






1. 本篇文章目标
将下面的excel中的寄存器表单读入并构建一个字典

2. openpyxl的各种基本使用方法
2.1 打开工作簿
wb = openpyxl.load_workbook('test_workbook.xlsx') |
2.2 获取工作簿中工作表名字并得到工作表
ws = wb[wb.sheetnames[0]] |
wb.sheetnames 会返回一个列表,列表中是每个工作表的名称,数据类型为str。执行上述代码后ws就是获取的工作表。
2.3 读取某个单元格的值
d = ws.cell(row=1, column=1).value | |
print(d) |
使用sheet.cell会返回cell对象,再使用cell.value才能返回单元格的值,执行上述代码的结果如下:

2.4 按行读取
按行读取可以用iter_rows()方法。
for row in ws.iter_rows(): | |
print(row) |
执行上述代码的输出如下:

由图可知,该方法应当是一个迭代器,返回的是row是一个tuple,里边是各个单元格cell。可以按照如下方法获取每列的值。
import pprint as pp | |
excel_list = [] | |
for row in ws.iter_rows(): | |
row = list(row) | |
for i in range(len(row)): | |
row[i] = row[i].value | |
excel_list.append(row) | |
pp.pprint(excel_list) |
这里用到了一个模块pprint,用来使打印出的列表、字典等美观易读。print结果如下:

可以看到已经将excel中的内容构建了一个列表,但是下边一些没有内容的行也读了进来,尽管每个单元的值是None,这是因为之前对下边的行做过编辑,然后又删掉,导致这些无内容的单元具有单元格格式,openpyxl会将这些单元格也识别进来,所以要想避免这种情况,使用xlrd库是一种办法,或者采用下面的办法:
excel_list = [] | |
for row in ws.iter_rows(): | |
row = list(row) | |
if row[3].value != None: | |
for i in range(len(row)): | |
row[i] = row[i].value | |
excel_list.append(row) | |
pp.pprint(excel_list) |
执行结果如下,可以看到全为None的行被过滤掉了。
按列读取方法类似,使用iter_cols()。
2.5切片读取
有时候我们并不想读取表格里的全部内容,只想读取一部分,这时候可以用iter_rows()和iter_cols()的切片功能。
excel_list = [] | |
for row in ws.iter_rows(min_row=2, min_col=2, max_row=3, max_col=3): | |
row = list(row) | |
if row[1].value != None: | |
for i in range(len(row)): | |
row[i] = row[i].value | |
excel_list.append(row) | |
pp.pprint(excel_list) |
执行结果如下,可以看到只获取了表格二行二列至三行三列的内容。

2.6 利用表格行列坐标直接获取单元格、单元格的值、切片
除了上述使用sheet.cell(row, col)来获取单元格值,以及iter_rows/cols获取行、列、切片外,还可以直接用excel的行列坐标表示来获取上述内容。
pp.pprint(ws['B3']) #获取B3单元格的cell对象 | |
pp.pprint(ws['B3'].value) #获取B3单元格cell对象的值 | |
pp.pprint(ws['A1':'B2']) # 获取A1:B2这个切片的cell们 | |
pp.pprint(ws['A:B']) # 获取A列到B列的所有cell对象 | |
pp.pprint(ws[1:2]) # 获取行1到行2两行的所有cell对象 |
这里要注意使用这种切片、获取行列对象值的时候不能直接用.value方法,.value只是单独cell即一个单元格的cell时才能直接用,所以要想用这种方法获取切片、行列的值时要配合遍历、列表等方法构建。
2.7快速获得工作表的行们和列们
使用sheet.rows 和sheet.cols。
https://blog.csdn.net/2401_83442335/category_12603381.html https://blog.csdn.net/2401_83442335/category_12603379.html
pp.pprint(list(ws.rows)) |
执行结果如下:

3.构建本任务所需字典
代码如下:
https://blog.csdn.net/2401_83442335/category_12603381.html https://blog.csdn.net/2401_83442335/category_12603379.html
class ReadRegListExcel: | |
def __init__(self, this_ws): | |
self.reg_dic = {} | |
self.ws = this_ws | |
def excel_max_rows(self): | |
max_rows = 0 | |
for row in ws.rows: | |
if row[3].value != None: | |
max_rows += 1 | |
return max_rows | |
def construct_dic(self): | |
max_rows = self.excel_max_rows() | |
self.reg_dic['module name'] = self.ws.cell(row=1, column=2).value | |
self.reg_dic['module base address'] = self.ws.cell(row=1, column=4).value | |
self.reg_dic['registers'] = [] | |
row = 3 | |
all_rows = list(self.ws.rows) | |
print(all_rows) | |
while row <= max_rows: | |
if all_rows[row-1][0].value != None: | |
self.reg_dic['registers'].append({}) | |
self.reg_dic['registers'][-1]['register name'] = all_rows[row-1][0].value | |
self.reg_dic['registers'][-1]['register address'] = all_rows[row-1][1].value | |
self.reg_dic['registers'][-1]['fields'] = [[value.value for value in all_rows[row-1][2:7]]] | |
else: | |
self.reg_dic['registers'][-1]['fields'].append([value.value for value in all_rows[row-1][2:7]]) | |
row += 1 | |
return self.reg_dic | |
if __name__ == "__main__": | |
reg_dic_obj = ReadRegListExcel(ws) | |
reg_dic = reg_dic_obj.construct_dic() | |
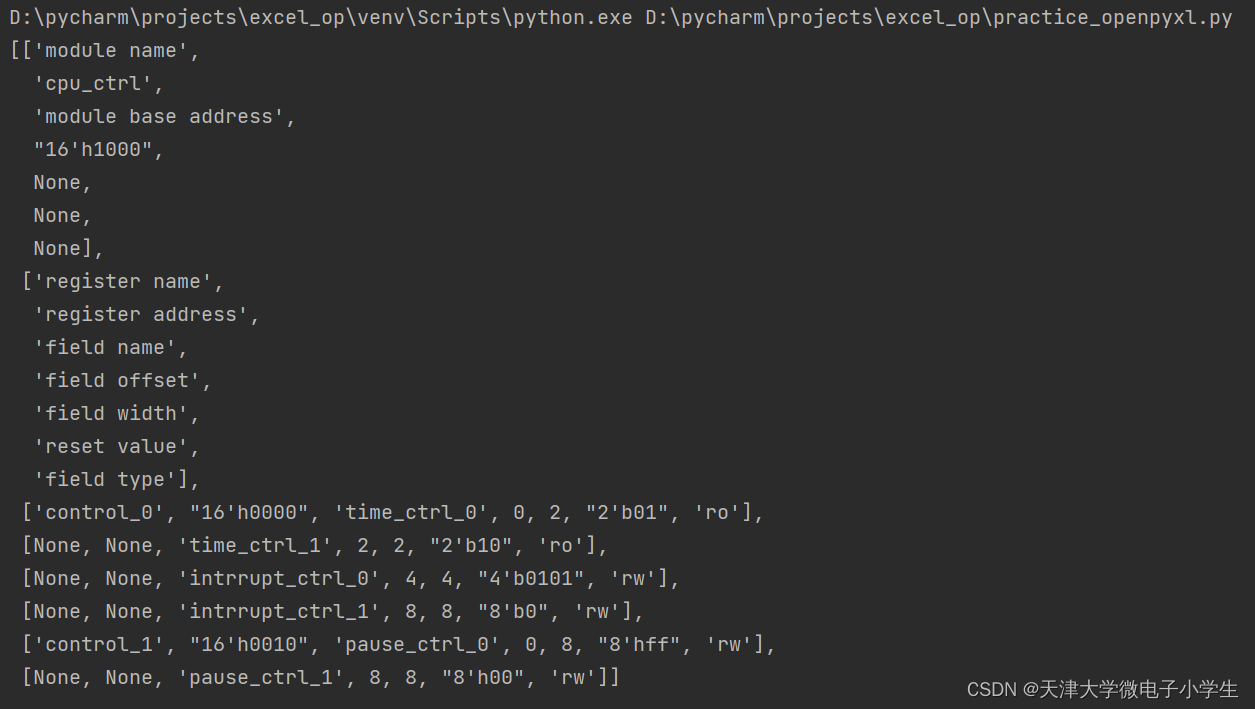
pp.pprint(reg_dic) |















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









