







然而如果链表要想访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,无法像数组那样,根据首地址和下标直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
2.2 循环链表

循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如我们之前做过的选队长问题。
2.3 双向链表
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。

双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历。
双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,使得双向链表插入、删除等操作比单链表更简单。
**用空间换时间。**开篇提到的缓存实际上就是利用了这种思想。如果我们把数据存储在硬盘上,会比较节省内存,但每次查找数据都要询问一次硬盘,会比较慢。但如果我们通过缓存技术,事先将数据加载在内存中,虽然会比较耗费内存空间,但是每次数据查询的速度就大大提高了。
3 基于链表实现 LRU 缓存淘汰算法
===================
我们可以维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
-
如果此数据之前已经被缓存了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
-
如果此数据没有在缓存链表中,又可以分为两种情况:
-
如果此时缓存未满,则将此结点直接插入到链表的头部;
-
如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
具体解释如下:
public static void main(String[] args) {
// 缓存容量为2
LRUCache cache = new LRUCache(2);
// 此时存入了1,缓存内{1}
cache.put(1);
// 此时存入了2,缓存内{2 -> 1}
cache.put(2);
// 此时存入了3,但缓存空间已满,所以移掉1存入3
// 缓存内{3 -> 2}
cache.put(3);
// 此时使用了数据2
// 缓存内{2 -> 3}
cache.get(2);
}
链表节点类:
要存储的信息:
值、下一个节点
package base;
public class Node {
public int val;
public Node next;
public Node(int v) {
this.val = v;
}
public Node(int v, Node next) {
this.val = v;
this.next = next;
}
}
单向链表类:
设置一个虚拟头节点、属性size记录链表长度
public Node head;
// 链表元素数
private int size;
public SingleList() {
// 初始化双向链表的数据
head = new Node(-1);
head.next = null;
size = 0;
}
提供添加元素的方法:
/**
-
在第index处插入元素e
-
@param index
-
@param e
*/
public void add(int index, int e){
if (index < 0 || index > size)
throw new IllegalArgumentException(“Add failed. Illegal index.”);
Node prev = head;
for (int i = 0; i < index; i ++){
prev = prev.next;
}
prev.next = new Node(e, prev.next);
size ++;
}
// 在链表尾部添加节点 x
public void addLast(Node x) {
add(size, x.val);
}
// 在链表头部添加节点 x
public void addFirst(Node x) {
add(0, x.val);
}
提供删除元素的方法:
- 根据索引删除
// 从链表中删除index处的元素
public Node remove(int index){
if (index < 0 || index > size)
throw new IllegalArgumentException(“Set failed. Illegal index.”);
Node prev = head;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node retNode = prev.next;
prev.next = retNode.next;
retNode.next = null;
size --;
return retNode;
}
- 删除传入节点
// 删除节点x
public void remove(Node x){
Node pre = head;
Node node = head.next;
while (node != null){
if (node == x){
pre.next = node.next;
node.next = null;
}
node = node.next;
pre = pre.next;
}
}
- 删除第一或最后一个元素
/**
-
删除最后一个节点
-
@return
*/
public Node removeLast() {
return remove(size - 1);
}
/**
-
删除第一个节点
-
@return
*/
public Node removeFirst(){
return remove(0);
}
提供根据数值寻找节点的方法:
/**
-
根据值寻找节点
-
@param val
-
@return
*/
public Node findByValue(int val){
Node node = head;
while (node != null){
if (node.val == val){
return node;
}
node = node.next;
}
return null;
}
LRU缓存算法类:
用链表的底层来实现缓存,构造函数传入初始容量
public class LRUCache {
private SingleList cache;
private int cap; // 最大容量
public LRUCache(int capacity) {
this.cap = capacity;
cache = new SingleList();
}
}
将某个val提升为最近使用的:
private void makeRecently(int val) {
Node x = cache.findByValue(val);
// 先从链表中删除这个节点
cache.remove(x);
// 重新插到队头
cache.addFirst(x);
}
添加最近使用的val:
private void addRecently(int val) {
Node x = new Node(val);
// 链表头部就是最近使用的元素
cache.addFirst(x);
}
删除某一个val:先找到对应节点,然后删除
private void deleteVal(int val) {
Node x = cache.findByValue(val);
// 从链表中删除
cache.remove(x);
}
删除最久未使用的val:
private void removeLeastRecently() {
// 链表尾部元素就是最久未使用的
cache.removeLast();
}
使用缓存中的某个数据:
public Node get(int val) {
Node x = cache.findByValue(val);
if (x == null){
return null;
}
// 将该数据提升为最近使用的
makeRecently(val);
return x;
}
放入新数据:如果缓存已经满了则需要删除最久未使用的
public void put(int val) {
if (cache.findByValue(val) != null) {
// 删除旧的数据
deleteVal(val);
// 新插入的数据为最近使用的数据
addRecently(val);
return;
}
if (cap == cache.size()) {
// 删除最久未使用的元素
removeLeastRecently();
}
// 添加为最近使用的元素
addRecently(val);
}
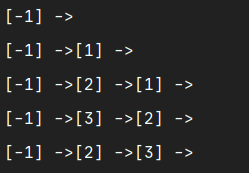
打印方法:
public void printCache(){
Node pointer = cache.head;
while (pointer != null){
System.out.print(“[” + pointer.val + “] ->”);
pointer = pointer.next;
}
System.out.println();
}
*3.1 优化
我们可以继续优化这个实现思路,比如引入散列表(Hash table)来记录每个数据的位置,将缓存访问的时间复杂度降到 O(1)。这里缓存改为存储键值对了,其实上面的单向链表的每个Node也可以存储两个值,key和value,有兴趣的同学们可以自己尝试一下
如果想让 put 和 get 方法的时间复杂度为 O(1),我们可以尝试总结以下几点:
-
cache中的元素存储时必须能体现先后顺序,以区分最近使用的和久未使用的数据; -
要在
cache中快速找某个key是否存在并得到对应的val; -
每次访问
cache中的值,需要将其变为最近使用的,即,要支持在任意位置快速插入和删除元素。
哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。
所以,结合一下,用哈希链表
实际上LRU算法的核心数据结构就是哈希链表,长这样:
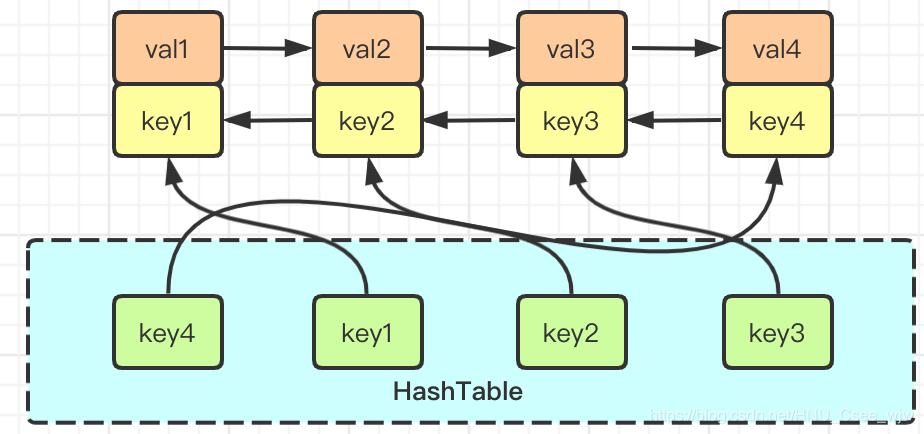
再看上面的条件:
-
同单链表的情况相同,如果从头部插入元素,显然越靠近尾部的元素是最久未使用的。(当然反过来也成立);
-
对于一个key,可以通过HashTable快速查找到val;
-
链表显然是支持在任意位置快速插入和删除的。只不过传统的链表查找元素的位置较慢,而这里借助哈希表,通过
key快速映射到一个链表节点,然后进行插入和删除。
这次我们从尾部插入,从头部删除~
双向链表的节点类Node:
只增加了一个指向上一个节点的指针 Node pre
class Node {
public int key, val;
public Node next, prev;
public Node(int k, int v) {
this.key = k;
this.val = v;
}
}
依靠实现的节点类Node给出双向链表的实现:
构造方法初始化头尾虚节点,链表元素个数
class DoubleList {
// 头尾虚节点
public Node head, tail;
// 链表元素数
private int size;
public DoubleList() {
// 初始化双向链表的数据
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0;
}
}
在尾部添加节点的方法:
// 在链表尾部添加节点 x,时间 O(1)
public void addLast(Node x) {
x.prev = tail.prev;
x.next = tail;
tail.prev.next = x;
tail.prev = x;
size++;
}
删除节点x的方法:
删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,双向链表由于有pre指针的存在所以删除操作的时间复杂度为O(1)
// 删除链表中的 x 节点(x 一定存在)
// 由于是双链表且给的是目标 Node 节点,时间 O(1)
public void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
size–;
}
删除链表第一个节点的方法:
// 删除链表中第一个节点,并返回该节点,时间 O(1)
public Node removeFirst() {
if (head.next == tail)
return null;
Node first = head.next;
remove(first);
return first;
}
LRU缓存算法类:
有了双向链表的实现,我们只需要在 LRU 算法中把它和哈希表结合起来即可
构造方法:
class LRUCache {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)…
private DoubleList cache;
// 最大容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
}
接下来先设计一些辅助函数,用于随后进行操作的:
将某个值设置为最近使用的:
private void makeRecently(int key) {
Node x = map.get(key);
// 先从链表中删除这个节点
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

更多:Java进阶核心知识集
包含:JVM,JAVA集合,网络,JAVA多线程并发,JAVA基础,Spring原理,微服务,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存等等

高效学习视频
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-q5zgMBLc-1713732332977)]
[外链图片转存中…(img-F1ujSWEV-1713732332978)]
[外链图片转存中…(img-PGN6qSPn-1713732332978)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
更多:Java进阶核心知识集
包含:JVM,JAVA集合,网络,JAVA多线程并发,JAVA基础,Spring原理,微服务,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存等等
[外链图片转存中…(img-7DrtrYVK-1713732332979)]
高效学习视频
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









