 后 执 行semaphoresA-,semaphoresA一旦超过10,就不再调用。
因为在使用线程池时经常需要切换线程,资源损耗较大,而信号量的优点恰巧就是切换快,所以正好能解决问题。不过它也有一个缺点,即接口一旦开始调用就无法中断,因为调用依赖的线程是当前请求的主线程,不像线程隔离那样调用依赖的是另外一个线程,当前请求的主线程可以根据超时时间把它中断。
至此,第一个问题就得到了解决,不会因为一个下游接口慢而将当前服务的所有连接数占满。
那第二个问题如何解决呢?这就涉及接下来要说的熔断机制了。
熔断机制
关于Hystrix熔断机制的设计思路,本小节将从以下几个方面来介绍。
1.在哪种条件下会触发熔断
熔断判断规则是某段时间内调用失败数超过特定的数量或比例时,就会触发熔断。那这个数据是如何统计出来的呢?
在 Hystrix 机 制 中 , 会 配 置 一 个 不 断 滚 动 的 统 计 时 间 窗 口
metrics.rollingStats.timeInMilliseconds,在每个统计时间窗口中,若调用接口的总数量达到circuitBreakerRequestVolumeThreshold,且接口调用超时 或 异 常 的 调 用 次 数 与 总 调 用 次 数 之 比 超 过circuitBreakerErrorThresholdPercentage,就会触发熔断。
2.熔断了会怎么样
如果熔断被触发,在
circuitBreakerSleepWindowInMilliseconds的时间内,便不再对外调用接口,而是直接调用本地的一个降级方法,代码如下所示。

3.熔断后怎么恢复
到达
circuitBreakerSleepWindowInMilliseconds的时间后,Hystrix首先会放开对接口的限制(断路器状态为HALF-OPEN),然后尝试使用一个请求去调用接口,如果调用成功,则恢复正常(断路器状态为CLOSED),如果调用失败或出现超时等待,就需要重新等待circuitBreakerSleepWindowInMilliseconds的时间,之后再重试。
这个不断滚动的时间窗口是什么意思呢?
滚动(滑动)时间窗口
比如把滚动事件的时间窗口设置为10秒,并不是说需要在1分10秒时统计一次,1分20秒时再统计一次,而是需要统计每一个10秒的时间窗口。
因此,还需要设置一个
metrics.rollingStats.numBuckets。假设设置metrics.rollingStats.numBuckets为10,表示时间窗口划分为10小份,每份是1秒,然后就会在1分0秒~1分10秒统计一次、1分1秒~1分11秒统计一次、1分2秒~1分12秒统计一次……即每隔1秒都有一个时间窗口。
图10-4所示即为一个10秒时间窗口,它被分成了10个桶(Bucket)。

• 图10-4 时间窗口示意图
在每个桶中,Hystrix首先会统计调用请求的成功数、失败数、超时数和拒绝数,再单独统计每10个桶的数据(到了第11个桶时就是统计第2个桶~第11个桶的合计数据)。
讲到这里,大家可能会觉得有点混乱,所以接下来笔者把Hystrix调用接口的请求处理流程梳理一下。
Hystrix调用接口的请求处理流程
图10-5所示为一次调用成功的流程。
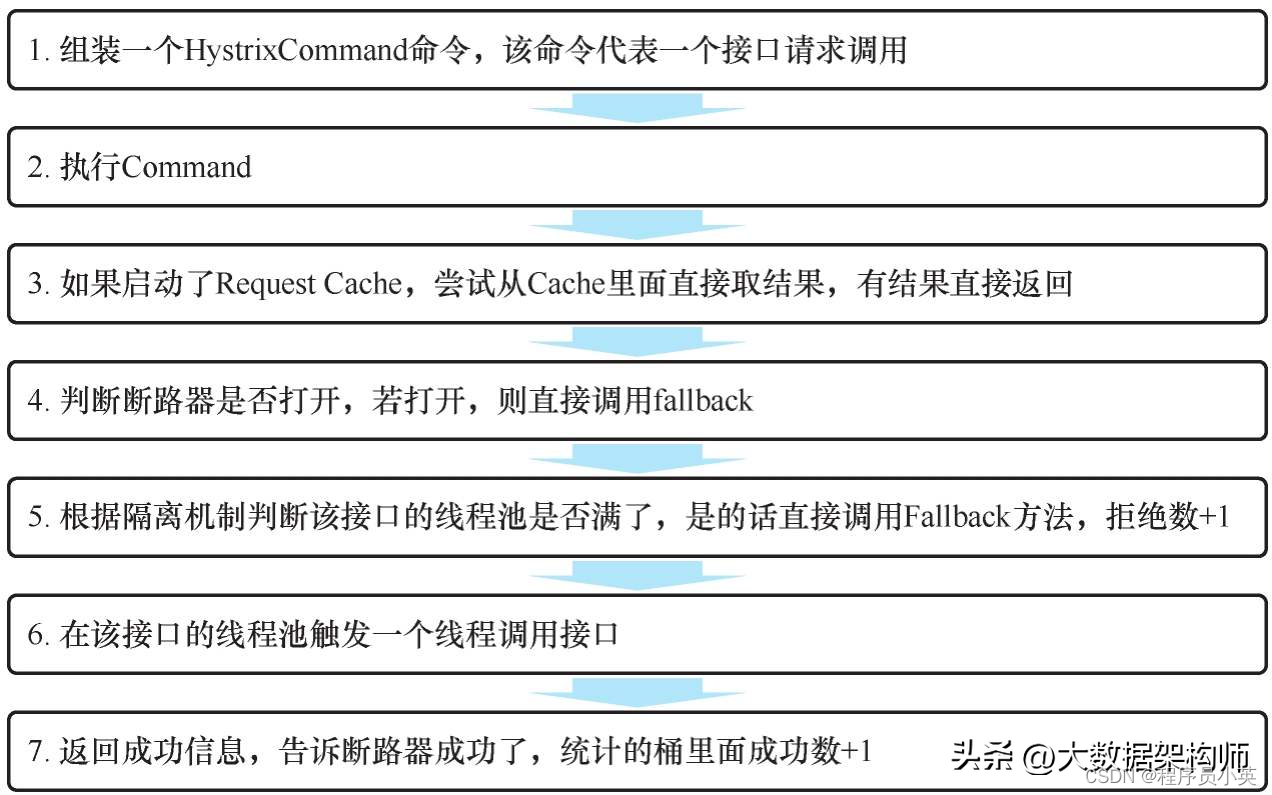
• 图10-5 Hystrix成功请求处理流程
图10-6所示为一次调用失败的流程。

• 图10-6 Hystrix失败请求处理流程
Hystrix调用接口的请求处理流程结束后,就可以直接启用它了。在Spring Cloud中启用Hystrix的操作也比较简单,此处就不展开了。
另 外 , Hystrix 还 有 requestcaching( 请 求 缓 存 ) 和requestcollapsing(请求合并)这两个功能,因为它们与熔断关系不大,这里就不再讲解。
注意事项
明白Hystrix的设计思路后,使用它之前还需要考虑数据一致性、超时降级、用户体验、熔断监控等方面。
数据一致性
这里通过一个例子来帮助理解。假设服务A更新了数据库,在调用服务B时直接降级了,那么服务A的数据库更新是否需要回滚?
再举一个复杂点的例子,比如服务A调用了服务B,服务B调用了服务C,在服务A中成功更新了数据库并成功调用了服务B,而服务B调用服务C时降级了,直接调用了Fallback方法,此时就会出现两个问题:服务B向服务A返回成功还是失败?服务A的数据库更新是否需要回滚?
以上两个例子体现的就是数据一致性的问题。关于这个问题并没有一个固定的设计标准,只要结合具体需求进行设计即可。
超时降级
比如服务A调用服务B时,因为调用过程中B没有在设置的时间内返回结果,被判断超时了,所以服务A又调用了降级的方法,其实服务B在接收到服务A的请求后,已经在执行工作并且没有中断;等服务B处理成功后,还是会返回处理成功的结果给服务A,可是服务A已经使用了降级的方法,而服务B又已经把工作做完了,此时就会导致服务B中的数据出现异常。
用户体验
请求触发熔断后,一般会出现以下3种情况。
1)用户发出读数据的请求时遇到有些接口降级了,导致部分数据获取不到,就需要在界面上给用户一定的提示,或让用户发现不了这部分数据的缺失。
2)用户发出写数据的请求时,熔断触发降级后,有些写操作就会改为异步,后续处理对用户没有任何影响,但要根据实际情况判断是否需要给用户提供一定的提示。
3)用户发出写数据的请求时,熔断触发降级后,操作可能会因回滚而消除,此时必须提示用户重新操作。
因此,服务调用触发了熔断降级时需要把这些情况都考虑到,以此来保证用户体验,而不是仅仅保证服务器不宕机。
熔断监控
熔断功能上线后,其实只是完成了熔断设计的第一步。因为Hystrix是一个事前配置的熔断框架,关于熔断配置对不对、效果好不好,只有实际使用后才知道。
为此,实际使用时,还需要从Hystrix的监控面板查看各个服务的熔断数据,然后根据实际情况再做调整,只有这样,才能将服务器的异常损失降到最低。
小结
引入Hystrix的项目方案一周就上线了,非常简单,下面两个问题很快就解决了。
1)下游接口慢导致当前服务所有连接池的线程被占满。
2)下游接口慢导致所有上游的接口雪崩。
之后系统就没有再出现相关的错误了。
但是Hystrix也有个不足。Hystrix的设计思想是事前配置熔断机制,也就是说,要事先预见流量是什么情况、系统负载能力如何,然后预先配置好熔断机制。但这种操作的缺点是,一旦实际流量或系统状况与预测的不一样,预先配置好的机制就达不到预期的效果。
所以这个项目上线以后,项目组又根据监控情况调整了几次参数。也因为这一点,开源Hystrix的公司Netflix想使用一个动态适应的更灵活的熔断机制。2018年后官方已不再为Hystrix开发新功能,转向开发Resilience4j了,对于Hystrix的原有功能只做简单维护。
再接着说熔断。目前的熔断框架已经设计得非常好了。对于使用熔断的人来说,虽然可以通过简单配置或代码编写实现应用,但是因为它是高并发中非常核心的一个技术,所以有必要理解清楚它的原理、机制及使用场景。
本文主要讲解了熔断的基本原理,有兴趣的读者可以去钻研一下它的源代码。
熔断和限流都是高并发场景当中面试官最喜欢问的,所以接下来讲一下限流。















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









