






前言
前面我们已经学习的最小二乘法属于多元线性回归的主要概念,所以在看这篇文章之前,请确保你已经了解了最小二乘法,详情请见我的博客动手学机器学习入门之Day1。
在机器学习领域,梯度下降和多元线性回归是两个至关重要的概念,它们为我们理解和构建复杂模型提供了基础。梯度下降作为一种优化算法,帮助我们调整模型参数以最小化损失函数,从而使模型更好地拟合数据。而多元线性回归则是一种经典的回归分析方法,用于建立因变量与多个自变量之间的线性关系。
在本文中,我们将深入探讨梯度下降算法的工作原理,以及如何应用它来优化模型参数。我们还将探讨多元线性回归模型的基本概念,包括如何建立模型、估计回归系数以及评估模型性能。
最后,我会用skicit-learn中SGDRegressor模型来搭建一个可以进行二元回归的模型,并且使用plotly库来对数据进行一个可视化。
通过学习梯度下降和多元线性回归,您将能够更好地理解机器学习模型的训练过程,并掌握构建和优化模型的关键技能。让我们一起深入探讨梯度下降和多元线性回归,为您的机器学习之旅增添新的知识和技能。
原理
梯度下降(Gradient Descent)
直观解释
想象你站在一座大山的某个位置,你的目标是走到山脚。但是你眼睛被蒙上了,你只能通过脚下的感觉来判断前进的方向。梯度下降就好比你在尝试走下山的过程。
-
起点选择:你从某个位置开始下山,这个位置对应于初始的模型参数。
-
下山步骤:你每向前迈出一步,都会感受到脚下坡度的陡峭程度,这个坡度就好比函数在当前位置的梯度(斜率)。
-
调整方向:如果你感觉坡度变陡了,你就朝着坡度最陡的方向走;如果坡度变缓了,你就朝着坡度变陡的方向走。这样,你会逐渐朝着山脚走去。
-
调整步长:你可以控制每一步的大小,这就是学习率。步子太大可能会导致你跨过山脚,步子太小可能会让你走的太慢。
-
收敛:最终,当你走到山脚时,你就找到了函数的最小值,也就是模型的最佳参数。

梯度下降就是通过不断调整模型参数,沿着损失函数梯度的反方向,逐步优化模型,使其更好地拟合数据。这个过程就像是在找到函数的最低点,从而使模型的预测能力达到最优。
主要概念:
梯度下降是一种优化算法,用于最小化函数的值。在机器学习中,它通常用于调整模型参数以最小化损失函数。
-
学习率(Learning Rate):控制每次参数更新的步长,过大可能导致震荡,过小可能导致收敛速度慢。
-
损失函数(Loss Function):衡量模型预测值与真实值之间的差异,常见的损失函数包括均方误差(MSE)和交叉熵损失等。
梯度下降公式:
梯度下降的更新规则通常如下所示:
![]()
其中:
- θ 是要更新的参数向量。
- α 是学习率。
- J(θ) 是损失函数。
- ∇J(θ) 是损失函数关于参数向量的梯度。
多元线性回归(Multiple Linear Regression)
多元线性回归是一种回归分析方法,用于预测因变量与一个或多个自变量之间的关系。
主要概念:
- 多元线性回归模型:用于描述因变量与多个自变量之间线性关系的模型

其中:
- y 是因变量。
- x1,x2,...,xn 是自变量。
- 𝛽0,𝛽1,𝛽2,...,𝛽𝑛是回归系数。
- ϵ是误差项。
- 最小二乘法(Ordinary Least Squares, OLS):常用的方法,通过最小化残差平方和来估计回归系数。
多元线性回归估计公式:
对于多元线性回归,回归系数可以通过以下公式估计:
![]()
其中:
- β^ 是回归系数的估计值。
- X 是自变量矩阵。
- y 是因变量向量。
实践
环境配置:pycharm 2023.2.3 python 3.11 Skicit-learn plotly numpy pandas
Step one:预处理数据
我们这里以skicit-learn自带的数据集鸢尾花数据集为例

一共有四个特征 150份数据
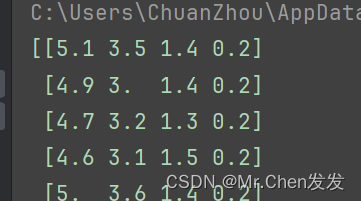
![]()
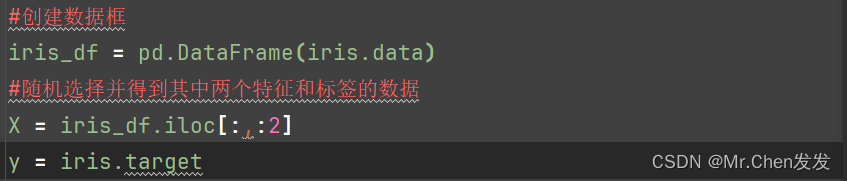
这里我们只要其中两个特征的数据
对数据进行预处理:
![]()

划分数据
![]()

Step two:建立模型和训练
![]()

这里介绍后面三个参数:
alpha(正则化参数): alpha 是控制正则化项的系数,用于防止过拟合。正则化项有助于限制模型的复杂度,避免模型在训练数据上过度拟合,从而提高模型的泛化能力。 增大 alpha 会增强正则化效果,降低模型复杂度,但可能会导致欠拟合;减小 alpha 则会减弱正则化效果,增加模型复杂度,可能导致过拟合。 learning_rate(学习率调度策略): learning_rate 参数控制模型在每次迭代中更新权重时的步长大小。学习率的选择对模型的训练效果至关重要。 在 SGDRegressor 中,learning_rate 可以设置为不同的值,如 'constant'、'optimal'、'invscaling'、'adaptive' 等,以控制学习率的变化方式。 不同的学习率调度策略适用于不同的问题和数据集。例如,'constant' 表示固定学习率,'optimal' 根据理论最优学习率进行更新,'invscaling' 根据时间逐渐降低学习率,'adaptive' 根据损失函数的值自适应调整学习率。 eta0(初始学习率): eta0 学习率的初始值,仅在学习率调度策略为 'constant' 时使用。 对于 'constant' 学习率调度策略,模型将保持固定的学习率,即初始学习率 eta0。
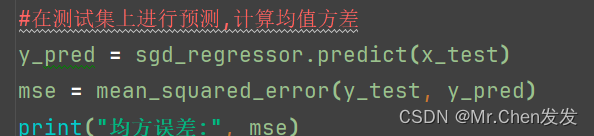
Step three:计算损失函数和评估模型
先计算对测试集的损失,这里计算的训练完毕后模型的损失
![]()
由于我们要计算每次迭代后损失,并统计成一个函数,我们可以这样做
![]()

将迭代次数设置为1,然后在for循环里面用partial_fit进行部分拟合训练,并将每次迭代后的损失添加到列表里,再绘制损失函数曲线
![]()
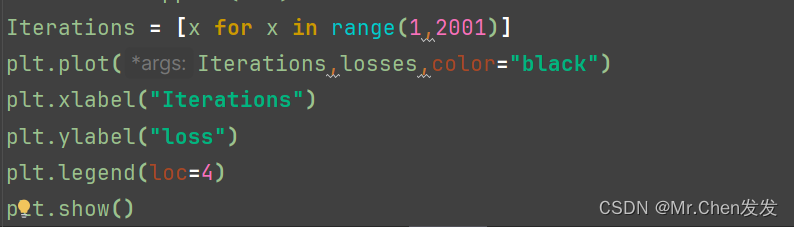
得到下列曲线,注意如果你得到的图形是乱七八糟的,你必须减小的学习率,建议调整为和我的一样
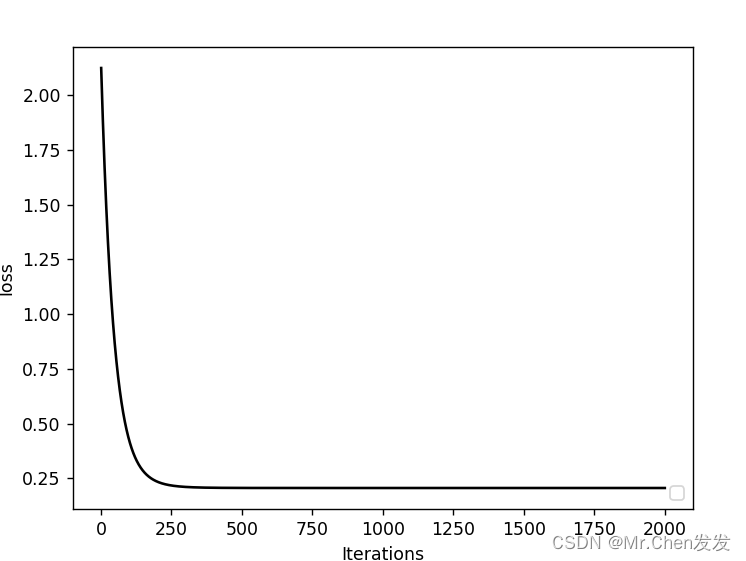
Step four:数据可视化
这里我们先介绍一下plotly库
我们先打开浏览器输入这个网址![]()
然后跳转到这个界面
我们稍后制作可视化的时候,只需要从这里面复制对应的代码,然后把名称改成你的数据集的名称就行了。
![]()
![]()
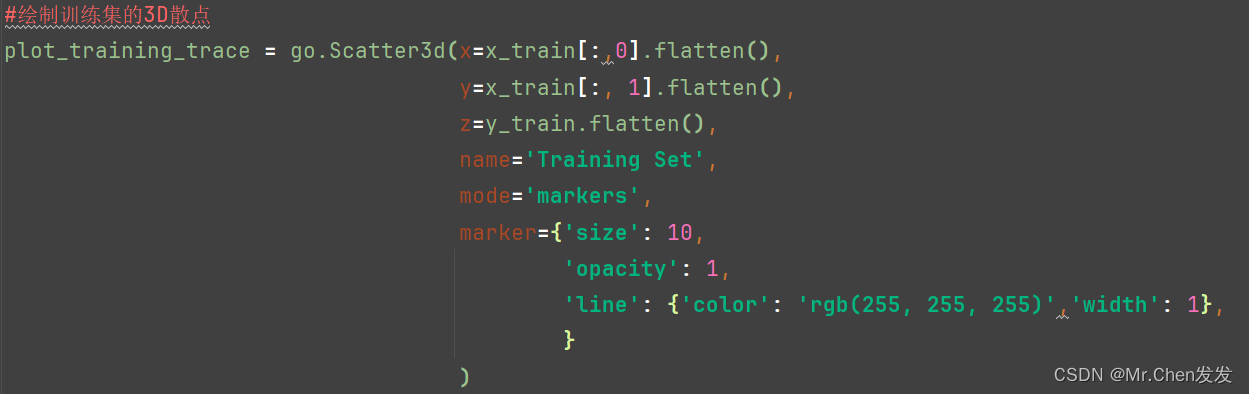
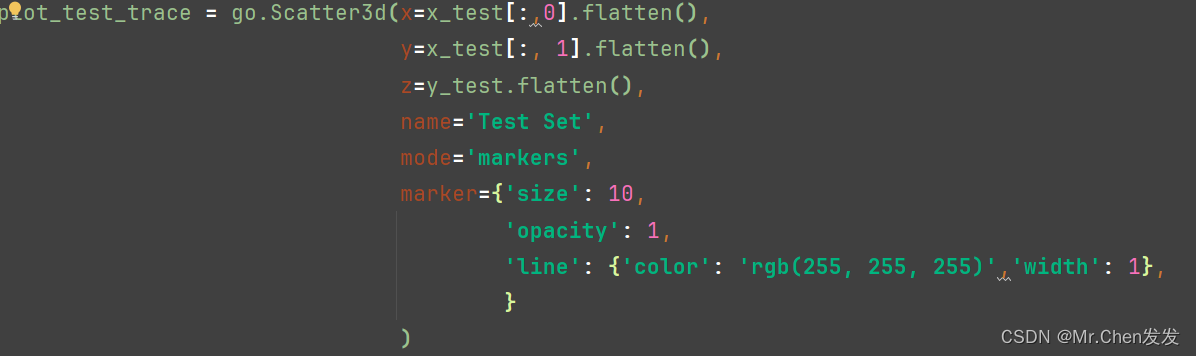
这里的代码都可以从那个网站上找到,需要注意的是,我们把特征1作为x轴,特征2为y轴,用的是x_train[:0]和x_test[:1]来提取两个特征的数据
然后我们还需要制作出我们模型的回归面

这里的代码我们都从网站上复制粘贴过来,然后把它写进html文件里
这个程序运行后就会在同级目录下生成一个html文件

我们点击右上角的edge浏览器打开
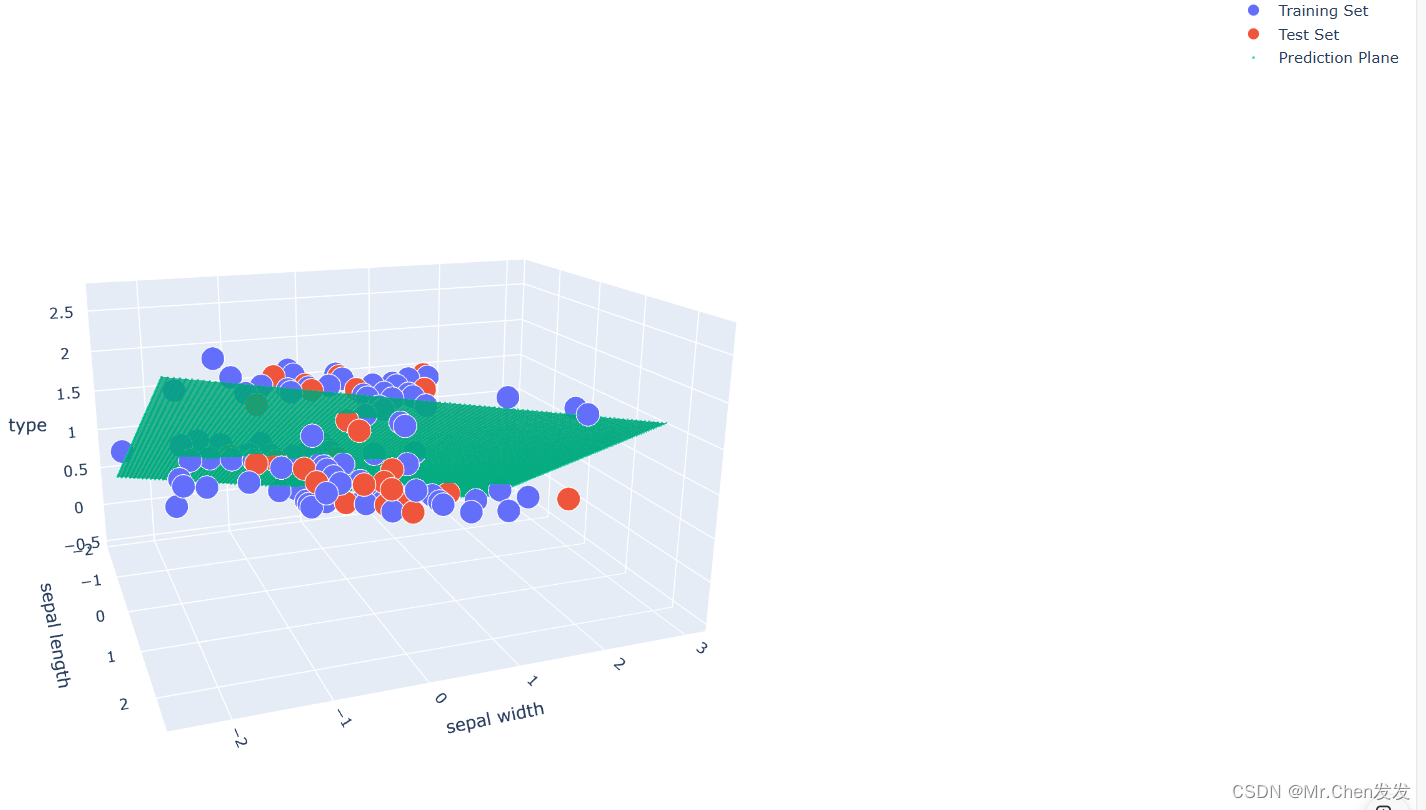
就可以看到我们这个模型建立的还是不错的。
接下来我们要得到相关系数
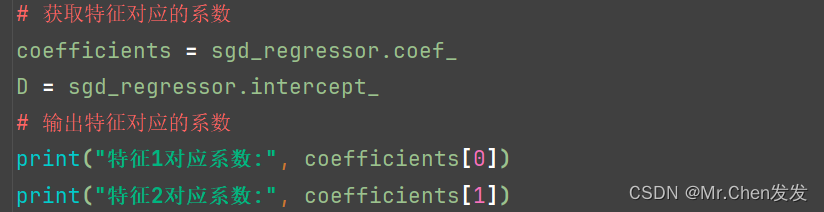


得到结果后我们再后续进行验证就大功告成了。
后言:探索机器学习的旅程
在本文中,我们深入探讨了机器学习中两个重要概念:梯度下降和多元线性回归。梯度下降作为一种优化算法,帮助我们最小化损失函数,从而训练模型以更好地预测未知数据。而多元线性回归则进一步扩展了我们对特征之间复杂关系的理解,使我们能够构建更准确的预测模型。
在实际应用中,梯度下降和多元线性回归发挥着关键作用,例如在房价预测、股票市场分析等领域。理解这些概念不仅有助于我们构建强大的机器学习模型,还能够为我们解决现实世界中的复杂问题提供有力支持。
未来,机器学习领域的可能性无限,我们可以继续探索更复杂的优化算法、高级的线性回归技术,甚至深入学习神经网络等更高级主题。这是一个充满挑战和机遇的领域,我们可以不断学习和成长,探索机器学习的无限可能性。
我鼓励每一位读者继续探索机器学习的世界,勇敢应用所学知识解决实际问题。如果您有任何问题或反馈,请随时与我分享。感谢您阅读本文,希望这篇博客能为您的机器学习之旅带来启发和帮助。
祝学习愉快,探索无限可能!















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









