







 文章讨论了在IT系统中,尤其是数据库查询性能优化时,分表时机的选择及其与MySQL内存管理的关系。作者通过用户筛选功能案例,对比单表和多表查询的差异,并强调了减少磁盘IO对性能提升的重要性,介绍了MySQL如何通过InnoDBBufferPool等内存结构来优化查询。
文章讨论了在IT系统中,尤其是数据库查询性能优化时,分表时机的选择及其与MySQL内存管理的关系。作者通过用户筛选功能案例,对比单表和多表查询的差异,并强调了减少磁盘IO对性能提升的重要性,介绍了MySQL如何通过InnoDBBufferPool等内存结构来优化查询。
如果此时,我们才去做分表,可能已经太晚了,为什么呢?
我以最典型的应用场景:用户筛选功能,以查询年龄在18到24岁的100位女性用户为例:
在单表的情况下,我们的SQL是这么写的:
SELECT * FROM user WHERE age >= 18 AND age <= 24 AND sex = 0 LIMIT 100
但是,拆分user表后,用户记录分散到了多张表,比如,分散到user_1,user_2,user_3这三张表,此时,要查询满足上面条件的用户,我们的查询过程就变成这样:
-
遍历
user_1到user_3这三张表 -
分别从三张表找出满足条件的用户,即执行上面的SQL
-
合并这些用户记录
-
从合并结果中过滤出前100名用户记录
通过对比,我们会发现分表后的查询过程跟单表相比,变化是比较大的,这势必导致我们不得不修改代码,如果系统内类似的情况很多,那么,可能引发系统较大规模的业务逻辑改动,所以,在系统真正出现数据库性能瓶颈前,必须提前规划分表方案,预留时间去做系统改造。
那么,问题来了,我们到底在单表数据规模达到多少时,做分表是最合适的呢?
在开头我提到分表的原因是因为单表数据规模太大,导致系统功能使用越来越慢,而影响数据库查询性能的因素很多,有并发连接线程数、磁盘IO,锁等等。但是,一条查询语句如果需要通过磁盘IO来获得查询结果,那么,无论是否存在数据库的并发查询请求,磁盘IO的性能瓶颈都会存在。而连接线程和锁导致的的性能问题,一般只有在高并发的场景下才会出现。所以,减少数据查询的磁盘IO,是我们在优化数据库查询性能时,最先需要考虑的。
那么,MySQL又是通过什么方法来减少数据查询的磁盘IO的呢?我们来看下面这张图:
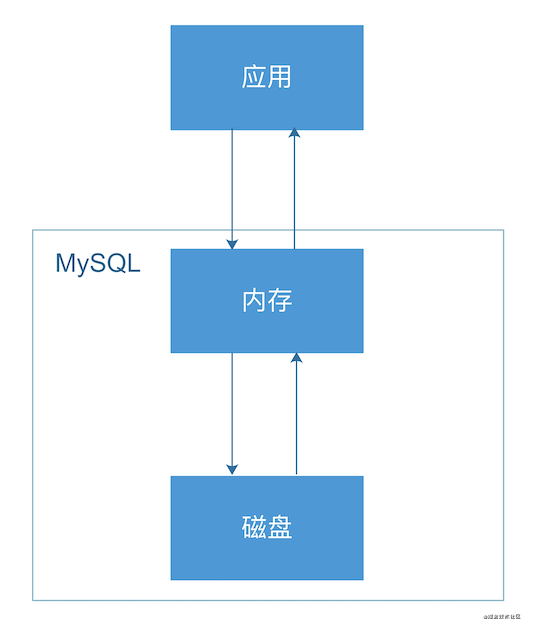
image-20210128202928887.png
这是很典型的应用请求MySQL的示意图,从图中,我们很容易发现,MySQL为了避免查询时都从磁盘读取查询结果,所以,在磁盘和应用之间加了一层内存,尽可能将磁盘数据加载到内存,那么,下次查询请求访问MySQL时,可以从内存中获取查询结果,避免了过多的磁盘IO的读取。
所以,通过MySQL对磁盘IO的优化方案,我们可以看出,只要把表中大部分数据缓存在内存中,那么,数据库的查询性能可以大大提升。结合user表来看,只要user表的数据规模可以保证大多数的数据可以加载到内存,那么,就不需要对user表拆分,反之,则需要拆分。
既然MySQL内存的大小决定了表何时拆分,那么,我们就先来看一下MySQL的内存结构吧!
内存管理
MySQL的内存结构: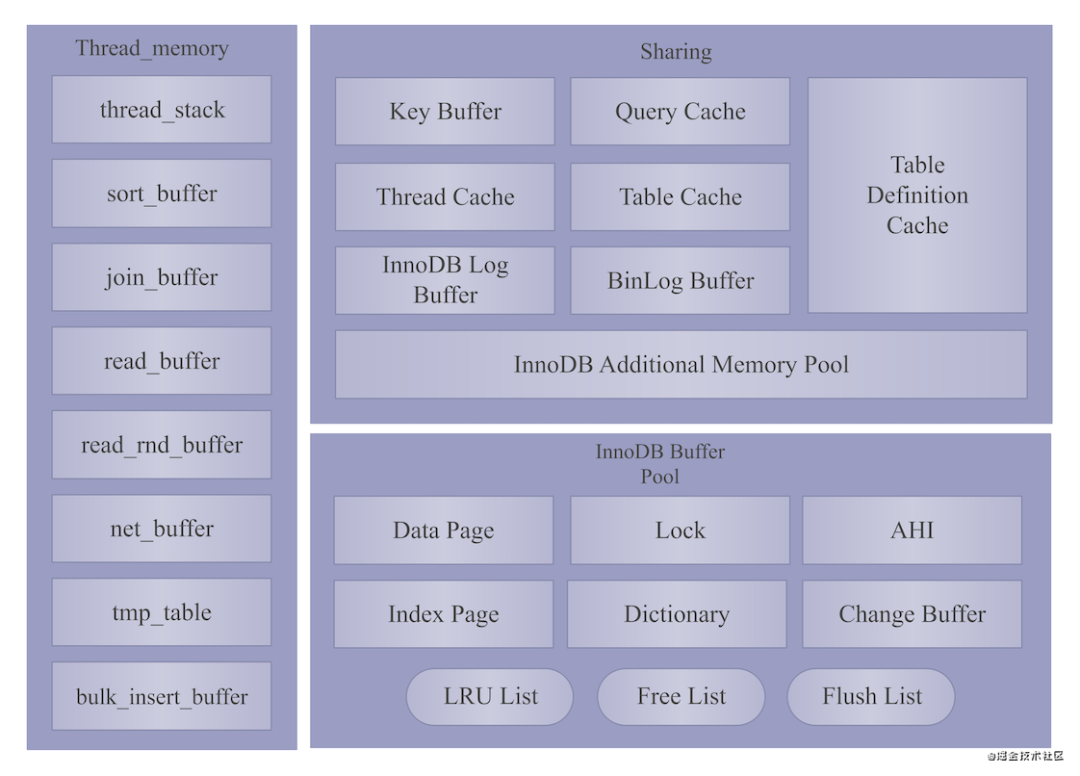 整个MySQL的内存主要分为3部分:
整个MySQL的内存主要分为3部分:
Thread Memory:这部分内存空间是每个连接线程独享的,也就是说每个连接自身独立拥有自己的内存空间。连接释放时,内存就释放。所以,它是动态的。
Sharing:这部分是所有连接线程共享的内存空间。
InnoDB Buffer Pool:这部分就是InnoDB引擎层维护的一块内存空间,它也是共享给每个连接线程的。它是相对静态的内存,不会随连接的释放而释放。
其中,Thread Memory和Sharing属于MySQL Server层的内存空间,InnoDB Buffer Pool属于MySQL InnoDB层的内存空间。
下面我再简单介绍一下上面3部分内存空间具体包含哪些部分:
Thread Memory
-
thread stack(线程栈):主要用来存放每一个线程自身的标识信息,如线程id,线程运行时基本信息等等。
-
sort_buffer:MySQL使用该内存区域进行记录排序。
-
join_buffer:在连表查询时,MySQL会使用该内存区来协助完成 Join操作。我会在《Join查询的极致优化》详细 讲解。
-
read_buffer:当查询无法使用索引时,需要全表扫描或全索引扫描来读取记录,那么,这时候,MySQL按照记录 的存储顺序依次读取数据页,每次读取的数据页首先会暂存在read_buffer中,该buffer写满或记录 读取完,就会将结果返回给上层调用。
-
read_rnd_buffer:和上面的顺序读取相对应,当 MySQL 进行非顺序读取(随机读取)数据页的时候,会利用这 个缓冲区暂存读取的数据。
-
net_buffer:这部分用来存放客户端连接线程的连接信息。
-
bulk_insert_buffer:当我们执行批量插入时,会使用该内存空间收集批量插入的记录,当该内存写满时,将该内 存中的记录写入数据文件。
-
tmp_table:临时表使用的内存空间。
Sharing
-
Key Buffer:MyISAM 索引缓存使用的内存空间。
-
Thread Cache:MySQL 为了减少连接线程的创建,将部分空闲的连接线程缓存在该内存区域,给后续连接使用。
-
InnoDB Log Buffer:这是 InnoDB 存储引擎的事务日志所使用的缓冲区。
-
Query Cache:缓存查询结果集的内存空间。
-
Table Cache:用来缓存表文件的文件句柄信息。
-
BinLog Buffer:用来缓存binlog的信息。
-
Table Definition Cache:用来缓存表定义信息。
-
InnoDB Additional Memory Pool:用来缓存InnoDB存储引擎internal 的共享数据结构信息。
InnoDB Buffer Pool
-
Index Page/Data Page:用来缓存InnoDB索引树的节点,包括非叶子节点的Index Page和叶子节点的Data Page。
-
Lock:用来缓存InnoDB索引树锁、AHI锁、数据字典锁等锁信息。
-
Dictionary:用来缓存InnoDB数据字典信息。
-
AHI:用来缓存InnoDB AHI结构相关信息。。
-
Change Buffer:用来存储change buffer信息。
-
LRU List/Free List/Flush List:InnoDB管理和维护索引树节点使用的几个链表,即使用这3个链表维护节点的增删 改查。
通过上面MySQL内存结构的讲解,我们得出2点:
-
Thread Memory是连接线程独享的内存空间。
-
Sharing和InnoDB Buffer Pool是连接线程共享的内存空间。
我们先来看下线程独享的内存空间Thread Memory是如何分配和释放的?
Linux内存结构
由于大多数情况,我们会把MySQL安装在Linux系统下,所以,MySQL连接线程独享的内存空间对Linux而言,就是Linux内存空间,所以,这里,我先讲解一下Linux中的内存结构是怎么样的?然后,再看一下它的分配和释放过程。
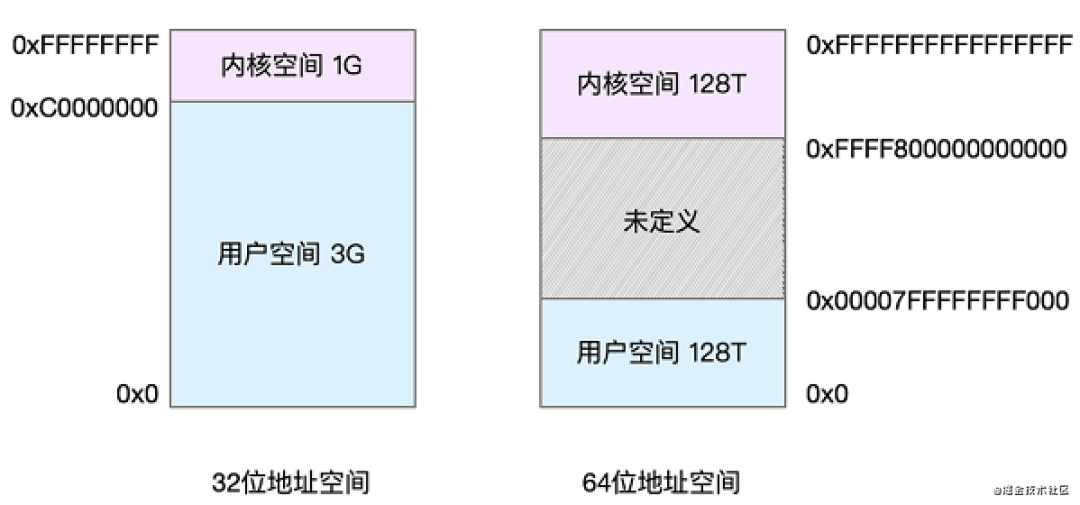
W311.png
上图为Linux系统分别在32位和64位情况下的内存结构。
32位
内核空间:从0xC0000000 ~ 0xFFFFFFF为内核空间,大小为1G,只有Linux系统自身可以访问,用户进程不能访问。
用户空间:从0x0 ~ 0xC0000000,大小为3G,Linux系统自身和用户进程都可以访问。
64位
内核空间:从0xFFF8000000000000 ~ 0xFFFFFFFFFFFF为内核空间,大小为128T,只有Linux系统自身可以访问,用户进程不能访问。
用户空间:从0x0 ~ 0x00007FFFFFFFF000,大小也为128T,Linux系统自身和用户进程都可以访问。
未定义:从0x00007FFFFFFFF000 ~ 0xFFF8000000000000,Linux未定义的空间。
用户空间
由于用户空间是我们进程使用的内存区,对MySQL而言,就是MySQL进程可以访问并控制的内存区域,所以,我们再详细看一下用户空间的内存结构:
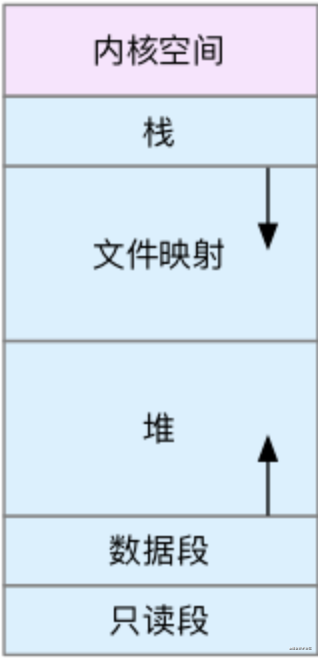
W310.png
上图为Linux用户空间(用户态)的内存结构,叫做虚拟内存,它包括以下几部分:
-
栈:包括局部变量和函数调用的上下文、调用返回地址等。
-
文件映射:包括动态库、共享内存等,从高地址开始向下增长。
-
堆:包括动态分配的内存,从低地址开始向上增长。
-
数据段:包括全局变量等。
-
只读段:包括代码和常量等。
内存分配
理解了用户空间内存的概念,我们再结合用户空间的概念,来看一下MySQL进程是如何分配和释放用户空间内存的?
MySQL使用C标准库的malloc()在堆动态分配内存,使用mmap()在文件映射段动态分配内存。详细过程如下图: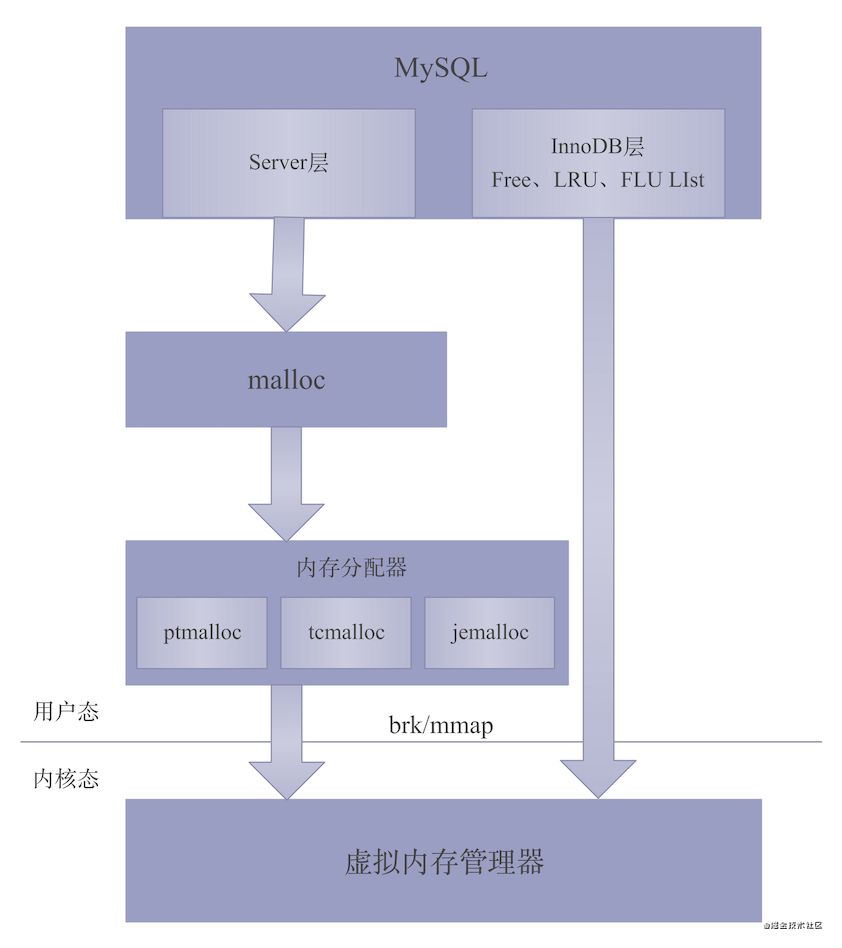
上图为MySQL分配内存的过程,主要分Server层和InnoDB层两部分的内存分配。
通过上图,我们发现MySQL在Server层是通过malloc来分配内存的,而InnoDB层是通过mmap来分配内存的。(搜索公众号Java知音,回复“2021”,送你一份Java面试题宝典)
图中,我们从上往下看:
-
MySQL Server层调用C语言的malloc函数申请分配内存
-
malloc调用内存分配器从用户态向Linux内核申请内存,为什么有个内存分配器,这是什么?我们先来看一张图:
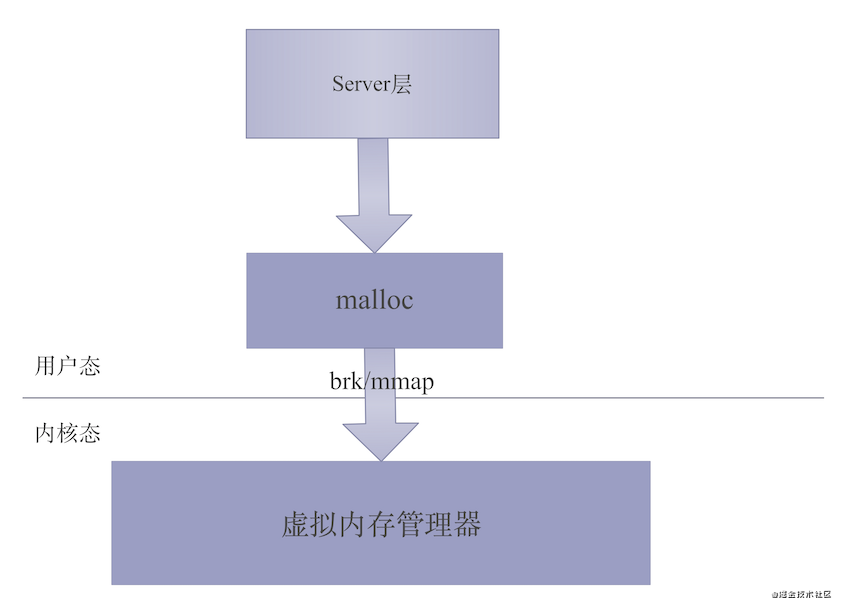
image-20210128234601866.png
这张图是malloc函数直接调用系统函数申请内存的过程,我们发现malloc通过brk和mmap这两个Linux系统函数从用户态向内核申请内存。这两个系统函数是干什么的呢?
brk
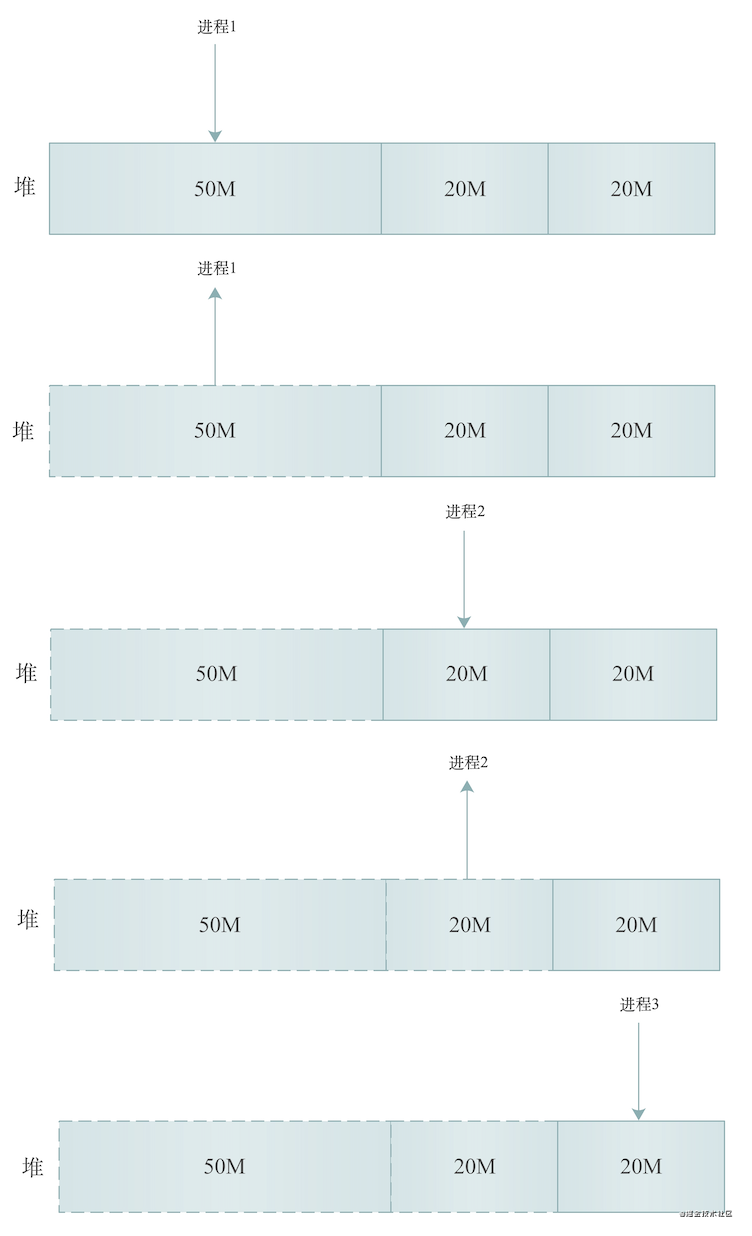
image-20210128235723307.png
当申请内存大小小于MMAP_THRESHOLD这个内核参数配置的大小(默认128K)时,Linux系统使用brk来分配内存,上图展示了brk分配内存的过程,从上到下,假设内存总大小为50 + 20 + 20 = 90M:
-
进程1申请分配了50M堆内存
-
进程1执行结束,释放50M堆内存,如上图,50M内存区域变为虚线
-
进程2申请分配了20M堆内存,如上图,在50M堆内存右边又分配了20M
-
进程2执行结束,释放20M堆内存,如上图,中间20M内存区域变虚线
-
进程3申请分配了20M堆内存,如上图,在中间20M堆内存右边又分配了20M
通过brk分配内存的过程,我们发现,这些分配的堆内存释放后并不会立刻归还系统。所以,内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
mmap
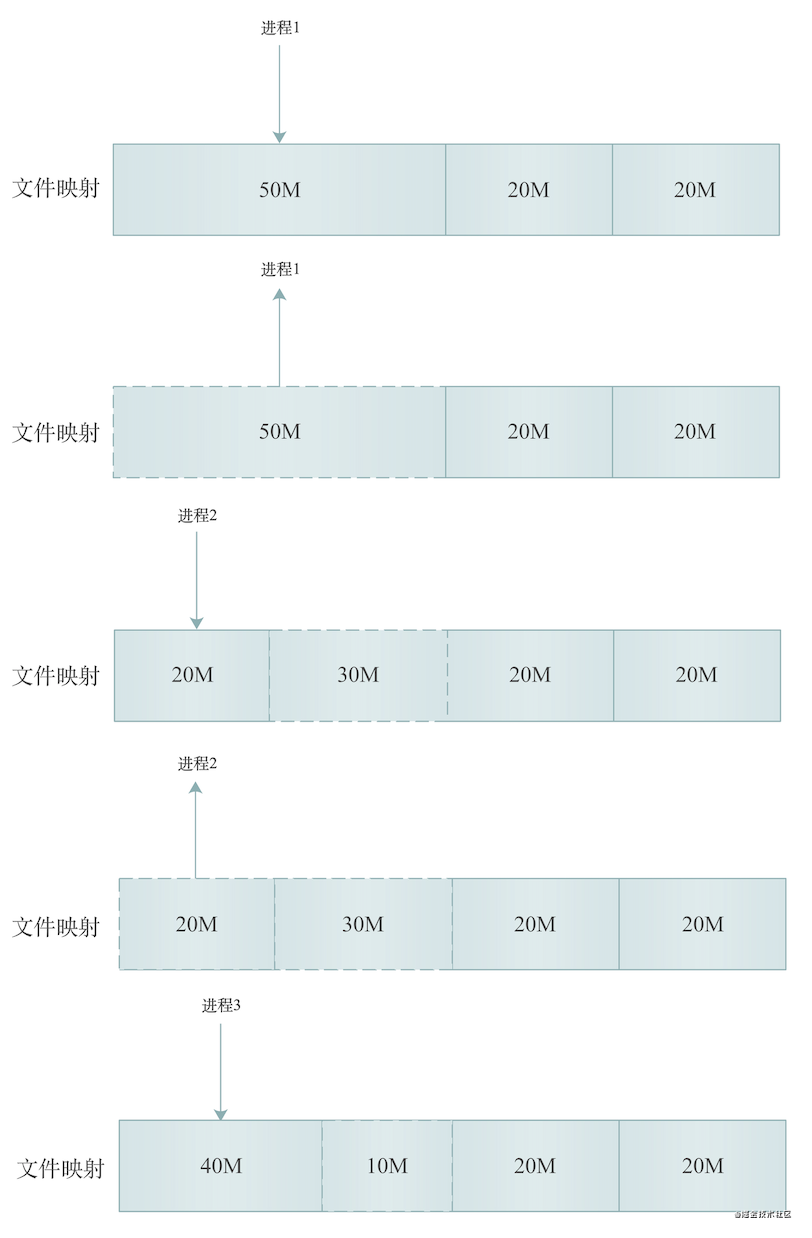
image-20210128220606454.png
当申请内存大小大于MMAP_THRESHOLD这个内核参数配置的大小(默认128K)时,Linux使用mmap分配内存,上图展示了mmap分配内存的过程,从上到下,假设内存总大小为50 + 20 + 20 = 90M:
-
进程1申请分配了50M文件映射段的内存
-
进程1执行结束,释放50M文件映射段的内存,如上图,50M内存区域变虚线
-
进程2申请分配了20M文件映射段的内存,如上图,在原来50M内存区域内又分配了20M
-
进程2执行结束,释放20M文件映射段的内存,如上图,最左边20M内存区域变虚线
-
进程3申请分配了40M堆内存,如上图,在原来50M内存区域内又分配了40M内存,剩下10M仍是释放状态,为虚线
通过mmap分配内存的过程,我们发现mmap方式释放内存后会将内存及时归还给系统,避免 OOM。但是频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是 malloc 只对大块内存使用 mmap 的原因。欧!!这里冒出一个新名词,缺页异常?别着急,我会在后面讲解。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
由于篇幅限制,小编在此截出几张知识讲解的图解





《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
img-community.csdnimg.cn/images/e5c14a7895254671a72faed303032d36.jpg" alt=“img” style=“zoom: 33%;” />
最后
由于篇幅限制,小编在此截出几张知识讲解的图解
[外链图片转存中…(img-8jadMXdZ-1713247451789)]
[外链图片转存中…(img-edUIPBeY-1713247451790)]
[外链图片转存中…(img-GoYH44Fn-1713247451790)]
[外链图片转存中…(img-TOmygJNK-1713247451790)]
[外链图片转存中…(img-qTLnFMCR-1713247451791)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 7452
7452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









